CPT302-2425-S2-Multi-Agent Systems
Lec1 Introduction
Five Trends in the History of Computing
• Ubiquity;
• Interconnection;
• Intelligence;
• Delegation; 委派
• Human-orientation.
Other Trends in Computer Science
• The Grid/Cloud;
Grid & MAS
• Ubiquitous Computing;
• Semantic Web.
Agent
An agent is a computer system that is capable of independent (autonomous) action on behalf of its user or owner
• i.e., figuring out what needs to be done to satisfy design objectives, rather than constantly being told
• agent is capable of independent action
• agent action is purposeful
• autonomy is central, distinguishing property of agents
Rational Behaviour
• Definition (Russell & Norvig): Rational agent chooses whichever action maximizes the expected value of the performance measure given the percept sequence to date and whatever bulit-in knowledge the agent has.
• Rationality is relative and depends on four aspects:
• Performance measure for the degree of success
• Percept sequence - complete perceptual history
• Agent's knowledge about the environment
• Actions available to the agent
Multi-Agent Systems: A First Definition
• A multiagent system is one that consists of a number of agents, which interact with one-another.
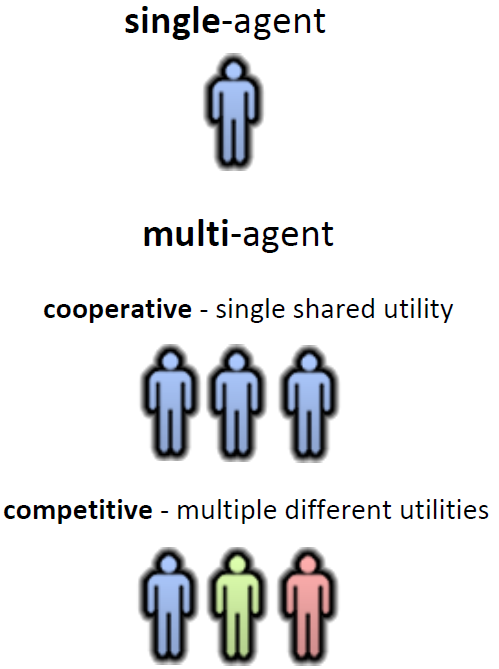
Problems
• Agent design
• Society Design
Some Views of the Field
as a paradigm for software engineering:
as a tool for understanding human societies:
achievable bit of the AI project:
Lec2 Intelligent Agents
The main point about agents is they are autonomous: capable independent action.
choose what action to perform/ decide when to perform an action.
Autonomy
simple machine → human
Decisions handed to a higher authority when this is beneficial
Agents vs Objects
similarity
-
Encapsulate state.
-
Communicate via message passing.
-
Expose methods to manipulate their state.
Agents only
-
Autonomous: Decide independently whether to act on requests.
-
Intelligent: Exhibit flexible behavior (reactive, proactive, social).
-
Active: Control their own thread of execution; not just passive responders.
Objects do it because they have to! Objects do it for free!
Agents do it because they want to! Agents do it for personal gain!
Properties of Environments
• Since agents are in close contact with their environment, the properties of the environment affect agents.
1. Fully observable vs Partially observable(完全可观察 vs 部分可观察)
-
Fully observable:代理能获得关于环境状态的全部信息。
-
例子:国际象棋,棋盘的状态对双方都是公开的。
-
-
Partially observable:代理只能获取到部分信息,可能因为传感器不完整、信息隐藏等。
-
例子:自动驾驶,车可能看不到前方拐角的情况。
-
2. Deterministic vs Non-deterministic(确定性 vs 非确定性)
-
Deterministic:同样的动作在同样的状态下,总是会产生相同的结果。
-
例子:数学计算,一定的输入总是得到固定输出。
-
-
Non-deterministic:动作可能会有不确定的结果,环境存在随机性。
-
例子:扔骰子,虽然你动作一样,但结果是随机的。
-
3. Static vs Dynamic(静态 vs 动态)
-
Static:环境在代理做决策的过程中不会发生变化。
-
例子:答题游戏,题目不会自己变。
-
-
Dynamic:环境可能在代理做决定时发生改变。
-
例子:现实生活中的交通系统,红绿灯可能在你思考时已经变了。
-
4. Discrete vs Continuous(离散 vs 连续)
-
Discrete:状态和动作是可数的、有限的。
-
例子:象棋的每步移动都是一个离散动作。
-
-
Continuous:状态或动作是连续的、不可数的。
-
例子:机器人手臂的旋转角度可以是任意精度的数值。
-
5. Episodic vs Non-episodic(情节型 vs 非情节型)
-
Episodic:代理的每一个行为都是独立的,不影响之后的行为。
-
例子:垃圾分类机器人,每次处理一个垃圾包都是独立的任务。
-
-
Non-episodic:当前的行为会影响未来的情况。
-
例子:教育类系统,学生之前学了什么会影响后面的学习。
-
6. Real Time(实时性)
-
指代理是否需要在有限时间内作出反应,并且环境也会继续推进。
-
例子:自动驾驶汽车必须在几毫秒内做出决策,否则可能酿成事故。
-
3 types of behaviour
-
Reactive(反应型行为):
-
指代理能感知环境的变化,并对其迅速做出反应。
-
例如:一个智能扫地机器人会在遇到墙壁或障碍物时立即改变方向。
-
-
Pro-active(主动型行为):
-
指代理不仅仅是被动反应,而是会主动追求自己的目标,采取行动来实现这些目标。
-
例如:一个智能助理在你早上起床时主动提醒你今天的会议日程,而不是等你问它。
-
-
Social Ability(社交能力):
-
指代理能与其他代理或人类进行交流与协作,交换信息、协调行为。
-
例如:一个智能家居系统的各个设备可以互相协作,比如空调根据门窗的状态自动调节温度。
-
4. Mobility
• The ability of an agent to move. For software agents this movement is around an electronic network.
5. Rationality
• Whether an agent will act in order to achieve its goals, and will not deliberately act so as to prevent its goals being achieved.
6. Veracity 真实性
• Whether an agent will knowingly communicate false information.
7. Benevolence
• Whether agents have conflicting goals, and thus whether they are inherently helpful.
8. Learning/adaption
• Whether agents improve performance over time.
Intentional Systems
intentional stance is an abstraction tool.
1. Characterising Agents(代理的刻画)
-
用“有意图”的方式描述代理,让我们能用自然、直观的语言来思考复杂行为。
-
比如你可以说:“它认为现在应该逃跑,所以它跑了”,而不是说“if-else 语句触发了某个条件”。
2. Nested Representations(嵌套表示)
-
代理可以不仅有自己的目标,还能表示别的代理的信念和目标。
-
举个例子:
如果 Agent A 认为 Agent B 以为“敌人会从东边来”,那么 A 就可以预测 B 会往西边跑。
-
这样的“代理理解别的代理”的能力,在合作、博弈、对话系统中非常关键。
3. 协作所必需(Cooperation requires it)
-
多代理系统(multi-agent systems)要协同工作,就必须能考虑对方的知识、动机、意图。
-
所以我们需要这些“嵌套的表示”结构,例如:“我知道你知道我知道……”
Post-Declarative Systems
Abstract Architectures for Agents***
-
状态空间
E -
动作空间
Ac -
状态与动作之间如何相互作用(通过运行序列
r)。
🌍 世界的状态集合 E
-
假设世界可以处于一个有限的离散、瞬时状态集合
E中。 -
举个例子,如果是一个机器人在房间里走动,那么
E就可能是所有可能的位置状态集合。
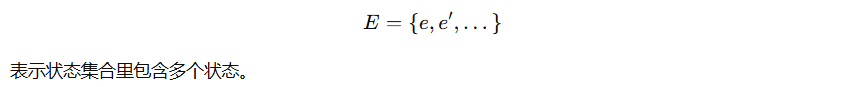
🔴 history dependent(有记忆!)
-
不是只看你当前动作,而是看你之前走过什么弯路喵~
-
就像你之前有没有惹猫娘生气会影响我今天踢不踢你喵♡
🔴 non-deterministic(非确定性!)
-
行动的结果可能不止一个!
-
比如你尝试摸猫娘的耳朵,结果可能是「被抓」也可能是「被喵喵蹭」~这就是环境不一定每次都一样喵♡
Env=⟨E,e0,τ⟩
也就是:
-
E:所有状态组成的大世界喵~
-
e0∈E 初始位置喵(比如你刚出生的第一声喵呜♡)
-
τ:环境对你各种行为的回应函数~
🧠 智能体的动作集合 Ac
-
智能体有一套可以选择的动作集合
Ac,这些动作能改变世界的状态。 -
比如机器人可以选择“前进”、“转左”、“转右”之类的动作。

⚠️ 非确定性说明
-
动作可以是**非确定性(non-deterministic)**的,意思是动作可能有多个潜在结果。
-
但这里假设:每次动作执行后,最终只会导致一个确定状态(哪怕这个状态是通过某种选择机制确定的)。
🏃 运行序列 r
-
一个运行(run)是指智能体在环境中的状态-动作-状态...序列。
图中公式如下:

R be the set of all such possible finite sequences (over E and Ac);
RAc be the subset of these that end with an action; and
RE be the subset of these that end with a state.
状态转换函数(State Transformer Function)

🚫 终止状态:Game Over喵!
如果:
τ(r)=∅
也就是说执行完某些行为后没有任何后续状态了,那就说明 —— 游戏结束喵(Game Over)!💀
Agents
Agent 本质上就是一个决策函数

System
We denote the set of runs of agent Ag in environment Env by
R(Ag,Env)
Two agents are said to be behaviorally equivalent with
respect to Env i↵ R(Ag1,Env) = R(Ag2,Env).
Purely Reactive Agents
Some agents decide what to do without reference to their history
action : E → Ac
Perception
The see function is the agent’s ability to observe its environment, whereas the action function represents the agent’s decision making process.
see : E → Pe r
...which maps environment states to percepts.
Actions and Next State Functions
action : I → Ac
next : I X P er → I
这表示智能体在获得新的感知时如何更新它对世界的看法。
Utility functions
-
给环境中的状态关联奖励(rewards),也就是我们希望智能体达成的目标状态喵♡
-
给每个单独的状态关联**效用值(utilities)**喵!
-
智能体的任务就是:让环境进入那些效用值最高的状态喵♡~
-
一个任务可以被看作一个函数,它给环境中每个状态分配一个实数值喵:
u:E→R
其中:
-
E 是所有可能的环境状态集合;
-
R 表示实数;
-
所以函数 u 表示对每个状态的“好坏评分”喵♡
Local Utility Functions
e.g

