深入探究Linux项目自动化构建工具:make与Makefile
目录
引言
一、make与Makefile概述
1.1 背景
1.2 理解
二、make工作原理
2.1 查找Makefile
2.2 确定目标文件
2.3 处理文件依赖
三、Makefile实例分析
3.1 简单C程序示例
3.2 项目清理机制
四、结合行缓冲区概念的有趣现象
五、结语
引言
在Linux软件开发的世界里, make 和 Makefile 是一对强大的搭档,它们承担着项目自动化构建的重任。熟练掌握如何编写 Makefile ,从某种程度上反映了一个开发者是否具备处理大型工程项目的能力。本文将深入剖析 make 和 Makefile 的原理与应用,同时结合实际代码示例进行讲解。
一、make与Makefile概述
1.1 背景
一个大型工程中,源文件数量众多,且依据类型、功能、模块等分布在不同目录。 Makefile 的出现,就是为了定义一系列规则,明确哪些文件需先编译、哪些后编译、哪些要重新编译,甚至执行更复杂的操作。 make 则是一个命令工具,专门解释 Makefile 中设定的指令。常见的IDE,如Delphi的 make 、Visual C++的 nmake 、Linux下GNU的 make ,都支持这一编译方式。二者配合,实现项目自动化构建,极大提升软件开发效率。
1.2 理解
以一个简单的依赖关系为例, gcc hello.* -option hello.* 就体现了文件之间的编译依赖。 make 在执行时,会按照特定逻辑处理这种依赖关系。
二、make工作原理
2.1 查找Makefile
当我们在命令行输入 make 命令时, make 首先会在当前目录下寻找名为“ Makefile ”或“ makefile ”的文件。若找不到,构建过程终止。
![]()
2.2 确定目标文件
若找到 Makefile , make 会定位文件中的第一个目标文件(target)。例如在常见的示例中,“ hello ”常作为第一个目标文件,被当作最终构建目标。
2.3 处理文件依赖
- 目标文件不存在或依赖文件更新:如果 hello 文件不存在,或者 hello 所依赖的文件(如 hello.o )的修改时间比 hello 文件新(可用 touch 命令测试文件时间) , make 会执行后续定义的命令来生成 hello 文件。
- 依赖文件缺失处理:若 hello 依赖的 hello.o 文件不存在, make 会在 Makefile 中查找构建 hello.o 的依赖规则,然后依据规则生成 hello.o 。这一过程类似堆栈操作,层层递进,直至找到最基础的文件依赖并完成构建。
- 构建过程中的错误处理:在查找依赖关系过程中,若找不到最终被依赖的文件, make 会直接退出并报错;但对于命令本身的错误或编译不成功等情况, make 不会主动处理,它只关注文件的依赖关系。若依赖关系处理完后,目标文件仍未生成, make 就停止工作。
三、Makefile实例分析
3.1 简单C程序示例
下面是一个简单的C程序:

对应的 Makefile 文件内容如下:
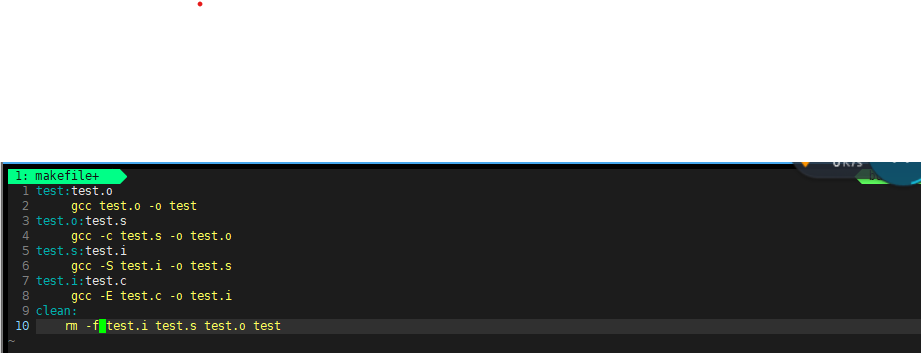
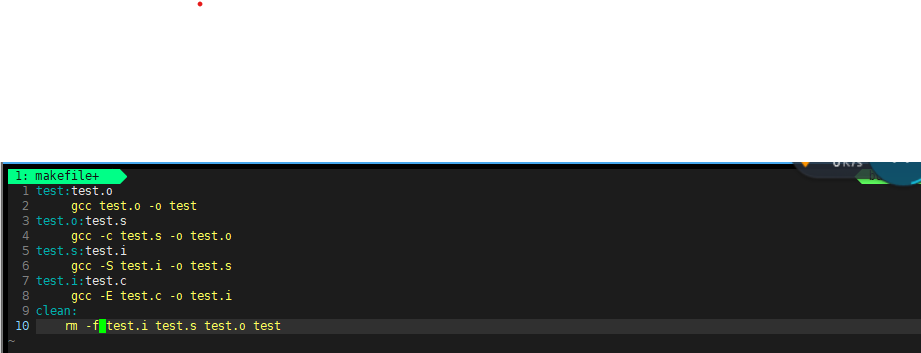
i这里定义了从test.c 文件逐步生成可执行文件test的过程,每一步都明确了依赖关系和编译命令。
3.2 项目清理机制
在项目开发中,清理已生成的目标文件很重要,以便重新编译。 Makefile 中可这样设置:

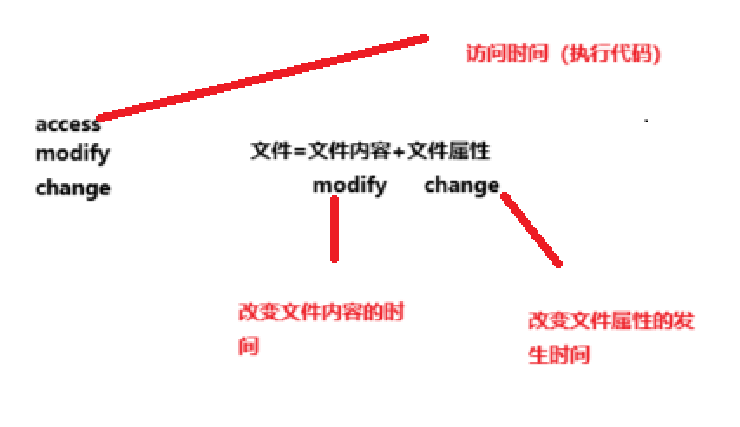
系统通过比较文件编译时间(文本属性变化时间)变化(时间转化为时间戳)来判断文献是否重新编译
-exe 新于 .c源文件是老的,不需要重新编译
-exe 老于 .c源文件是老的,需要重新编译
-exe==.c一般不会(通常比较modify)
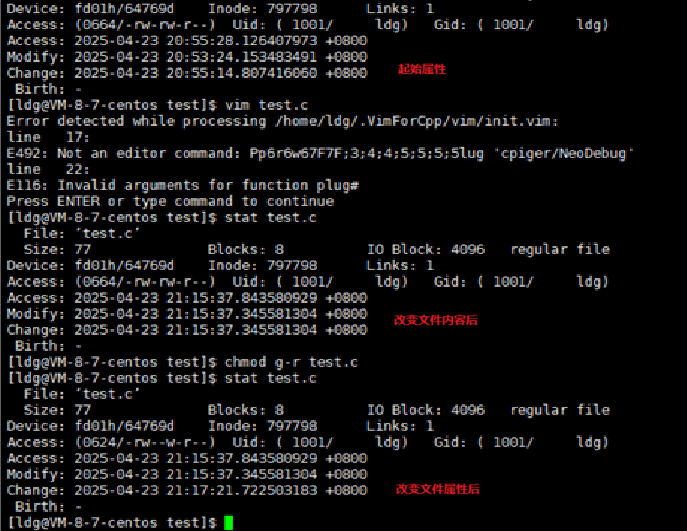
通过stat获取文件编译发生时间:

但是modify与change不一定同时改变,access可能在用户访问多次后改变(提升效率)
也可通过touch test.c 直接改变
如果想要多次make 则加.PHONY:(依赖关系)
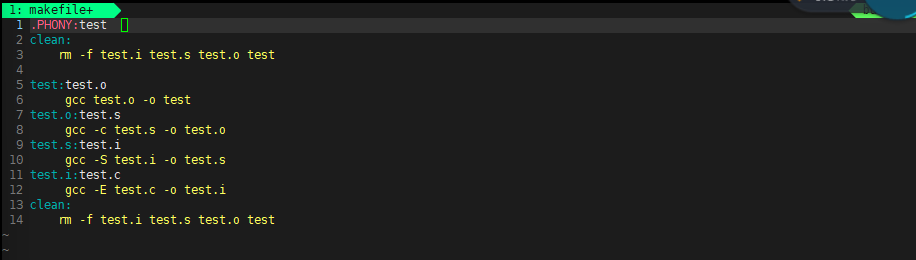
之后可多次make,但是.PHONY+test意义不大,基b于历史源文件编译通常不尽人意,会强制程序员删除源代码,又因为clean中可添加其他可执行程序,因此建议PHONY+clean
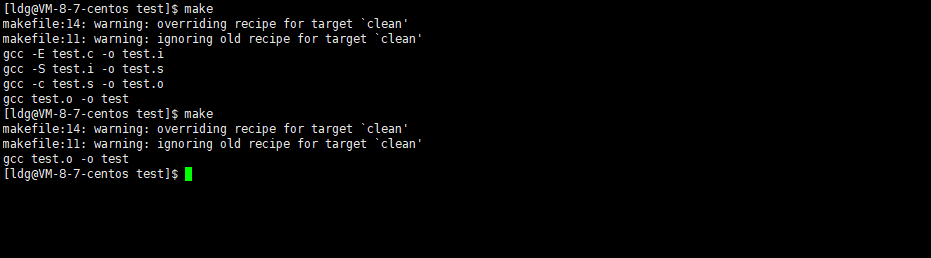 另外哪段代码在前面,make执行时,运行的就是该代码段。
另外哪段代码在前面,make执行时,运行的就是该代码段。

