Python-数据库概念-pymysql-元编程-SQLAlchemy-学习笔记
序
欠4前年的一份笔记 ,献给今后的自己。
数据库
概念
数据库:按照数据结构来组织、存储、管理数据的仓库。
诞生
计算机的发明是为了做科学计算的,而科学计算需要大量的数据输入和输出。
早期,可以使用打孔卡片的孔、灯泡的亮灭来表示数据输入、输出。
后来,数据可以存储在磁带上,顺序的读取、写入磁带。
1956年IBM发明了磁盘驱动器这个革命性产品,支持随机访问。
随着信息化时代的到来,有了硬件存储技术的发展,有大量的数据需要存储和管理,数据库管理系统DBMS就诞生了。
不管使用什么存储介质,数据库的数据模型才是其核心和基础。
分类
按照数据模型分类:网状数据库、层次数据库、关系型数据库
层次数据库
以树型结构表示实体及其之间的联系。关系只支持一对多。代表数据库IBM IMS。
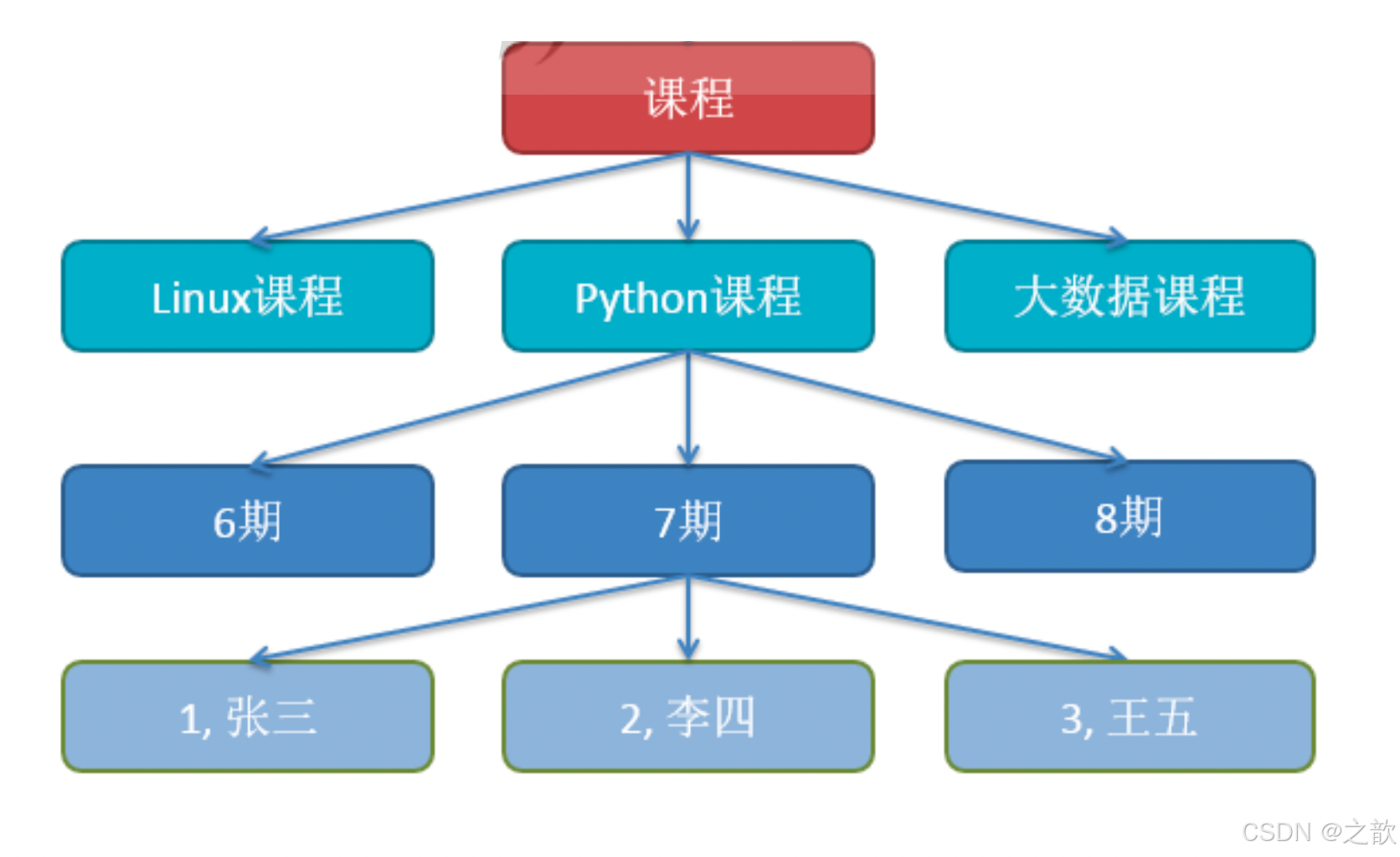
网状数据库
通用电气最早在1964年开发出网状数据库IDS,只能运行在GE自家的主机上。
结点描述数据,结点的联系就是数据的关系。
能够直接描述客观世界,可以表示实体间多种复杂关系,而这是层次数据模型无法做到的。比如,一个结点可以有多个父结点,结点之间支持可以多对多关联。
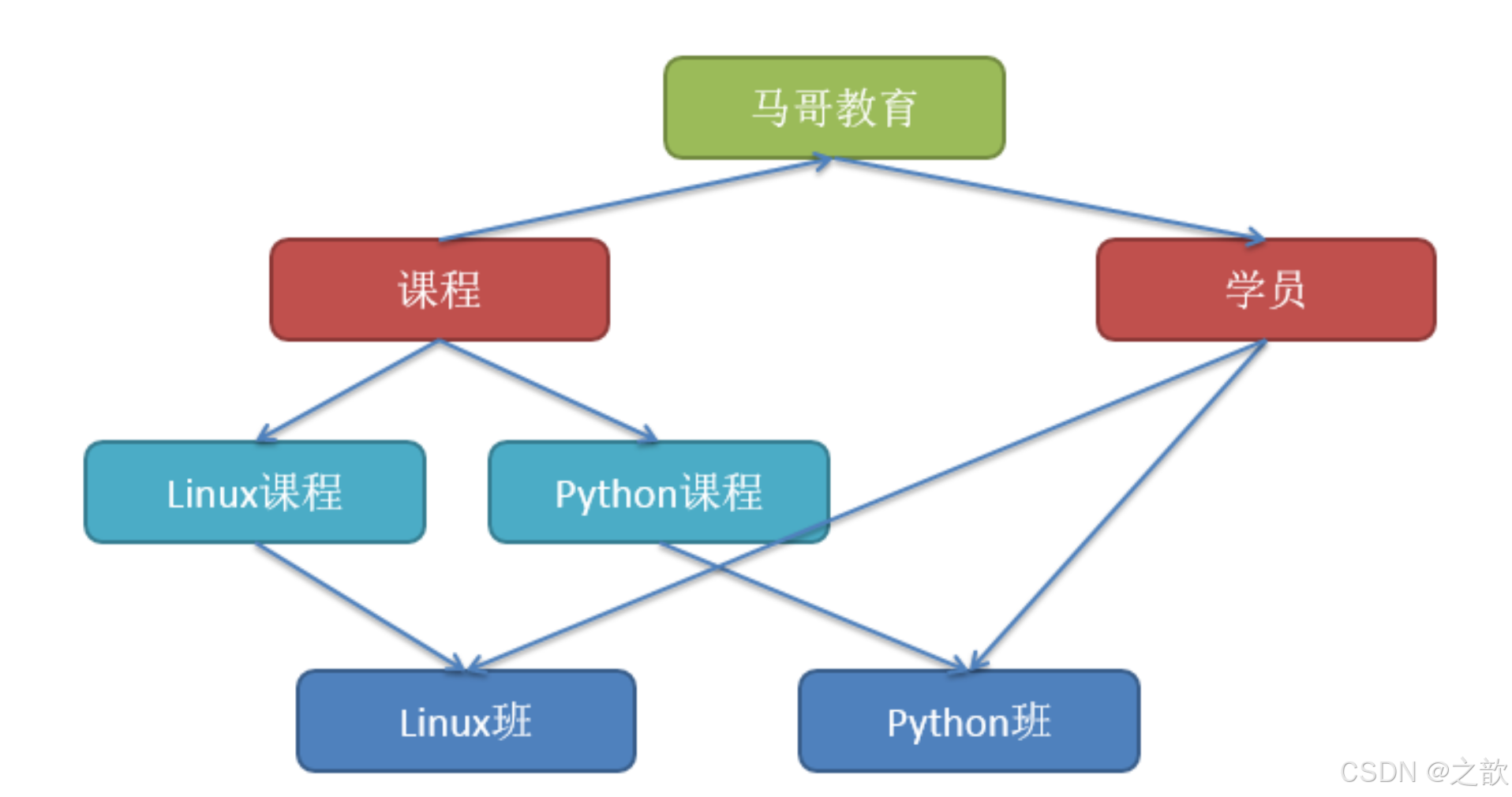
关系数据库
使用行、列组成的二维表来组织数据和关系,表中行(记录)即可以描述数据实体,也可以描述实体间关系。
关系模型比网状模型、层次模型更简单,不需要关系数存储的物理细节,专心于数据的逻辑构建,而且关系模型有论文的严格的数学理论基础支撑。

1970年,IBM的研究员E.F.Codd发表了名为"A Relational Model of Data for Large Shared Data Banks”的论文,
提出了关系模型的概念,奠定了关系模型的理论基础。
关系模型,有严格的数学基础,抽象级别较高,简单清晰,便于理解和使用。
经过几十年的发展,关系数据库百花齐放,技术日臻成熟和完善。
基于关系模型构建的数据库系统成为RDBMS(Relational DataBase System)。IBM DB2、Oracle的Oracle和Mysql、微软的MS SQL。以前的infomix、Sybase等。
Oracle的发展
拉里:埃里森(Larry Ellison)仔细阅读了IBM的关系数据库的论文,敏锐意识到在这个研究基础上可以开发商用软件系统。他们决定开发通用商用数据库系统Oracle,这个名字来源于他们曾给中央情报局做过的项目名。几个月后,他们就开发了Oracle 1.0。 Oracle快速的被推销,但是很不稳定。直到1992年的时候,Oracle7才逐渐稳定下来,并取得巨大成功。2001年的9i版本被广泛应用。
2009年4月20日,甲骨文公司宣布将以每股9.50美元,总计74亿美金收购sun(计算机系统)公司。2010年1月成功收购。
2013年,甲骨文超过IBM,成为继微软之后的全球第二大软件公司。
Mysql发展
1985年几个瑞典人为大型零售商的项目设计了一种利用索引顺序存取数据的软件,这就是MyISAM的前身。1996年,MySQL 1.0发布,随后发布了3.11.1版本,并开始往其它平台移植。2000年MySQL采用GPL协议开源。
MySQL 4.0开始支持MyISAM、InnoDB引擎。2005年10月,MySQL5.0成为里程碑版本。
2008年1月被Sun公司收购。
2009年1月,在Oracle收购MySQL之前,Monty Widenius担心收购,就从MySQL Server 5.5开始一条新的GPL分支,起名MariaDB。
MySQL的引擎是插件化的,可以支持很多种引擎:
MyISASM,不支持事务,插入、查询速度快。
InnoDB,支持事务,行级锁,MySQL 5.5起的默认引擎
去IOE
它是阿里巴巴造出的概念。其本意是,在阿里巴巴的IT架构中,去掉IBM的小型机、Oracle数据库、EMC存储设备,取而代之使用自己在开源软件基础上开发的系统。传统上,一个高端大气的数据中心,IBM小型机、Oracle数据库、EMC存储设备,可以说缺一不可。而使用这些架构的企业,不但采购、维护成本极高,核心架构还掌握在他人手中。
对于阿里巴巴这样大规模的互联网应用,应该采用开源、开放的系统架构。这种思路并不是阿里巴巴的新发明,国外的谷歌、Facebook、亚马逊等早已为之。只不过它们几乎一开始就有没有采用I商业公司的架构,所以他们也不用“去IOE”。
去IOE,转而使用廉价的架构,稳定性一定下降,需要较高的运维水平解决。
NOSQL
NoSQL是对非SQL、非传统关系型数据库的统称。
NoSQL一词诞生于1998年,2009年这个词汇被再次提出指非关系型、分布式、不提供ACID的数据库设计模式。
随着互联网时代的到来,数据爆发式增长,数据库技术发展日新月异,要适应新的业务需求。
随着移动互联网、物联网的到来,大数据的技术中NoSQL也同样重要。
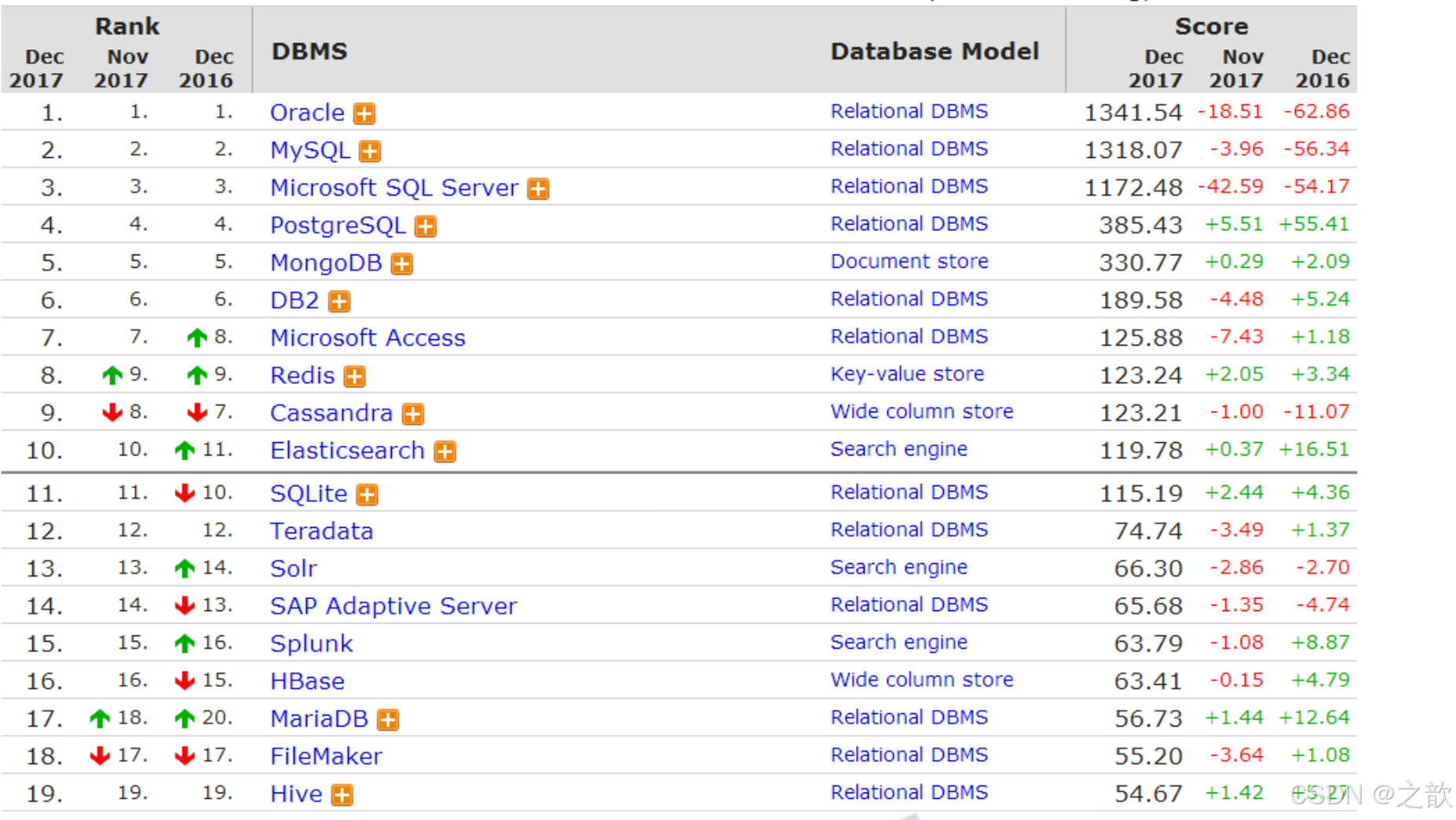
数据库流行度排名 2017.12
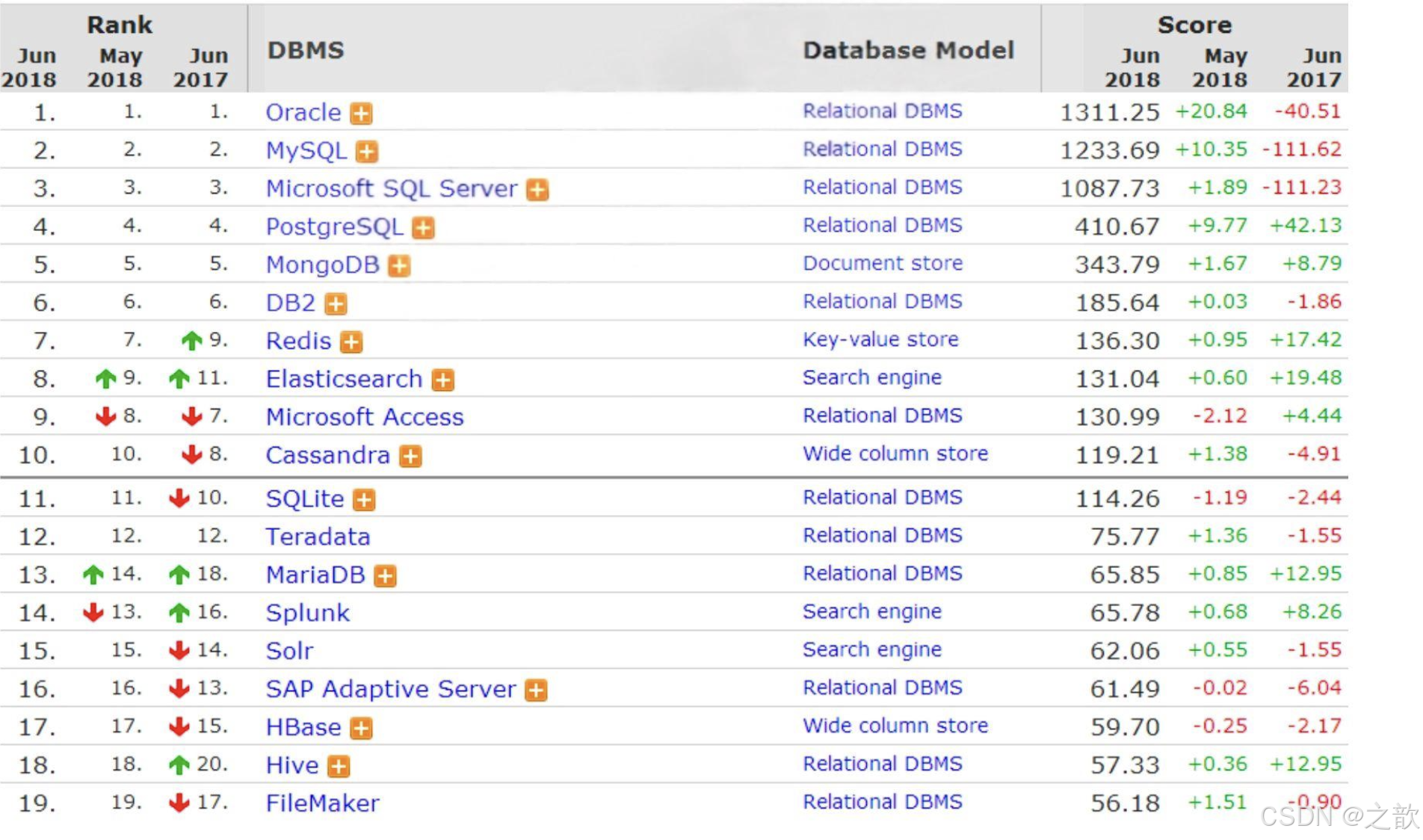
数据库流行度排名 2018.6
MySQL
MySQL是一种关系型数据库管理软件,支持网络访问,默认服务端口3306。
MySQL通信使用mysql协议。
问题
MySQL应该基于什么网络协议通信?