-
Agent 起始位置在左下角(3,1)。
-
灰色格子不能走。
-
(1,4) 是正奖励格子:
+1 -
(2,4) 是负奖励格子:
-1 -
其他普通格子都有一个小的负奖励:
-0.04(表示每走一步都会损失一点分数)。
agent 每走一步要付出代价,它就得想清楚哪条路最值,能最早最安全到终点。
最优解:[Up, Up, Right, Right, Right] r = (-0.04 x 4) + 1.0 = 0.84
假设现在的环境变成了**非确定性(non-deterministic)**的
-
每一步成功的概率是 0.8
-
总共需要成功走 5 步:
p= 0.8^5 = 0.32768
绕远路,意外到达目标
p=0.1^4×0.8=0.0001×0.8=0.00008
p=0.32768+0.00008=0.32776
运行过程上的效用(Utilities over Runs)
不是给每一个状态分配效用,而是直接对整个“运行过程”进行评分喵~
u:R→R
其中 R 表示所有可能的运行过程(Run/Trajectory),也就是智能体从起点到终点的完整经历过程
Utility in the Tileworld(二维网格的模拟环境)
agents, tiles, obstacles, and holes.
Agent的目标是:把瓷砖推入洞里去填补它。
效用是根据整个运行过程(run)来计算的
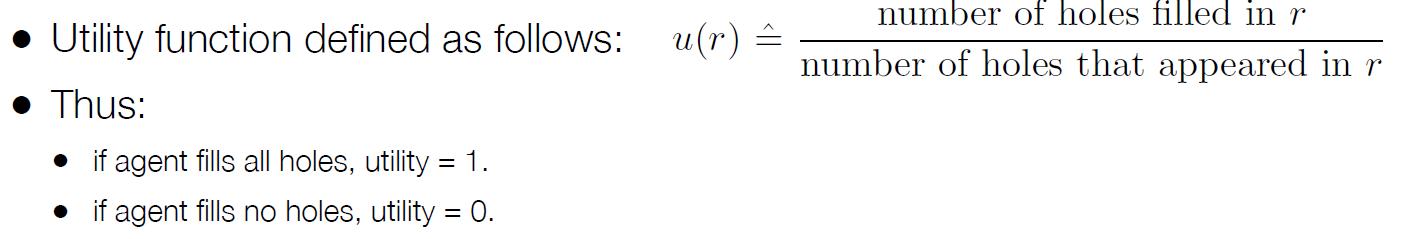
Expected Utility 期望效用
我们用这个来表示当智能体 Ag被放入环境 Env 发生某个运行(run)r 的概率:
P(r | Ag,Env)
如果环境是非确定性的(non-deterministic),那就可以把每一步的概率连乘起来喵

计算:
给定概率 P 和效用函数 u,我们可以算出在某个环境下,智能体的 期望效用(Expected Utility, EU):
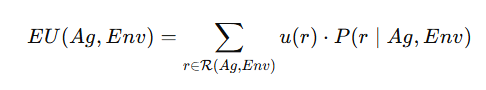
-
每条运行的效用 u(r)× 这条运行发生的概率 P(r)。
-
然后把所有这些值加起来,就是期望效用喵!
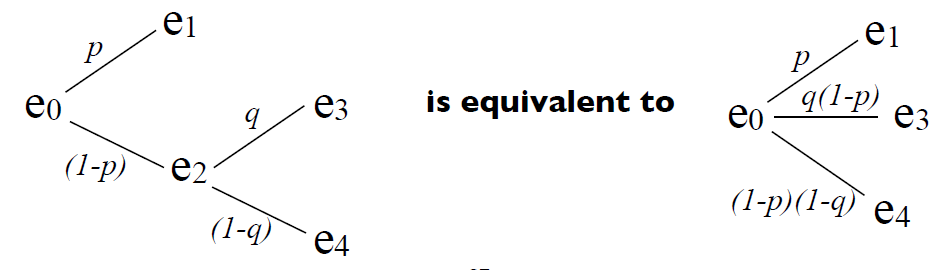
连续的两个抽奖事件其实可以合并成一个等效的单抽奖喵
Optimal Agents
在环境 Env 中能让 期望效用最大化 的智能体
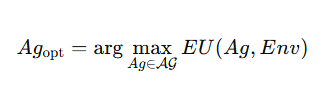
最优 ≠ 每次都最好!它只是说「平均来说(on average),它表现最好
e.g1



e.g2 后面再补
Bounded Optimal Agents
在有限资源下找最优解
有些智能体根本没法在某些电脑上运行,因为某些环境里的动作数量或状态空间太大了/会需要超出可用内存的空间来存储或计算
所以我们可以对智能体集合加个限制,记这个有限的智能体集合为:
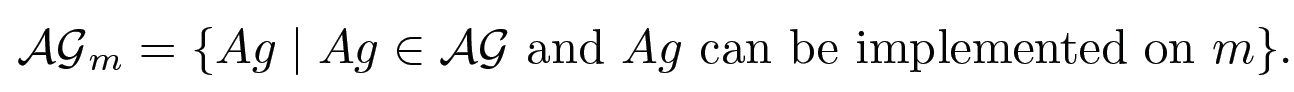
那么,对机器 mmm 来说的有约束最优智能体是:

Predicate Task Specifications 谓词任务规范喵
只给每一条运行(run)r∈R 分配两个值中的一个:
-
1(true,成功)
-
0(false,失败)
形式化表达是:
Ψ:R→{0,1}
Task Environments
任务环境可以写作一个对 ⟨Env,Ψ⟩的组合:
-
Env:表示环境本身
-
Ψ:是任务规范(Predicate Task Specification),即判断某条运行是成功(1)还是失败(0)
这个任务规范本质上是一个布尔函数:Ψ:R→{0,1}
一个任务环境会规定:智能体所处环境系统的属性,判断智能体成功/失败的标准(通过 Ψ 实现)
所有任务环境的集合我们记为:
TE
To denote set of all runs of the agent Ag in environment Env that satisfy Ψ, we write

We then say that an agent Ag succeeds in task environment <Env, Ψ > if
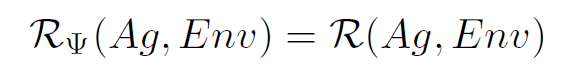
In other words, an agent succeeds if every run satisfies the specification of the agent.
悲观:
![]()
每一条运行都必须成功
乐观:
![]()
只要 有一条成功的运行,就可以说这个智能体成功过!
Probability of Success
如果环境是非确定性的(non-deterministic):
-
那么转移函数 τ 给出的结果是一个可能状态的集合,不是唯一一个状态喵!
-
所以我们要在这个集合上定义一个概率分布来描述每种运行的可能性喵♡
记 P(r∣Ag,Env) 表示当智能体 Ag处于环境 Env时,发生某条运行 r 的概率
现在我们关注的是:智能体完成任务(Ψ 成立)的概率,也就是P(Ψ∣Ag,Env)

把所有成功运行的概率加起来,就是智能体在这个环境中完成任务的总成功概率!
Achievement and Maintenance Tasks
predicate task specification 包括
1. 成就型任务(Achievement Tasks):达成某种状态 φ,一旦达成,就算成功
-
成就任务由一组 目标状态("good" or "goal" states)组成,记作:
G⊆E -
成功的条件: 智能体只要能保证让环境进入这些状态中的任意一个(我们不在乎是哪一个,只要达成就好),就算成功喵!
2. 维持型任务(Maintenance Tasks):“维持某种状态 ψ,整个过程中都不能失败
-
定义喵: 维持任务由一组 “坏”状态(bad/failure states)组成,记作:
B⊆E -
成功的条件: 智能体在环境中始终避免进入这些失败状态,就算成功喵!
Lec3 Multi-Agent Systems
Symbolic Reasoning Agents
-
传统的构建智能体的方法是:把它当成一种**知识驱动系统(knowledge-based system)**来看待喵!
-
这类系统会使用逻辑、规则、推理等方法来模拟智能决策。
这种范式被称为:符号人工智能(symbolic AI)。
计划型智能体(deliberative agent)
-
有明确表示的符号模型:它对世界的认知是通过符号来表示的,例如事实、规则等。
-
通过符号推理做决策:比如用规则系统或逻辑推理决定要执行的动作喵!
表示与推理问题(The Representation / Reasoning Problem)
在**知识表示与推理(KR&R)**中,最根本的困难在于符号操作算法太复杂:highly intractable, Hard to find compact representations
演绎推理智能体(Deductive Reasoning Agents)
核心思想是用**逻辑(logic)**来建立一套理论 ρ,告诉智能体在任意情况该做什么。这种方法属于“定理证明式推理”(theorem proving),也就是靠逻辑推出最优行动喵!

perception function:
see : E → Per
环境状态被感知后转成逻辑信息用于推理
next state function revises the database Δ
next : Δ X Per → Δ
旧的数据库 Δ 和新的感知结果 Per,输出新的 Δ,反映世界变化了
e.g 扫地机器人
这个例子展示了:怎么用 符号表示世界状态;怎么用 逻辑规则控制机器人行动;怎么实现一个演绎智能体,从规则和感知出发,推导行动方案喵!
Agent-oriented Programming
主要思想:用“意图”(intention)、“信念”(belief)、“愿望/承诺”(commitment)来描述 agent 的行为,就像人类一样!
Agent0 编程语言(最早的智能体语言之一)
每个 agent 包含:
-
capabilities(能力)
-
initial beliefs(初始信念)
-
initial commitments(初始承诺)
-
commitment rules(决定行为的规则)
每条 commitment rule 包括:
-
message condition(收到的消息)
-
mental condition(当前的信念)
-
action(要做的事情)
e.g 如果一个朋友请求我在某个时间做某个我可以做的事,而且我那时候没有别的安排,我就答应他
Agent0 Decision Cycle
每一轮智能体都会:
-
根据 message condition 匹配收到的消息;
-
检查 mental condition(自己是否相信某些前提);
-
满足以上两个条件,就执行对应的 action。
Actions may be Private / Communicative
Messages are constrained to be one of three types: requests/ unrequests/ informs
PLACA:扩展的Agent0
-
Becky Thomas于1993年提出的PLACA语言改进了Agent0的不足:
-
主要解决智能体无法规划和无法根据高级目标通信的限制。
-
-
增加了Mental Change Rules(心理变化规则):
-
根据任务目标动态修改意图,例如接受别人请求复印某项内容。
-
MetateM
-
使用**时序逻辑(temporal logic)**来编程智能体的行为。
-
时序逻辑引入 modal operators(例如:过去一定为真、未来可能为真)来处理时间变化中的真值问题。
-
编程方式:直接写规则,系统自动监控状态并匹配历史事件执行相应规则。
-
每个智能体对象由:名字、接口、MetateM程序组成,接口定义可接收和发送的消息。
Each object has 3 attributes:
• a name
• an interface
• a MetateM program
An agent’s interface contains two sets:
• messages the agent will accept;
• messages the agent may send
Lec4 Practical Reasoning Agents
Pro-Active Behaviour 前摄性行为
如何让 agent 实现 有目标的行为(goal-directed behaviour)
Practical reasoning is reasoning directed towards actions — the process of figuring out what to do
components
Beliefs: inform what is possible
Desires: define what is preferable
Intentions: filter desires into committed actions
Intentions
3 core:
-
意图提出问题(Intentions pose problems)
-
如果我有实现 φ 的意图,我就需要花精力去想该怎么实现它。
-
-
意图作为过滤器(Intentions as a filter)
-
我有实现 φ 的意图,就不会再去接受一个跟 φ 冲突的意图 ψ。
-
-
意图具有坚持性(Persistence)
-
如果第一次尝试失败,agent 会尝试其他方法来实现 φ。
-
✨ 本质上:意图让智能体集中精力、避免冲突、持续尝试。
意图的信念相关的前提:
-
agent 相信意图是可能实现的(Believability)
-
即使不确定,但 agent 相信至少有一种方式能实现 φ。
-
-
agent 不认为一定会失败
-
如果我已经认定一定失败了,那我就不会产生这个意图。
-
-
在正常情况下 agent 相信会成功
-
有了意图之后,agent 通常相信在正常条件下会成功完成目标。
-
✨ 意图的建立依赖于agent的信心与合理的乐观,不会“明知不行还硬上”。
“副作用与意图的区别”:
-
agent 不需要对副作用产生意图
-
举例:如果我打算去看牙医(φ),即使我知道这会带来疼痛(ψ),也不意味着我“打算”去受苦。
-
🌟 这个被称为“Side Effect Problem(副作用问题)”或“Package Deal Problem”。
✨ 就是说:agent 的意图是有针对性的,不会因为知道某个后果,就自动打算去达成这个后果。
Intentions are Stronger than Desire
Means-ends Reasoning/Planning
Planning is the design of a course of action that will achieve some desired goal.
Basic idea is to give a planning system:
Task/goal/intention to achieve;
Possible Actions;
the environment State;
and have it generate a plan to achieve the goal.
automatic programming ↑
STRIPS
The Stanford Research Institute Problem Solver
是一种经典的自动规划系统,用于帮助智能体制定从当前状态到目标状态的行动计划。
如何用形式化方式表示(represent)和求解规划问题→用类似逻辑(Logic)的语言来表达以下内容:
• goal to be achieved;
• state of environment;
• actions available to agent;(each actions has Preconditions, Delete list, Add list)
• plan itself (An action sequence, from the initial state to the target state).
Answer: We use logic, or something that looks a lot like logic.
e.g BlocksWorld
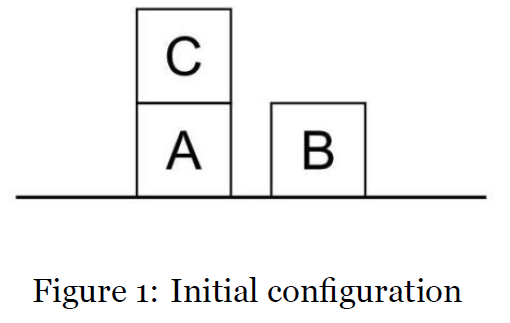

