python应用day11--requests爬虫详解
1.爬虫简介:
- 简介:网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能做。
爬虫只能获取到浏览器(客户端)所展示出来的数据。
- 作用:数据分析中,进行数据采集的一种方式。
2.爬虫工作过程:
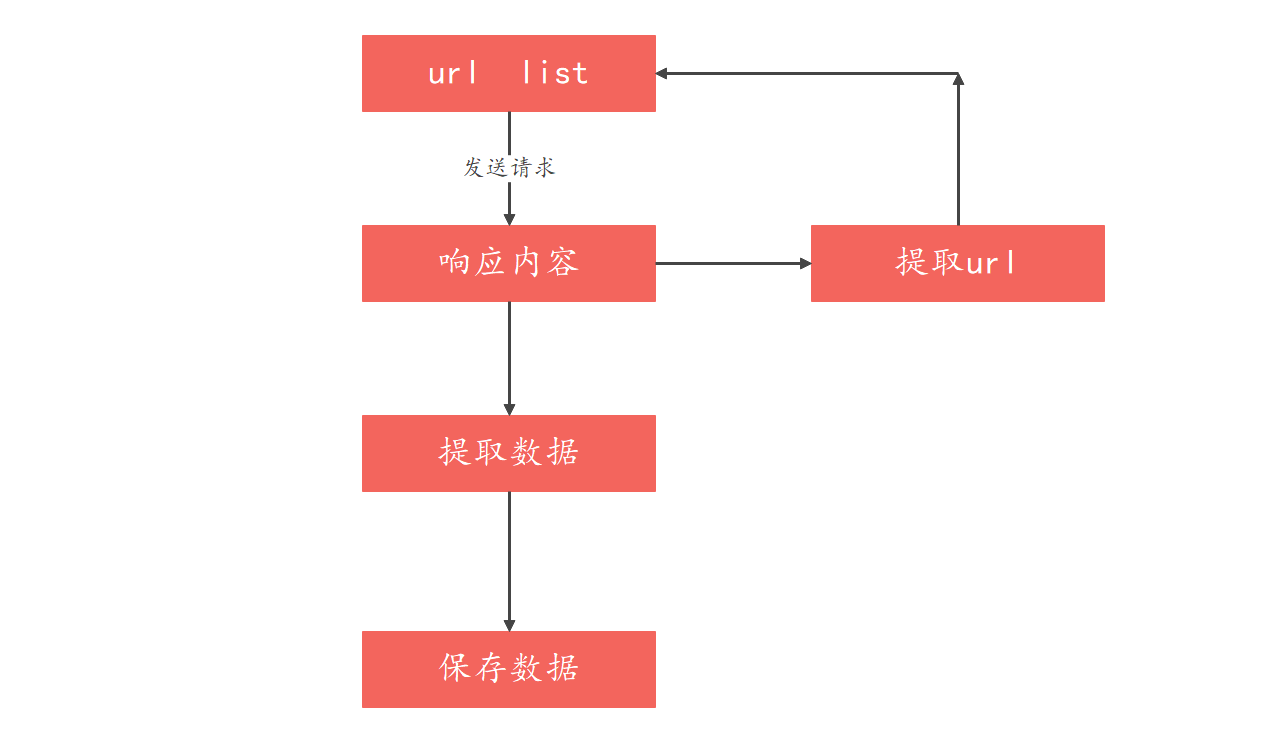
①向起始的 url 地址发送请求,并获取响应数据
②对响应内容进行提取
③如果提取 url,则继续发送请求获取响应
④如果提取数据,将数据进行保存
3.requests模块:
- 简介 : requests 是用 python 语言编写的一个开源的HTTP库,可以通过 requests 库编写 python 代码发送网络请求,其简单易用,是编写爬虫程序时必知必会的一个模块。
- 使用 requests 模块:
①安装
pip install requests
或者
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple②示例:请求百度,并获取响应内容
# 导入 requests 包
import requests
# 准备 url 地址
url = 'https://www.baidu.com'
# 使用 requests 发送 GET 请求,并设置请求头
headers_dic = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/136.0.0.0 Safari/537.36"
}
res = requests.get(path_url, headers=headers_dic)
response = requests.get(url)
# 获取响应的内容
# response.content:bytes,服务器返回的原始响应内容
# bytes -> str:bytes数据.decode('解码方式')
print(response.content.decode())# 获取请求头
print(response.request.headers)4.爬取单张图片:
import requestsurl = "https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png"
# 使用requests项目目标地址发送请求
res = requests.get(url)
# 获取响应内容
img_content = res.content
# 将获取的二进制图片存放到本地
with open("./images/logo.png", "wb") as file:file.write(img_content)5.爬取多张图片:
import requests
import rebase_url = "http://127.0.0.1:8082"
res = requests.get(base_url + "/index.html")
html_content = res.content.decode()
# 获取html中src的图片路径:["./images/0.jpg",...]
img_list = re.findall(r'<img src="(.*?)"', html_content)for i, img_path in enumerate(img_list):# 拼接完整的请求url:# http://127.0.0.1:8082/images/0.jpgimg_url = base_url + img_path[1:]# 发送请求,获取响应的二进制图片response = requests.get(img_url)# 存储二进制图片到本地with open(f"./images/{i}.jpg", "wb") as file:file.write(response.content)6.多线程爬取图片和gdp数据:
import requests
import re
import threadingdef get_img():base_url = "http://127.0.0.1:8082"res = requests.get(base_url + "/index.html")html_content = res.content.decode()# 获取html中src的图片路径:["./images/0.jpg",...]img_list = re.findall(r'<img src="(.*?)"', html_content)for i, img_path in enumerate(img_list):# 拼接完整的请求url:# http://127.0.0.1:8082/images/0.jpgimg_url = base_url + img_path[1:]# 发送请求,获取响应的二进制图片response = requests.get(img_url)# 存储二进制图片到本地with open(f"./images/{i}.jpg", "wb") as file:file.write(response.content)print("图片爬取完成")def get_gdp():url = "http://127.0.0.1:8082/gdp.html"res = requests.get(url)# 获取html内容html_content = res.content.decode()# 通过正则匹配国家和gdp金额data_list = re.findall(r'<a href=""><font>(.*?)</font></a>.*?<font>¥(.*?)亿元</font>', html_content, flags=re.S)# 创建文件并将内容写入到文件中with open("gdp.txt", "w", encoding="utf-8") as file:file.write(str(data_list))print("gdp爬取完成")if __name__ == '__main__':img_thread = threading.Thread(target=get_img)gdp_thread = threading.Thread(target=get_gdp)img_thread.start()gdp_thread.start()