连接字符串参考
https://dev.mysql.com/doc/connector-net/en/connector-net-connection-options.html
“server=127.0.0.1;uid=root;pwd=12345;database=test”
安装
使用yum安装rpm包,Centos自带的版本太低,建议官方下载安装5.5以上版本。
推荐安装MariaDB,或者Percona版本。
Percona安装在第十章介绍过,这里不再赘述。
找一台虚拟机,安装好MySQL,充当数据库服务器。
# yum install Percona-Server-shared-55-5.5.45-re137.4.el6.x86_64.rpm Percona-Server-client-55-
5.5.45-re137.4.el6.x86_64.rpm Percona-Server-server-55-5.5.45-re137.4.el6.x86_64. rpm
service mysql start
# mysql_secure_installation
# mysql -uroot -p < test.sql
test.sql 为测试用脚本
SQL语句
SQL是结构化查询语言Structured Query Language。1987年被ISO组织标准化。
所有主流的关系型数据库都支持SQL,NoSQL也有很大一部分支持SQL。
SQL语句分为
DDL数据定义语言,负责数据库定义、数据库对象定义,由CREATE、ALTER与DROP三个语法所组成
DML数据操作语言,负责对数据库对象的操作,CRUD增删改查
DCL数据控制语言,负责数据库权限访问控制,由 GRANT和 REVOKE 两个指令组成
TCL事务控制语言,负责处理ACID事务,支持commit、rollback指令
SQL语句大小写不敏感。
SQL语句末尾应该使用分号结束。
DCL
GRANT授权、REVOKE撒销
GRANT ALL ON employees.* TO 'wayne'@'%' IDENTIFIED by 'wayne';
REVOKE ALL ON ** FROM wayne;
为通配符,指代任意库或者任意表。.* 所有库的所有表;employees.* 表示employees库下所有的表,%为通配符,它是SQL语句的通配符,匹配任意长度字符串
DDL
删除用户(慎用)
DROP USER wayne;
创建数据库
库是数据的集合,所有数据按照数据模型组织在数据库中。
CREATE DATABASE IF NOT EXISTS gogs CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
CHARACTER SET指定字符集。utf8mb4是utf8的扩展,支持4字节utf8mb4,需要MySQL5.5.3+。
COLLATE指定字符集的校对规则,用来做字符串的比较的。例如a、A谁大?
删除数据库
DROP DATABASE IF EXISTS gogs;
创建表
表分为行和列,MySQL是行存数据库。数据是一行行存的,列必须固定多少列。
行Row,也称为记录Record,元组。
列Column,也称为字段Field。
CREATE TABLE `employees` (`emp_no` int(11) NOT NULL,`birth_date` date NOT NULL,`first_name` varchar(14) NOT NULL,`last_name` varchar(16) NOT NULL,`gender` enum('M','F') NOT NULL,`hire_date` date NOT NULL,PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
反引号标注的名称,被认为是非关键字。
DESC
查看列信息
{DESCRIBE | DESC} tbl_name [col_name | wild]
DESC employees;
DESC employees '%name';
练习
设计一张表,记录登录账户的,应该存储用户的姓名、登录名、密码
DROP DATABASE IF EXISTS test;
CREATE DATABASE IF NOT EXISTS test CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;CREATE TABLE reg (
id int (11) NOT NULL,
loginname varchar(50) DEFAULT NULL,
name varchar (64) DEFAULT NULL,
password varchar (128) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB;
PRIMARY KEY主键
表中一列或者多列组成唯一的key,也就是通过这一个或者多个列能唯一的标识一条记录。
主键的列不能包含空值null。主键往往设置为整型、长整型,且自增AUTO_INCREMENT。
表中可以没有主键,但是,一般表设计中,往往都会有主键。
索引Index
可以看做是一本字典的目录,为了快速检索用的。空间换时间,显著提高查询效率。
可以对一列或者多列字段设定索引。
主键索引,主键会自动建立主键索引,主键本身就是为了快速定位唯一记录的。
唯一索引,表中的索引列组成的索引必须唯一,但可以为空,非空值必须唯一普通索引,没有唯一性的要求,就是建了一个字典的目录而已。
约束Constraint
UNIQUE约束(唯一键约束)
定义了唯一键索引,就定义了唯一键约束。
PRIMARY KEY约束
定义了主键,就定义了主键约束。
外键约束Foreign Key
外键,在表B中的列,关联表A中的主键,表B中的列就是外键。
如果在表B插入一条数据,B的外键列插入了一个值,这个值必须是表A中存在的主键值。
修改表B的外键值也是同样,外键值同样要在表A中存在。
如果表A要删除一条记录,那么就等于删除一个主键,那么如果表B中引用到了这个主键,就必须先删除表B中引用这个主键的记录,然后才能删除表A的记录,否则删除失败。
修改表A的主键,由于主键的唯一性,修改的主键相当于插入新主键,那么表B引用过这个主键,将阻止表A的主键修改,必须删除表B的相关记录后,才可修改表A的主键。
外键约束,是为了保证数据完整性、一致性,杜绝数冗余、数据讹误。
视图
视图,也称虚表,看起来像表。它是由查询语句生成的。可以通过视图进行CRUD操作。视图的作用
简化操作,将复杂查询SQL语句定义为视图,可以简化查询。
数据安全,视图可以只显示真实表的部分列,或计算后的结果,从而隐藏真实表的数据
数据类型
MySQL中的数据类型
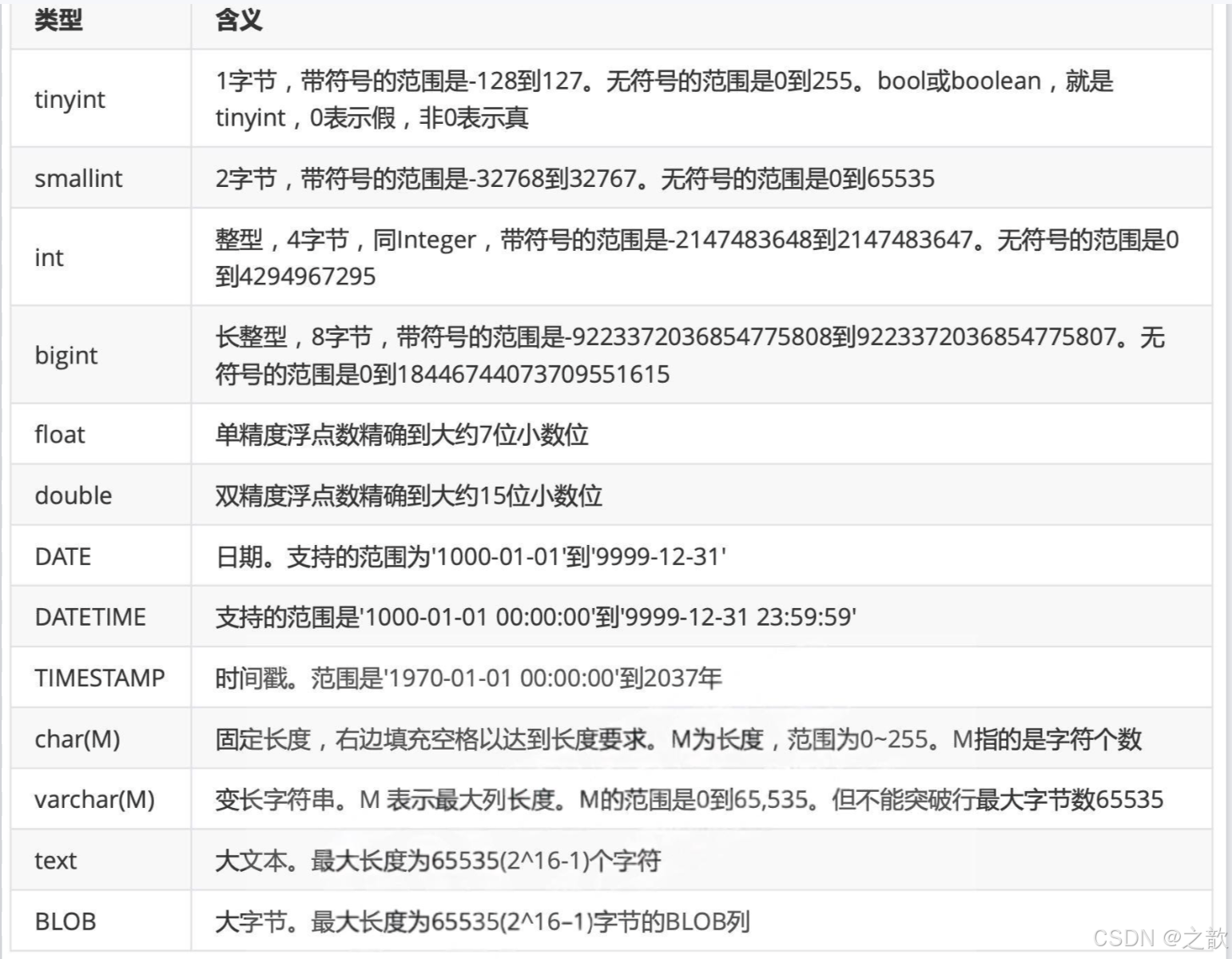
LENGTH函数返回字节数。而char和varchar定义的M是字符数限制。
char可以将字符串变成等长的,空间换时间,效率略高;varchar变长,省了空间。
关系操作
关系:在关系数据库中,关系就是二维表。
关系操作就是对表的操作。
选择(selection):又称为限制,是从关系中选择出满足给定条件的元组。
投影(projection):在关系上投影就是从选择出若干属性列组成新的关系。
连接(join):将不同的两个关系连接成一个关系。
DML CRUD 增删改
Insert语句
INSERT INTO table_name (col_name,...) VALUES (value1,...);
向表中插入一行数据,自增字段、缺省值字段、可为空字段可以不写
INSERT INTO table_name SELECT ... ;
将select查询的结果插入到表中
INSERT INTO table_name (col_name1,...) VALUES (value1,...) ON DUPLICATE KEY UPDATE
col_name1=value1,...;
如果主键冲突、唯一键冲奕就执行update后的设置。这条语句的意思,就是主键不在新增记录,主键在就更新部分字段。
INSERT IGNORE INTO table_name (col_name,...) VALUES (value 1,...);
如果主键冲突、唯一键冲突就忽略错误,返回一个警告。
Update语句
UPDATE [IGNORE] tbl_name
SET col_name1=expr1 [, col_name2=expr2 ...]