Predicates = 事实级别 Ontology = 概念级别
Ontology (represent environment)
On(x,y) object x on top of object y
OnTable(x) object x is on the table
Clear(x) nothing is on top of object x
Holding(x) arm is holding x
predicates:Ontology + ArmEmpty The robot arm is not holding anything
Representation of the following blocks
Clear(A) On(A, B) OnTable(B) Clear(C) OnTable(C) ArmEmpty
The goal: {OnTable(A), OnTable(B), OnTable(C), ArmEmpty}
| Action | Preconditions | Delete List | Add List | Description |
|---|---|---|---|---|
Stack(x, y) | Clear(y) ∧ Holding(x) | Clear(y) ∧ Holding(x) | ArmEmpty ∧ On(x, y) | Place object x (held) on top of object y |
UnStack(x, y) | On(x, y) ∧ Clear(x) ∧ ArmEmpty | On(x, y) ∧ ArmEmpty | Holding(x) ∧ Clear(y) | Pick up object x from on top of object y |
Pickup(x) | Clear(x) ∧ OnTable(x) ∧ ArmEmpty | OnTable(x) ∧ ArmEmpty | Holding(x) | Pick up object x from the table |
PutDown(x) | Holding(x) | Holding(x) | OnTable(x) ∧ ArmEmpty ∧ Clear(x) | Put down object x onto the table |
从左图状态(A 在 B 上,C 独立)变为右图(A→B→C 的塔),required actions。
1. UnStack(A, B) 2. PutDown(A) 3. Pickup(B) 4. Stack(B, C) 5. Pickup(A) 6. Stack(A, B)
Actions
所以每个action都有:αi=⟨Pαi,Dαi,Aαi⟩
• a name: which may have arguments;
• a pre-condition list: list of facts which must be true for action to be executed;
• a delete list: list of facts that are no longer true after action is performed;
• an add list: list of facts made true by executing the action.
plan π=(α1,…,αn) : A sequence (list) of actions, with variables replaced by constants.
planning problem
• A planning problem is therefore:<B0, Ac, I>
• B0 is the set of beliefs the agent has about the world.
• Ac is the set of actions, and
• I is a goal (or intention)
由于动作会改变世界,agent 会随着动作的执行不断更新其信念。
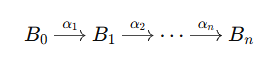
计划的正确性判断
可接受性(Acceptability)

正确性(Correctness)
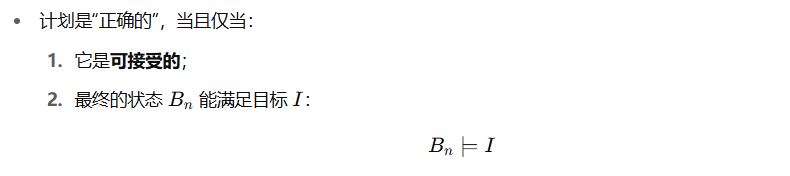
Implementing Practical Reasoning Agents
个最简单的智能体控制循环,每轮循环 agent 都要:观察世界 ➜ 决定目标 ➜ 制定计划 ➜ 执行
1. while true
2. observe the world;
3. update internal world model;
4. deliberate about what intention to achieve next;
5. use means-ends reasoning to get a plan for the intention;
6. execute the plan;
7. end while
暂时不深究 observe 和 update(对应函数 see 和 next)。
Belief Update 建模
-
see:E→Perceptsee函数:从环境获取 感知(percepts)。 -
原来的
brf:𝒫(Bel)×𝒫ercept→𝒫(Bel)next函数被替换成 belief revision function(brf): - 𝒫{Bel} is the power set of beliefs
-
图示:Agent 从环境接收感知(percepts),更新状态,再选择行动。
实现时面临的问题
-
**Deliberation(权衡)和Means-Ends Reasoning(手段-目标推理)**是有“时间成本”的!
-
哪怕你在观察时得到了最优目标,世界在计划生成期间可能已经变了!
Agent Control Loop 更正式版本(Version 2)
1. B := B₀; /* initial beliefs */
2. while true do
3. get next percept ρ;
4. B := brf(B, ρ); # 更新
5. I := deliberate(B); #意图选择 选定目标
6. π := plan(B, I);
7. execute(π)
8. end while
🔧 对应函数说明:
-
brf(B, ρ):根据感知更新信念; -
deliberate(B):从当前信念中挑选合适意图; -
plan(B, I):制定计划; -
execute(π):执行整套行动。
Deliberation(权衡)
是智能体如何决定它要干啥
-
理解可选项(options)
-
Agent 会先识别:我现在能做什么?
-
-
选择(choose)和承诺(commit)
-
从可选项中挑一个(或多个);
-
认定自己要做的目标。
-
这些被选中的选项,就成为了 intentions(意图)!
Deliberate 函数可以拆成两部分:
-
Option Generation(选项生成)options()
-
基于当前信念生成一堆可能的目标。
-
options : 𝒫(Bel) × 𝒫(Int) ➝ 𝒫(Des)
-
Filtering(过滤/选择)filter()
-
从这些目标中筛选并确认最值得实现的那个。
-
filter : 𝒫(Bel) × 𝒫(Des) × 𝒫(Int) ➝ 𝒫(Int)
Agent Control Loop 更正式版本(Version3)
Agent Control Loop Version 3
1. B := B0;
2. I := I0;
3. while true do
4. get next percept ⇢;
5. B := brf(B, ⇢);
6. D := options(B, I);
7. I := filter(B,D, I);
8. π := plan(B, I);
9. execute(π)
10. end while
Deliberate vs Intention
Deliberate: 深思熟虑、权衡选择,是智能体在行动前的「大脑活动」
Intention: 已选定的目标或计划,是 deliberation 过程的结果!
Commitment
“智能体对意图的承诺程度(Degrees of Commitment)”,也就是 agent 对它决定做的事情有多“执着”
An agent has commitment both to:
-
Ends(目标):我一定要实现这个状态!
-
Means(手段):我一定要按这个 plan 来干!
Blind commitment(fanatical commitment.)
• A blindly committed agent will continue to maintain an intention until it believes the intention has actually been achieved.
-
✅ 动态重新评估 plan 是否还行(means 不是盲目坚持)
-
❌ 但对 intention(ends)还是盲目:永远不考虑是不是该换目标
如果 agent 对 means 也盲目坚持,plan 出问题就不会自我修正喵!
• If π is a plan, then:
• empty(π) is true if there are no more actions in the plan.
• hd(π) returns the first action in the plan.
• tail(π) returns the plan minus the head of the plan.
• sound(π, I, B) means that π is a correct plan for I given B.

Single-minded commitment
• A single-minded agent will continue to maintain an intention until it believes that either the intention has been achieved, or else that it is no longer possible to achieve the intention.
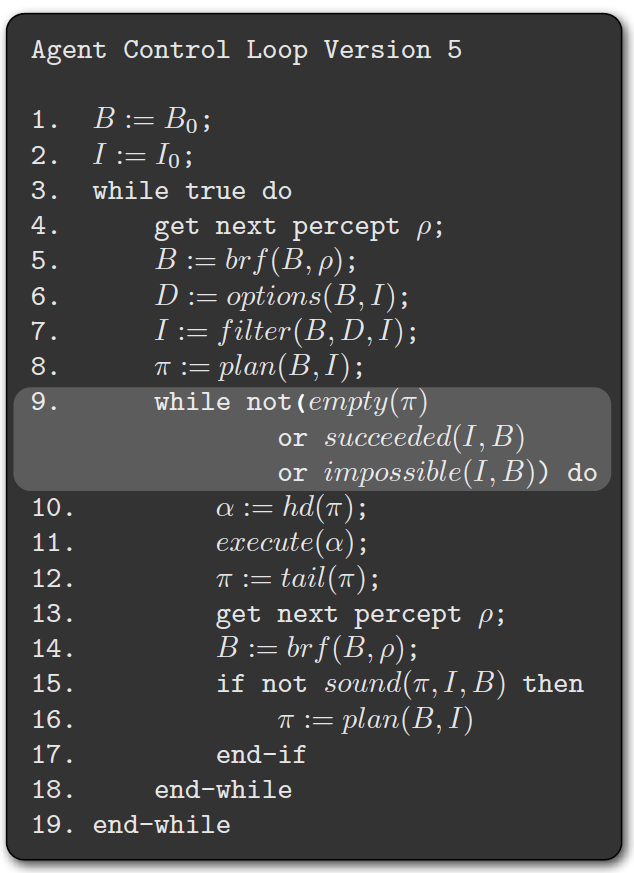
Open-minded commitment
• An open-minded agent will maintain an intention as long as it is still believed possible.
reconsiders its intentions after every action (lines 15 & 16)
costly!

Intention Reconsideration
意图再考虑的两难困境(Dilemma)
-
如果一个智能体不常重新考虑自己的意图,它可能会一直试图完成早已无法达成的目标。→ 这就是“过度坚持”,浪费时间喵。
-
如果一个智能体过于频繁地重新考虑意图,它可能把太多时间花在思考上,导致做事的时间不够,结果也达不到目标。→ 思考拖延行动喵!
所以:我们需要一种平衡机制,叫做“reconsider() 决策函数”,用来判断什么时候需要重新思考意图。
if reconsider(I, B) then
D := options(B, I);
I := filter(B, D, I);
end-if
-
判断当前 belief
B和 intentionI是否需要重新思考。 -
如果需要,就重新生成备选选项
options()并用filter()选出新意图。