特殊符号
$@==:左侧内容 $^==:右侧内容
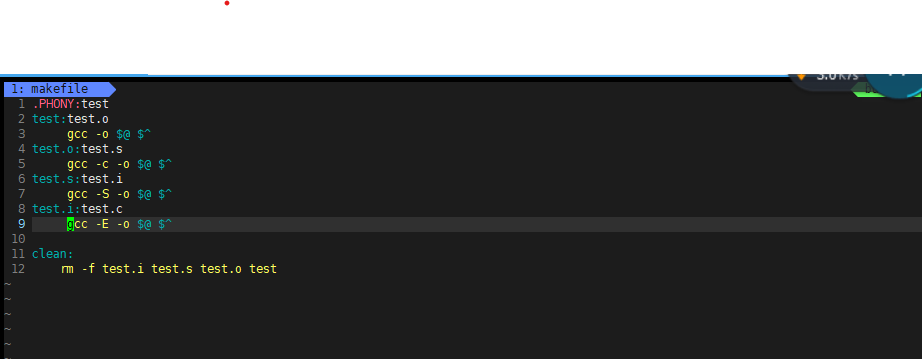

@
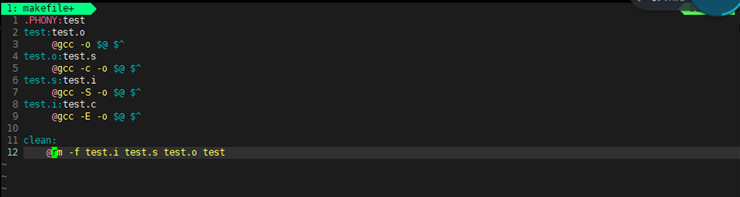

像 clean 这种未与第一个目标文件直接或间接关联的目标,其定义的命令不会自动执行。需手动输入 make clean 来清除目标文件。通常将 clean 设置为伪目标(用 .PHONY 修饰) ,伪目标的特性是每次都会被执行。也可将其他目标文件(如 hello )声明为伪目标进行测试。
四、结合行缓冲区概念的有趣现象
在处理输入输出时,行缓冲区概念很重要。以如下代码为例:
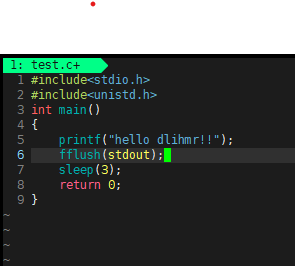
这里 printf 输出字符串后会换行, \n 会触发行缓冲区刷新,立即显示输出内容。若去掉 \n ,输出可能会延迟显示,这与行缓冲区的工作机制有关。 sleep(3) 函数使程序暂停3秒,可用于观察输出显示时机。若想强制立即输出,可使用 fflush(stdout) 函数手动刷新缓冲区。
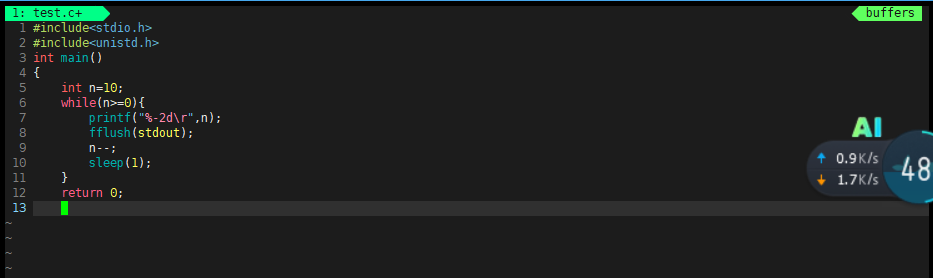
计时器
五、结语
make 和 Makefile 是Linux项目开发中不可或缺的工具,掌握它们对于高效开发大型项目意义重大。通过本文对原理的阐述、实例的分析,希望能帮助读者更好地理解和运用这一强大的自动化构建机制,在Linux软件开发之路上更进一步。