征程 6 UCP 任务优先级 抢占简介与实操
一、引言
多模型推理场景中,可能会存在谁先谁后,甚至 A 模型任务正在运行,但需要被 B 模型任务抢占的情况。针对这种情况,地平线提供了模型优先级控制策略。
二、优先级与抢占介绍
此功能仅支持在开发板端实现,x86 模拟器不支持此功能。
2.1 理论简介
征程 6 计算平台 BPU 硬件本身没有任务抢占功能,对于每一个推理任务,一旦它进到 BPU 计算后,在该任务执行完之前,会一直占用 BPU,其他任务只能排队等待。
此时容易出现 BPU 计算资源被一个大模型任务独占,进而影响其他高优先级模型任务的执行。针对这种问题,工具链开发了基于软件的方式 实现的 BPU 资源抢占功能。
需要关注:
- hbm 模型在 BPU 上推理时,它表现为 1 个或者多个 function-call 的调用,其中 function-call 是 BPU 的执行粒度,多个 function-call 调用任务 在 BPU 硬件队列上按序进行调度,当一个模型所有的 function-call 都执行完成,那么一个模型推理任务也就执行完成了。
- BPU 模型任务抢占粒度设计为 function-call,即 BPU 执行完一个 function-call 之后,暂时挂起当前模型,然后切入执行另外一个模型,当新模型执行完成之后,再恢复原来模型的状态继续运行。 但是这里存在两个问题,第一是编译出来的 hbm 模型 function-call 都是 merge 在一起的,此时模型只有一个大(长)的 function-call,它无法被抢占;第二是每个 function-call 的执行时间比较长或者不固定,会造成抢占时机不确定,影响抢占效果。
为了解决上述两个问题,地平线进行了一些处理,下面介绍其操作方法:
- 如果您使用 QAT 方案:在 模型编译 阶段,需要在 compile 接口中添加 max_time_per_fc 选项,用于设置每个 function call 的执行时间(以微秒为单位),默认取值为 0 (即不做限制)。您可以自行设置这个选项,控制 hbm 上板运行时每个 function-call 的执行时间。假设某 hbm 总执行时间为 10ms,当模型编译时 将 max_time_per_fc 设置为 1000,则这个 hbm 将会从默认的 1 个 10ms function-call 被拆分成 10 个 1ms function-call。
- 如果您使用 PTQ 方案,在 模型转换 阶段,需要在 YAML 文件 编译器相关参数( compiler_parameters )中,添加 max_time_per_fc 参数。
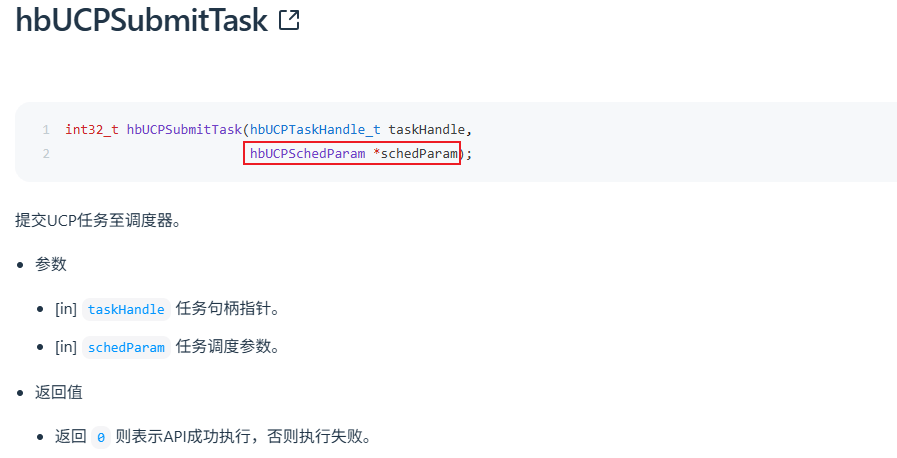
2.2 UCP 推理 API
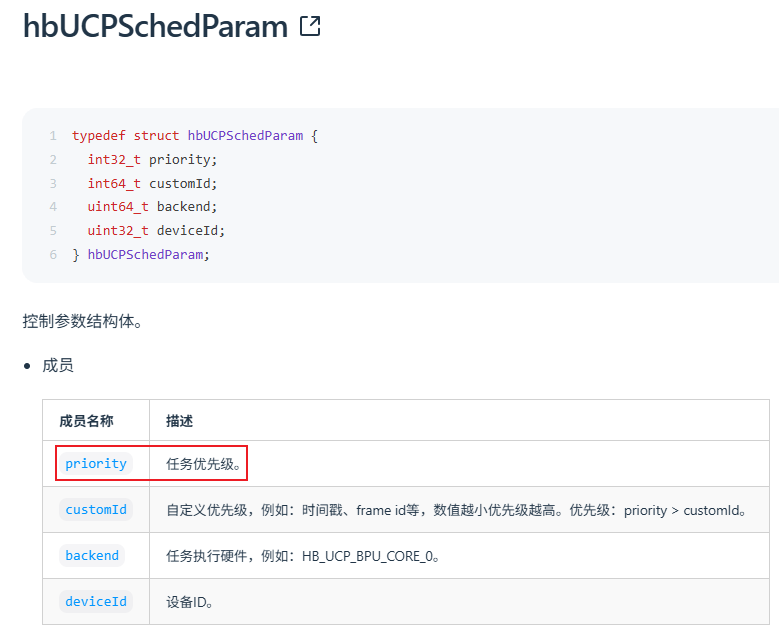
板端推理 C++代码:需要在任务提交时设置 hbUCPSchedParam.priority 参数。