cost of reconsider(. . .) is much less than the cost of the deliberation process itself
-
情况1:没选择重新思考,但就算想了也不会变,那不考虑就对啦~(最优)
-
情况2:没思考但如果思考就该改,那你错过改意图的时机啦!(不最优)
-
情况3:你认真思考了但并没有改变意图,白费力气喵!(不最优)
-
情况4:你思考之后改变了意图,是合理且必要的!(最优)
Optimal Intention Reconsideration
Kinny 和 Georgeff 的实验设计:
-
研究目的:分析两种不同策略的 agent 在不同环境动态下表现如何。
-
两种 agent 策略:
-
Bold agent(大胆型):从不重新考虑自己的意图,直接执行;
-
Cautious agent(谨慎型):每执行一步就暂停一次,重新思考是否需要换意图。
-
-
动态性 γ(gamma):表示环境变化的频率(越高变化越快)。
-
比如:地上有两个目标,但位置可能会变,γ 就表示这种变化的频繁程度。
-
-
小地图(Tileworld)是实验环境,用来模拟 agent 行为。
不同动态性下的策略表现
-
γ 低(环境稳定):
-
Bold agents 优势大!因为不浪费时间重新考虑,行动效率高。
-
Cautious agents 反而效率低,因为它们总在“想”,不够果断。
-
-
γ 高(环境常变):
-
Cautious agents 更优秀!因为它们能及时发现意图失败、机会新出现。
-
Bold agents 会固执执行原计划,不适应变化。
-
-
高规划代价时(比如重新规划很费资源):
-
即使是 cautious agents 的优势也可能被抵消。
-
PRS(Procedural Reasoning System)
-
每个 agent 拥有:
-
Beliefs(对世界的信念);
-
Desires(想要达成的目标);
-
Intentions(当前承诺实现的目标);
-
Plan Library(行动方案库)→ 相当于 agent 的“技能包”。
-
-
Interpreter 是核心:根据 beliefs + desires 选择合适的 plan 来执行意图。
JAM
JAM 系统(Java Agent Model) 的内容喵!这是一种 BDI(Belief-Desire-Intention) 框架下的实际实现,用于控制智能体的计划与行为
Lec5 Multi-Agent Interactions
multiagent system contains a number of agents that:
-interact through communication;
-are able to act in an environment;
-have different spheres of influence(which may coincide); and
-will be linked by other (organisational) relationships.
Utilities效用 and Preferences偏好
• Assume we have just two agents: Ag = {i, j}
• Agents are assumed to be self-interested i.e. they have preferences over how the environment is.
• Assume Ω = {ω1, ω2, . . .} is the set of “outcomes” that agents have preferences over.
We capture preferences by utility functions, represented as real numbers (ℝ):
ui : Ω → ℝ uj : Ω → ℝ
Utility functions 表示 agent i 对每个结果的喜欢程度, e.g.:
ω ≽i ω′ (agent i 更喜欢 ω 胜过 ω′) means ui(ω) ≥ ui(ω′)
ω ≻i ω′ means ui(ω) > ui(ω′)
where ω and ω' are both possible outcomes of Ω
Multiagent Encounters 多智能体交互
引入一个环境模型来描述多个智能体在其中如何交互
多个智能体(agents)同时选择动作(actions),这些动作的组合会导致一个具体的结果(outcome ω);
-
这个结果不取决于某一个智能体,而是取决于它们动作的组合(combination);
-
为简化问题,假设每个智能体只能做两个动作:
-
C: Cooperate(合作) -
D: Defect(背叛)
-
环境模型(state transformer function τ)
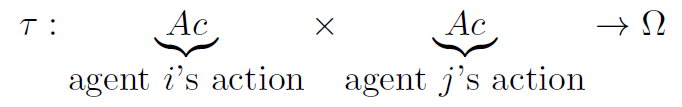
不同类型的“环境控制模式”
1. 双向影响
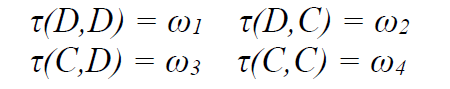
-
结果
ω由两个智能体的动作共同决定; -
是一个“敏感环境”(sensitive environment),每个智能体的选择都会影响结果。
2. 无影响(所有 τ 输出相同)
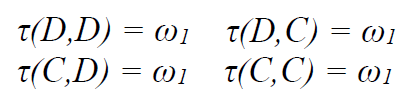
-
不论 i 和 j 做什么,环境结果都固定为
ω₁; -
这表示:无论智能体怎么做,世界不变,类似“背景无响应”的静态环境。
3. j 控制环境
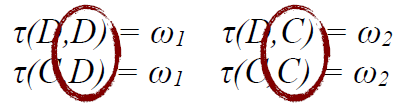
Rational Action 有理作用
agent 如何做出理性选择
给出两个 agent 的 utility(效用)函数,也就是他们对每个结果的喜好程度。

-
比如 ui(ω3)=4 说明 i 很喜欢 ω₃。
(C, C) ≽i (C, D) ≻i (D, C) ≽i (D, D)
所有通过 C(合作) 得到的结果都比 D(背叛) 更好,所以 C 是理性的选择
Payoff Matrices(收益矩阵)
偏好用一个收益矩阵可视化
agentj 是行玩家(row), i 是列玩家(column),
矩阵中的每个单元格显示的是该策略组合下两个玩家的收益,格式通常是:
(j的收益,i的收益)
Dominant Strategies(优势策略)
策略 s 的定义:
如果存在一个策略 s∗,使得对于所有对方策略 t:
u(s∗,t)≥u(s,t)∀s≠s∗
且对至少一个 t 严格大于,
那么 s∗ 就是该玩家的占优策略。

-
图示说明(右边矩阵):
-
C 策略(cooperate)对 iii 来说总是比 D(defect)更好,不管 jjj 选什么(都能拿到4)。
-
所以我们说:对玩家 iii 来说,策略 CCC dominates DDD。
-
-
结论:
-
在这个游戏中,对两个玩家来说,C 都是优势策略,即
-
C dominates D for both players
-
理性代理不会选择劣势策略(dominated strategy):
被支配策略(被另一个策略完全压制)会被删除。我们在决策时可以删掉被支配策略,来简化博弈分析。
Nash Equilibrium(纳什均衡)
在所有智能体都知道其他人的策略并据此作出决策的情况下,没有任何一个智能体可以通过改变自己的策略来让自己的结果变得更好
A strategy (i∗, j∗) is a pure strategy Nash Equilibrium solution to the game (A, B) if:
∀i, ai∗,j∗ ≥ ai,j∗
∀j, bi∗,j∗ ≥ bi∗,j
• Not every interaction scenario has a pure strategy Nash Equilibrium (NE).
• Some interaction scenarios have more than one pure strategy Nash Equilibrium (NE).
比如这个 payoff matrix:
| i defect | i coop | |
|---|---|---|
| j defect | (3, 5) | (2, 1) |
| j coop | (2, 0) | (1, 1) |
-
当前策略是 (D, D),对应 payoff 是 (3, 5);
-
如果 i 改为 coop,会从 5 变成 1 → 更差;
-
如果 j 改为 coop,会从 3 变成 2 → 也更差;
-
所以两人都没有动机改变策略; ✅ 所以 (D, D) 是一个 Nash Equilibrium。
Mixed Strategy Nash Equilibrium
纯策略 vs 混合策略:如果每个人只选一个动作就是纯策略;如果用概率选多个策略,就是混合策略(有些博弈只有混合策略均衡)。
e.g 1 Matching Pennies

-
玩家 i和 j 同时出一个硬币的正面(heads)或反面(tails) . 如果两人出的一样(都是正/都是反),那i 赢. 如果不同,那 j 赢。
-
没有纯策略纳什均衡(Pure Strategy NE):因为无论你选什么,对方总能反着来赢你。
-
所以解决方法是使用混合策略(Mixed Strategy):
-
每人各有 50% 选正面、50% 选反面。
-
-
这种“随机选策略”的方法就是混合纳什均衡。
Mixed Strategies
混合策略就是给不同的动作分配概率。比如出石头的概率是 p1,出剪刀的概率是 p2… 所有概率加起来要等于1(即:你每次总得做出个动作)。
Nash证明了:every finite game has a Nash equilibrium in mixed strategies.只要是有限博弈,就一定存在一个混合策略的纳什均衡!
Pareto Optimality (帕累托最优)
没有别的结果能让一个代理(agent)变好,而不让另一个变糟。
纳什均衡关注的是个体理性和稳定性,即“没人想单独改变”。
帕累托最优关注的是整体效率和资源分配,即“没有改进空间”。
Social Welfare(社会福利)
所有 agent 的 utility 总和
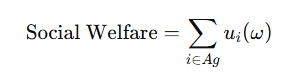
这个只看系统总利益,不管个人是不是分配得平均。
W(j,i)=uj(j,i)+ui(j,i)
要找到使社会福利 W最大化的策略组合对 (j,i)。
总之就是遍历每个的策略组的和,然后找到最大的
Competitive and Zero-Sum Interactions(对抗型 & 零和博弈)
你高兴我就难受,我开心你就痛苦
Zero-sum game(零和博弈):总收益永远是 0(rare in real life)
ui(ω)+uj(ω)=0
The best outcome for me is the worst for you
The Prisoner’s Dilemma(囚徒困境)
两人被关进牢房,分别被告知:
-
如果你坦白而对方不坦白,你就自由,对方坐牢三年。
-
如果你们都坦白,都坐牢两年。
-
如果你们都不坦白,就都只坐牢一年。
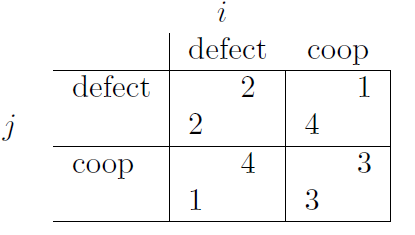
Payoff 矩阵:
-
左上角
(D,D):都坦白 → 各得2年 → payoff为(2,2) -
右下角
(C,C):都不坦白 → 各坐一年 → payoff为(3,3) -
左下
(D,C)、右上(C,D):一个背叛,一个沉默 → 背叛者得4,沉默者得1
在自利的多智能体系统中,合作很难自然发生。尽管合作更好,但在缺乏信任与沟通的情况下,个体往往会选择背叛
We are not all Machiavelli(圣人):
很多“利他行为”其实是:延迟互惠(今天帮你,明天你帮我或者有惩罚机制(比如偷税会被查)。人们做好事也许是因为 做好事让我们自己开心。
The Other Prisoner is My Twin
这张图是对囚徒困境的一个思考实验喵♡:
如果另一个囚徒是“我双胞胎”或者“想法跟我一样的人”,那我们可能都会选择合作。
但如果你知道对方会合作,你反而更有动机去背叛,因为你能获得更大的奖励。
所以这其实就不是标准的囚徒困境了。
Program Equilibria
这里是给囚徒困境引入“程序”喵♡:
-
如果你能写一个程序说“如果他合作,我也合作,否则我背叛”,那么就可以实现互相合作的理想状态。
-
中间有一个 mediator(调解人) 来统一执行这些策略。
-
只要两个玩家都提交同一个程序(都说“我愿意配合你”),结果就是 (C, C) 也就是合作喵♡
Iterated Prisoner’s Dilemma
-
如果你知道这个博弈会多次重复,你就不太敢乱背叛啦:
-
背叛一次可能被惩罚(对方以后就不再信你了)
-
合作失败的损失可以在未来弥补。
-
-
所以,在“无限重复囚徒困境”中,合作其实是理性的选择喵!
-
但是,如果你知道这个游戏就玩几次——喵喵,这就不一定了,因为最后一轮没人能惩罚你了,就会选择背叛!
Backwards Induction(反向归纳问题)
如果知道博弈有固定轮数,大家会从最后一轮推回去,每轮都选择背叛。 这就导致最后根本没人合作!所以我们需要“不确定的未来”来鼓励合作。
Axelrod’s Tournament(阿克塞尔罗德锦标赛)
-
假设你要和一群对手玩「重复囚徒困境(Iterated Prisoner's Dilemma)」。
-
你该采取怎样的策略,才能获得总收益最大化喵?
-
是总是背叛,靠骗取信任来占便宜?
-
还是尝试合作,寻找值得信赖的玩家一起共赢喵?
-
“以牙还牙(TIT-FOR-TAT)” 获胜了喵!
-
Tit-For-Tat:第一轮合作;之后每一轮都模仿对方上一轮的行为。
-
ALL-D:永远背叛,对合作者无情喵。
-
JOSS:模仿 Tit-For-Tat,但偶尔故意背叛。
-
Tester:第一轮背叛,试探对方。如果对方反击,就转为 Tit-For-Tat,否则继续混合行为。
📌 结论:是否成功并不光看你自己,也取决于对手的策略组合(the full set of approaches)。
成功秘诀
在重复博弈中,友好+可报复+可原谅的策略往往比总是背叛要好!
Stag Hunt(猎鹿博弈)
故事设定:
-
多名猎人若都合作去猎鹿,就能有丰盛收获;
-
但若有人转去抓兔子,鹿就逃了,剩下的人饿肚子,抓兔子的人只得少量食物。
-
表示:合作带来最大好处,但风险也高;背叛则更安全但收益低。