[WHERE where_definition]
IGNORE 意义同Insert语句UPDATE reg SET name='3K=' WHERE id=5;Delete语句
DELETE [IGNORE] FROM tbl_name
[WHERE where_definition]
删除符合条件的记录
Select语句
SELECTI[DISTINCT]select_expr, ... [FROM table_references[WHERE where_definition][GROUP BY {col_name | expr | position}[ASC | DESC ], ... [WITH ROLLUP]][HAVING where_definition][ORDER BY {col_name | expr | position}[ASC| DESC], ...][LIMIT {[offset,] row_count |row_count OFFSET offset}][FOR UPDATE | LOCK IN SHARE MODE]]
FOR UPDATE会把行进行写锁定,这是排它锁。
查询
查询的结果成为结果集recordset。
SELECT 1;
--最简单的查询
SELECT * FROM employees;
-- 字符串合并
SELECT emp_no, first_name + last_name FROM employees;
SELECT emp_no, CONCAT(first_name,' ', last_name) FROM employees;
-- AS 定义别名,可选。写AS是一个好习惯
SELECT emp_no as no, CONCAT(first_name,' ',last_name) name FROM employees emp;
Limit子句
-- 返回5条记录
SELECT * FROM employees emp LIMIT 5;
--返回5条记录,偏移18条
SELECT * FROM employees emp LIMIT 5 OFFSET 18;
SELECT * FROM employees emp LIMIT 18, 5;
Where子句
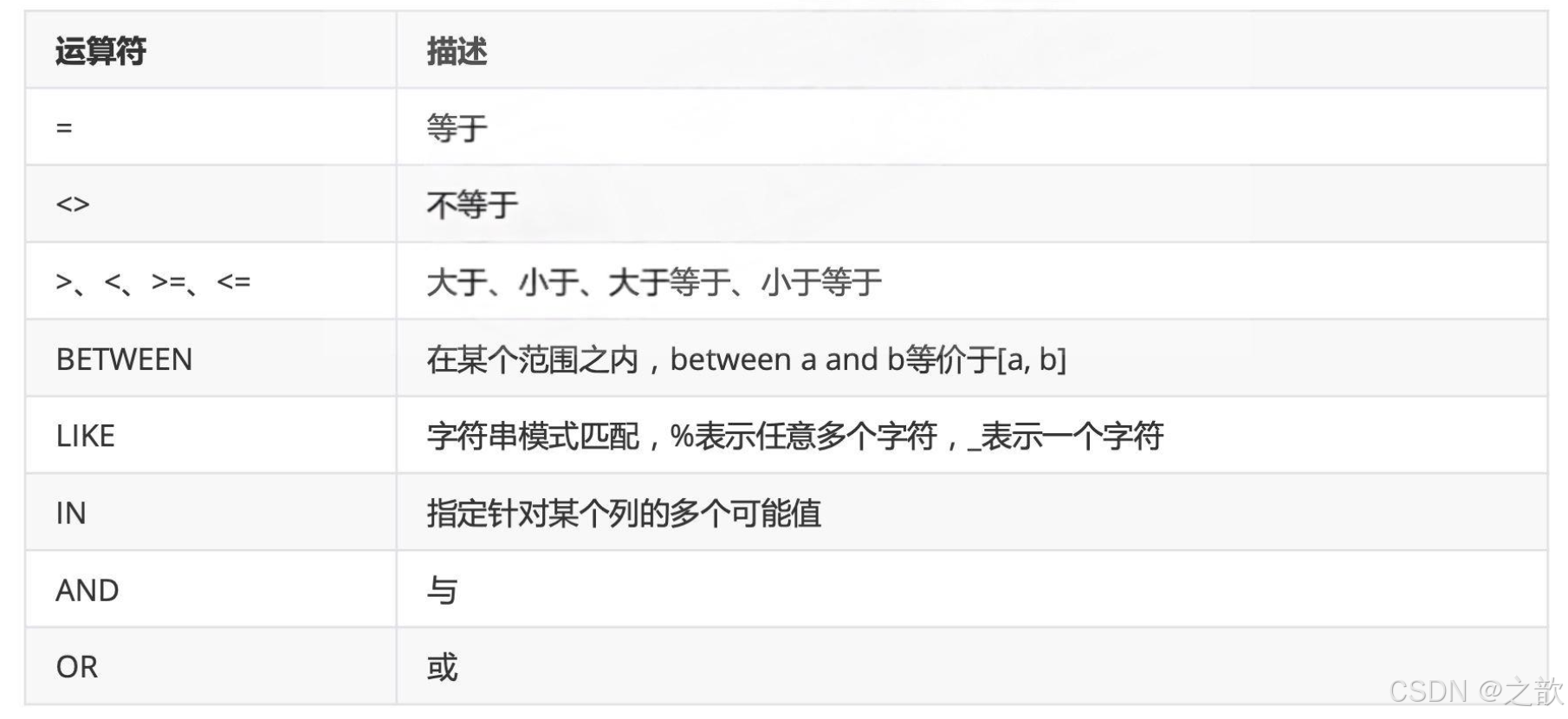
注意:如果很多表达式需要使用AND、OR计算逻辑表达式的值的时候,由于有结合律的问题,建议使用小括号来避免产生错误
-- 条件查询
SELECT * FROM employees WHERE emp_no < 10015 and last_name LIKE 'P%' ;
SELECT * FROM employees WHERE emp_no BETWEEN 10010 AND 10015 AND last_name LIKE 'P%' ;
SELECT * FROM employees WHERE emp_no in (10001, 10002, 10010);
Order by子句
对查询结果进行排序,可以升序ASC、降序DESC。
-- 降序
SELECT * FROM employees WHERE emp_no in (10001, 10002, 10010) ORDER BY emp_no DESC;DISTINCT
不返回重复记录
-- DISTINCT使用
SELECT DISTINCT dept_no from dept_emp;
SELECT DISTINCT emp_no from dept_emp;
SELECT DISTINCT dept_no, emp_no from dept_emp;
聚合函数
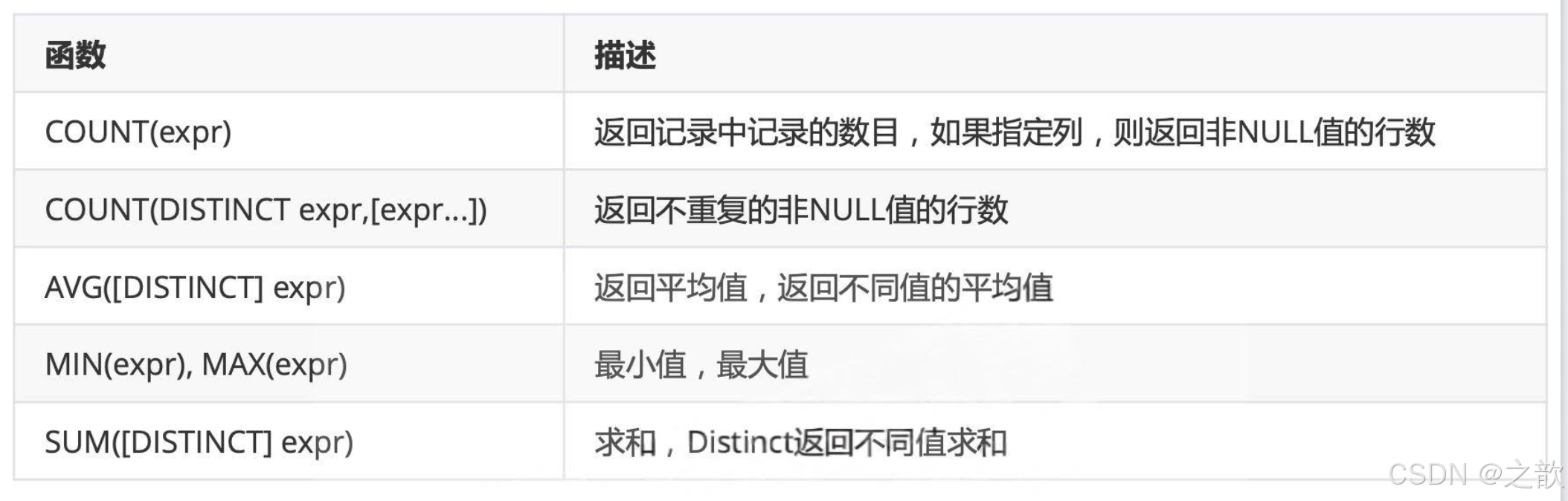
-- 聚合函数
SELECT COUNT(*), AVG(emp_no), SUM(emp_no), MIN(emp_no), MAX(emp_no) FROM employees;
分组查询
使用Group by子句,如果有条件,使用Having子句过滤分组、聚合过的结果。
-- 聚合所有
SELECT emp_no, SUM(salary), AVG(salary), COUNT(emp_no) from salaries;-- 聚合被选择的记录
SELECT emp_no, SUM(salary), AVG(salary), COUNT(emp_no) from salaries WHERE emp_no < 10003;--按照不同emp_no分组,每组分别聚合
SELECT emp_no, SUM(salary), AVG(salary), COUNT(emp_no) from salaries WHERE emp_no < 10003 GROUP BY emp_no;-- HAVING子句对分组结果过滤
SELECT emp_no, SUM(salary), AVG(salary), COUNT(emp_no) from salaries GROUP BY emp_no HAVING AVG (salary) > 45000;--使用别名
SELECT emp_no, SUM(salary), AVG(salary) AS sal_avg, COUNT(emp_no) from salaries GROUP BY emp_no HAVING sal_avg > 60000;-- 最后对分组过滤后的结果排序
salaries SELECT emp_no, SUM(salary), AVG(salary) AS sal_avg, COUNT(emp_no) from GROUP BY emp_no HAVING sal_avg › 60000 ORDER BY sal_avg;
子查询
查询语句可以嵌套,内部查询就是子查询。
子查询必须在一组小括号中。
子查询中不能使用Order by。
-- 子查询
SELECT * FROM employees WHERE emp_no in (SELECT emp_no from employees WHERE emp_no > 10015) ORDER BY emp_no DESC;SELECT emp.emp_no, emp.first_name, gender FROM (SELECT * from employees WHERE emp_no › 10015) AS emp WHERE emp emp_no ‹ 10019 ORDER BY emp_no DESC;连接join
交叉连接cross join
笛卡尔乘积,全部交叉
在MySQL中,CROSS JOIN从语法上说与INNER JOIN等同
-- 工资40行
SELECT * FROM salaries;
-- 20行
SELECT * FROM employees;
--- 800行
SELECT * from employees CROSS JOIN salaries;
注意:departments和employees并没有直接的关系,做笛卡尔乘积只是为了看的清楚内连接
inner join,省略为join。
等值连接,只选某些field相等的元组(行),使用On限定关联的结果
自然连接,特殊的等值连接,会去掉重复的列。用的少。
-— 内连接,笛卡尔乘积 800行
SELECT * from employees JOIN salaries;
SELECT * from employees INNER JOIN salaries;
-- ON等值连接 40行
SELECT * from employees JOIN salaries ON employees. emp_no = salaries.emp_no;-- 自然连接,去掉了重复列,且自行使用employees.emp_no = salaries.emp_no的条件
SELECT * from employees NATURAL JOIN salaries;
外连接
outer join,可以省略为join
分为左外连接,即左连接;右外连接,即右连接;全外连接
-- 左连接
SELECT * from employees LEFT JOIN salaries ON employees. emp_no = salaries.emp_no;
-- 右连接
SELECT * from employees RIGHT JOIN salaries ON employees. emp_no = salaries.emp_no;-- 这个右连接等价于上面的左连接
SELECT * from salaries RIGHT JOIN employees ON employees.emp_no = salaries.emp_no;
左外连接、右外连接
看表的数据的方向,谁是主表,谁的所有数据都显示
自连接
表自己和自己连接
select manager.* from emp manager, emp worker where manaer. empno=worker.mgr and worker.empno=1;select manager.* from emp manager inner join emp worker on manaer. empno=worker.mgr where worker.empno=1;
事务Transaction
InnoDB引擎,支持事务。
事务,由若干条语句组成的,指的是要做的一系列操作。
关系型数据库中支持事务,必须支持其四个属性(ACID)

原子性,要求事务中的所有操作,不可分割,不能做了一部分操作,还剩一部分操作;
一致性,多个事务并行执行的结果,应该和事务排队执行的结果一致。如果事务的并行执行和多线程读写共享资源一样不可预期,就不能保证一致性。
隔离性,就是指多个事务访问共同的数据了,应该互不干扰。隔离性,指的是究竟在一个事务处理期间,其他事务能不能访问的问题
持久性,比较好理解,就是事务提交后,数据不能丟失。
MySQL隔离级别
隔离性不好,事务的操作就会互相影响,带来不同严重程度的后果。
首先看看隔离性不好,带来哪些问题:
- 更新丢失Lost Update
事务A和B,更新同一个数据,它们都读取了初始值100,A要减10,B要加100,A减去10后更新为90,B加100更新为200,A的更新丢失了,就像从来没有减过10一样。 - 脏读
事务A和B,事务B读取到了事务A未提交的数据(这个数据可能是一个中间值,也可能事务A后来回滚事务)。事务A是否最后提交并不关心。只要读取到了这个被修改的数据就是脏读。 - 不可重复读Unrepeatable read
事务A在事务执行中相同查询语句,得到了不同的结果,不能保证同一条查询语句重复读相同的结果就是不可以重复读。
例如,事务A查询了一次后,事务B修改了数据,事务A又查询了一次,发现数据不一致了。注意,脏读讲的是可以读到相同的数据的,但是读取的是一个未提交的数据,不是提交的最终结果。 - 幻读Phantom read
事务A中同一个查询要进行多次,事务B插入数据,导致A返回不同的结果集,如同幻觉,就是幻读。数据集有记录增加了,可以看做是增加了记录的不可重复读。
有了上述问题,数据库就必须要解决,提出了隔离级别。隔离级别由低到高,如下表
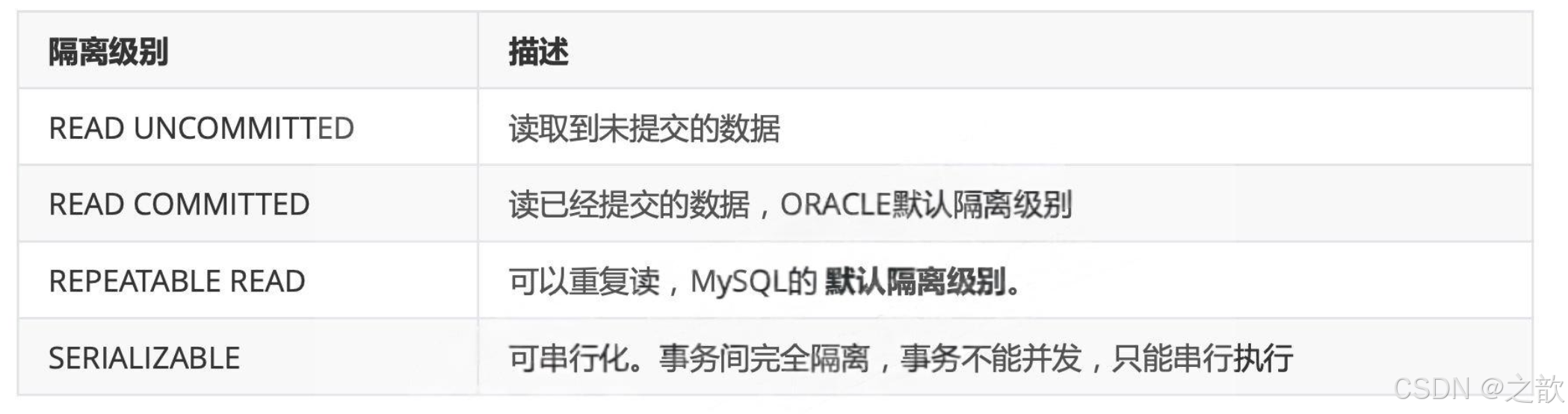
隔离级别越高,串行化越高,数据库执行效率低;隔离级别越低,并行度越高,性能越高。
隔离级别越高,当前事务处理的中间结果对其它事务不可见程度越高,
-- 设置会话级或者全局隔离级别
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL
{READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE}
-- 查询隔离级别
SELECT @@global.tx_isolation;
SELECT @@tx_isolation;
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SERIALIZABLE,串行了,解决所有问题
REPEATABLE READ,事务A中同一条查询语句返回同样的结果,就是可以重复读数据了。例如语句为(select * from user)。解决的办法有:
1、对select的数据加锁,不允许其它事务删除、修改的操作
2、第一次select的时候,对最后一次确切提交的事务的结果做快照
解决了不可以重复读,但是有可能出现幻读。因为另一个事务可以增删数据。
READ COMMITTED,在事务中,每次select可以读取到别的事务刚提交成功的新的数据。因为读到的是提交后的数据,解决了脏读,但是不能解决 不可重复读和 幻读的问题。因为其他事务前后修改了数据或增删了数据。
READ UNCOMMITTED,能读取到别的事务还没有提交的数据,完全没有隔离性可言,出现了脏读,当前其他问题都可能出现。
事务语法
START TRANSACTION或BEGIN开始一个事务,START TRANSACTION是标准SQL的语法。
使用COMMIT提交事务后,变更成为永久变更。
ROLLBACK可以在提交事务之前,回滚变更,事务中的操作就如同没有发生过一样(原子性)。
SET AUTOCOMMIT语句可以禁用或启用默认的autocommit模式,用于当前连接。
SET AUTOCOMMIT=0禁用自动提交事务。如果开启自动提交,如果有一个修改表的语句执行后,会立即把更新存储到磁盘。
数据仓库和数据库的区别
本质上来说没有区别,都是存放数据的地方。但是数据库关注数据的持久化、数据的关系,为业务系统提供支持,事务支持;数据仓库存储数据的是为了分析或者发掘而设计的表结构,可以存储海量数据。
数据库存储在线交易数据OLTP(联机事务处理OLTP,On-line Transaction Processing);数据仓库存储历史数据用于分析OLAP(联机分析处理OLAP,On-Line Analytical Processing)。数据库支持在线业务,需要频繁增删改查;数据仓库一般囤积历史数据支持用于分析的SQL,一般不建议删改。
其它概念
游标Cursor
操作查询的结果集的一种方法。
可以将游标当做一个指针,指向结果集中的某一行。
存储过程、触发器
存储过程(Stored Procedure),数据库系统中,一段完成特定功能的SQL语句。编写成类似函数的方式,可以传参并调用。支持流程控制语句。
触发器(Trigger),由事件触发的特殊的存储过程,例如insert数据时触发。
触发器功能虽然强大,但是会有性能问题。
这两种技术,虽然是数据库高级内容,但基本很少用了。
数据库开发
驱动
MySQL基于TCP协议之上开发,但是网络连接后,传输的数据必须遵循MySQL的协议。封装好MySQL协议的包,就是驱动程序。
MySQL的驱动
-
MySQLdb
最有名的库。对MySQL的C Client封装实现,支持Python 2,不更新了,不支持Python3 -
MySQL官方Connector
-
pymysql
语法兼容MySQLdb,使用Python写的库,支持Python 3
pymysql便用
安装
$ pip3 install pymysql
创建数据库和表
CREATE DATABASE IF NOT EXISTS school;
SHOW DATABASES;
USE school;
CREATE TABLE student (id int (11) NOT NULL AUTO_INCREMENT,name varchar (255) NOT NULL,age int(11) DEFAULT NULL,PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
连接Connect
首先,必须建立一个传输数据通道一一连接。
pymysql.connect()方法返回的是Connections模块下的Connection类实例。connect方法传参就是给Connection
类的__init__提供参数
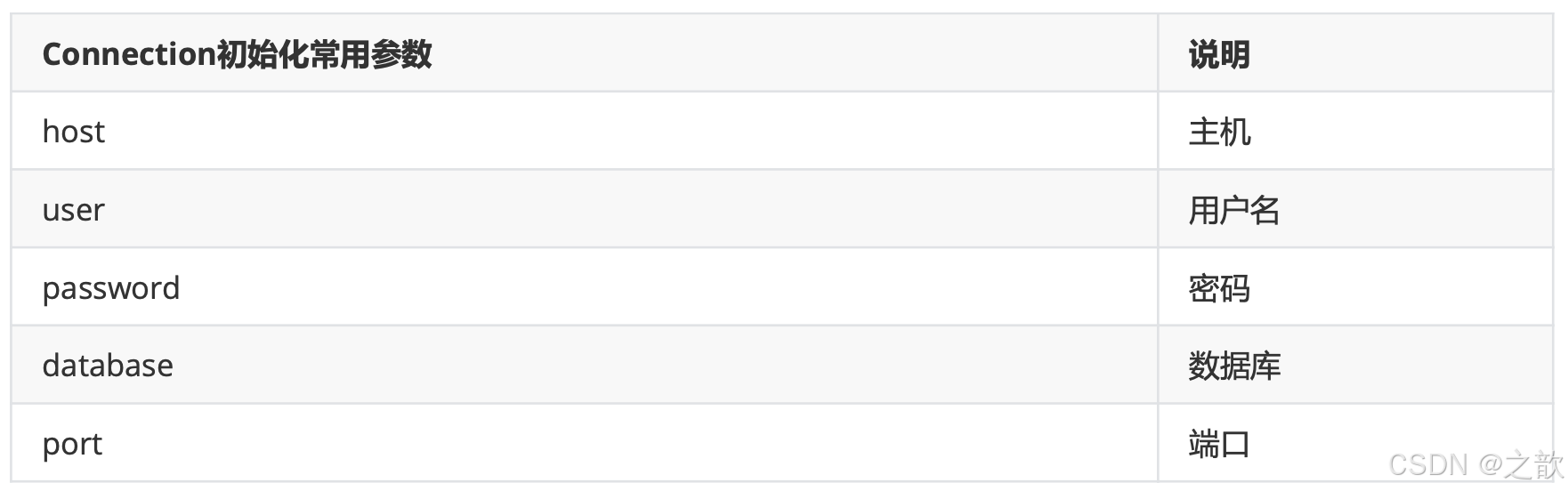
Connection.ping()方法,测试数据库服务器是否活着。有一个参数reconnect表示断开与服务器连接是否重连。
import pymysqltry:conn = pymysql.connect('127.0.0.1', 'username', 'password', 'database')print(conn.ping(False))
finally:if conn:conn.close()print(conn.ping(False))
游标Cursor
操作数据库,必须使用游标,需要先获取一个游标对象。
Connection.cursor(cursor=None)方法返回一个新的游标对象。
连接没有关闭前,游标对象可以反复使用。
cursor参数,可以指定一个Cursor类。如果为None,则使用默认Cursor类。
操作数据库
数据库操作需要使用Cursor类的实例,提供execute() 方法,执行SQL语句,成功返回影响的行数。
新增记录
使用insert into语句插入数据。
import pymysqltry:conn = pymysql.connect('127.0.0.1', 'username', 'password', 'database')print(conn.ping(False))cursor = conn.cursor()insert_sql = "insert into student (name,age) values( 'tom', 20)"rows = cursor.execute(insert_sql)print(rows)
finally:if conn:conn.close()发现数据库中没有数据提交成功,为什么?
