现代数据湖架构全景解析:存储、表格式、计算引擎与元数据服务的协同生态
本文全面剖析现代数据湖架构的核心组件,深入探讨对象存储(OSS/S3)、表格式(Iceberg/Hudi/Delta Lake)、计算引擎(Spark/Flink/Presto)及元数据服务(HMS/Amoro)的协作关系,并提供企业级选型指南。
一、数据湖架构演进与核心价值
数据湖架构演进历程
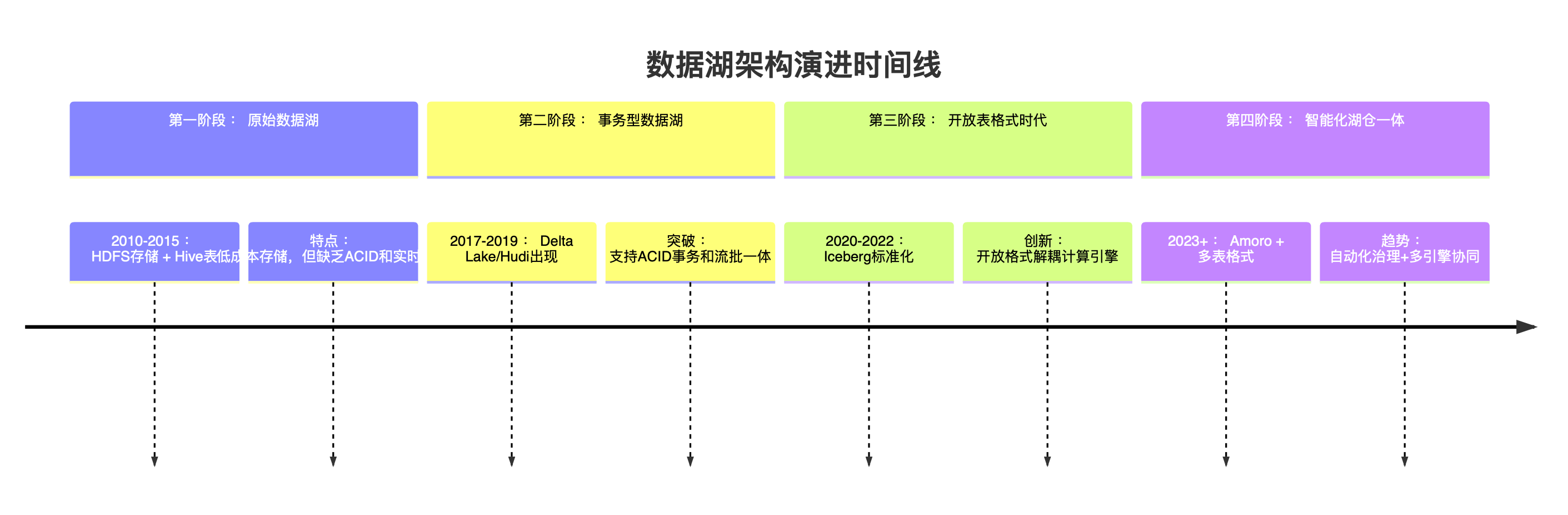
现代数据湖核心价值矩阵
| 维度 | 传统数仓 | 现代数据湖 |
|---|---|---|
| 存储成本 | 高(专有硬件) | 低(对象存储) |
| 数据时效性 | 小时/天级 | 分钟/秒级 |
| Schema灵活性 | 强Schema约束 | Schema-on-Read |
| 事务支持 | 完善 | ACID(通过表格式实现) |
| 计算引擎绑定 | 紧密耦合 | 开放解耦 |
二、核心组件深度解析
1. 对象存储:数据湖的存储基石
- 核心能力:
- 无限扩展的存储空间(EB级)
- 跨AZ/Region的高可用性(99.999999999%耐久性)
- 成本仅为HDFS的1/3-1/5
- 架构优势:
2. 表格式三巨头对比
Iceberg vs Hudi vs Delta Lake
| 特性 | Apache Iceberg | Apache Hudi | Delta Lake |
|---|---|---|---|
| 创始 | Netflix(2018) | Uber(2016) | Databricks(2019) |
| 存储格式 | Parquet/AVRO | Parquet/AVRO | Parquet |
| ACID实现 | 原子提交+快照隔离 | 时间轴+写入器 | 事务日志+乐观锁 |
| 流批一体 | 完善支持 | 原生设计 | 支持 |
| 多引擎支持 | Spark/Flink/Presto/Trino | Spark/Flink | Spark为主 |
| Schema演进 | 无损演进 | 支持 | 支持 |
| 时间旅行 | 完善支持 | 支持 | 支持 |
| 数据更新 | MERGE ON READ | COPY ON WRITE/MOR | COPY ON WRITE |
| 最佳场景 | 大规模分析+多引擎 | 频繁更新+实时摄入 | Databricks生态 |