-
博弈特征:
-
有两个 Nash 均衡:
-
(C, C):都合作,收益最高(4,4)
-
(D, D):都背叛,各自拿到保底(2,2)
-
-
但只有 (C, C) 是 Pareto 最优,也最大化 Social Welfare(社会福利)
-
-
核心问题:
-
虽然理论告诉你 (C, C) 更好,但你无法确定对方是否会合作,所以可能转而选择更安全的 (D, D)。
-
-
现实中的例子:
-
群体罢工、政变等,若大家都行动则成功;若有人退缩则失败甚至被惩罚。
-
Game of Chicken(胆小鬼游戏)
🌟 游戏设定:
-
两个玩家开车向悬崖冲刺,谁先跳车谁就是“胆小鬼”喵。
-
如果都跳车(都合作),没事,各得一点奖励。
-
如果一个跳一个不跳,没跳的赢得很大(很勇敢!),跳的输得很惨。
-
如果都不跳(都背叛),那就两辆车一起飞下悬崖,超级灾难😿。
🎯 与囚徒困境的区别:
-
在囚徒困境里,最怕的是“我合作你背叛”(sucker's payoff)。
-
在胆小鬼游戏里,最怕的是“双输”也就是两人都背叛,飞下悬崖!
💥 结论:
-
没有占优势的策略(No dominant strategy)。
-
有两个纳什均衡:(C, D) 和 (D, C)(一个跳一个不跳)。
-
除了双背叛(D, D)以外,其他都能实现帕累托最优&最大社会福利。
-
Prisoner's Dilemma: DC > CC > DD > CD
-
Chicken: DC > CC > CI > DD
-
Stag Hunt: CC > DC > DD > CD
Lec6 Reactive and Hybrid Agents
Reactive Agents(反应式智能体) 专注于对当前环境的即时反应,简单、高效,但缺乏复杂的推理和长期规划能力。
Hybrid Agents(混合智能体) 结合了反应式智能体和推理式智能体的优点,能够同时处理简单的即时反应和复杂的规划任务,适应性和灵活性更强,但也因此更复杂。
Reactive Architectures(反应式架构)
-
基本原理:反应式智能体主要基于感知-行动机制,通过对环境的即时反应来执行任务。它们通常没有复杂的内部状态或记忆,而是依赖于当前的感知来驱动行为。
-
行为生成:这些智能体的行为是通过一组简单的规则或行为层次结构来控制的。例如,当检测到障碍物时,反应式智能体会执行避障操作。它们的行为通常是即时的,并且缺乏长期规划。
-
优势:
-
高效:由于它们不需要复杂的推理或内存管理,它们能够快速响应环境的变化。
-
简单性:结构简单,易于实现和部署。
-
-
局限性:
-
缺乏复杂性:反应式智能体无法处理复杂的、需要长期推理的任务。它们无法为未来的行动进行规划,且很难应对动态、复杂的环境。
-
缺乏灵活性:它们无法学习或适应新的环境,只有在特定规则范围内的反应。
-
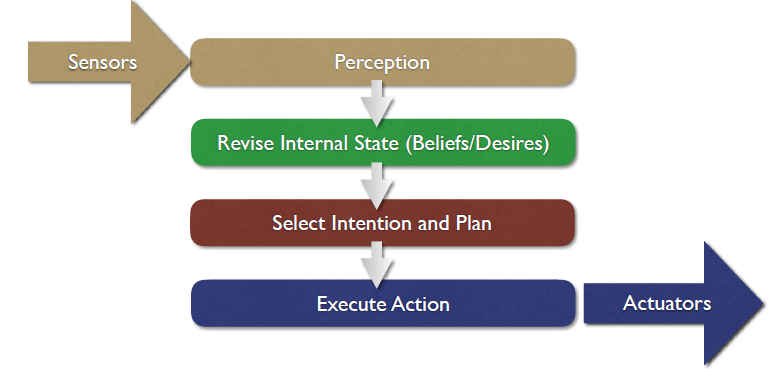
General Control Architecture
classic “Sense/Plan/Act” approach breaks it down serially like this
Behaviour based control
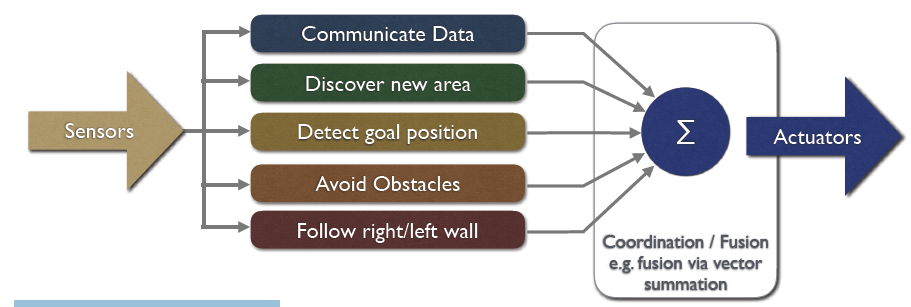
•行为块的控制,每个连接传感器到执行器
•隐式并行
•特别适合自主机器人
Brooks Behavioural Languages
1. Intelligent behaviour can be generated without explicit representations of the kind that symbolic AI proposes.
2. Intelligent behaviour can be generated without explicit abstract reasoning of the kind that symbolic AI proposes.
3. Intelligence is an emergent涌现 property of certain complex systems.
key ideas that have informed his research
1. Situatedness and embodiment 情境化 + 具身性: ‘Real’ intelligence is situated in the world, not in disembodied systems such as theorem provers or expert systems.真正的智能必须在真实世界中表现出来。
2. Intelligence and emergence智能不是内建的,而是“浮现”的: ‘Intelligent’ behaviour arises as a result of an agent’s interaction with its environment. Also, intelligence is ‘in the eye of the beholder’; it is not an innate, isolated property.
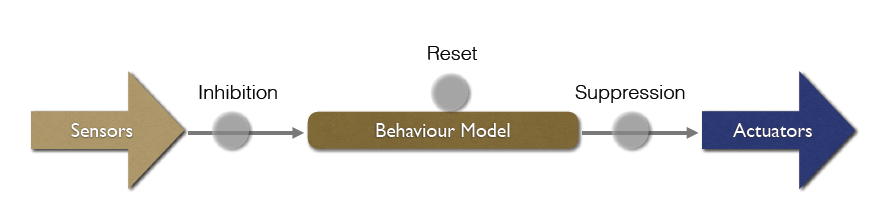
Subsumption Architecture 归约架构
A subsumption architecture is a hierarchy of task-accomplishing behaviours.
Each behavior is a basic rule that competes for control.
Lower layers (e.g., obstacle avoidance) take priority over higher ones.
Subsumption Machine
Layered approach based on levels of competence
Higher level behaviours inhibit lower levels
Emergent Behaviour 涌现行为
Putting simple behaviours together leads to synergies
当系统的观察行为远比你在代码中明确编写的行为更复杂和协调时,你就看到了涌现
e.g
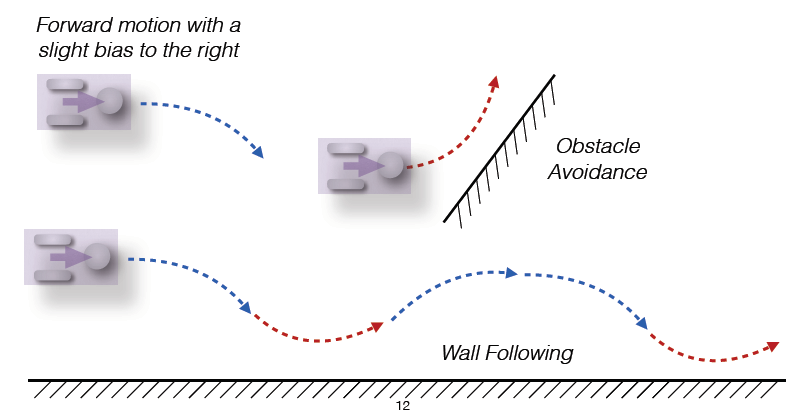
当“向前运动(带偏右)”+“避障反应”一起作用时,机器人会呈现出一种顺着墙体移动的复杂行为,虽然系统中没有明确编程“贴墙行走”这个功能,但它就“自然出现”了
Coded behaviour: 编程中显式写下的行为逻辑
Observed behaviour: 观察者眼中系统最终展现出来的行为(可能更复杂)
e.g Toto
一个由 Maja Mataric 设计的机器人,采用 subsumption architecture
-
subsumption architecture:Toto 使用的是子层架构,其中不同的行为层层叠加,简单的行为覆盖更复杂的行为。
-
Toto 可以 map spaces 和 execute plans,而不需要复杂的符号表示,这意味着它不需要像传统 AI 那样依赖复杂的思维模型或推理过程。
-
受到昆虫启发:Toto 的设计灵感来源于昆虫(如蜜蜂)的导航方式,昆虫通过识别地标并找到捷径来导航。Toto 采用类似的策略来与环境互动。
-
行为三元组:Toto 对每个环境特征(地标)进行感知并记录为 三元组:
-
Landmark type
-
Compass heading
-
Approximate length/size
-
-
Distributed topological map:Toto 不依赖全局地图,而是拥有一个分布式地图,每个行为都与不同的地标相关联,基于感知输入来判断当前位置。
Toto 的定位与行为激活
-
行为激活:当 Toto 访问特定地标时,与该地标关联的行为会被激活。如果没有行为被激活,Toto 认为该地标是新的,并创建一个新的行为。
-
行为抑制:如果某个现有的行为被激活,它会抑制所有其他行为。这是子层架构的一个关键特性:在需要时,更简单的行为会覆盖更复杂的行为。
-
定位机制:Toto 没有明确的地图,而是根据当前激活的行为来进行 定位。一组活跃的行为本身就构成了 Toto 的“地图”,这使得它的导航和位置确定更加简单和去中心化。
e.g Steel’s Mars Explorer System
work:
• Steels’ Mars explorer system
• Uses the subsumption architecture to achieve near-optimal cooperative performance in simulated ‘rock gathering on Mars’ domain
• Individual behaviour is governed by a set of simple rules.
• Coordination between agents can also be achieved by leaving “markers” in the environment.
Priority Rules:
The lowest-priority behavior is obstacle avoidance.
When collecting samples, agents return them to the mothership by navigating back if far away.
Tasks like sampling, avoiding obstacles, and moving are executed by priority.
The system works well with randomly distributed samples.
For clustered samples, agents need to cooperate to locate them.
Solution: Inspired by ant foraging—agents leave "radioactive trails" to mark sample locations.
Others follow these trails to find clusters, improving cooperation and efficiency.
Situated Automata
通过将感知和行动的部分分开,并通过一个声明式语言来描述代理的行为,使得代理能够根据环境的变化做出反应。在编译阶段就做了推理,避免了实时推理的复杂性。
定义与工作原理
-
代理的描述:代理通过一种规则性的声明式语言来指定。这个声明式语言会被编译成数字机器,从而实现代理的行为。
-
操作时间:该数字机器可以在一个可证明的时间边界provable time bound 内操作,即能够明确地确定其操作需要的时间。
-
离线推理:该方法在编译时(而非运行时)进行推理,意味着推理的过程是在代理执行时事先完成的off line ,而不是实时的online at run time。
2. 理论限制
-
编译Compilation(使用命题规格)被证明是NP完备问题,这意味着它的计算复杂度很高。
-
代理的规格语言越复杂,编译它的难度也会增大。
3. RULER 和 GAPPS:两个程序
-
RULER:用于指定代理的感知组件。它根据输入的感知数据来决定代理的感知状态,例如它可以设定“如果湿度传感器显示湿,则地面湿”,并根据这些输入设置状态转换。
-
GAPPS:用于指定代理的行动组件。它根据设置的目标减少规则和顶级目标来生成一个非符号化的程序。
Limitations
• If a model of the environment isn’t used, then sufficient information of the local environment is needed for determining actions
• As actions are based on local information, such agents inherently take a “short-term” view
• Emergent behaviour is very hard to engineer or validate; typically a trial and error approach is ultimately adopted
• Whilst agents with few layers are straightforward to build, models using many layers are inherently complex and difficult to understand.
Hybrid Architectures
仅依靠完全的符号推理(deliberative)或完全的反应式(reactive)方法来构建智能体都不是最佳的。单独使用这两种方式都存在一定的局限
混合系统的一个常见方式是构建一个由两种(或更多)子系统组成的智能体:
-
符号推理子系统(deliberative subsystem):这部分包含一个符号的世界模型,用于制定计划并作出决策。符号推理方法在进行决策时考虑到广泛的信息和复杂的逻辑推理。(• a deliberative one, containing a symbolic world model, which develops plans and makes decisions in the way proposed by symbolic AI; and
) -
反应式子系统(reactive subsystem):这部分能够应对实时事件,无需复杂的推理过程。(a reactive one, which is capable of reacting to events without complex reasoning.)
混合架构通常通过层次结构来组织这些子系统:
-
水平分层(Horizontal Layering):每个层级直接与感官输入和行为输出相连接。每个层级类似一个独立的智能体,根据当前感知的情况,提出行动建议。
-
垂直分层(Vertical Layering):每个感知输入和行动输出只由一个层级来处理。在垂直层级架构中,多个层级通过不同的抽象层级来控制信息流动。
在混合架构中,一个关键问题是如何嵌入智能体的各个子系统以及如何管理这些层次之间的互动,确保智能体能够高效运作。
Touring Machines
是一种用于机器人和智能体的体系结构。它由多个层次组成,每个层次都执行不同的任务。
体系结构组件:它包括感知和行动子系统,并通过三个控制层次与它们交互,分别为反应层(reactive layer)、规划层(planning layer)和建模层(modelling layer)。
-
感知子系统:负责从环境中获取传感器输入。
-
规划层:该层负责构建计划并选择执行的行动,以实现智能体的目标。
-
反应层:作为一个基于情境的动作规则集(类似于subsumption架构)进行工作,直接与环境互动。
-
建模层:包含环境中其他实体的“认知状态”的符号表示。它主要用于理解周围的世界并调整智能体的行为。
层次结构与规则:
-
反应层:通过一组简单的情境-行动规则来处理即时的反应任务。例如,当遇到障碍物时,反应层会指示机器人改变方向。
-
规划层:根据环境的变化,制定适应目标的行动计划。它为反应层提供高层次的目标指引。
-
建模层:该层记录与其他实体(例如障碍物)的感知数据,并生成相应的控制信号。
模块化设计:这三个层次协作以实现灵活的行为,能够应对动态的环境变化和任务需求。每个层次独立处理特定的任务,并能通过控制框架进行有效的协调。
在这套架构中,反应层可能会处理实时数据,例如当感知到障碍物时,反应层会即时做出决策;而规划层会为机器人生成长远的目标,并根据建模层提供的世界状态作出调整。通过建模层,智能体可以拥有关于其他实体(如障碍物、目标位置等)的知识,并利用这些信息进行决策。
Lec 8 Coalitions, Voting Power, and Computational Social Choice
Coalitional Games 联盟博弈
联盟博弈 是博弈论中的一种模型,用来描述多个智能体(agents)通过合作获得更大利益的情境。
Issues in coalitional games (Sandholm et al, 1999):
Coalition Structure Generation
Teamwork
Dividing the benefits of cooperation
Coalition Structure Generation 联盟结构生成
目标:决定谁和谁组成联盟。
The basic question:
Which coalition should I join?
The result: partitions agents into disjoint coalitions **互不重叠的多个小团体(即联盟)**
The overall partition is a coalition structure 联盟结构
optimization problem of each coalition
Deciding how to work together.
Solving the “joint problem” of a coalition
Finding how to maximize the utility of the coalition(联盟的整体效用) itself.
Typically involves joint planning 联合计划 etc.
Dividing the Benefits 利益分配
Deciding “who gets what” in the payoff.
Coalition members cannot ignore each other’s preferences, because members can defect 退出
We might want to consider issues such as fairness of the distribution
Formalizing Cooperative Scenarios 形式化合作场景
A coalitional game: <Ag, v>
Ag = {1,…,n} is a set of agents
-
意思是:在这个博弈中,有
n个参与者(智能体、玩家、机器人、组织等)。 -
每个数字代表一个具体的智能体。例如:
-
Ag = {1, 2, 3} 就表示有 3 个智能体。
-
v = 2Ag -> R is the characteristic function 特征函数 of the game
-
2^Ag表示智能体集合的幂集,也就是说,所有可能的子集(即所有可能的联盟)。
Usual interpretation: if ν(C) = k, then coalition C can cooperate in such a way they will obtain utility k, which may then be distributed among the team members
-
v(C)表示某个联盟C(一个子集,比如 {1,3})的总效用值。 -
v(C)=k的含义是:如果这个联盟C选择合作,那么他们可以共同获得k单位的效用或收益。
Core
The core is the set of outcomes for the grand coalition to which no coalition objects
If the core is non-empty then the grand coalition is stable, since nobody can benefit from defection
合作博弈中的**核心(Core)**是所有可能的收益分配方案的集合,这些方案保证了没有任何子联盟(子合作组)会反对当前的分配。换句话说,核心中的分配方案是稳定的,任何子联盟都无法通过单独行动获得比核心方案更好的收益。
Feasibility condition:
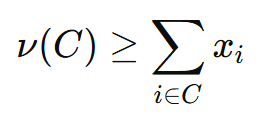
members of any group get at least as much as they could achieve themselves.
Stability:
If the core is non-empty, then the grand coalition is stable — no group of players has an incentive to break away.
Problems with the core:
Sometimes the core is empty — no stable allocation exists.
Sometimes the core is unfair — e.g., identical agents might receive very different payoffs, as long as no one can profit by leaving.a
Shapley Value
代理人 i 的Shapley值是该代理人预期对联盟贡献的平均值。
来定义如何公平地分配合作产生的收益。
它通过考虑“每个代理人的贡献有多大(how much an agent contributes)”来实现公平分配。
公理性质
Shapley值满足以下公理:
-
对称性(symmetry):对称代理人的分配相同。
-
虚拟玩家(dummy player):如果某个代理人对所有联盟都不贡献价值,则其Shapley值为零。
-
可加性(additivity):对于两个合作游戏,其Shapley值的加和等于两个游戏的合并。
Marginal Contribution(边际贡献)
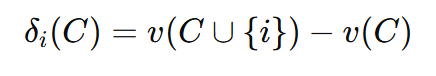