原因在于,在Connection类的__init__方法的注释中有这么一句话
autocommit: Autocommit mode.None means use server default. (default: False)
那是否应该开启自动提交呢?
不用开启,一般我们需要手动管理事务。
事务管理
Connection类有三个方法:
begin 开始事务
commit 将变更提交
rollback 回滚事务
import pymysqlconn = pymysql.connect('127.0.0.1', 'username', 'password', 'database')cursor = conn.cursor()try:insert_sql = "insert into student (name, age) values ('tom' ,20)"rows = cursor.execute(insert_sql)print(rows)conn.commit()
except:conn.rollback()
finally:if cursor:cursor.close()if conn:conn.close()
批量增加数据
import pymysqlconn = pymysql.connect(host='127.0.0.1',user= 'test', password="xxxx", database='xxxx',port=3306)cursor = conn.cursor()try:for i in range(10):insert_sql = "insert into student (name,age) values('tom{0}',20+{0})".format(i)rows = cursor.execute(insert_sql)conn.commit()
except:conn.rollback()
finally:if cursor:cursor.close()if conn:conn.close()
一般流程
- 建立连接
- 获取游标
- 执行SQL
- 提交事务
- 释放资源
查询
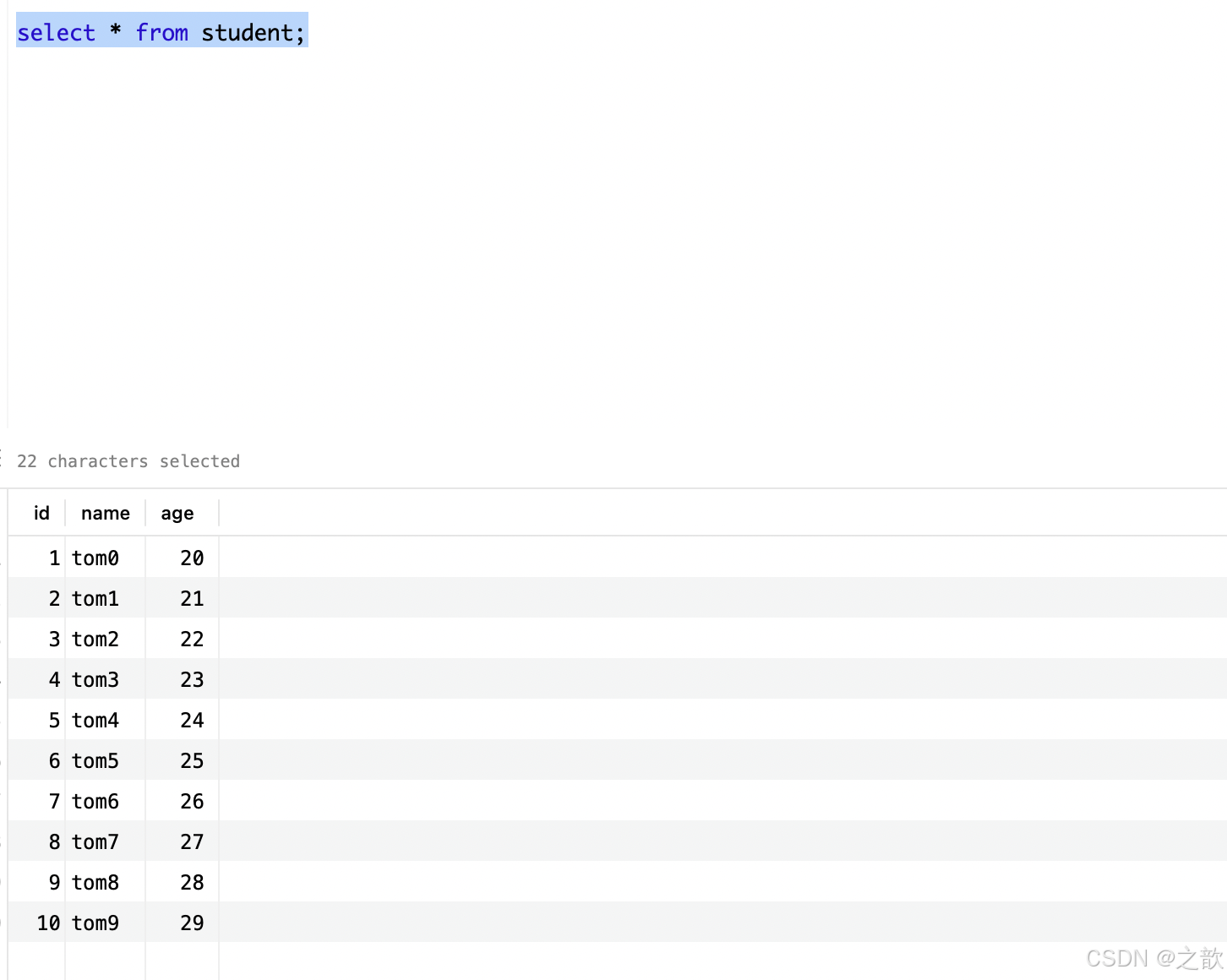
Cursor类的获取查询结果集的方法有fetchone()、fetchmany(size=None)、fetchall()。
import pymysqlconn = pymysql.connect(host='127.0.0.1',user= 'test', password="xxxx", database='xxxx',port=3306)cursor = conn.cursor()sql = 'select * from student'
rows = cursor.execute(sql) # 返回影响的行数print(cursor.fetchone)
print(cursor.fetchone)
print('1 -----------')
print(cursor.fetchmany(2))
print('2 ~~~~~~~~~~~~~~~~~~~~~~~~~~~')
print(cursor.fetchmany(2))
print('3-----------')
print(cursor.fetchall())
if cursor:cursor.close()
if conn:conn.close()输出:
<bound method Cursor.fetchone of <pymysql.cursors.Cursor object at 0x104db1940>>
<bound method Cursor.fetchone of <pymysql.cursors.Cursor object at 0x104db1940>>
1 -----------
((1, 'tom0', 20), (2, 'tom1', 21))
2 ~~~~~~~~~~~~~~~~~~~~~~~~~~~
((3, 'tom2', 22), (4, 'tom3', 23))
3-----------
((5, 'tom4', 24), (6, 'tom5', 25), (7, 'tom6', 26), (8, 'tom7', 27), (9, 'tom8', 28), (10, 'tom9', 29))
fetchone()方法,获取结果集的下一行
fetchmany(size=None)方法,size指定返回的行数的行,None则返回空元组。
fetchall()方法,获取所有行。
返回多行,如果走到末尾,就返回空元组,否则返回一个元组,其元素就是每一行的记录。
每一行的记录也封装在一个元组中。
cursor.rownumber返回当前行号。可以修改,支持负数。
cursor.rowcount 返回的总行数
注意:fetch操作的是结果集,结果集是保存在客户端的,也就是说fetch的时候,查询已经结束了。
带列名查询
Cursor类有一个Mixin的子类DictCursor。
只需要 cursor = conn.cursor(DictCursor)就可以了
# 返回结果
{' name': 'tom', 'age': 20, 'id': 4}
{'name': 'tom®', 'age': 20, 'id': 5}
SQL注入攻击
找出用户id为6的用户信息的SQL语句如下
SELECT * from student WHERE id = 6
现在,要求可以找出某个id对应用户的信息,代码如下
userid = 5 #用户id可以变
sql = 'SELECT * from student WHERE id = {}'. format(userid)
userid可以变,例如从客户端request请求中获取,直接拼接到查询字符串中。
可是,如果userid='5 or 1=1’呢?
sql = 'SELECT * from student WHERE id = {}'. format ('5 or 1=1')
运行的结果竟然是返回了全部数据。
SQL注入攻击
猜测后台数据库的查询语句使用拼接字符串的方式,从而经过设计为服务端传参,令其拼接出特殊字符串,返回用
户想要的结果。
永远不要相信客户端传来的数据是规范的及安全的!!!
如何解决注入攻击?
参数化查询,可以有效防止注入攻击,并提高查询的效率。
Cursor.execute(query, args=None)
args,必须是元组、列表或字典。如果查询字符串使用%(name)s,就必须使用字典。
import pymysql
from pymysql.cursors import DictCursorconn = pymysql.connect(host='127.0.0.1',user= 'test', password="xxxx", database='xxxx',port=3306)cursor = conn.cursor(DictCursor)userid = '1=1'
sql = 'SELECT * from student WHERE id = 5 OR %s'
print(sql)cursor.execute(sql,(userid, )) # 参数化查询print(cursor.fetchall())print('~~~~~~~~~~~~~~~~~~~~~~~~~')sql = 'SELECT * from student WHERE name like %(name)s and age > %(age)s'cursor.execute(sql,{'name':'tom%','age':25}) # 参数化查询
print(cursor.fetchall())if cursor:cursor.close()
if conn:conn.close输出:
[{'id': 1, 'name': 'tom0', 'age': 20}, {'id': 2, 'name': 'tom1', 'age': 21}, {'id': 3, 'name': 'tom2', 'age': 22}, {'id': 4, 'name': 'tom3', 'age': 23}, {'id': 5, 'name': 'tom4', 'age': 24}, {'id': 6, 'name': 'tom5', 'age': 25}, {'id': 7, 'name': 'tom6', 'age': 26}, {'id': 8, 'name': 'tom7', 'age': 27}, {'id': 9, 'name': 'tom8', 'age': 28}, {'id': 10, 'name': 'tom9', 'age': 29}]
~~~~~~~~~~~~~~~~~~~~~~~~~
[{'id': 7, 'name': 'tom6', 'age': 26}, {'id': 8, 'name': 'tom7', 'age': 27}, {'id': 9, 'name': 'tom8', 'age': 28}, {'id': 10, 'name': 'tom9', 'age': 29}]
参数化查询为什么提高效率?
