架构设计之计算高性能——单体服务器高性能
架构设计之计算高性能——单体服务器高性能
高性能是每个程序员共同的追求,无论是开发系统,还是仅仅只是写一段脚本,都希望能够达到高性能的效果,而高性能又是软件系统设计中最复杂的一步。无论是开发千万级并发的电商系统,还是编写简单的数据处理脚本,开发者们都在不断追求更快的执行速度、更低的响应延迟。在网络时代,性能等同于用户体验。用户可能不会注意到精心设计的界面,但500毫秒的延迟就会显著降低满意度;开发者或许能优化复杂的算法,但I/O瓶颈却能让一切努力付诸东流。
而高性能又是软件系统设计中最复杂的一步。它要求我们平衡:
- 资源效率:最大化利用CPU、内存、网络
- 系统复杂度:避免过度设计带来的维护成本
- 实时性与吞吐量:响应速度 vs 处理能力
- 成本约束:服务器资源的经济性优化
高性能架构主要在两个维度展开:单服务器高性能和集群高性能。本文主要聚焦单服务器领域,揭示如何通过网络编程模型的选择,在单台机器上压榨出极致的性能潜力。
1. 网络编程模型:
单服务器高性能的关键之一在于服务器采取的网络编程模型,网络编程模型的两个关键点:
- 服务器如何管理连接?
- 服务器如何处理请求?
这两个问题最终都指向操作系统的I/O模型与进程/线程模型。不同的组合方式会产生截然不同的性能特征:
| 模型组合 | 典型应用 | 连接处理能力 | CPU利用率 |
|---|---|---|---|
| 阻塞I/O+多进程 | 传统Apache | 中等 | 较低 |
| 非阻塞I/O+线程池 | Tomcat NIO | 高 | 高 |
| 异步I/O+协程 | Nginx | 极高 | 极高 |
2. PPC:
PPC是Process per Connection的缩写,其含义是指每次有新的连接就新建一个进程去专门处理这个连接的请求,这是传统的UNIX网络服务器所采用的模型。基本的流程图如下。
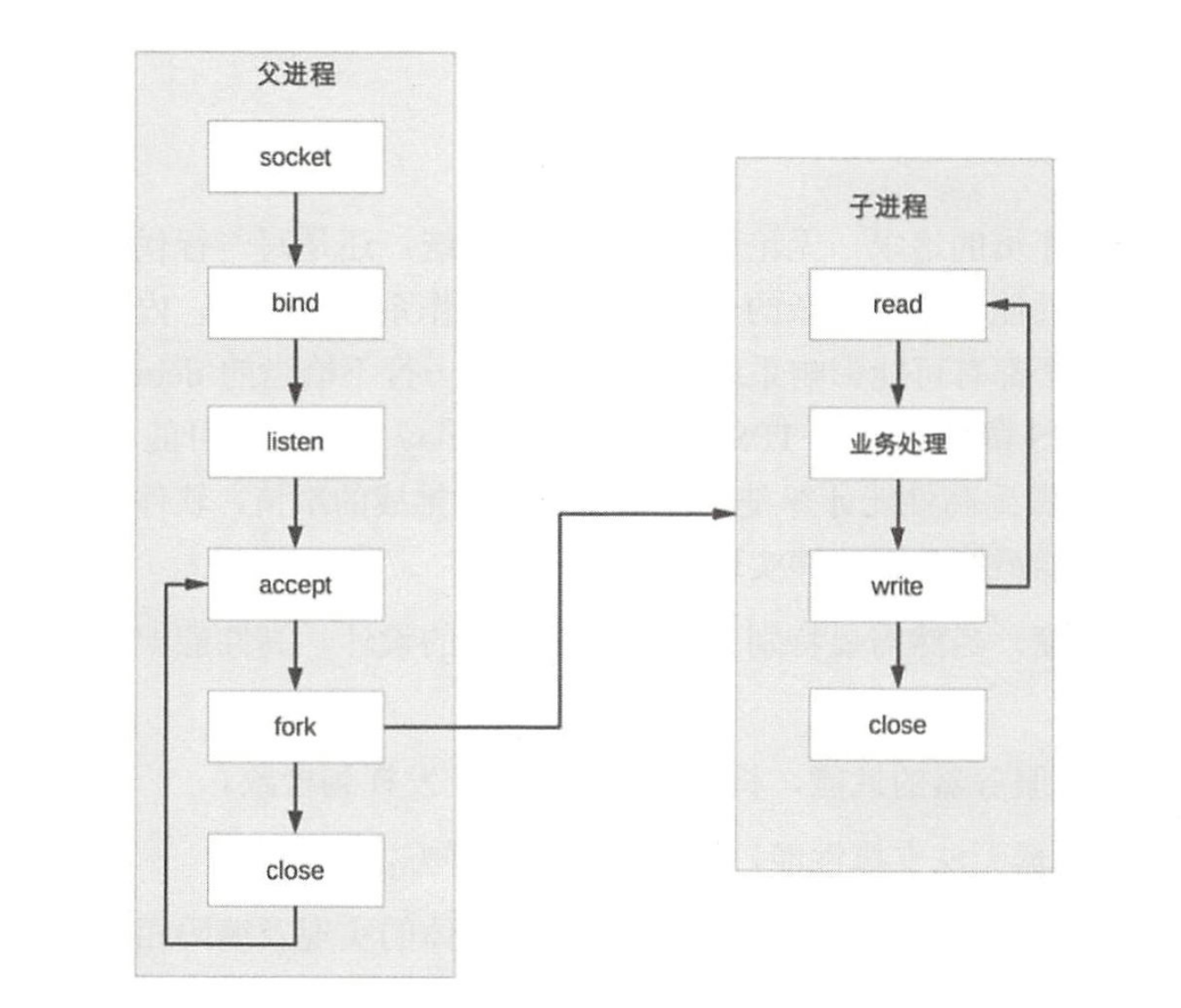
(1)父进程接受连接(图中accept)。
(2)父进程“fork”子进程(图中 fork)。
(3)子进程处理连接的读写请求(图中子进程read、业务处理、write)。
(4)子进程关闭连接(图中子进程中的 close)。
// 简化版PPC伪代码