Shapley Value(夏普利值)
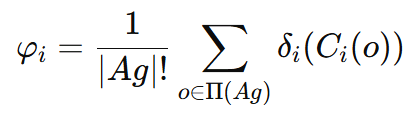

计算e.g
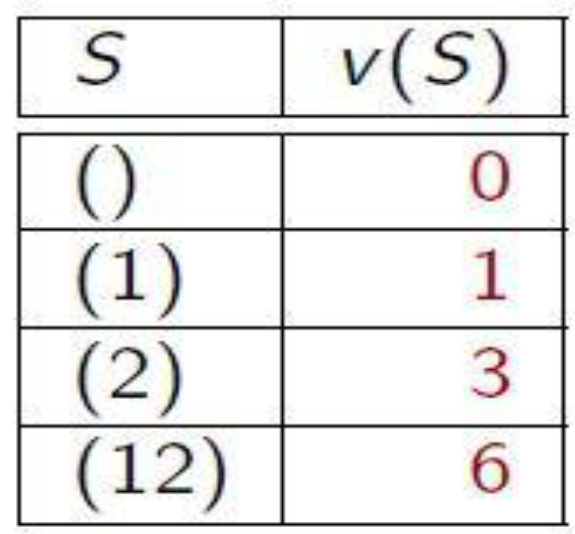
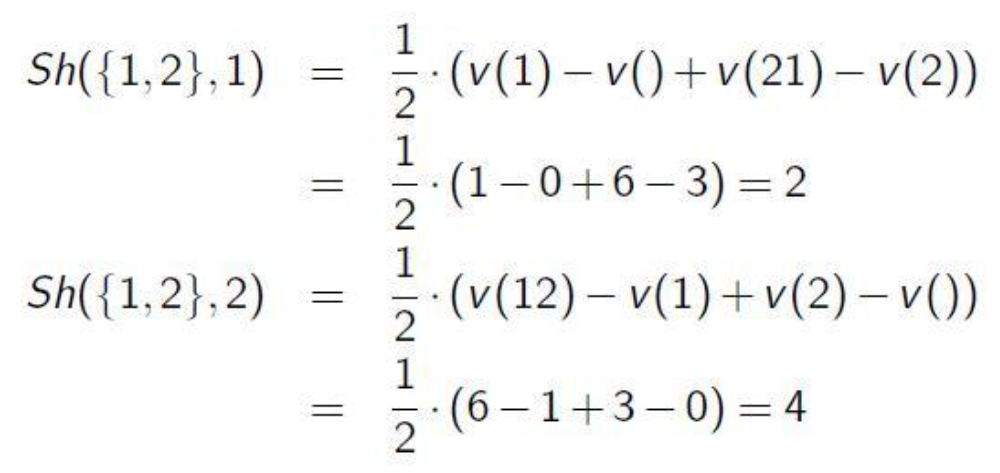
Representing Coalitional Games
It is important for an agent to know (for example) whether the core of a coalition is nonempty
characteristic function
在合作博弈中,Characteristic Function(特征函数)是一个函数,用来表示任意一个“玩家子集”(联盟)能够合作创造的总价值。
![]()
其中:
-
N 是所有玩家的集合(例如 N={1,2,3})
-
2^N 是 N 的所有子集(即所有可能的联盟)
-
v(S) 就是联盟 S的“价值”
定义了整个博弈的“合作潜力”, 是计算 Shapley Value(公平分配) 的前提
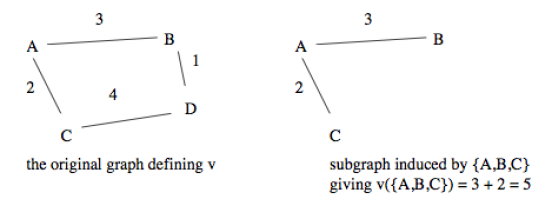
Induced Subgraph
Represent ν as an undirected graph on Ag, with integer weights wi,j between nodes i, j ∈ Ag
Value of coalition C then:
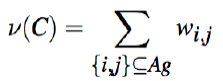
i.e., the value of a coalition C ⊆ Ag is the weight of the subgraph induced by C
Marginal Contribution Nets
Pattern is conjunction of agents, a rule applies to a group of agents C if C is a superset of the agents in the pattern
某些 agent 同时在场(逻辑与 ∧),就能带来某个价值。
e.g
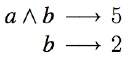
We have: ν({a}) = 0, ν({b}) = 2, and ν({a, b}) = 7
We can also allow negations in rules (agent not present)
e.g