原因就是一—SQL语句缓存。
数据库服务器一般会对SQL语句编译和缓存,编译只对SQL语句部分,所以参数中就算有SQL指令也不会被执行。
编译过程,需要词法分析、语法分析、生成AST、优化、生成执行计划等过程,比较耗费资源。
服务端会先查找是否对同一条查询语句进行了缓存,如果缓存未失效,则不需要再次编译,从而降低了编译的成
本,降低了内存消耗。
可以认为SQL语句字符串就是一个key,如果使用拼接方案,每次发过去的SQL语句都不一样,都需要编译并缓存。
大量查询的时候,首选使用参数化查询,以节省资源。
开发时,应该使用参数化查询。
注意:这里说的是查询字符串的缓存,不是查询结果的缓存。
上下文支持
查看连接类和游标类的源码
# 连接类
class Connection(object):def __enter__(self):"""Context manager that returns a Cursor"""return self.cursor()def __exit__(self, exc, value, traceback):"""On successful exit, commit. On exception, rollback"""if exc:self.rollback()else:self.commit()# 游标类
class Cursor(object):def __enter__(self):return selfdef __exit__(self, *exc_info):del exc_infoself.close()连接类进入上下文的时候会返回一个游标对象,退出时如果没有异常会提交更改。
游标类也使用上下文,在退出时关闭游标对象。
import pymysqlconn = pymysql.connect(host='127.0.0.1', user='cds', password="ds^#8^f!2", database='ds',port=3306)
try:with conn.cursor() as cursor:for i in range(3):insert_sql = "insert into student (name,age) values( 'tom{0}',20+{0})".format(i)print(insert_sql)cursor.execute(insert_sql)rows = cursor.execute(insert_sql)conn.commit()# 如果此时使用这个关闭的cursor,会抛异常# sql = "select * from student"# cursor.execute(sql)# print(cursor.fetchall())
except Exception as e:print(e)conn.rollback()
finally:conn.close()换一种写法,使用连接的上下文
import pymysqlconn = pymysql.connect(host='127.0.0.1', user='23232', password="3232^#8^f!2", database='323',port=3306)with conn as cursor:for i in range(3):insert_sql = "insert into student (name,age) values ('tom{0}' ,20+{0})".format(i)print(insert_sql)rows = cursor.cursor().execute(insert_sql)print(rows)cursor.commit()sql = "select * from student"xx = cursor.cursor();xx.execute(sql)print(xx.fetchall())# 关闭xx.close()xx.close()
conn的with进入是返回一个新的cursor对象,退出时,只是提交或者回滚了事务。并没有关闭cursor和conn。
不关闭cursor就可以接着用,省的反复创建它。
如果想关闭cursor对象,这样写
import pymysqlconn = pymysql.connect(host='127.0.0.1', user='323232', password="323232^#8^f!2", database='32323',port=3306)with conn as cursor:with cursor:sql = "select * from student"xx = cursor.cursor();xx.execute(sql)print(xx.fetchall())
# 关闭
conn.close()
输出:
((1, 'tom0', 20), (2, 'tom1', 21), (3, 'tom2', 22), (4, 'tom3', 23), (5, 'tom4', 24), (6, 'tom5', 25), (7, 'tom6', 26), (8, 'tom7', 27), (9, 'tom8', 28), (10, 'tom9', 29), (11, 'tom0', 20), (12, 'tom0', 20), (13, 'tom1', 21), (14, 'tom1', 21), (15, 'tom2', 22), (16, 'tom2', 22), (17, 'tom0', 20), (33, 'tom0', 20), (34, 'tom1', 21), (35, 'tom2', 22), (36, 'tom0', 20), (37, 'tom1', 21), (38, 'tom2', 22), (39, 'tom0', 20), (40, 'tom1', 21), (41, 'tom2', 22))
Traceback (most recent call last):File "/Users/quyixiao/pp/python_lesson/lean/EchoServer.py", line 6, in <module>with conn as cursor:^^^^File "/Users/quyixiao/pp/python_lesson/.venv/lib/python3.13/site-packages/pymysql/connections.py", line 368, in __exit__self.close()~~~~~~~~~~^^File "/Users/quyixiao/pp/python_lesson/.venv/lib/python3.13/site-packages/pymysql/connections.py", line 414, in closeraise err.Error("Already closed")
pymysql.err.Error: Already closed
通过上面的实验,我们应该知道,连接应该不需要反反复复创建销毁,应该是多个cursor共享一个conn。
元编程
元编程概念来自LISP和smalltalk。
我们写程序是直接写代码,是否能够用代码来生成未来我们需要的代码吗?这就是元编程
用来生成代码的程序称为元程序metaprogram,编写这种程序就称为元编程metaprogramming
Python语言能够通过反射实现元编程。
type类
class type(object):def __init__(cls, what, bases=None, dict=None): # known special case of type.__init_"""type(object_or_name, bases, dict)type(object) -> the object's typetype(name, bases, dict) -> a new type# (copied from class doc)"""passtype(object) -> the object’s type,返回对象的类型,例如 type(10)
type(name,bases,dict) -> a new type 返回一个新的类型
XClass = type('myclass', (object,), {'a': 100, 'b': 'string'})
print(XClass) # <class '__main__.myclass'>
print(XClass.__dict__) # {'a': 100, 'b': 'string', '__module__': '__main__', '__dict__': <attribute '__dict__' of 'myclass' objects>, '__weakref__': <attribute '__weakref__' of 'myclass' objects>, '__doc__': None}
print(XClass.__name__) # myclass
print(XClass.__bases__) # (<class 'object'>,)
print(XClass.mro()) #[<class '__main__.myclass'>, <class 'object'>]可以借助type构造任何类,用代码来生成代码,这就是元编程。
换一种写法,可以使用继承type的方法
class ModelMeta(type):def __new__(cls, *args, **kwargs):print(cls)print(args)print(kwargs)return super().__new__(cls, *args, **kwargs)继承自type,相当于 ModeIMeta = type("ModeIMeta’, bases, dict)
可以认为ModelMeta就是元类,它可以创建出类。
class ModelMeta1(type): # #*#typedef __new__(cls, *args, **kwargs):print('a',cls)print('b',args)print('c',kwargs, **kwargs)return super().__new__(cls, *args, **kwargs)# 第一种 使用metaclass关键字参数指定元类
class A(metaclass=ModelMeta1):id = 100def __init__(self):print('~~A.init~')# 第二种 B继承自A后,依然是从ModeIMeta的类型
class B(A):def __init__(self):print('~~B.init~~')# 第三种 元类就可以使用下面的方式创建新的类
D = ModelMeta1('D', (), {})# C、E是type的实例
class C: pass # C = type('C', (), (})E = type('E', (), {})class F(ModelMeta1): passprint('~' * 30)
print(1,type(A)) # <class '__main__.ModelMeta1'>
print(2,type(B)) # <class '__main__.ModelMeta1'>
print(3,type(D)) # <class '__main__.ModelMeta1'>
print(4,type(C)) # <class 'type'>
print(5,type(E)) # <class 'type'>
print(6,type(F)) # <class 'type'>
输出:
a <class '__main__.ModelMeta1'>
b ('A', (), {'__module__': '__main__', '__qualname__': 'A', '__firstlineno__': 10, 'id': 100, '__init__': <function A.__init__ at 0x102357ec0>, '__static_attributes__': ()})
c {}
a <class '__main__.ModelMeta1'>
b ('B', (<class '__main__.A'>,), {'__module__': '__main__', '__qualname__': 'B', '__firstlineno__': 18, '__init__': <function B.__init__ at 0x102410040>, '__static_attributes__': ()})
c {}
a <class '__main__.ModelMeta1'>
b ('D', (), {})
c {}
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
1 <class '__main__.ModelMeta1'>
2 <class '__main__.ModelMeta1'>
3 <class '__main__.ModelMeta1'>
4 <class 'type'>
5 <class 'type'>
6 <class 'type'>
从运行结果还可以分析出__new__(cls, *args, **kwargs):的参数结构,中间是一个元组 (‘A’, (), {‘__module__’: ‘__main__’, ‘__qualname__’: ‘A’, ‘__firstlineno__’: 10, ‘id’: 100, ‘__init__’: <function A.__init__ at 0x102357ec0>, ‘__static_attributes__’: ()}) 对应的(name, bases, dict),修改代码如下
class ModelMeta(type): # 继承自typedef __new__(cls, name, bases, dict):print(cls)print(name)print(bases)print(dict, '--------------------------')return super().__new__(cls, name, bases, dict)元类的应用
class Field:def __init__(self, fieldname=None, pk=False, nullable=True):self.fieldname = fieldnameself.pk = pkself.nullable = nullabledef __repr__(self):return "<Field {}>".format(self.fieldname)class ModelMeta(type): # 继承自typedef __new__(cls, name, bases, attrs: dict):print(cls)print(name)print(bases)print(attrs, '------')if '__tablename__' not in attrs.keys():attrs['__tablename__'] = nameprimarykeys = []for k, v in attrs.items():if isinstance(v, Field):if v.fieldname is None:v.fieldname = k # 没有名字则使用属性名if v.pk:primarykeys.append(v)attrs['__primarykeys__'] = primarykeysreturn super().__new__(cls, name, bases, attrs)class ModelBase(metaclass=ModelMeta):'''从ModelBase继承的类的类型都是ModelMeta'''passclass Student(ModelBase):id = Field(pk=True, nullable=False)name = Field('username', nullable=False)age = Field()print(1,Student.__dict__) # 1 {'__module__': '__main__', '__firstlineno__': 39, 'id': <Field id>, 'name': <Field username>, 'age': <Field age>, '__static_attributes__': (), '__tablename__': 'Student', '__primarykeys__': [<Field id>], '__doc__': None}输出:
<class '__main__.ModelMeta'>
ModelBase
()
{'__module__': '__main__', '__qualname__': 'ModelBase', '__firstlineno__': 34, '__doc__': '从ModelBase继承的类的类型都是ModelMeta', '__static_attributes__': ()} ------
<class '__main__.ModelMeta'>
Student
(<class '__main__.ModelBase'>,)
{'__module__': '__main__', '__qualname__': 'Student', '__firstlineno__': 39, 'id': <Field None>, 'name': <Field username>, 'age': <Field None>, '__static_attributes__': ()} ------
1 {'__module__': '__main__', '__firstlineno__': 39, 'id': <Field id>, 'name': <Field username>, 'age': <Field age>, '__static_attributes__': (), '__tablename__': 'Student', '__primarykeys__': [<Field id>], '__doc__': None}元编程总结
元类是制造类的工厂,是生成类的类。
定义一个元类,需要使用type(name, bases, dict),也可以继承type。
构造好元类,就可以在类定义是使用关键字参数metaclass指定元类,可以使用最原始的metatype(name, bases,dict)的方式构造一个类。
元类的__new__()方法中,可以获取元类信息、当前类、基类、类属性字典。
元编程一般用于框架开发中。
开发中除非你明确的知道自己在干什么,否则不要随便使用元编程
99%的情况下用不到元类,可能有些程序员一辈子都不会使用元类
Django、SQLAlchemy使用了元类,让我们使用起来很方便。
SQLAlchemy
SQLAlchemy是一个ORM框架
大量使用了元编程
安装
$ pip3 install sqlalchemy
文档
官方文档
http://docs.sqlalchemy.org/en/latest/
import sqlalchemyprint(sqlalchemy.__version__)输出:
2.0.41开发
SQLAlchemy内部使用了连接池
创建连接
数据库连接的事情,交给引擎
# mysqldb的连接
# mysql+mysqldb://<user>: ‹password>@<host>[: <port>]/<dbname>
engine = sqlalchemy.create_engine("mysql+mysqldb://wayne:wayne@127.0.0.1:3306/magedu")
# pymysql的连接
# mysql+pymysql: //<username>: <password>@<host>/<dbname>[?<options>]
engine = sqlalchemy.create_engine("mysql+pymysql://wayne:wayne@127.0.0.1:3306/magedu")
engine = sqlalchemy create_engine("mysql+pymysql://wayne:wayne@127.0.0.1:3306/magedu",
echo=True)echo=True
引擎是否打印执行的语句,调试的时候打开很方便。
Declare a Mapping创建映射
创建基类
from sqlalchemy.ext.declarative import declarative_base
# 创建基类,便于实体类继承
Base = declarative_base()
创建实体类
student表
CREATE TABLE `student` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(255) NOT NULL,`age` int DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=42 DEFAULT CHARSET=utf8mb3;
# 创建实体类
class Student(Base):# 指定表名__tablename__ = 'student'# 定义属性对应字段id = Column(Integer, primary_key=True)name = Column(String(64))age = Column(Integer)# 第一参数是字段名,如果和属性名不一致,一定要指定# age = Column ('age', Integer)def __repr__(self):return "{} id={} name={} age={}".format(self.__class__.__name__, self.id, self.name, self.age)__tablename__ 指定表名
Column类指定对应的字段,必须指定
实例化
s = Student (name=‘tom’ )
print(s. name)
s.age = 20
print(s.age)
创建表
可以使用SQLAlchemy来创建、删除表
# 删除继承自Base的所有表
Base.metadata.drop_all(engine)
# 创建继承自Base的所有表
Base.metadata.create_all(engine)
生产环境很少这样创建表,都是系统上线的时候由脚本生成。
生成环境很少删除表,宁可废弃都不能删除。
创建会话session
在一个会话中操作数据库,会话建立在连接上,连接被引擎管理。
# 创建session
Session = sessionmaker(bind=engine)# 返回类
session = Session()# 实例化
session对象线程不安全。所以不同线程使用不用的session对象。
Session类和engine都是线程安全的,有一个就行了。
CRUD操作
增
import sqlalchemy
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmakerhost = '127.0.0.1'
user = 'iowiewoiii'
password = 'iewiewio^#8^f!2'
port = 3306
database = 'iewoiew'
conn_str = "mysql+pymysql://{}:{}@{}:{}/{}".format(user, password, host, port, database)
engine = sqlalchemy.create_engine(conn_str, echo=True)
# 创建基类
Base = declarative_base()# 创建实体类
class Student(Base):# 指定表名__tablename__ = 'student'# 定义属性对应字段id = Column(Integer, primary_key=True)name = Column(String(64), nullable=False)age = Column(Integer)# 第一参数是字段名,如果和属性名不一致,一定要指定# age = Column ('age', Integer)def __repr__(self):return "{} id={} name={} age={}".format(self.__class__.__name__, self.id, self.name, self.age)s = Student(name='tom') # 构造的时候传入
print(s.name)
s.age = 20 # 属性賦値
print(s.age)## 删除继承自Base的所有表
# Base.metadata.drop_all(engine)
## 创建继承自Base的所有表
# Base.metadata.create_all(engine)
# 创建sessionSession = sessionmaker(bind=engine)
session = Session()
session.add(s)
print(s)
session.commit()print(s)print('~~~~~~~~~~~~~~~~~~~~~~~~~~~ ')
try:session.add_all([s])print(s)session.commit() # 提交能够成功吗print(s)
except:session.rollback()raise输出:
tom
20
Student id=None name=tom age=20
/Users/quyixiao/pp/python_lesson/lean/testclinet.py:16: MovedIn20Warning: The ``declarative_base()`` function is now available as sqlalchemy.orm.declarative_base(). (deprecated since: 2.0) (Background on SQLAlchemy 2.0 at: https://sqlalche.me/e/b8d9)Base = declarative_base()
2025-07-21 09:03:14,360 INFO sqlalchemy.engine.Engine SELECT DATABASE()
2025-07-21 09:03:14,360 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-07-21 09:03:14,406 INFO sqlalchemy.engine.Engine SELECT @@sql_mode
2025-07-21 09:03:14,406 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-07-21 09:03:14,430 INFO sqlalchemy.engine.Engine SELECT @@lower_case_table_names
2025-07-21 09:03:14,430 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-07-21 09:03:14,470 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2025-07-21 09:03:14,472 INFO sqlalchemy.engine.Engine INSERT INTO student (name, age) VALUES (%(name)s, %(age)s)
2025-07-21 09:03:14,472 INFO sqlalchemy.engine.Engine [generated in 0.00012s] {'name': 'tom', 'age': 20}
2025-07-21 09:03:14,505 INFO sqlalchemy.engine.Engine COMMIT
2025-07-21 09:03:14,551 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2025-07-21 09:03:14,555 INFO sqlalchemy.engine.Engine SELECT student.id AS student_id, student.name AS student_name, student.age AS student_age
FROM student
WHERE student.id = %(pk_1)s
2025-07-21 09:03:14,555 INFO sqlalchemy.engine.Engine [generated in 0.00024s] {'pk_1': 43}
Student id=43 name=tom age=20
~~~~~~~~~~~~~~~~~~~~~~~~~~~
Student id=43 name=tom age=20
2025-07-21 09:03:14,577 INFO sqlalchemy.engine.Engine COMMIT
2025-07-21 09:03:14,620 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2025-07-21 09:03:14,621 INFO sqlalchemy.engine.Engine SELECT student.id AS student_id, student.name AS student_name, student.age AS student_age
FROM student
WHERE student.id = %(pk_1)s
2025-07-21 09:03:14,621 INFO sqlalchemy.engine.Engine [cached since 0.06615s ago] {'pk_1': 43}
Student id=43 name=tom age=20
add_all()方法不会提交成功的,不是因为它不对,而是s,S成功提交后,s的主键就有了值,所以,只要s没有修改过,就认为没有改动。如下,s变化了,就可以提交修改了。
s.name = 'jerry’# 修改
session.add_all([s])
s主键没有值,就是新增;主键有值,就是找到主键对应的记录修改。
简单查询
使用query0方法,返回一个Query对象
students = session.query(Student)# 无条件
for student in students:print(student)print('~~~~~~~~~~~~~~~~~~~~~~~~~~~')
student = session.query(Student).get(2) #
print(student)
query方法将实体类传入,返回类的对象可迭代对象,这时候并不查询。迭代它就执行SQL来查询数据库,封装数据到指定类的实例。
get方法使用主键查询,返回一条传入类的一个实例。
改
student = session.query(Student).get (2)
print(student)
student. name = 'sam'
student.age = 30
print(student)
session. add (student)
session.commit()
先查回来,修改后,再提交更改。
删除
先看下数据库,表中有
1 tom 20
2 sam 30
3 20 jerry
4 ben 20
5 ben 20
编写如下程序来删除数据,会发生什么?
try:name = "sam"student = Student(id=2, age=30)session.delete(student)session.commit()
except Exception as e:session.rollback()print('~~~~~~~~~~~~~~~~~~~~')print(e)
会产生一个异常
Instance '<Student at ex3e654e@>'is not persisted 未持久的异常!
状态**
每一个实体,都有一个状态属性_sa_instance_state,其类型是sqlalchemy.orm.state.InstanceState,可以使用
sqlalchemy.inspect(entity) 函数查看状态。
常见的状态值有transient.pending、persistent, deleted. detached.
