强化学习核心原理及数学框架
1. 定义与核心思想
强化学习(Reinforcement Learning, RL)是一种通过智能体(Agent)与环境(Environment)的持续交互来学习最优决策策略的机器学习范式。其核心特征为:
- 试错学习:智能体初始策略随机("开局是智障"),通过大量交互获得经验数据("装备全靠打")
- 奖励驱动:环境对每个动作给出奖励信号(Reward),智能体目标为最大化长期累积奖励
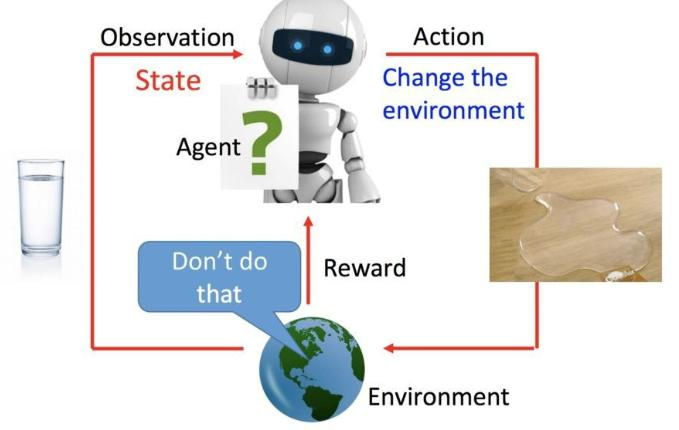
2. 马尔可夫决策过程(MDP)
RL问题可形式化为五元组:
其中:
:状态空间(如飞船位置、速度)
:动作空间(离散:{左,右,开火};连续:力度∈[0,1])
:状态转移概率
:即时奖励函数
:折扣因子
3. 奖励机制与目标函数
智能体追求最大化期望折扣累积奖励:
对于飞船着陆问题:
- 最终奖励:成功着陆+100,坠毁-100
- 过程奖励:燃料消耗-0.1,姿态偏离-0.5
4. 策略与价值函数
策略表示状态到动作的概率分布,状态值函数评估策略优劣:
动作值函数(Q函数)定义为:
5. 策略优化方法
5.1 基于值函数的方法(如Q-Learning)
通过贝尔曼最优方程更新Q值:
5.2 策略梯度方法(如REINFORCE)
直接优化参数化策略,梯度计算为:
6. 深度强化学习实现
使用神经网络近似策略或价值函数(如DQN):
输入:输出:动作概率分布/最优动作
训练目标为最小化时序差分误差:
7. 应用领域
| 领域 | 状态空间 | 动作空间 | 奖励设计 |
|---|---|---|---|
| 机器人控制 | 关节角度、力反馈 | 力矩调整 | 姿态稳定性奖励 |
| 游戏AI | 屏幕像素 | 手柄按键组合 | 得分增减机制 |
| 金融交易 | 市场行情 | 买入/卖出量 | 投资回报率 |
8. 核心挑战
- 探索与利用的平衡:ε-greedy、UCB等方法
- 稀疏奖励问题:基于好奇心(Curiosity)的探索
- 高维连续动作空间:确定性策略梯度(DDPG)