一文理清楚大模型里的RAG架构
一、引言
在人工智能领域,大模型如GPT、T5等取得了显著成就,但在处理知识密集型任务时,仍存在知识过时、幻觉等问题。为解决这些问题,Facebook AI Research(FAIR)团队于2020年提出了RAG(Retrieval-Augmented Generation,检索增强生成)技术,它结合信息检索与生成模型的优势,通过从外部知识库检索信息并提供给生成模型,增强了模型处理知识密集型任务的能力,本文将对RAG技术进行深入探讨,希望对你有所帮助。
二、RAG的基本概念
RAG是一种将信息检索和文本生成相结合的技术框架。其核心思想是在生成答案前,先从外部知识库检索相关证据,再基于检索结果和用户输入生成更准确、可靠的回答。简单来说,RAG就是给AI装上“知识导航”,通过检索外部数据,增强大模型的生成效果。
三、RAG的背景与意义
- 背景 :通用大模型存在知识“过期”、“异想天开”、专业知识局限等问题,亟需优化。而传统通过提示词工程、微调等方法无法有效解决知识实时更新和准确性问题。
- 意义 :RAG可以解决大模型知识更新难、企业/个人数据隐私风险、幻觉问题以及长文本处理成本高等局限性,能够根据不同领域需求定制专业答案,提升模型在问答、文本摘要、内容生成等知识密集型任务中的性能和准确性。
四、RAG的技术架构
RAG系统主要由检索模块(Retriever)、增强模块(Augmentation Component)和生成模块(Generator)三个核心组件构成。
-
检索模块(Retriever) :负责从外部数据库中提取相关信息,通过计算输入查询与数据库中文档的语义相似度,选择最相关的文档片段。常用方法包括 BM25 和嵌入方法,其中嵌入方法又分为浅层和深层嵌入。
-
增强模块(Augmentation Component) :负责将用户查询与检索到的上下文信息整合为一个提示模板,使检索到的信息能够以合适的逻辑和格式呈现给生成模型,指导其生成回答。
-
生成模块(Generator) :使用预训练的大语言模型(如 GPT、T5)来生成最终的回答,将用户查询与检索到的文档结合,作为生成模型的输入,从而生成上下文相关且准确的回答。
五、RAG的工作流程
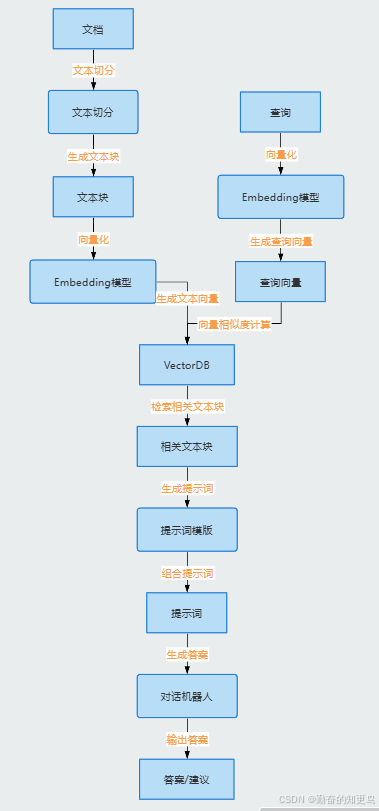
RAG的工作流程可以分为离线数据处理和在线检索两个阶段。
-
离线数据处理 :
- 知识库的选择与构建 :选择合适的知识库是关键一步,如维基百科、专业文档、企业知识库等。需要将知识库中的数据进行收集、清洗、转换和存储,并构建检索友好的索引结构。
- 文档预处理与索引构建 :对知识库中的文档进行解析、清洗、分块等预处理操作,然后使用嵌入模型将文本转换为向量表示,并构建向量索引,以提高检索效率。
-
在线检索 :
- 用户问题理解与处理 :对用户输入的问题进行分析和处理,明确用户需求,并将其转换为适合检索的表示形式。
- 检索与召回 :根据用户问题的表示,在向量数据库中检索出与问题最相似的文档或段落。
- 结果重排序 :对检索到的文档进行重排序,筛选出与问题最相关的信息,以提高生成答案的质量。
- 上下文构建与生成 :将重排序后的文档片段与原始问题结合,构建出包含丰富上下文信息的输入提示,用于引导预训练生成模型生成准确且相关的回答。
- 后置处理 :对生成的回答进行进一步的优化和调整,如格式校正、内容完善、质量评估等,以确保最终呈现给用户的答案具有良好的可读性和完整性。
六、RAG的关键技术
- 向量化技术 :向量化技术是将文本数据转换为向量表示,以便在向量空间中进行相似度计算和检索。预训练模型是实现向量化的关键,主流的预训练模型有:
- BERT:基于Transformer的预模型训练,能够生成语义丰富的文本向量。
- RoBERTa:优化版的BERT,通过更长的训练时间和更大规模的训练数据提升性能。
- Sentence-BERT(SBERT):在BERT基础上优化,直接生成用于句子嵌入的向量。