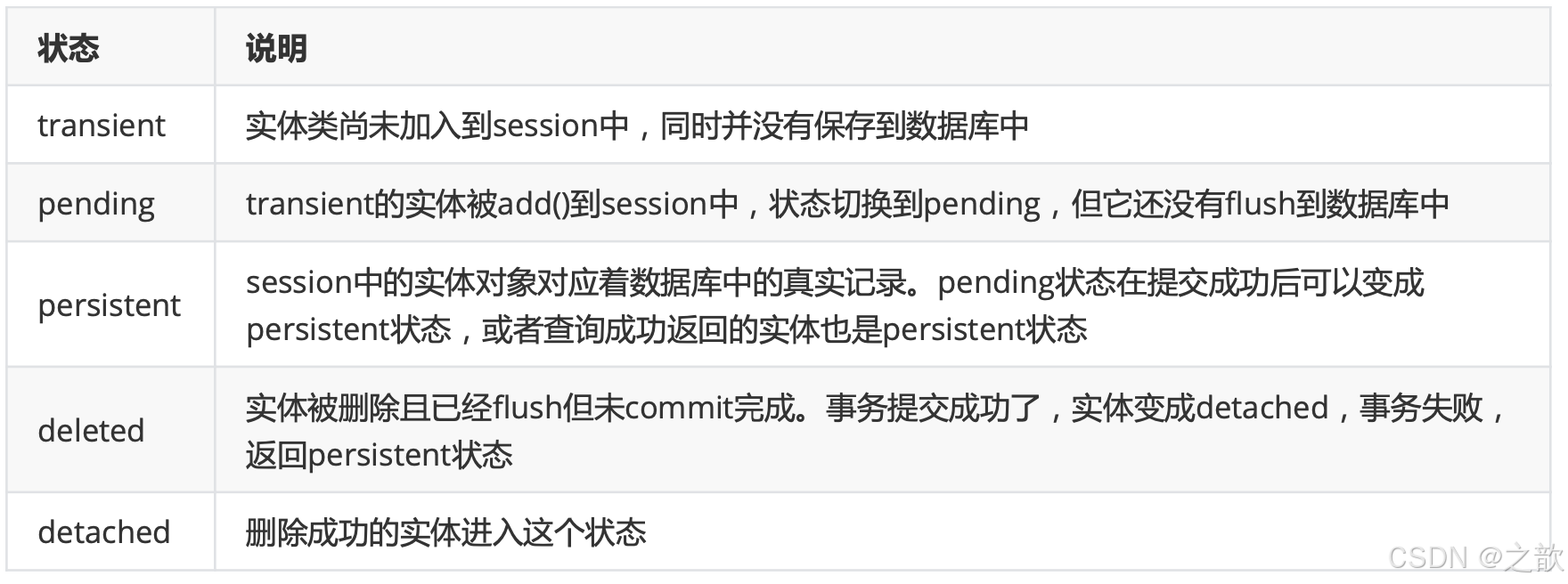
新建一个实体,状态是transient时的。
一旦add()后从transient变成pending状态。
成功commit() 后从pending变成persistent状态。
成功查询返回的实体对象,也是persistent状态。
persistent状态的实体,修改依然是persistent状态。
persistent状态的实体,删除后,flush后但没有commit,就变成deteled状态,成功提交,变为detached状态,
提交失败,还原到persistent状态。flush方法,主动把改变应用到数据库中去。删除、修改操作,需要对应一个真实的记录,所以要求实体对象是persistent状态。
import sqlalchemy
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmakerhost = '127.0.0.1'
user = 'iweoiew'
password = 'ioewie^#8^f!2'
port = 3306
database = 'ioewoiewiowei'
connstr = "mysql+pymysql://{}:{}@{}:{}/{}".format(user, password, host, port, database)engine = create_engine(connstr, echo=True)
Base = declarative_base()# 创建实体类
class Student(Base):# 指定表名__tablename__ = 'student'# 定义属性对应字段id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(64), nullable=False)age = Column(Integer)# 第一参数是字段名,如果和属性名不一致,则一定要指定# age = Column ('age', Integer)def __repr__(self):return "{} id={} name={} age={}".format(self.__class__.__name__, self.id, self.name, self.age)Session = sessionmaker(bind=engine)
session = Session()from sqlalchemy.orm.state import InstanceStatedef getstate(entity, i):insp = sqlalchemy.inspect(entity)state = "sessionid={}, attached={}\ntransient={}, persistent={}\npending={}, deleted={},detached={}".format(insp.session_id,insp._attached,insp.transient,insp.persistent,insp.pending,insp.deleted,insp.detached)print(i, state)print(insp.key)print('-' * 30)student = session.query(Student).get(2)getstate(student, 1) # persistenttry:student = Student(id=2, name="sam", age=30)getstate(student, 2) # transitstudent = Student(name="sammy", age=30)getstate(student, 3) # transitsession.add(student) # add后变成pendinggetstate(student, 4) # pending# session.delete(student)# 删除的前提是persistent,否则抛异常# getstate(student, 5)session.commit()getstate(student, 6) # persistent
except Exception as e:session.rollback()print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~')print(e)输出:
2025-07-21 09:21:56,332 INFO sqlalchemy.engine.Engine SELECT DATABASE()
2025-07-21 09:21:56,332 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-07-21 09:21:56,387 INFO sqlalchemy.engine.Engine SELECT @@sql_mode
2025-07-21 09:21:56,387 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-07-21 09:21:56,423 INFO sqlalchemy.engine.Engine SELECT @@lower_case_table_names
2025-07-21 09:21:56,423 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-07-21 09:21:56,486 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2025-07-21 09:21:56,487 INFO sqlalchemy.engine.Engine SELECT student.id AS student_id, student.name AS student_name, student.age AS student_age
FROM student
WHERE student.id = %(pk_1)s
2025-07-21 09:21:56,487 INFO sqlalchemy.engine.Engine [generated in 0.00010s] {'pk_1': 2}
1 sessionid=1, attached=True
transient=False, persistent=True
pending=False, deleted=False,detached=False
(<class '__main__.Student'>, (2,), None)
------------------------------
2 sessionid=None, attached=False
transient=True, persistent=False
pending=False, deleted=False,detached=False
None
------------------------------
3 sessionid=None, attached=False
transient=True, persistent=False
pending=False, deleted=False,detached=False
None
------------------------------
4 sessionid=1, attached=True
transient=False, persistent=False
pending=True, deleted=False,detached=False
None
------------------------------
2025-07-21 09:21:56,513 INFO sqlalchemy.engine.Engine INSERT INTO student (name, age) VALUES (%(name)s, %(age)s)
2025-07-21 09:21:56,513 INFO sqlalchemy.engine.Engine [generated in 0.00008s] {'name': 'sammy', 'age': 30}
2025-07-21 09:21:56,541 INFO sqlalchemy.engine.Engine COMMIT
6 sessionid=1, attached=True
transient=False, persistent=True
pending=False, deleted=False,detached=False
(<class '__main__.Student'>, (44,), None)
------------------------------
上面数据库中的数据记录多于3条。
import sqlalchemy
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmakerhost = '127.0.0.1'
user = '3232'
password = '2^32328^f!2'
port = 3306
database = '32'connstr = "mysql+pymysql://{}:{}@{}:{}/{}".format(user, password, host, port, database)engine = create_engine(connstr, echo=True)
Base = declarative_base()# 创建实体类
class Student(Base):# 指定表名__tablename__ = 'student'# 定义属性对应字段id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(64), nullable=False)age = Column(Integer)# 第一参数是字段名,如果和属性名不一致,则一定要指定# age = Column ('age', Integer)def __repr__(self):return "{} id={} name={} age={}".format(self.__class__.__name__, self.id, self.name, self.age)Session = sessionmaker(bind=engine)
session = Session()from sqlalchemy.orm.state import InstanceStatedef getstate(entity, i):insp = sqlalchemy.inspect(entity)state = "sessionid={}, attached={}\ntransient={}, persistent={}\npending={}, deleted={},detached={}".format(insp.session_id,insp._attached,insp.transient,insp.persistent,insp.pending,insp.deleted,insp.detached)print(i, state)print(insp.key)print('-' * 30)student = session.query(Student).get(2)
getstate(student, 10) # persistent
try:session.delete(student) # 删除的前提是persistentgetstate(student, 11) # persistentsession.flush()getstate(student, 12) # deletedsession.commit()getstate(student, 13) # persistent
except Exception as e:session.rollback()print('~~~~~~~~~~~~~~~~~~~~~~~~~')print(e)输出:
2025-07-21 09:24:37,658 INFO sqlalchemy.engine.Engine SELECT DATABASE()
2025-07-21 09:24:37,658 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-07-21 09:24:37,704 INFO sqlalchemy.engine.Engine SELECT @@sql_mode
2025-07-21 09:24:37,705 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-07-21 09:24:37,728 INFO sqlalchemy.engine.Engine SELECT @@lower_case_table_names
2025-07-21 09:24:37,728 INFO sqlalchemy.engine.Engine [raw sql] {}
2025-07-21 09:24:37,786 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2025-07-21 09:24:37,788 INFO sqlalchemy.engine.Engine SELECT student.id AS student_id, student.name AS student_name, student.age AS student_age
FROM student
WHERE student.id = %(pk_1)s
2025-07-21 09:24:37,788 INFO sqlalchemy.engine.Engine [generated in 0.00008s] {'pk_1': 2}
10 sessionid=1, attached=True
transient=False, persistent=True
pending=False, deleted=False,detached=False
(<class '__main__.Student'>, (2,), None)
------------------------------
11 sessionid=1, attached=True
transient=False, persistent=True
pending=False, deleted=False,detached=False
(<class '__main__.Student'>, (2,), None)
------------------------------
2025-07-21 09:24:37,809 INFO sqlalchemy.engine.Engine DELETE FROM student WHERE student.id = %(id)s
2025-07-21 09:24:37,809 INFO sqlalchemy.engine.Engine [generated in 0.00008s] {'id': 2}
12 sessionid=1, attached=True
transient=False, persistent=False
pending=False, deleted=True,detached=False
(<class '__main__.Student'>, (2,), None)
------------------------------
2025-07-21 09:24:37,828 INFO sqlalchemy.engine.Engine COMMIT
13 sessionid=None, attached=False
transient=False, persistent=False
pending=False, deleted=False,detached=True
(<class '__main__.Student'>, (2,), None)
------------------------------
/*
Create By WayneSource Server : python
Source Server Version : 50545
Source Host : 192.168.142.135:3306
Source Database : testTarget Server Type : MYSQL
Target Server Version : 50545
File Encoding : 65001Date: 2017-10-01 20:27:47http://www.magedu.com
*/
DROP DATABASE IF EXISTS test;
CREATE DATABASE IF NOT EXISTS test CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
USE test;SET FOREIGN_KEY_CHECKS=0;-- ----------------------------
-- Table structure for departments
-- ----------------------------
DROP TABLE IF EXISTS `departments`;
CREATE TABLE `departments` (`dept_no` char(4) NOT NULL,`dept_name` varchar(40) NOT NULL,PRIMARY KEY (`dept_no`),UNIQUE KEY `dept_name` (`dept_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- ----------------------------
-- Records of departments
-- ----------------------------
INSERT INTO `departments` VALUES ('d009', 'Customer Service');
INSERT INTO `departments` VALUES ('d005', 'Development');
INSERT INTO `departments` VALUES ('d002', 'Finance');
INSERT INTO `departments` VALUES ('d003', 'Human Resources');
INSERT INTO `departments` VALUES ('d001', 'Marketing');
INSERT INTO `departments` VALUES ('d004', 'Production');
INSERT INTO `departments` VALUES ('d006', 'Quality Management');
INSERT INTO `departments` VALUES ('d008', 'Research');
INSERT INTO `departments` VALUES ('d007', 'Sales');-- ----------------------------
-- Table structure for dept_emp
-- ----------------------------
DROP TABLE IF EXISTS `dept_emp`;
CREATE TABLE `dept_emp` (`emp_no` int(11) NOT NULL,`dept_no` char(4) NOT NULL,`from_date` date NOT NULL,`to_date` date NOT NULL,PRIMARY KEY (`emp_no`,`dept_no`),KEY `dept_no` (`dept_no`),CONSTRAINT `dept_emp_ibfk_1` FOREIGN KEY (`emp_no`) REFERENCES `employees` (`emp_no`) ON DELETE CASCADE,CONSTRAINT `dept_emp_ibfk_2` FOREIGN KEY (`dept_no`) REFERENCES `departments` (`dept_no`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- ----------------------------
-- Records of dept_emp
-- ----------------------------
INSERT INTO `dept_emp` VALUES ('10001', 'd005', '1986-06-26', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10002', 'd007', '1996-08-03', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10003', 'd004', '1995-12-03', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10004', 'd004', '1986-12-01', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10005', 'd003', '1989-09-12', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10006', 'd005', '1990-08-05', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10007', 'd008', '1989-02-10', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10008', 'd005', '1998-03-11', '2000-07-31');
INSERT INTO `dept_emp` VALUES ('10009', 'd006', '1985-02-18', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10010', 'd004', '1996-11-24', '2000-06-26');
INSERT INTO `dept_emp` VALUES ('10010', 'd006', '2000-06-26', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10011', 'd009', '1990-01-22', '1996-11-09');
INSERT INTO `dept_emp` VALUES ('10012', 'd005', '1992-12-18', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10013', 'd003', '1985-10-20', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10014', 'd005', '1993-12-29', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10015', 'd008', '1992-09-19', '1993-08-22');
INSERT INTO `dept_emp` VALUES ('10016', 'd007', '1998-02-11', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10017', 'd001', '1993-08-03', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10018', 'd004', '1992-07-29', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10018', 'd005', '1987-04-03', '1992-07-29');
INSERT INTO `dept_emp` VALUES ('10019', 'd008', '1999-04-30', '9999-01-01');
INSERT INTO `dept_emp` VALUES ('10020', 'd004', '1997-12-30', '9999-01-01');-- ----------------------------
-- Table structure for employees
-- ----------------------------
DROP TABLE IF EXISTS `employees`;
CREATE TABLE `employees` (`emp_no` int(11) NOT NULL,`birth_date` date NOT NULL,`first_name` varchar(14) NOT NULL,`last_name` varchar(16) NOT NULL,`gender` enum('M','F') NOT NULL,`hire_date` date NOT NULL,PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- ----------------------------
-- Records of employees
-- ----------------------------
INSERT INTO `employees` VALUES ('10001', '1953-09-02', 'Georgi', 'Facello', 'M', '1986-06-26');
INSERT INTO `employees` VALUES ('10002', '1964-06-02', 'Bezalel', 'Simmel', 'F', '1985-11-21');
INSERT INTO `employees` VALUES ('10003', '1959-12-03', 'Parto', 'Bamford', 'M', '1986-08-28');
INSERT INTO `employees` VALUES ('10004', '1954-05-01', 'Chirstian', 'Koblick', 'M', '1986-12-01');
INSERT INTO `employees` VALUES ('10005', '1955-01-21', 'Kyoichi', 'Maliniak', 'M', '1989-09-12');
INSERT INTO `employees` VALUES ('10006', '1953-04-20', 'Anneke', 'Preusig', 'F', '1989-06-02');
INSERT INTO `employees` VALUES ('10007', '1957-05-23', 'Tzvetan', 'Zielinski', 'F', '1989-02-10');
INSERT INTO `employees` VALUES ('10008', '1958-02-19', 'Saniya', 'Kalloufi', 'M', '1994-09-15');
INSERT INTO `employees` VALUES ('10009', '1952-04-19', 'Sumant', 'Peac', 'F', '1985-02-18');
INSERT INTO `employees` VALUES ('10010', '1963-06-01', 'Duangkaew', 'Piveteau', 'F', '1989-08-24');
INSERT INTO `employees` VALUES ('10011', '1953-11-07', 'Mary', 'Sluis', 'F', '1990-01-22');
INSERT INTO `employees` VALUES ('10012', '1960-10-04', 'Patricio', 'Bridgland', 'M', '1992-12-18');
INSERT INTO `employees` VALUES ('10013', '1963-06-07', 'Eberhardt', 'Terkki', 'M', '1985-10-20');
INSERT INTO `employees` VALUES ('10014', '1956-02-12', 'Berni', 'Genin', 'M', '1987-03-11');
INSERT INTO `employees` VALUES ('10015', '1959-08-19', 'Guoxiang', 'Nooteboom', 'M', '1987-07-02');
INSERT INTO `employees` VALUES ('10016', '1961-05-02', 'Kazuhito', 'Cappelletti', 'M', '1995-01-27');
INSERT INTO `employees` VALUES ('10017', '1958-07-06', 'Cristinel', 'Bouloucos', 'F', '1993-08-03');
INSERT INTO `employees` VALUES ('10018', '1954-06-19', 'Kazuhide', 'Peha', 'F', '1987-04-03');
INSERT INTO `employees` VALUES ('10019', '1953-01-23', 'Lillian', 'Haddadi', 'M', '1999-04-30');
INSERT INTO `employees` VALUES ('10020', '1952-12-24', 'Mayuko', 'Warwick', 'M', '1991-01-26');-- ----------------------------
-- Table structure for salaries
-- ----------------------------
DROP TABLE IF EXISTS `salaries`;
CREATE TABLE `salaries` (`emp_no` int(11) NOT NULL,`salary` int(11) NOT NULL,`from_date` date NOT NULL,`to_date` date NOT NULL,PRIMARY KEY (`emp_no`,`from_date`),CONSTRAINT `salaries_ibfk_1` FOREIGN KEY (`emp_no`) REFERENCES `employees` (`emp_no`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- ----------------------------
-- Records of salaries
-- ----------------------------
INSERT INTO `salaries` VALUES ('10001', '60117', '1986-06-26', '1987-06-26');
INSERT INTO `salaries` VALUES ('10001', '62102', '1987-06-26', '1988-06-25');
INSERT INTO `salaries` VALUES ('10001', '66074', '1988-06-25', '1989-06-25');
INSERT INTO `salaries` VALUES ('10001', '66596', '1989-06-25', '1990-06-25');
INSERT INTO `salaries` VALUES ('10001', '66961', '1990-06-25', '1991-06-25');
INSERT INTO `salaries` VALUES ('10001', '71046', '1991-06-25', '1992-06-24');
INSERT INTO `salaries` VALUES ('10001', '74333', '1992-06-24', '1993-06-24');
INSERT INTO `salaries` VALUES ('10001', '75286', '1993-06-24', '1994-06-24');
INSERT INTO `salaries` VALUES ('10001', '75994', '1994-06-24', '1995-06-24');
INSERT INTO `salaries` VALUES ('10001', '76884', '1995-06-24', '1996-06-23');
INSERT INTO `salaries` VALUES ('10001', '80013', '1996-06-23', '1997-06-23');