sol
![]()
Lec 9 Reaching Agreements
Auction
Auction: method for allocating scarce resources in a society given preferences of agents
The English Auction (EA)
第一价格公开喊价(递增式)
• Each bidder raises freely his bid (in public), auction ends if no bidder is willing to raise his bid anymore(公开喊价,竞标者自由加价,直到没人愿意再加价时结束)
• Bidding process public in correlated auctions, it can be worthwhile to counterspeculate
• In correlated value auctions, often auctioneer increases price at constant/appropriate rate, also use of reservation prices(保留价)
• Dominant strategy in private-value EA: bid a small amount above highest current bid until one’s own valuation is reached
Advantages:
- Truthful bidding is individually rational & stable
- Auctioneer cannot lie (whole process is public)
Disadvantages:
- Can take long to terminate in correlated/common value auctions
- Information is given away by bidding in public
- Use of shills (in correlated-value EA) and “minimum price bids” possible, to drive prices(“假买家”操纵价格,设置“最低价)
- Bidder collusion self-enforcing (once agreement has been reached, it is safe to participate in a coalition) and identification of partners easily possible(投标人串通)
cheating
• The goal of the cheating in English auction is to induce the bidders to reach their maximum valuations
• In case of multiple bidding a cheating agent submits many bids adopting multiple (fake) identities
• Some of these bids are higher than his/her personal valuation of the product
Dutch/First-Price Sealed Bid Auctions
• Dutch (descending) auction: seller continuously lowers prices until one of the bidders accepts the price (递减式)卖方价格不断下降,直到有人接受
• First-price sealed bid: bidders submit bids so that only auctioneer can see them, highest bid wins (only one round of bidding)投标者秘密提交出价,最高价获胜(只进行一次投标)
• DA/FPSB strategically equivalent (no information given away during auction, highest bid wins)
Advantages:
- Efficient in terms of real time (especially Dutch)
- No information is given away during auction
- Bidder collusion not self-enforcing, and bidders have to identify each other(不易形成自我维系,且需识别合作者)
Disadvantages:
• No dominant strategy, individually optimal strategy depends on assumptions about others’ valuations
• One would normally bid less than own valuation but just enough to win Incentive to counter-speculate
• Without incentive to bid truthfully, computational resources might be wasted on speculation(投标人有反推策略的激励,可能浪费计算资源)
cheating
-Dutch Auction : Bidder collusion:
• The bidders can coordinate their bid prices so that the bids stay artificial low
• The bidders get the item at a lower price than they normally would
first-price auction: examining the competing bids(偷偷先看其他投标人的出价) before submitting his own bid. (这样他就能以稍微高于最高竞争对手的价钱出价,既能保证赢标,又不会出价过高,赚取最大利益。)
The Vickrey Auction (VA)
第二价格密封投标,是结合efficiency of Dutch/FPSB和 incentive compatibility of English auction的方式
• Second-price sealed bid: Highest bidder wins, but pays price of second-highest bid(最高出价者获胜,但支付第二高价)
Advantages:
- Truthful bidding is dominant strategy
- No incentive for counter-speculation
- Computational efficiency
Disadvantages:
- Bidder collusion self-enforcing
- Lying auctioneer
实际应用中不太流行,但计算机拍卖系统中很成功
cheating
The seller examines the bids of a second-price auction before the auction clears and then submits a shill bid(“假投标”,叫做“水军”或“虚假投标) in order to increase the payment of the winning bidder
这样卖家可以提高卖出价格,获得更多收入。
conclusion form
| Auction Type | Key Features | Advantages | Disadvantages | Cheating Methods | Dominant Strategy |
|---|---|---|---|---|---|
| English Auction (Ascending Open Auction) | - Bidders publicly raise bids- Auction ends when no one raises- Uses reserve prices- Suitable for private-value settings | - Truthful bidding is individually rational & stable- Auctioneer cannot lie due to public process | - Can be long in correlated/common value auctions- Public bidding reveals information- Shills and minimum price bids possible- Bidder collusion is easy and self-enforcing | - Using multiple fake identities to submit bids- Fake bids higher than bidder’s own valuation | In private-value settings, bid just above current highest bid until own valuation is reached (truthful bidding) |
| Dutch Auction / First-Price Sealed Bid (FPSB) | - Dutch: price decreases until a bidder accepts- FPSB: bidders submit one secret bid, highest wins- Both are strategically equivalent | - Efficient in real-time, especially Dutch auction- No info revealed during bidding- Bidder collusion is not self-enforcing | - No dominant strategy- Bidders typically shade bids below own valuation- Incentive to speculate may waste resources | - Bidder collusion to keep bids artificially low- Inspect others’ bids secretly and bid slightly higher | No dominant strategy; optimal bid depends on beliefs about others’ valuations, typically bid below true value to balance winning and payoff |
| Vickrey Auction (Second-Price Sealed Bid) | - Highest bidder wins but pays second-highest bid- Combines efficiency of FPSB with incentive compatibility of English auction | - Truthful bidding is dominant strategy- No incentive for counter-speculation- Computationally efficient | - Bidder collusion can be self-enforcing- Auctioneer can cheat via shill bids- Less popular in practice but used in computational auctions | - Seller submits fake bids after seeing others’ bids to increase winning price | Truthful bidding (bid own true valuation) is the dominant strategy |
Lec 10 Social Choice
Social Choice Theory
concerned with group decision making (basically analysis of mechanisms for voting)
Basic setting:
• Agents have preferences over outcomes
• Agents vote to bring about their most preferred outcome
Preference Aggregation
settings:

Preference Aggregation: How do we combine a collection of potentially different preference orders in order to derive a group decision?
• Voting Procedures:
- Social Welfare Function(社会福利函数)输入是每个投票者的偏好排序,输出是一个整体的社会偏好排序。:
f : Π(Ω) × . . . × Π(Ω) → Π(Ω)
- Social Choice Function(社会选择函数): f : Π(Ω) × . . . × Π(Ω) → Ω 输入同样是所有投票者的偏好排序,输出是最终选出的一个获胜者(候选项)。
Task is either to derive a globally acceptable preference ordering, or determine a winner
Plurality- Single-winner voting system
简单多数制 — 单一赢家投票系
• Each voter votes for one alternative; the candidate with the most first place votes wins.
e.g
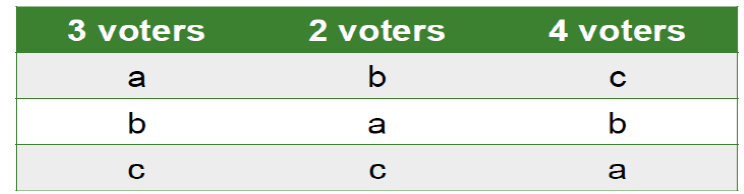
col:选民数,row:preference place
3个选民的第一选择是a,第二是b,第三是c,2个选民的第一选择是b,第二是a,第三是c,4个选民的第一选择是c,第二是b,第三是a
简单多数制中,c获得最多票数(4票),因此c获胜。但是注意,即使5票选民中有4票把c放最后(因为3票a第一,2票b第一),c仍然赢了。这意味着简单多数制可能让“被大多数人放在最后的候选人”赢得选举。
• Advantages: simple to implement and easy to understand
• Problems: Tactical voting(voters are pressured to vote)and tie vote
Condorcet’s Paradox
There are scenarios in which no matter which outcome we choose the majority of voters will be unhappy with the outcome chosen
(好想要...没人受伤的世界...)
Borda Count
• Each voter submits preferences over the m alternatives
每个候选项根据它在每个选民排名中的位置获得对应分数。通常排名第一的候选人得 m−1 分,第二名得 m−2 分,依此类推,最后一名得0分。
Points for each alternative are summed across all voters, and the alternative with the highest total is the winner
e.g
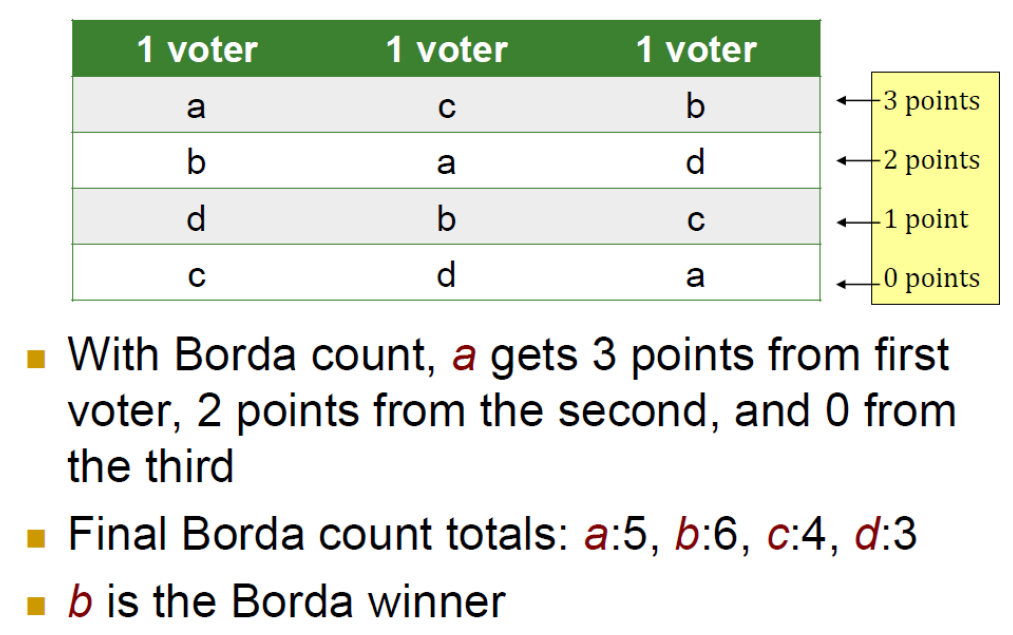
col:选民数,row:preference place
Sequential Majority Elections
pairwise
两两比较,选出偏好最高的
多步选举,是pair wise的一种
• voting can be done in several steps
• Candidates face each other in pairwise elections, the winner progresses to the next election
• Election agenda(选举议程) is the ordering of these elections (e.g.ω2, ω3, ω4, ω1)
calculation:所有候选人两两比较, 找有多少人把 A 排在 B 前面
• Can be organised as a binary voting tree
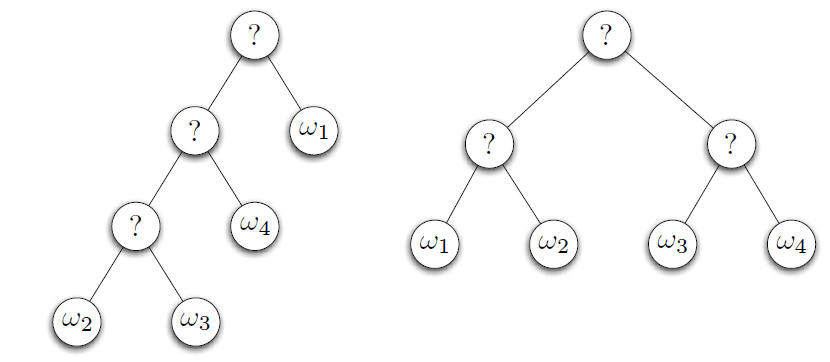
Key Problem: The final outcome depends on the election agenda
Majority Graphs
• A majority graph is a succinct representation of voter preferences, Nodes correspond to outcomes, e.g. ω1, ω2, . . .
There is an edge from ω to ω' if a majority of voters rank ω above ω'
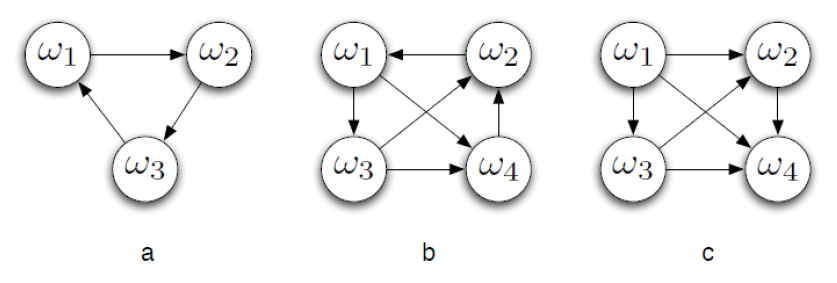
Condorcet Winner
A Condorcet winner is a candidate that would beat every other candidate in a pairwise election. Not every election has one.
e.g