while(1) {int conn_fd = accept(listen_fd); // 接受新连接if(fork() == 0) { // 创建子进程close(listen_fd); // 子进程关闭监听process_request(conn_fd); // 处理请求close(conn_fd); // 关闭连接exit(0); // 子进程退出}close(conn_fd); // 父进程关闭连接
}
PPC的优势:
- 逻辑隔离性强:进程崩溃不影响整体服务
- 编程简单直接:无需考虑并发控制
- 利用多核优势:操作系统自动调度进程
PPC的不足:
三大性能瓶颈:
- 进程创建代价高昂:Linux中fork()需要复制页表、文件描述符等资源,消耗数百微秒
- 进程通信复杂低效:共享内存需同步、管道/消息队列引入额外拷贝
- 进程数量限制:Linux默认最多32768进程,消耗GB级内存
3. Prefork:
空间换时间
在PPC模式中,当连接进来时才“fork”新进程来处理连接请求,由于“fork”进程代价高,用户访问时可能感觉比较慢,prefork模式的出现就是为了解决这个问题。面对PPC的性能瓶颈,Prefork模式带来的思路是:预先创建进程池,规避实时fork()的开销。
// Prefork实现框架
void init_process_pool(int num) {for(int i=0; i<num; i++) {if(fork() == 0) {// 子进程进入就绪循环while(1) {int conn_fd = accept_lock(listen_fd);process_request(conn_fd);close(conn_fd);}}}
}
优化点:
- 进程预热:服务启动时创建N个进程
- 资源预分配:预先分配文件描述符、内存等
- 连接竞争管理:通过文件锁控制accept()调用
- 优势:解决实时fork开销,连接响应时间平均降低40%
- 局限:未能解决进程间通信和内存开销问题
- 典型应用:Apache HTTP Server的prefork MPM模式
进程池大小设置公式:
推荐pool_size = CPU核心数 × 2 + 预期平均并发数 × 0.2
4. TPC:轻量级线程的崛起