INSERT INTO `salaries` VALUES ('10001', '81025', '1997-06-23', '1998-06-23');
INSERT INTO `salaries` VALUES ('10001', '81097', '1998-06-23', '1999-06-23');
INSERT INTO `salaries` VALUES ('10001', '84917', '1999-06-23', '2000-06-22');
INSERT INTO `salaries` VALUES ('10001', '85112', '2000-06-22', '2001-06-22');
INSERT INTO `salaries` VALUES ('10001', '85097', '2001-06-22', '2002-06-22');
INSERT INTO `salaries` VALUES ('10001', '88958', '2002-06-22', '9999-01-01');
INSERT INTO `salaries` VALUES ('10002', '65828', '1996-08-03', '1997-08-03');
INSERT INTO `salaries` VALUES ('10002', '65909', '1997-08-03', '1998-08-03');
INSERT INTO `salaries` VALUES ('10002', '67534', '1998-08-03', '1999-08-03');
INSERT INTO `salaries` VALUES ('10002', '69366', '1999-08-03', '2000-08-02');
INSERT INTO `salaries` VALUES ('10002', '71963', '2000-08-02', '2001-08-02');
INSERT INTO `salaries` VALUES ('10002', '72527', '2001-08-02', '9999-01-01');
INSERT INTO `salaries` VALUES ('10003', '40006', '1995-12-03', '1996-12-02');
INSERT INTO `salaries` VALUES ('10003', '43616', '1996-12-02', '1997-12-02');
INSERT INTO `salaries` VALUES ('10003', '43466', '1997-12-02', '1998-12-02');
INSERT INTO `salaries` VALUES ('10003', '43636', '1998-12-02', '1999-12-02');
INSERT INTO `salaries` VALUES ('10003', '43478', '1999-12-02', '2000-12-01');
INSERT INTO `salaries` VALUES ('10003', '43699', '2000-12-01', '2001-12-01');
INSERT INTO `salaries` VALUES ('10003', '43311', '2001-12-01', '9999-01-01');
INSERT INTO `salaries` VALUES ('10004', '40054', '1986-12-01', '1987-12-01');
INSERT INTO `salaries` VALUES ('10004', '42283', '1987-12-01', '1988-11-30');
INSERT INTO `salaries` VALUES ('10004', '42542', '1988-11-30', '1989-11-30');
INSERT INTO `salaries` VALUES ('10004', '46065', '1989-11-30', '1990-11-30');
INSERT INTO `salaries` VALUES ('10004', '48271', '1990-11-30', '1991-11-30');
INSERT INTO `salaries` VALUES ('10004', '50594', '1991-11-30', '1992-11-29');
INSERT INTO `salaries` VALUES ('10004', '52119', '1992-11-29', '1993-11-29');
INSERT INTO `salaries` VALUES ('10004', '54693', '1993-11-29', '1994-11-29');
INSERT INTO `salaries` VALUES ('10004', '58326', '1994-11-29', '1995-11-29');
INSERT INTO `salaries` VALUES ('10004', '60770', '1995-11-29', '1996-11-28');-- ----------------------------
-- Table structure for titles
-- ----------------------------
DROP TABLE IF EXISTS `titles`;
CREATE TABLE `titles` (`emp_no` int(11) NOT NULL,`title` varchar(50) NOT NULL,`from_date` date NOT NULL,`to_date` date DEFAULT NULL,PRIMARY KEY (`emp_no`,`title`,`from_date`),CONSTRAINT `titles_ibfk_1` FOREIGN KEY (`emp_no`) REFERENCES `employees` (`emp_no`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- ----------------------------
-- Records of titles
-- ----------------------------
INSERT INTO `titles` VALUES ('10001', 'Senior Engineer', '1986-06-26', '9999-01-01');
INSERT INTO `titles` VALUES ('10002', 'Staff', '1996-08-03', '9999-01-01');
INSERT INTO `titles` VALUES ('10003', 'Senior Engineer', '1995-12-03', '9999-01-01');
INSERT INTO `titles` VALUES ('10004', 'Engineer', '1986-12-01', '1995-12-01');
INSERT INTO `titles` VALUES ('10004', 'Senior Engineer', '1995-12-01', '9999-01-01');
INSERT INTO `titles` VALUES ('10005', 'Senior Staff', '1996-09-12', '9999-01-01');
INSERT INTO `titles` VALUES ('10005', 'Staff', '1989-09-12', '1996-09-12');
INSERT INTO `titles` VALUES ('10006', 'Senior Engineer', '1990-08-05', '9999-01-01');
INSERT INTO `titles` VALUES ('10007', 'Senior Staff', '1996-02-11', '9999-01-01');
INSERT INTO `titles` VALUES ('10007', 'Staff', '1989-02-10', '1996-02-11');
INSERT INTO `titles` VALUES ('10008', 'Assistant Engineer', '1998-03-11', '2000-07-31');
INSERT INTO `titles` VALUES ('10009', 'Assistant Engineer', '1985-02-18', '1990-02-18');
INSERT INTO `titles` VALUES ('10009', 'Engineer', '1990-02-18', '1995-02-18');
INSERT INTO `titles` VALUES ('10009', 'Senior Engineer', '1995-02-18', '9999-01-01');
INSERT INTO `titles` VALUES ('10010', 'Engineer', '1996-11-24', '9999-01-01');
INSERT INTO `titles` VALUES ('10011', 'Staff', '1990-01-22', '1996-11-09');
INSERT INTO `titles` VALUES ('10012', 'Engineer', '1992-12-18', '2000-12-18');
INSERT INTO `titles` VALUES ('10012', 'Senior Engineer', '2000-12-18', '9999-01-01');
INSERT INTO `titles` VALUES ('10013', 'Senior Staff', '1985-10-20', '9999-01-01');
INSERT INTO `titles` VALUES ('10014', 'Engineer', '1993-12-29', '9999-01-01');
INSERT INTO `titles` VALUES ('10015', 'Senior Staff', '1992-09-19', '1993-08-22');复杂查询
实体类
import sqlalchemy
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmakerfrom sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Date, Enum, ForeignKey, create_engine
from sqlalchemy.orm import sessionmaker
import enumhost = '127.0.0.1'
user = '3232'
password = '2333232^#8^f!2'
port = 3306
database = '323232'connstr = "mysql+pymysql://{}:{}@{}:{}/{}".format(user, password, host, port, database)Base = declarative_base()engine = create_engine(connstr, echo=True)Session = sessionmaker(bind=engine)
session = Session()class MyEnum(enum.Enum):M = 'M'F = 'F'class Employee(Base):# 指定表名__tablename__ = 'employees'# 定义属性对应字段emp_no = Column(Integer, primary_key=True)birth_date = Column(Date, nullable=False)first_name = Column(String(14), nullable=False)last_name = Column(String(16), nullable=False)gender = Column(Enum(MyEnum), nullable=False)hire_date = Column(Date, nullable=False)def __repr__(self):return "{} no={} name={} {} gender={}".format(self.__class__.__name__, self.emp_no, self.first_name,self.last_name,self.gender.value)# 打印函数
def show(emps):for x in emps:print(1,x)print('~' * 30, end='\n\n')# 简单条件查询
emps = session.query(Employee).filter(Employee.emp_no > 10015)show(emps)输出:
2025-07-21 13:01:06,851 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no > %(emp_no_1)s
2025-07-21 13:01:06,851 INFO sqlalchemy.engine.Engine [generated in 0.00012s] {'emp_no_1': 10015}
1 Employee no=10016 name=Kazuhito Cappelletti gender=M
1 Employee no=10017 name=Cristinel Bouloucos gender=F
1 Employee no=10018 name=Kazuhide Peha gender=F
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 与或非
from sqlalchemy import or_, and_, not_# AND 条件
emps = session.query(Employee).filter(Employee.emp_no > 10015).filter(Employee.gender == MyEnum.F)
show(emps)输出:2025-07-21 13:01:56,580 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no > %(emp_no_1)s AND employees.gender = %(gender_1)s
2025-07-21 13:01:56,580 INFO sqlalchemy.engine.Engine [generated in 0.00025s] {'emp_no_1': 10015, 'gender_1': 'F'}
1 Employee no=10017 name=Cristinel Bouloucos gender=F
1 Employee no=10018 name=Kazuhide Peha gender=F
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
emps = session.query(Employee).filter(and_(Employee.emp_no > 10015, Employee.gender == MyEnum.M))
show(emps)输出:
2025-07-21 13:03:43,224 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no > %(emp_no_1)s AND employees.gender = %(gender_1)s
2025-07-21 13:03:43,224 INFO sqlalchemy.engine.Engine [generated in 0.00030s] {'emp_no_1': 10015, 'gender_1': 'M'}
1 Employee no=10016 name=Kazuhito Cappelletti gender=M
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# & 一定要注意&符号两边表达式都要加括号
emps = session.query(Employee).filter((Employee.emp_no > 10015) & (Employee.gender == MyEnum.M))
show(emps)输出:
2025-07-21 13:04:35,065 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no > %(emp_no_1)s AND employees.gender = %(gender_1)s
2025-07-21 13:04:35,065 INFO sqlalchemy.engine.Engine [generated in 0.00027s] {'emp_no_1': 10015, 'gender_1': 'M'}
1 Employee no=10016 name=Kazuhito Cappelletti gender=M
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~# OR 条件
emps = session.query(Employee).filter((Employee.emp_no > 10018) | (Employee.emp_no < 10003))
show(emps)输出:
2025-07-21 13:05:19,619 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no > %(emp_no_1)s OR employees.emp_no < %(emp_no_2)s
2025-07-21 13:05:19,620 INFO sqlalchemy.engine.Engine [generated in 0.00012s] {'emp_no_1': 10018, 'emp_no_2': 10003}
1 Employee no=10001 name=Georgi Facello gender=M
1 Employee no=10002 name=Bezalel Simmel gender=F
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# OR 条件
emps = session.query(Employee).filter(or_(Employee.emp_no > 10018, Employee.emp_no < 10003))
show(emps)输出:
2025-07-21 13:06:03,074 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no > %(emp_no_1)s OR employees.emp_no < %(emp_no_2)s
2025-07-21 13:06:03,074 INFO sqlalchemy.engine.Engine [generated in 0.00018s] {'emp_no_1': 10018, 'emp_no_2': 10003}
1 Employee no=10001 name=Georgi Facello gender=M
1 Employee no=10002 name=Bezalel Simmel gender=F
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Not
emps = session.query(Employee). filter(not_(Employee.emp_no < 10018))
show (emps)输出:
2025-07-21 13:06:40,262 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no >= %(emp_no_1)s
2025-07-21 13:06:40,262 INFO sqlalchemy.engine.Engine [generated in 0.00009s] {'emp_no_1': 10018}
1 Employee no=10018 name=Kazuhide Peha gender=F
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 一定注意要加括号
emps = session.query(Employee).filter(~(Employee.emp_no < 10018))
show(emps)输出:2025-07-21 13:09:07,925 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no >= %(emp_no_1)s
2025-07-21 13:09:07,925 INFO sqlalchemy.engine.Engine [generated in 0.00006s] {'emp_no_1': 10018}
1 Employee no=10018 name=Kazuhide Peha gender=F
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 总之,与或非的运算符&、1、~,一定要在表达式上加上括号
# in
emplist = [10010, 10015, 10018]
emps = session.query(Employee).filter(Employee.emp_no.in_(emplist))
show(emps)输出:
2025-07-21 13:09:54,162 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no IN (%(emp_no_1_1)s, %(emp_no_1_2)s, %(emp_no_1_3)s)
2025-07-21 13:09:54,162 INFO sqlalchemy.engine.Engine [generated in 0.00014s] {'emp_no_1_1': 10010, 'emp_no_1_2': 10015, 'emp_no_1_3': 10018}
1 Employee no=10010 name=Duangkaew Piveteau gender=F
1 Employee no=10015 name=Guoxiang Nooteboom gender=M
1 Employee no=10018 name=Kazuhide Peha gender=F
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~# 总之,与或非的运算符&、1、~,一定要在表达式上加上括号
# in
emplist = [10010, 10015, 10018]
# not in
emps = session. query(Employee).filter(~Employee.emp_no.in_(emplist))
show (emps)
输出:
2025-07-21 13:10:26,743 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE (employees.emp_no NOT IN (%(emp_no_1_1)s, %(emp_no_1_2)s, %(emp_no_1_3)s))
2025-07-21 13:10:26,743 INFO sqlalchemy.engine.Engine [generated in 0.00016s] {'emp_no_1_1': 10010, 'emp_no_1_2': 10015, 'emp_no_1_3': 10018}
1 Employee no=10001 name=Georgi Facello gender=M
1 Employee no=10002 name=Bezalel Simmel gender=F
1 Employee no=10003 name=Parto Bamford gender=M
1 Employee no=10004 name=Chirstian Koblick gender=M
1 Employee no=10005 name=Kyoichi Maliniak gender=M
1 Employee no=10006 name=Anneke Preusig gender=F
1 Employee no=10007 name=Tzvetan Zielinski gender=F
1 Employee no=10008 name=Saniya Kalloufi gender=M
1 Employee no=10009 name=Sumant Peac gender=F
1 Employee no=10011 name=Mary Sluis gender=F
1 Employee no=10012 name=Patricio Bridgland gender=M
1 Employee no=10013 name=Eberhardt Terkki gender=M
1 Employee no=10014 name=Berni Genin gender=M
1 Employee no=10016 name=Kazuhito Cappelletti gender=M
1 Employee no=10017 name=Cristinel Bouloucos gender=F
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# like
emps = session.query(Employee).filter(Employee.last_name.like('P%'))
show(emps)2025-07-21 13:11:02,714 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.last_name LIKE %(last_name_1)s
2025-07-21 13:11:02,714 INFO sqlalchemy.engine.Engine [generated in 0.00009s] {'last_name_1': 'P%'}
1 Employee no=10006 name=Anneke Preusig gender=F
1 Employee no=10009 name=Sumant Peac gender=F
1 Employee no=10010 name=Duangkaew Piveteau gender=F
1 Employee no=10018 name=Kazuhide Peha gender=F
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
ilike可以忽略大小写匹配
排序
# 排序
# 升序
emps = session.query(Employee).filter(Employee.emp_no > 10010).order_by(Employee.emp_no)show(emps)emps = session.query(Employee).filter(Employee.emp_no > 10010).order_by(Employee.emp_no.asc())show(emps)2025-07-21 13:12:19,452 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2025-07-21 13:12:19,455 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no > %(emp_no_1)s ORDER BY employees.emp_no
2025-07-21 13:12:19,455 INFO sqlalchemy.engine.Engine [generated in 0.00012s] {'emp_no_1': 10010}
1 Employee no=10011 name=Mary Sluis gender=F
1 Employee no=10012 name=Patricio Bridgland gender=M
1 Employee no=10013 name=Eberhardt Terkki gender=M
1 Employee no=10014 name=Berni Genin gender=M
1 Employee no=10015 name=Guoxiang Nooteboom gender=M
1 Employee no=10016 name=Kazuhito Cappelletti gender=M
1 Employee no=10017 name=Cristinel Bouloucos gender=F
1 Employee no=10018 name=Kazuhide Peha gender=F
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~2025-07-21 13:12:19,489 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no > %(emp_no_1)s ORDER BY employees.emp_no ASC
2025-07-21 13:12:19,489 INFO sqlalchemy.engine.Engine [generated in 0.00010s] {'emp_no_1': 10010}
1 Employee no=10011 name=Mary Sluis gender=F
1 Employee no=10012 name=Patricio Bridgland gender=M
1 Employee no=10013 name=Eberhardt Terkki gender=M
1 Employee no=10014 name=Berni Genin gender=M
1 Employee no=10015 name=Guoxiang Nooteboom gender=M
1 Employee no=10016 name=Kazuhito Cappelletti gender=M
1 Employee no=10017 name=Cristinel Bouloucos gender=F
1 Employee no=10018 name=Kazuhide Peha gender=F
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~# 降序
emps = session.query(Employee).filter(Employee.emp_no > 10010).order_by(Employee.emp_no.desc())
show(emps)输出:
2025-07-21 13:12:52,437 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no > %(emp_no_1)s ORDER BY employees.emp_no DESC
2025-07-21 13:12:52,437 INFO sqlalchemy.engine.Engine [generated in 0.00010s] {'emp_no_1': 10010}
1 Employee no=10020 name=Mayuko Warwick gender=M
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10018 name=Kazuhide Peha gender=F
1 Employee no=10017 name=Cristinel Bouloucos gender=F
1 Employee no=10016 name=Kazuhito Cappelletti gender=M
1 Employee no=10015 name=Guoxiang Nooteboom gender=M
1 Employee no=10014 name=Berni Genin gender=M
1 Employee no=10013 name=Eberhardt Terkki gender=M
1 Employee no=10012 name=Patricio Bridgland gender=M
1 Employee no=10011 name=Mary Sluis gender=F
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~# 多列排序
emps = session.query(Employee).filter(Employee.emp_no > 10010).order_by(Employee.last_name).order_by(Employee.emp_no.desc())
show(emps)
输出:
2025-07-21 13:13:24,685 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