- OpenAI Embeddings:由OpenAI提供的文本嵌入模型,如ada、babbage等。
这些模型通过训练学习到文本的语义特征,生成的向量在语义相似度计算和文本检索中表现出色。
- 双塔模型架构 :双塔模型是RAG检索模块的核心架构之一,主要由查询编码器(Query Encoder)和文档编码器(Document Encoder)组成:**
- 查询编码器:用于将用户输入的查询文本转换为向量表示。
- 文档编码器:用于将外部知识库中的文档转换为向量表示。
双塔模型通过将查询和文档分别映射到同一向量空间,然后计算它们的相似度,从而实现高效检索。双塔模型的优势在于: - 高效性:可以独立编码查询和文档,便于并行处理和大规模数据检索。
- 可扩展性:适用于大规模知识库,能够快速检索到与查询相关的文档。
- 高效检索算法 :检索算法是检索模块的核心,用于从大规模知识库中快速找到与查询相关的文档。常见的检索算法包括:
- BM25算法:基于词频统计的检索算法,适用于文本检索任务,对短文本和长文本的检索效果较好。
- 向量检索算法:利用向量相似度计算方法,如余弦相似度、欧氏距离等。向量数据库(如FAISS、Milvus)提供了高效的向量检索功能,能够快速处理大规模数据集并返回与查询向量最相似的文档。
- 提示构建策略 :提示构建策略用于将检索到的文档与原始问题整合为一个提示模板,以引导生成模型生成准确的回答。常见的提示构建方法包括:
- 原始问题拼接:直接将检索到的文档片段与原始问题拼接在一起。
- 关键信息抽取:从检索到的文档中抽取关键信息,将其与原始问题结合。
- 提示模板设计:根据任务需求设计特定的提示模板,如问答模板、摘要模板等。
提示构建策略能够有效地将检索到的信息传递给生成模型,提高生成回答的相关性和准确性。
七、RAG的优化方法
-
检索增强 :
- HyDE :先用 LLM 生成假设答案,再基于假设答案进行检索,能够快速定位与问题高度相关的文档。
- Rerank :使用交叉编码器对初筛结果进行重排序,更精准地筛选出与查询最相关的文档,从而进一步提升 RAG 的性能。
-
生成优化 :对生成模型进行微调或采用强化学习等方法,使其更好地理解检索到的文档信息,提高生成答案的质量和准确性。
-
块大小调整 :根据嵌入模型和任务需求,合理调整文档分块大小,以在语义完整性和检索效率之间取得平衡。
-
模型融合 :结合多种预训练模型或检索算法的优势,提高 RAG 的整体性能和稳定性。
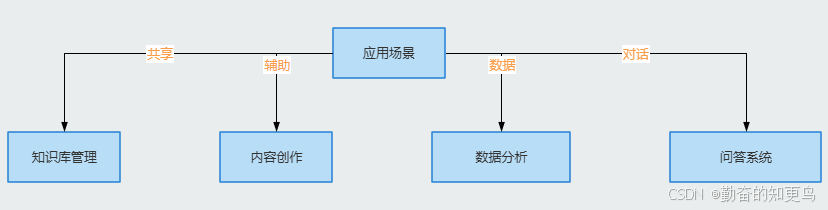
八、RAG的应用案例
- 问答系统 :如智能客服通过 RAG 技术实时检索企业知识库,为用户提供有用的问题解答,提高服务质量和效率。
- 内容创作 :为创作者提供相关主题的高质量文档和信息,辅助创作,提升内容的准确性和深度。
- 数据分析 :从海量数据中快速提取有价值的信息,为数据分析和决策提供有力支持。
- 知识库管理 :帮助企业更好地管理和利用内部知识资源,提高知识的共享和利用效率。
九、RAG的优势与挑战
- 优势 :通过检索增强生成,弥补生成模型知识的不足,提高生成答案的准确性和可信度;能够实时接入外部知识,及时获取最新的信息;支持个性化定制,满足不同领域和任务的需求;在一定程度上缓解了大模型的幻觉问题。
- 挑战 :检索模块的准确性对整体性能至关重要,但检索错误可能导致生成错误答案;检索到的文档与生成模型的融合不够紧密,影响回答的连贯性和一致性;对计算资源和存储资源要求较高;在某些情况下,可能无法满足用户对实时性的期望;存在检索到无关或低质量信息的风险。
十、结论
RAG 技术作为大模型应用中的重要技术,通过结合信息检索与生成模型的优势,为解决大模型在知识密集型任务中的局限性提供了一种有效的方法。它不仅可以提高大模型的性能和准确性,还能为各行业的智能化应用提供支持。未来,随着技术的不断发展和创新,RAG 技术将更加成熟和完善,为人工智能领域的发展做出更大贡献。