TPC是 Thread per Connection的缩写,其含义是指每次有新的连接就新建一个线程去专门处理这个连接的请求。与进程相比,线程更轻量级,创建线程的消耗比进程要少得多:同时多线程是共享进程内存空间的,线程通信相比进程通信更简单。因此,TPC实际上是解决或弱化了PPC的问题1(fork代价高)和问题2(父子进程通信复杂)。
TPC 的基本流程如下:
(1)父进程接受连接(图中 accept)。
(2)父进程创建子线程(图中pthread)。
(3)子线程处理连接的读写请求(图中子线程read、业务处理、write)。
(4)子线程关闭连接(图中子线程中的 close)。
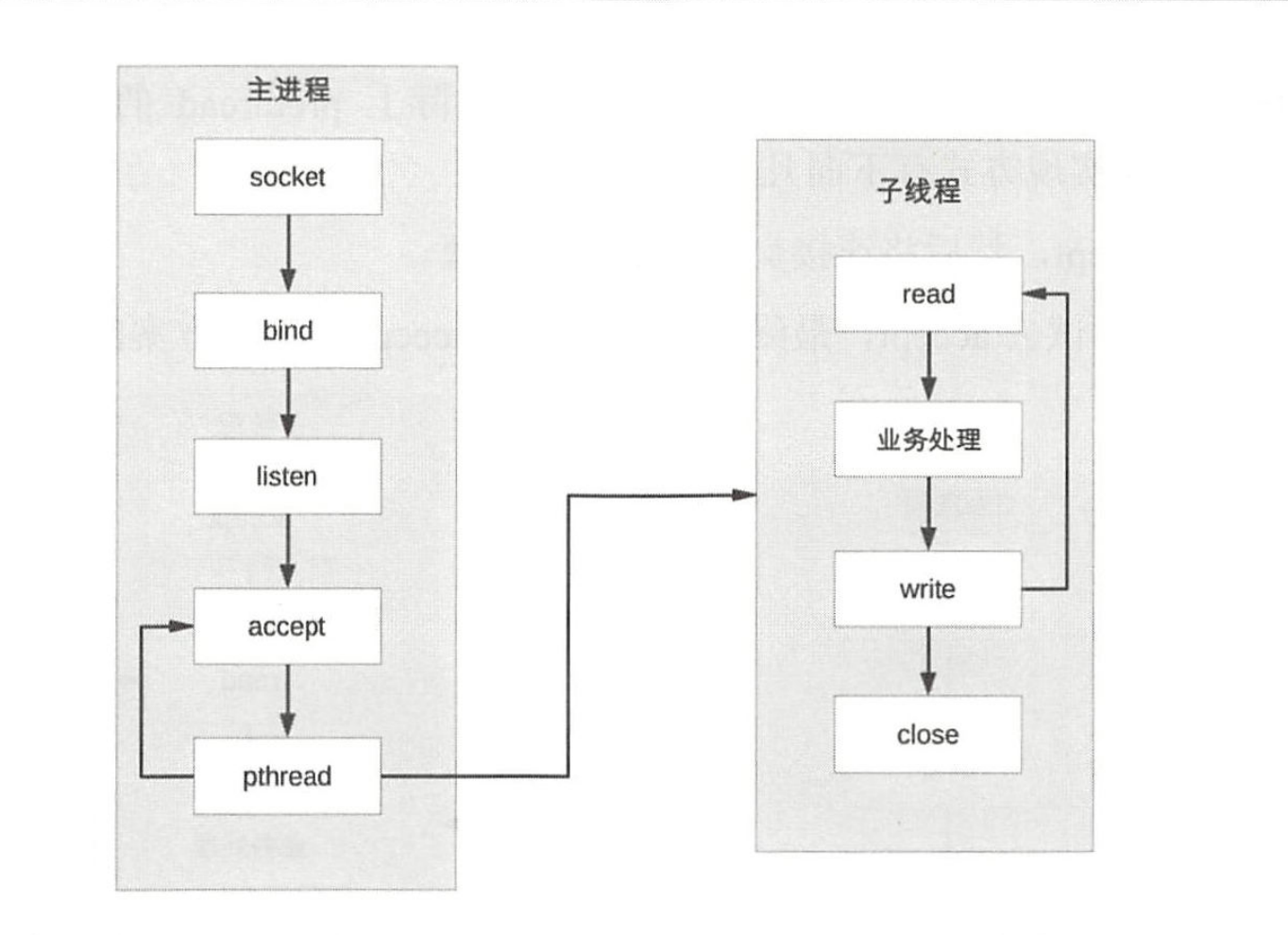
TPC(Thread Per Connection) 的核心:为每个连接创建服务线程而非进程。
// Java TPC示例
ServerSocket server = new ServerSocket(8080);
while(true) {Socket client = server.accept();new Thread(() -> {// 在线程中处理请求handleRequest(client);}).start();
}
优点:
- 创建成本下降:线程创建仅需10-30微秒,比进程快10倍
- 通信效率提升:共享内存空间,避免数据拷贝
- 上下文切换快:线程切换开销仅为进程的1/5
不足:
- 并发限制:Java默认每进程最多2000线程
- 同步复杂性:共享资源需要加锁
- 多核调度开销:线程数量超过CPU核心时效率下降
5. Prethread:线程池的力量
在TPC模式中,当连接进来时才创建新的线程来处理连接请求,虽然创建线程比创建进程要更加轻量级,但还是有一定的代价,而prethread模式就是为了解决这个问题。和 prefork 类似,prethread 模式会预先创建线程,然后才开始接受用户的请求,当有新的连接进来的时候,就可以省去创建线程的操作,让用户感觉更快、体验更好。
由于多线程之间数据共享和通信比较方便,因此实际上prethread的实现方式相比prefork要灵活一些,常见的实现方式有下面几种:
(1)主进程 accept,然后将连接交给某个线程处理。
(2)子线程都尝试去 accept,最终只有一个线程accept成功,方案的基本示意图如下
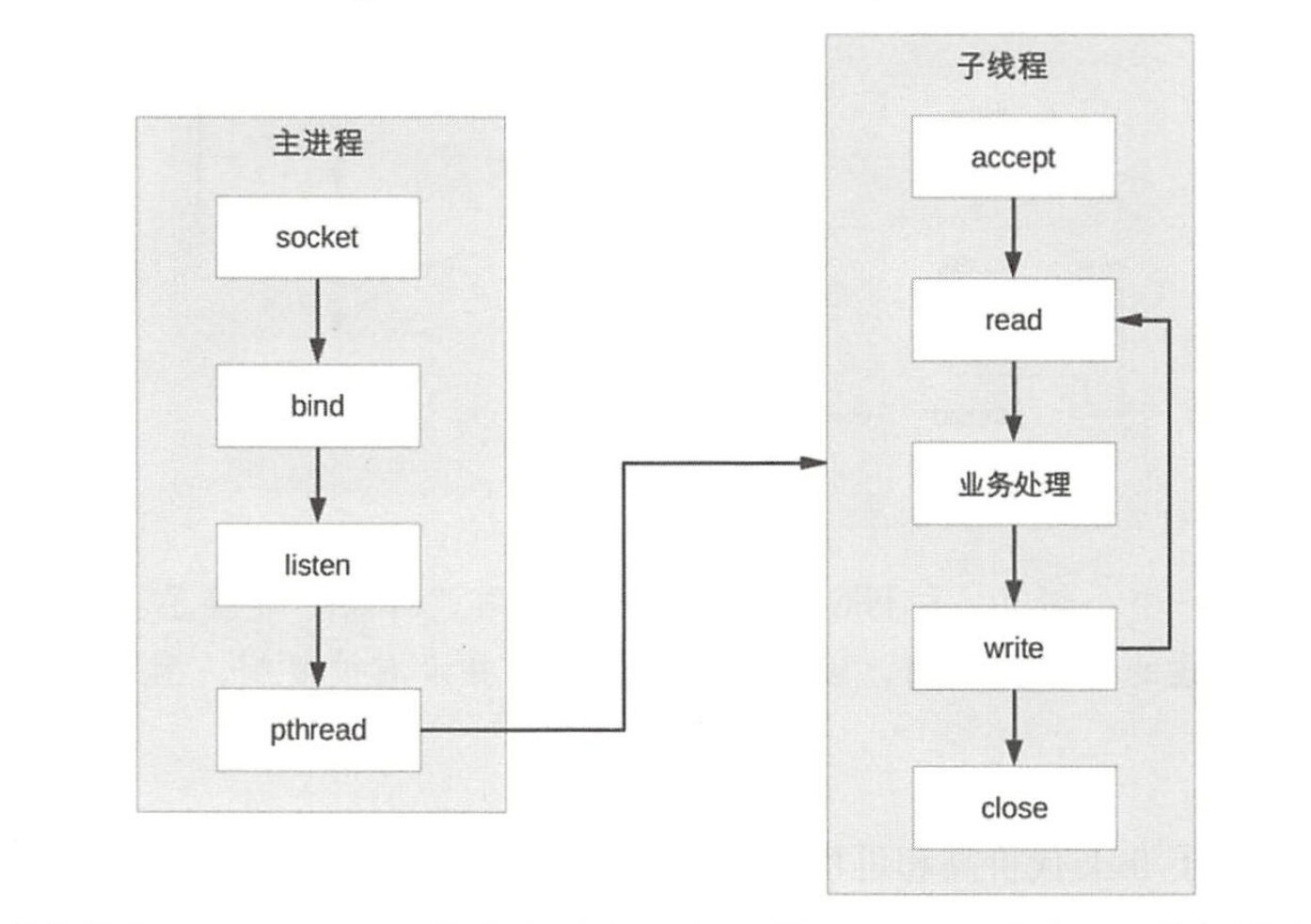
Prethread模式通过线程池优化TPC:
# Python线程池示例
from concurrent.futures import ThreadPoolExecutorwith ThreadPoolExecutor(max_workers=100) as executor:while True:client_sock = server_sock.accept()executor.submit(handle_connection, client_sock)
线程池:
- 线程复用:避免频繁创建/销毁开销
- 流量控制:通过队列缓冲突发请求
- 资源隔离:重要业务使用独立线程池
线程池配置:
Tomcat线程池配置
maxThreads = 200 # 最大线程数minSpareThreads = 20 # 最小空闲线程queueSize = 100 # 等待队列大小
6. Reactor模式:I/O多路复用的革命
PPC方案最主要的问题就是每个连接都要创建进程(为了描述简洁,这里只以PPC和进程为例,实际上换成 TPC 和线程,原理是一羊的),连接结束后进程就销毁了,这样做其实是很大的浪费。为了解决这个问题,一个自然而然的想法就是资源复用,即不再单独为每个连接创建进程,而是创建一个进程池,将连接分配给进程,一个进程可以处理多个连接的业务。
Reactor 模式的核心组成部分包括 Reactor 和处理资源池(进程池或线程池),其中 Reactor负责监听和分配事件,处理资源池负责处理事件。初看Reactor的实现是比较简单的,但实际上结合不同的业务场景,Reactor模式的具体实现方案灵活多变,主要体现在如下两点Reactor的数量可以变化:可以是一个Reactor,也可以是多个Reactor。
资源池的数量可以变化:以进程为例,可以是单个进程,也可以是多个进程(线程类似)。
Reactor模式通过I/O多路复用实现质的飞跃:
- 核心:单线程/进程监听所有连接状态,事件触发后分发处理
6.1 单Reactor单进程
- 代表应用:Redis
- 优点:极致简单高效
- 缺点:无法利用多核
6.2 单Reactor多进程
- 代表应用:Apache MPM worker
- 折中方案:平衡多核与复杂度
6.3 多Reactor多进程
- 代表应用:Nginx
- 终极方案:每个CPU核心独立Reactor
Reactor的三个核心组件:
- Initiation Dispatcher:核心调度器
- Synchronous Event Demultiplexer:I/O多路复用器
- Event Handler:事件处理回调
7. Proactor:
Reactor 是非阻塞同步网络模型,因为真的read 和send 操作都需要用户进程同步操作,这里的“同步”指用户进程在执行read 和 senc这类 I/O 操作的时候是同步的,如果把 I/O 操作网络模型 Proactor。改为异步就能够进一步提升性能,这就是异步网络模型Proactor。
Reactor 可以理解为“来了事件我通知你你来处理”,而Proactor 可以理解为“来了事件我来处理,处理完了我通知你”。这里的“我”就是操作系统内核,“事件”就是有新连接、有数据可读、有数据可写这些 IO 事件。
与Reactor的本质差异:
- Reactor:通知何时可读 → 用户执行读取
- Proactor:直接读取完成 → 用户处理数据
Proactor的优势:
- 完全避免用户态I/O阻塞
- 更高吞吐量,尤其适合大文件传输
- Windows IOCP原生支持
Linux实现方案:
// Linux AIO示例
struct aiocb cb = {.aio_fildes = fd,.aio_buf = buf,.aio_nbytes = size
};
aio_read(&cb); // 发起异步读
while(aio_error(&cb) == EINPROGRESS); // 等待完成
结语:
通过了解单服务器高性能架构的演进,我们见证了性能的进步其实就是探索-枷锁-破冰的历程:
- 资源粒度:从进程到线程再到协程
- I/O效率:从阻塞到非阻塞再到异步
- 控制方式:从串行到分时再到事件驱动
选择架构的核心准则:
- C10K以下:线程池或prefork足够
- C100K级别:Reactor模式必备
- C10M级别:Proactor+多Reactor+DPDK
当今最前沿的两种架构:
最后:没有普适的最优解,只有特定场景下的最佳选择。衡量维度包括:
- 并发量预期
- 请求响应时间分布
- 数据局部性特征
- 硬件资源组合
📌 关注 是对原创的最大认可,你的每一个关注 ,都是技术生态圈的+1节点!
🔔 开启通知,下一篇《架构设计之计算高性能——集群高性能》内容更新时,你就是技术圈最前沿的「极客」!