WHERE employees.emp_no > %(emp_no_1)s ORDER BY employees.last_name, employees.emp_no DESC
2025-07-21 13:13:24,685 INFO sqlalchemy.engine.Engine [generated in 0.00010s] {'emp_no_1': 10010}
1 Employee no=10017 name=Cristinel Bouloucos gender=F
1 Employee no=10012 name=Patricio Bridgland gender=M
1 Employee no=10016 name=Kazuhito Cappelletti gender=M
1 Employee no=10014 name=Berni Genin gender=M
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10015 name=Guoxiang Nooteboom gender=M
1 Employee no=10018 name=Kazuhide Peha gender=F
1 Employee no=10011 name=Mary Sluis gender=F
1 Employee no=10013 name=Eberhardt Terkki gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~分页
# 分页
emps = session.query(Employee).limit(4)
show (emps)输出:
2025-07-21 13:14:01,888 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees LIMIT %(param_1)s
2025-07-21 13:14:01,888 INFO sqlalchemy.engine.Engine [generated in 0.00008s] {'param_1': 4}
1 Employee no=10001 name=Georgi Facello gender=M
1 Employee no=10002 name=Bezalel Simmel gender=F
1 Employee no=10003 name=Parto Bamford gender=M
1 Employee no=10004 name=Chirstian Koblick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 分页
emps = session.query(Employee).limit(4).offset(18)
show (emps)输出:
2025-07-21 13:14:28,986 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees LIMIT %(param_1)s, %(param_2)s
2025-07-21 13:14:28,986 INFO sqlalchemy.engine.Engine [generated in 0.00019s] {'param_1': 18, 'param_2': 4}
1 Employee no=10019 name=Lillian Haddadi gender=M
1 Employee no=10020 name=Mayuko Warwick gender=M
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~消费者方法
消费者方法调用后,Query对象(可迭代)就转换成了一个容器。
# 总行数
emps = session.query(Employee)
print(len(list(emps))) # 返回大量的结果集,然后转换1ist
print(emps.count()) # 聚合函数count(*)的查询
# 取所有数据
print(emps.all()) # 返回列表,查不到返回空列表
# 取首行
print(emps.first()) # 返回首行,查不到返回None
# 有且只能有一行
# print(emps.one())#如果查询结果是多行抛异常
print(emps.limit(1).one())
# 删除 delete by query
session.query(Employee).filter(Employee.emp_no > 10018).delete()
# session.commit()# 提交则删除输出:
2025-07-21 13:16:05,633 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
2025-07-21 13:16:05,633 INFO sqlalchemy.engine.Engine [generated in 0.00021s] {}
20
2025-07-21 13:16:05,674 INFO sqlalchemy.engine.Engine SELECT count(*) AS count_1
FROM (SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees) AS anon_1
2025-07-21 13:16:05,674 INFO sqlalchemy.engine.Engine [generated in 0.00023s] {}
20
2025-07-21 13:16:05,711 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees
2025-07-21 13:16:05,711 INFO sqlalchemy.engine.Engine [cached since 0.07815s ago] {}
[Employee no=10001 name=Georgi Facello gender=M, Employee no=10002 name=Bezalel Simmel gender=F, Employee no=10003 name=Parto Bamford gender=M, Employee no=10004 name=Chirstian Koblick gender=M, Employee no=10005 name=Kyoichi Maliniak gender=M, Employee no=10006 name=Anneke Preusig gender=F, Employee no=10007 name=Tzvetan Zielinski gender=F, Employee no=10008 name=Saniya Kalloufi gender=M, Employee no=10009 name=Sumant Peac gender=F, Employee no=10010 name=Duangkaew Piveteau gender=F, Employee no=10011 name=Mary Sluis gender=F, Employee no=10012 name=Patricio Bridgland gender=M, Employee no=10013 name=Eberhardt Terkki gender=M, Employee no=10014 name=Berni Genin gender=M, Employee no=10015 name=Guoxiang Nooteboom gender=M, Employee no=10016 name=Kazuhito Cappelletti gender=M, Employee no=10017 name=Cristinel Bouloucos gender=F, Employee no=10018 name=Kazuhide Peha gender=F, Employee no=10019 name=Lillian Haddadi gender=M, Employee no=10020 name=Mayuko Warwick gender=M]
2025-07-21 13:16:05,756 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees LIMIT %(param_1)s
2025-07-21 13:16:05,756 INFO sqlalchemy.engine.Engine [generated in 0.00015s] {'param_1': 1}
Employee no=10001 name=Georgi Facello gender=M
2025-07-21 13:16:05,783 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees LIMIT %(param_1)s
2025-07-21 13:16:05,783 INFO sqlalchemy.engine.Engine [cached since 0.02664s ago] {'param_1': 1}
Employee no=10001 name=Georgi Facello gender=M
2025-07-21 13:16:05,820 INFO sqlalchemy.engine.Engine DELETE FROM employees WHERE employees.emp_no > %(emp_no_1)s
2025-07-21 13:16:05,820 INFO sqlalchemy.engine.Engine [generated in 0.00013s] {'emp_no_1': 10018}
聚合、分组
# 聚合函数
# count
from sqlalchemy import funcquery = session.query(func.count(Employee.emp_no))
print(1,query.one()) # 只能有一行结果
print(2,query.scalar()) # 取one()返回元组的第一个元素
# max/min/avg
print(3,session.query(func.max(Employee.emp_no)).scalar())
print(4,session.query(func.min(Employee.emp_no)).scalar())
print(5,session.query(func.avg(Employee.emp_no)).scalar())
# #分组
print(6,session.query(Employee.gender, func.count(Employee.emp_no)).group_by(Employee.gender).all())
输出:
2025-07-21 13:18:26,645 INFO sqlalchemy.engine.Engine SELECT count(employees.emp_no) AS count_1
FROM employees
2025-07-21 13:18:26,645 INFO sqlalchemy.engine.Engine [generated in 0.00008s] {}
1 (20,)
2025-07-21 13:18:26,676 INFO sqlalchemy.engine.Engine SELECT count(employees.emp_no) AS count_1
FROM employees
2025-07-21 13:18:26,676 INFO sqlalchemy.engine.Engine [cached since 0.03161s ago] {}
2 20
2025-07-21 13:18:26,707 INFO sqlalchemy.engine.Engine SELECT max(employees.emp_no) AS max_1
FROM employees
2025-07-21 13:18:26,707 INFO sqlalchemy.engine.Engine [generated in 0.00013s] {}
3 10020
2025-07-21 13:18:26,736 INFO sqlalchemy.engine.Engine SELECT min(employees.emp_no) AS min_1
FROM employees
2025-07-21 13:18:26,736 INFO sqlalchemy.engine.Engine [generated in 0.00010s] {}
4 10001
2025-07-21 13:18:26,763 INFO sqlalchemy.engine.Engine SELECT avg(employees.emp_no) AS avg_1
FROM employees
2025-07-21 13:18:26,763 INFO sqlalchemy.engine.Engine [generated in 0.00007s] {}
5 10010.5000
2025-07-21 13:18:26,788 INFO sqlalchemy.engine.Engine SELECT employees.gender AS employees_gender, count(employees.emp_no) AS count_1
FROM employees GROUP BY employees.gender
2025-07-21 13:18:26,788 INFO sqlalchemy.engine.Engine [generated in 0.00012s] {}
6 [(<MyEnum.M: 'M'>, 12), (<MyEnum.F: 'F'>, 8)]关联查询
从语句看出员工、部门之间的关系是多对多关系。
先把这些表的Model类和字段属性建立起来。
# 创建实体类
class Employee(Base):# 指定表名__tablename__ = 'employees'# 定义属性对应字段emp_no = Column(Integer, primary_key=True)birth_date = Column(Date, nullable=False)first_name = Column(String(14), nullable=False)last_name = Column(String(16), nullable=False)gender = Column(Enum(MyEnum), nullable=False)hire_date = Column(Date, nullable=False)# 第一参数是字段名,如果和属性名不一致,一定要指定# age = Column ('age', Integer)def __repr__(self):return "{} no={} name={} {} gender={}".format(self.__class__.__name__, self.emp_no, self.first_name, self.last_name, self.gender.value)class Department(Base):__tablename__ = 'departments'dept_no = Column(String(4), primary_key=True)dept_name = Column(String(40), nullable=False, unique=True)def __repr__(self):return "{} no={} name={}".format(type(self).__name__, self.dept_no, self.dept_name)class Dept_emp(Base):__tablename__ = "dept_emp"emp_no = Column(Integer, ForeignKey(' employees emp_no', ondelete='CASCADE'), primary_key=True)dept_no = Column(String(4), ForeignKey('departments.dept_no', ondelete='CASCADE'), primary_key=True)from_date = Column(Date, nullable=False)to_date = Column(Date, nullable=False)def __repr__(self):return "{} empno={} deptno={}".format(type(self).__name__, self.emp_no, self.dept_no)Foreignkey(‘employees.emp_no’,ondelete=‘CASCADE’)定义外键约束
需求
查询10010员工的所在的部门编号
1、使用隐式内连接
import sqlalchemy
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmakerfrom sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Date, Enum, ForeignKey, create_engine
from sqlalchemy.orm import sessionmaker
import enumhost = '127.0.0.1'
user = '3323232'
password = '323232^32328^f!2'
port = 3306
database = '323232'connstr = "mysql+pymysql://{}:{}@{}:{}/{}".format(user, password, host, port, database)Base = declarative_base()engine = create_engine(connstr, echo=True)Session = sessionmaker(bind=engine)
session = Session()class MyEnum(enum.Enum):M = 'M'F = 'F'# 打印函数
def show(emps):for x in emps:print(1, x)print('~' * 30, end='\n\n')# 与或非
from sqlalchemy import or_, and_, not_# 排序# 创建实体类
class Employee(Base):# 指定表名__tablename__ = 'employees'# 定义属性对应字段emp_no = Column(Integer, primary_key=True)birth_date = Column(Date, nullable=False)first_name = Column(String(14), nullable=False)last_name = Column(String(16), nullable=False)gender = Column(Enum(MyEnum), nullable=False)hire_date = Column(Date, nullable=False)# 第一参数是字段名,如果和属性名不一致,一定要指定# age = Column ('age', Integer)def __repr__(self):return "{} no={} name={} {} gender={}".format(self.__class__.__name__, self.emp_no, self.first_name, self.last_name, self.gender.value)class Department(Base):__tablename__ = 'departments'dept_no = Column(String(4), primary_key=True)dept_name = Column(String(40), nullable=False, unique=True)def __repr__(self):return "{} no={} name={}".format(type(self).__name__, self.dept_no, self.dept_name)class Dept_emp(Base):__tablename__ = "dept_emp"emp_no = Column(Integer, ForeignKey(' employees emp_no', ondelete='CASCADE'), primary_key=True)dept_no = Column(String(4), ForeignKey('departments.dept_no', ondelete='CASCADE'), primary_key=True)from_date = Column(Date, nullable=False)to_date = Column(Date, nullable=False)def __repr__(self):return "{} empno={} deptno={}".format(type(self).__name__, self.emp_no, self.dept_no)# 查询10010员工所在的部门编号
results = session.query(Employee, Dept_emp).filter(Employee.emp_no == Dept_emp.emp_no).filter(Employee.emp_no == 10010).all()
show(results)
# 查询结果
2025-07-21 13:25:57,006 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date, dept_emp.emp_no AS dept_emp_emp_no, dept_emp.dept_no AS dept_emp_dept_no, dept_emp.from_date AS dept_emp_from_date, dept_emp.to_date AS dept_emp_to_date
FROM employees, dept_emp
WHERE employees.emp_no = dept_emp.emp_no AND employees.emp_no = %(emp_no_1)s
2025-07-21 13:25:57,006 INFO sqlalchemy.engine.Engine [generated in 0.00010s] {'emp_no_1': 10010}
1 (Employee no=10010 name=Duangkaew Piveteau gender=F, Dept_emp empno=10010 deptno=d004)
1 (Employee no=10010 name=Duangkaew Piveteau gender=F, Dept_emp empno=10010 deptno=d006)
这种方式产生隐式连接的语句
SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date, dept_emp.emp_no AS dept_emp_emp_no, dept_emp.dept_no AS dept_emp_dept_no, dept_emp.from_date AS dept_emp_from_date, dept_emp.to_date AS dept_emp_to_date
FROM employees, dept_emp
WHERE employees.emp_no = dept_emp.emp_no AND employees.emp_no = %(emp_no_1)s
2、使用join
# 第二种写法
results = session.query(Employee).join(Dept_emp, Employee.emp_no ==Dept_emp.emp_no).filter(Employee.emp_no == 10010).all()
print(results)输出:
2025-07-21 13:30:09,306 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees INNER JOIN dept_emp ON employees.emp_no = dept_emp.emp_no
WHERE employees.emp_no = %(emp_no_1)s
2025-07-21 13:30:09,306 INFO sqlalchemy.engine.Engine [generated in 0.00008s] {'emp_no_1': 10010}
[Employee no=10010 name=Duangkaew Piveteau gender=F]
这两种写法,返回都只有一行数据,为什么?
原因在于 query(Employee)这个只能返回一个实体对象中去,为了解决这个问题,需要修改实体类Employee,增加属性用来存放部门信息
sqlalchemy.orm.relationship(实体类名字符串)
总结
在开发中,一般都会采用ORM框架,这样就可以使用对象操作表了。定义表映射的类,使用Column的描述器定义类属性,使用ForeignKey来定义外键约束。如果在一个对象中,想查看其它表对应的对象的内容,就要使用relationship来定义关系。
是否使用外键?
1、力挺派
能使数据保证完整性一致性
2、嫌弃派
开发难度增加,大数据的时候影响插入、修改、删除的效率。
在业务层保证数据的一致性。
import sqlalchemy
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmakerfrom sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Date, Enum, ForeignKey, create_engine
from sqlalchemy.orm import sessionmaker, relationship
import enumhost = '127.0.0.1'
user = '323232'
password = '32323232^#8^f!2'
port = 3306
database = '32323'connstr = "mysql+pymysql://{}:{}@{}:{}/{}".format(user, password, host, port, database)Base = declarative_base()engine = create_engine(connstr, echo=True)Session = sessionmaker(bind=engine)
session = Session()class MyEnum(enum.Enum):M = 'M'F = 'F'# 创建实体类
class Employee(Base):# 指定表名__tablename__ = 'employees'# 定义属性对应字段emp_no = Column(Integer, primary_key=True)birth_date = Column(Date, nullable=False)first_name = Column(String(14), nullable=False)last_name = Column(String(16), nullable=False)gender = Column(Enum(MyEnum), nullable=False)hire_date = Column(Date, nullable=False)dept_emps = relationship('Dept_emp')def __repr__(self):return "{} no={} name={} {} gender={} no={}".format(self.__class__.__name__, self.emp_no, self.first_name, self.last_name,self.gender.value, self.dept_emps) # 修改self.dept_emps为self.emp_no,再看运行结果class Department(Base):__tablename__ = 'departments'dept_no = Column(String(4), primary_key=True)dept_name = Column(String(40), nullable=False, unique=True)def __repr__(self):return "{} no={} name={}".format(type(self).__name__, self.dept_no, self.dept_name)class Dept_emp(Base):__tablename__ = "dept_emp"emp_no = Column(Integer, ForeignKey('employees.emp_no', ondelete='CASCADE'), primary_key=True)dept_no = Column(String(4), ForeignKey('departments.dept_no', ondelete='CASCADE'), primary_key=True)from_date = Column(Date, nullable=False)to_date = Column(Date, nullable=False)def __repr__(self):return "{} empno={} deptno={}".format(type(self).__name__, self.emp_no, self.dept_no)# # 删除继承自Base的所有表
# Base.metadata.drop_all(engine)
# # 创建继承自Base的所有表
# Base.metadata.create_all(engine)
# 创建session
Session = sessionmaker(bind=engine)
session = Session()def show(emps):for x in emps:print(x)print('~~~~~~~~~~~~~~~', end='\n\n')# 查询10010员工所在的部门编号
results = session.query(Employee).join(Dept_emp, Employee.emp_no ==Dept_emp.emp_no).filter(Employee.emp_no == 10010)
show(results.all())输出:
2025-07-21 17:28:51,342 INFO sqlalchemy.engine.Engine SELECT employees.emp_no AS employees_emp_no, employees.birth_date AS employees_birth_date, employees.first_name AS employees_first_name, employees.last_name AS employees_last_name, employees.gender AS employees_gender, employees.hire_date AS employees_hire_date
FROM employees INNER JOIN dept_emp ON employees.emp_no = dept_emp.emp_no
WHERE employees.emp_no = %(emp_no_1)s
2025-07-21 17:28:51,342 INFO sqlalchemy.engine.Engine [generated in 0.00017s] {'emp_no_1': 10010}
2025-07-21 17:28:51,377 INFO sqlalchemy.engine.Engine SELECT dept_emp.emp_no AS dept_emp_emp_no, dept_emp.dept_no AS dept_emp_dept_no, dept_emp.from_date AS dept_emp_from_date, dept_emp.to_date AS dept_emp_to_date
FROM dept_emp
WHERE %(param_1)s = dept_emp.emp_no
2025-07-21 17:28:51,377 INFO sqlalchemy.engine.Engine [generated in 0.00015s] {'param_1': 10010}
Employee no=10010 name=Duangkaew Piveteau gender=F no=[Dept_emp empno=10010 deptno=d004, Dept_emp empno=10010 deptno=d006]
~~~~~~~~~~~~~~~
总结
到这里,Python的学习也告一段落了。 下一步,学习大模型 。