Desirable Properties
• Pareto Condition
如果所有选民都偏好候选项 ωi超过 ωj,那么最终的社会偏好也应该是 ωi 优于 ωj
- If every voter ranks ωi above ωj then ![]()
- Satisfied by plurality and Borda, but not by sequential majority
• Condorcet winner condition
如果存在一个候选项,在两两对决中能击败所有其他候选项,那么最终的社会选择应当是这个候选项。
- The outcome would beat every other outcome in a pairwise election
- Satisfied only by sequential majority elections
• Independence of irrelevant alternatives (llA)
说明:社会对两个候选项 ωi 和 ωj的排序,只应该取决于选民对这两个候选项之间的偏好关系,而不受其他无关候选项的影响。
The social ranking of two outcomes ωi and ωj should exclusively depend on their relevant ordering in the preference orders
Plurality, Borda and sequential majority elections do not satisfy lIA
• Non-Dictatorship(非独裁性)
- None of the voters can systematically impose his preferences on the other ones
Arrow’s Theorem 阿罗不可能定理
社会选择理论的总体目标:
寻找一种“理想的”社会选择程序(投票规则),既公平又合理,满足一系列好的性质,然而这hi是不可能的,因为↓
• Arrow’s Theorem: For elections with more than two outcomes, the only voting procedures that satisfy the Pareto condition and IIA are dictatorships
任何试图同时满足这些公平和合理性质的投票机制,都不可避免地陷入独裁。换句话说,不存在完美的投票规则能兼顾所有好的性质
Lec 11 Working Together
Basic Consecepts
benevolent vs self-interested agents
benevolent 仁慈的 agents
If we “own” the whole system, we can design agents to help each other whenever asked
In this case, we can assume agents are benevolent: our best interest is their best interest
Problem-solving in benevolent systems is cooperative distributed problem solving
(CDPS)(协作分布式问题求解)
Benevolence simplifies the system design task enormously!
self-interested agents
If agents represent individuals or organizations, (the more general case), then we cannot make the benevolence assumption
Agents will be assumed to act to further their own interests, possibly at expense of others
Potential for conflict
May enormously complicate the design task
Task Sharing & Result Sharing
task sharing: components of a task are distributed to component agents
result sharing: information (partial results, etc.) is distributed
contract net 合同网协议
A well known task-sharing protocol for task allocation
1. Recognition
an agent recognizes it has a problem it wants help with.
Agent has a goal, and either:
1)cannot achieve the goal in isolation —does not have capability
2) prefer not to achieve the goal in isolation (typically because of solution quality, deadline, etc.)
2. Announcement
he agent with the task sends out an announcement of the task which includes a specification of the task to be achieved. (目的:让其他代理了解任务并决定是否参与。)
Specification must encode:
1) description of task itself (maybe executable)
2) any constraints (e.g., deadlines, quality constraints)
3) meta-task information (e.g., bids must be submitted by…”)
The announcement is then broadcast
3. Bidding 出价
Agents that receive the announcement decide for themselves whether they wish to bid for the task
consider:
whether it is capable of expediting task
quality constraints & price information (if relevant)
If they do choose to bid, then they submit a tender投标书
4. Awarding & 5 Expediting
Agent that sent task announcement must choose between bids & decide who to "award the contract" to
The result of this process is communicated to agents that submitted a bid
The successful contractor then expedites 加快 the task
May involve generating further manager-contractor relationships: sub-contracting(分包)
issues
…specify tasks?
…specify quality of service?
…select between competing offers?
…differentiate between offers ?
Cooperative Distributed Problem Solving (CDPS)
Neither global (control/ data storage) — no agent has sufficient information to solve entire problem
Control and data are distributed
CDPS System Characteristics and Consequences
Communication is slower than computation
松耦合(Loose coupling):减少代理间频繁通信,保持独立性。
高效协议(Efficient protocol):优化通信过程,避免浪费时间。
模块化问题(Modular problems):把大问题拆成小模块,方便分配。
粗粒度问题(Large grain size):每个子任务相对较大,减少通信开销。
Any unique node is a potential bottleneck
distribute data /control
organized behavior is hard to guarantee (since no one node has complete picture)
sol:Contract Net
The collection of nodes is the “contract net”
Each node on the network can, at different times or for different tasks, be a manager or a contractor
When a node gets a composite task , it 1) breaks it into subtasks (if possible) and announces them (acting as a manager), 2) receives bids from potential contractors, 3) then awards the job (e.g: network resource management, printers, …)
steps:
1. Problem Decomposition 问题分解
2. Sub-problem distribution 子任务分配
3. Sub-problem solution 子任务求解
4. Answer synthesis 答案合成
Types of Messages
Task announcement
Bid
Award
Interim report (on progress)
Final report (including result description)
Termination message (if manager wants to terminate contract)
Efficiency Modifications
用于减少通信开销
Focused addressing (针对性定向通信)— when general broadcast isn’t required
Directed contracts(定向合同) — when manager already knows which node is appropriate
Request-response mechanism(请求-响应机制) — for simple transfer of information without overhead of contracting
Node-available message(节点可用消息) — 节点主动告知管理者自己有能力执行任务reverses initiative of negotiation process
Lec12 Agent Communication 不用考!!!!!!!!
macro-aspects of intelligent agent technology
Speech Acts
n Most communication in (multi-) agent systems are from speech act theory 言语行为理论
n Speech act theories are pragmatic theories of language 语用学理论, i.e., theories of language use: 关注语言如何被人们用来实现目的和意图。
Austin noticed that some utterances are rather like ‘physical actions’ that appear to change the state of the world
n Paradigm examples would be:
q declaring war
q christening
q ‘I now pronounce you man and wife’ :-)
A theory of how utterances are used to achieve intentions is a speech act theory
Different Aspects of Speech Acts
From “A Dictionary of Philosophical Terms and Names”:
“Locutionary act(发话行为): the simple speech act of generating sounds that are linked together by grammatical conventions so as to say something meaningful. e.g ‘It is raining’
“Illocutionary act(施为行为): the speech act of doing something else – offering advice or taking a vow, for example – in the process of uttering meaningful language. e.g ‘I will repay you this money next week,’
“Perlocutionary act(效果行为): the speech act of having an effect on those who hear a meaningful utterance. e.g By telling a ghost story late at night, for example, one may frightening a child.”
different types of speech act
Searle (1969) identified various:
Representatives(陈述性):such as informing, e.g., ‘It is raining’
Directives(指令性):attempts to get the hearer to do something e.g., ‘please make the tea’
Commisives(承诺性):which commit the speaker to doing something, e.g., ‘I promise to… ’
Expressives(表达性):whereby a speaker expresses a mental state, e.g., ‘thank you!’
Declarations(宣告性):such as declaring war or christening
In general, a speech act can be seen to have two components:
Performative verb(行为动词):(e.g., request, inform, promise, … )
Propositional content(命题内容): (e.g., “the door is closed”)
e.g
| 行为动词 (Performative) | 命题内容 (Content) | 言语行为 (Speech Act) |
|---|---|---|
| request | “the door is closed” | “Please close the door”(请关门) |
| inform | “the door is closed” | “The door is closed!”(门关着) |
| inquire | “the door is closed” | “Is the door closed?”(门关了吗?) |
Plan Based Semantics
基于计划的语义是一种利用规划研究中的概念来定义言语行为(如请求、命令或陈述)含义的方法。其主要目标是理解何时可以说一个人完成了特定的言语行为(例如,发出请求或提供信息)
n Cohen & Perrault (1979) defined semantics of speech acts using the precondition-delete-add list formalism(前提-删除-添加列表形式主义) of planning research
n Note that a speaker cannot (generally) force a hearer to accept some desired mental state
n In other words, there is a separation between the illocutionary act 言内行为 and the perlocutionary act 言后行为
言内行为(Illocutionary Act):指的是话语背后的意图(如发出请求)。
示例: 请求别人关闭窗户。
言后行为(Perlocutionary Act):指的是话语对听者产生的实际效果(如对方真的去关窗户)。
示例: 听者受到请求后,真的去关了窗户。
即使说话者完成了言内行为(如提出请求),这并不保证言后效果(听者真的去做)。换句话说,说话者不能强制听者接受某种期望的心理状态。
semantics for request
request(s,h,ϕ)
Where:
-
s: The sender (agent making the request)
-
h: The hearer (agent receiving the request)
-
ϕ: The action or proposition being requested
Preconditions (pre):
· s believe h can do ϕ
The sender believes that the hearer is capable of performing the action.
· s believe h believe h can do ϕ
The sender believes that the hearer themselves believes they can do it.
· s believe s want ϕ
The sender actually wants the action to be performed.
Postconditions (post):
· h believe s believe s want f
The hearer becomes aware that the sender wants the action to be performed.
Agent Communication Languages
在多智能体系统(MAS)中,不同的智能体之间需要交换信息和协同工作,这就需要一种标准化的通信语言。目前最广泛使用的**智能体通信语言(Agent Communication Languages,ACLs)**是 KQML(knowledge query and manipulation language) 和 KIF(the knowledge interchange format)。
-
KQML 提供了智能体间交流的格式和行为类型。
-
KIF 使智能体能够表达复杂的逻辑和事实。
-
Ontology 本体确保不同智能体间语义一致性,通过共享词汇和定义来实现。
KQML
KQML is an ‘outer’ language 外部语言, that defines various acceptable ‘communicative verbs’(“交流动词”(即行为或传达意图的动作)), or performatives(执行动作)
e.g:
1. ask-if (‘is it true that. . . ’)
2. perform (‘please perform the following action. . . ’)
3. tell (‘it is true that. . . ’)
4. reply (‘the answer is . . . ’)
KIF
KIF 是一种内部语言,用于描述智能体间消息内容的逻辑表达。主要用于描述领域内事物的性质、事物之间的关系、领域的一般性质。
1. Properties of things in a domain (e.g., “Noam is chairman”)
e.g “The temperature of m1 is 83 Celsius”:
(= (temperature m1) (scalar 83 Celsius))
2. Relationships between things in a domain (e.g., “Amnon is Yael’s boss”)
e.g “An object is a bachelor if the object is a man and is not married”:
(defrelation bachelor (?x) := (and (man ?x) (not (married ?x))))
3. General properties of a domain (e.g., “All students are registered for at least one course”)
e.g “Any individual with the property of being a person also has the property of being a mammal”:
(defrelation person (?x) :=> (mammal ?x))
Ontology 本体
为了在不同智能体之间有效通信,智能体需要共享相同的术语集。(In order to be able to communicate, agents must have agreed on a common set of terms)
-
本体(Ontology): 一组正式规范的术语,用于在特定领域中保持一致性。
-
Ontolingua: 用于定义和共享本体的软件工具。
Example KQML/KIF dialogue…
A to B: (ask-if (> (size chip1) (size chip2))) 芯片1的大小是否大于芯片2?
B to A: (reply true) 是的,芯片1确实大于芯片2。
B to A: (inform (= (size chip1) 20)) 芯片1的大小是20
B to A: (inform (= (size chip2) 18)) 芯片2的大小是18
FIPA
FIPA(Foundation for Intelligent Physical Agents)是一个致力于制定智能体标准的组织, 核心是智能体通信语言(ACL,Agent Communication Language),这些标准用于多智能体系统(MAS)中,确保不同智能体之间能够有效交流和协作。
Basic structure is quite similar to KQML:
performative(行为/动作词)
20 performative in FIPA
e.g inform(告知),request(请求)。
Housekeeping(通信元数据)
e.g sender(发送者),receiver(接收者),timestamp(时间戳)
Content(消息内容)
the actual content of the message
E.g


Inform” and “Request
“Inform” and “Request” are the two basic performatives in FIPA. All others are macro definitions, defined in terms of these.
The meaning of inform and request is defined in two parts:
pre-condition
what must be true in order for the speech act to succeed
“rational effect”
what the sender of the message hopes to bring about
n For the “inform” performative…
The content is a statement.
Pre-condition is that:
sender:
q holds that the content is true
q intends that the recipient believe the content
q does not already believe that the recipient is aware of whether content is true or not
n For the “request” performative…
The content is an action.
Pre-condition is that:
sender:
q intends action content to be performed
q believes recipient is capable of performing this action
q does not believe that receiver already intends to perform action