优先级按照是否支持抢占,可以分为:高优抢占优先级任务、普通优先级任务。
- 配置 infer 任务优先级小于 254,则为普通任务,不可抢占其他任务。
- 配置 infer 任务优先级等于 254,则为高优抢占任务,可支持抢占普通任务。
- 配置 infer 任务优先级等于 255,则为 urgent 抢占任务,可抢占普通任务和 254 抢占任务。
注意:
- 抢占(254/255)是系统级别的,即当前进程提交的抢占任务不仅能对进程内的普通任务,也可对其他进程的普通任务实施抢占行为。抢占不需要考虑 中继 relay 或 直连 direct 模式。
- 优先级(0~253)在进程内可以按照优先级排序,跨进程优先级排序,需要启动中继模式。
2.3 工作模式
UCP 框架支持两种主要工作模式:直连模式和中继模式。系统默认运行在直连模式下。QNX 操作系统和 x86 仿真不支持中继模式。
中继模式下,支持多进程任务的统一调度,使用中继模式前,首先启动 ucp_service,service 文件位于 deps_aarch64/ucp/bin/service/ 路径下,并通过设置环境变量 HB_UCP_ENABLE_RELAY_MODE=true 来启用 Relay 模式,使得用户进程可以通过中继服务进行通信。
无论是直连模式还是中继模式,UCP 接口的调用方式保持一致,不会对编程逻辑产生影响。您可以根据实际需求灵活选择这两种模式,以满足系统在性能和灵活性方面的要求。
三、抢占示例介绍
示例 UCP trace 图如下:
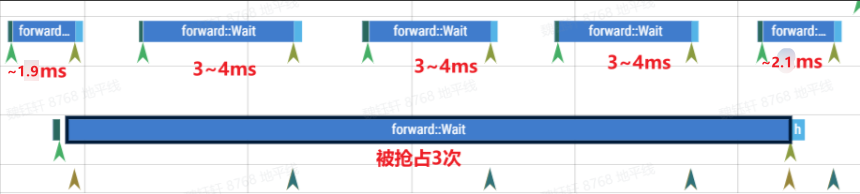
- 上面的抢占模型 A,单独运行是 1.9ms
- 下面的被抢占的模型 B,单独运行 17.1ms,且模型 B 设置的 Function call 是 1000us=1ms
分析如下:
- 模型 B 开启 Function call=1000 编译,在未发生被抢占情况时,latency 与不开启 fc 一致。
- 抢占模型 A,在任务提交抢占时,会等待 1~2ms,再开始执行模型 A(因此模型 A wait 大约 3~4ms),在等待的 1~2ms 中,模型 B 继续执行,因此模型 B 相比于单独运行,wait 只会多~6ms≈1.9*3(3 次模型 A 执行时间)。
- 模型 B 运行最后一个 function call 期间,不能被抢占,所以上面 最后那个 抢占模型 A 多等了一会,变成~2.1ms。
在 BPU Trace 中,可以看到更具体的 BPU 抢占与优先级详情,示例如下

到更具体的 BPU 抢占与优先级详情,示例如下
[外链图片转存中…(img-AEuVyAuw-1752764429000)]
图中:三个模型设置了三个优先级,其中 petr 最低优,且是分段可抢占的,googlenet 的 task_priority=255,resnet50 的 task_priority=254。