简说IMM
1. 基本概念和表述
齐次马尔科夫链
其次马尔可夫链的转移过程可表述为:
P i j { m j ( k + 1 ) ∣ m i ( k ) } = p i j ∀ i , j ∈ M f P_{ij}\{m_j(k+1)|m_i(k)\}=p_{ij} \qquad \forall i,j \in M_f Pij{mj(k+1)∣mi(k)}=pij∀i,j∈Mf
易理解, p i j p_{ij} pij表达了由 k k k时刻的模型 i i i转移到 k + 1 k+1 k+1时刻的模型 j j j的概率
文中符号说明
- M f M_f Mf 表示模型空间,IMM表达多个模型都属于这个模型空间
- 下标 i , j i,j i,j:
- 当有一个下标时,一般表示某个模型的变量,如 μ i \mu_i μi表示模型i的概率
- 当有两个下标时,用来表示两个模型间的转移,如KaTeX parse error: Undefined control sequence: \p at position 1: \̲p̲_{ij}表示模型i转移到模型j的概率
- 当有两个下标中间有竖线"|"时,表示归一化的信息
- ⋅ ^ \hat \cdot ⋅^ Hat 表示这个变量是某个条件下的最优估计
- 括号():表示时间,如 x ( k ) x(k) x(k)表示时间k的状态x;
- 括号中有竖线:表示观测时间和状态时间,如x(k|k-1)表示在k-1时刻的观测信息得到k时刻的状态,如x(k|k)表示基于k时刻的观测估计的k时刻的状态
2. IMM过程
先有个基本概念,整个过程可描述为:
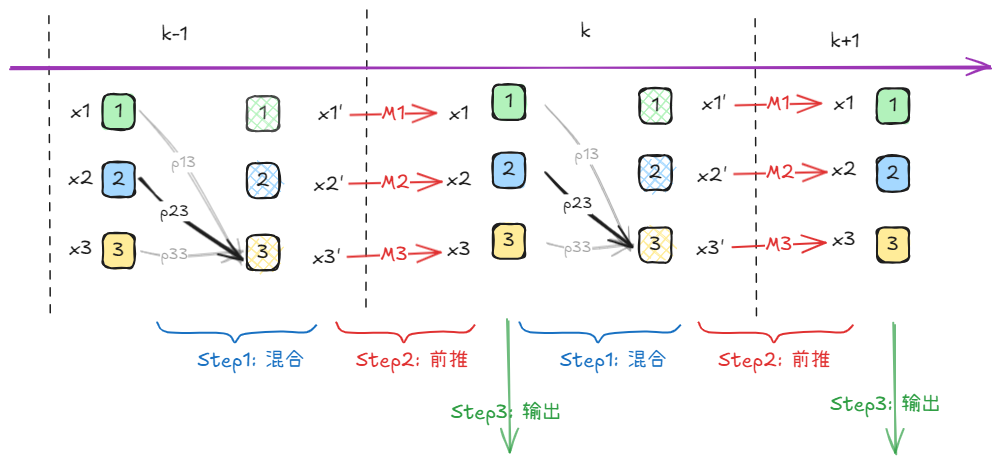
Step1: Interact
交互,顾名思义,就是多个模型之间的交互。
∀ i , j ∈ M f \forall i,j \in M_f ∀i,j∈Mf
μ i ∣ j ( k − 1 ∣ k − 1 ) = 1 c ˉ j p i j μ i ( k − 1 ) \begin{equation} \mu_{i|j}(k-1|k-1) = \frac{1}{\bar c_j}p_{ij}\mu_i(k-1) \end{equation} μi∣j(k−1∣k−1)=cˉj1pijμi(k−1)
解释:
- μ i ( k − 1 ) \mu_i(k-1) μi(k−1)是k-1时刻,模型 i i i的概率
- μ i ∣ j ( k − 1 ∣ k − 1 ) \mu_{i|j}(k-1|k-1) μi∣j(k−1∣k−1) 表示的就是k-1时刻,模型i转移的j的混合概率;
- 这个公式表达的还是在k-1时刻的进行的估计,是基于k-1时刻的观测和状态,对下一个状态概率的预估
- 为了描述方便,本章节中的变量都略去时刻的表述 ( k − 1 ∣ k − 1 ) (k-1|k-1) (k−1∣k−1)
式(1)这个过程表达了模型i到模型j转移的混合概率,其实就是在转移概率 p i j p_{ij} pij的基础上混合了当前状态i模型的概率
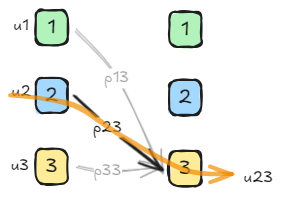
如图, u 23 u_{23} u23表达的是从模型2转移到模型3的概率,混合上当前的模型2的概率
可以表达为
[ μ 11 μ 12 μ 13 ] = [ p 11 p 12 p 13 ] μ 1 [ μ 21 μ 22 μ 23 ] = [ p 21 p 22 p 23 ] μ 2 [ μ 31 μ 32 μ 33 ] = [ p 31 p 32 p 33 ] μ 3 \begin{bmatrix} \mu_{11} & \mu_{12} & \mu_{13} \end{bmatrix} = \begin{bmatrix} p_{11} & p_{12} & p_{13} \end{bmatrix} \mu_{1} \\ \begin{bmatrix} \mu_{21} & \mu_{22} & \mu_{23} \end{bmatrix} = \begin{bmatrix} p_{21} & p_{22} & p_{23} \end{bmatrix} \mu_{2} \\ \begin{bmatrix} \mu_{31} & \mu_{32} & \mu_{33} \end{bmatrix} = \begin{bmatrix} p_{31} & p_{32} & p_{33} \end{bmatrix} \mu_{3} [μ11μ12μ13]=[p11p12p13]μ1[μ21μ22μ23]=[p21p22p23]μ2[μ31μ32μ33]=[p31p32p33]μ3
然后还要归一化一次,表示了转移到模型 i ∈ [ 1 , 3 ] i\in[1,3] i∈[1,3]的一致性概率,可以理解为, u i 1 u_{i1} ui1表示从上一时刻多个模型转移到模型1的概率,归一化是所有转移到模型1的概率。有点绕,看公式
μ 2 ∣ 3 = μ 23 μ 13 + μ 23 + μ 33 \begin{equation} \mu_{2|3} = \frac{\mu_{23}}{\mu_{13}+\mu_{23}+\mu_{33}} \end{equation} μ2∣3=μ13+μ23+μ33μ23
注:先不要纠结为什么这里要归一化概率,后面会解释
无论什么模型,目的都是为了获得对当前状态的估计。当我们使用多个模型对状态进行估计时,会得到不同模型对状态估计的结果,然后我们将这些结果加权,就得到了多模型混合估计结果。
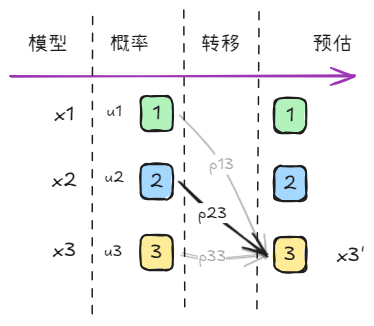
对于上图中的模型转移过程,如果我们要求模型3的预估状态 x 3 ′ x'_3 x3′,很容易想到,通过加权来获得
x 3 ′ = x 1 ⋅ p 13 μ 1 + x 2 ⋅ p 23 μ 2 + x 3 ⋅ p 33 μ 3 p 13 μ 1 + p 23 μ 2 + p 33 μ 3 x'_3=\frac{x_1\cdot p_{13}\mu_1+x_2\cdot p_{23}\mu_2+x_3\cdot p_{33}\mu_3}{ p_{13}\mu_1+ p_{23}\mu_2+ p_{33}\mu_3} x3′=p13μ1+p23μ2+p33μ3x1⋅p13μ1+x2⋅p23μ2+x3⋅p33μ3
显然,式(2)就是这个权重。
即
x 3 ′ = x 1 ⋅ μ 1 ∣ 1 + x 2 ⋅ μ 2 ∣ 1 + x 3 ⋅ μ 1 ∣ 3 x'_3=x_1\cdot \mu_{1|1}+x_2\cdot \mu_{2|1}+x_3\cdot \mu_{1|3} x3′=x1⋅μ1∣1+x2⋅μ2∣1+x3⋅μ1∣3
总结下,Step1得到了对状态的估计模型 x ′ x' x′,论文中记 x ^ 0 j \hat x_{0j} x^0j,有了状态我们还需要相关协方差 P P P,同样,协方差的更新于状态量类似,
P ^ 3 = P 1 ′ ⋅ μ 1 ∣ 1 + P 2 ′ ⋅ μ 2 ∣ 1 + P 3 ′ ⋅ μ 1 ∣ 3 \hat P_3=P'_1\cdot \mu_{1|1}+P'_2\cdot \mu_{2|1}+P'_3\cdot \mu_{1|3} P^3=P1′⋅μ1∣1+P2′⋅μ2∣1+P3′⋅μ1∣3
其中
P 1 ′ = P 1 + ( x ^ 3 ′ − x 1 ) × ( x ^ 3 ′ − x 1 ) T P'_1=P_1+(\hat x'_3-x_1) \times (\hat x'_3-x_1)^T P1′=P1+(x^3′−x1)×(x^3′−x1)T
公式表示即为:
P ^ j = ∑ i P i ′ ⋅ μ i ∣ j = ∑ i [ P i + ( x ^ j 0 − x i ) × ( x ^ j 0 − x i ) T ] ⋅ μ i ∣ j \begin{equation} \hat P_j =\sum_{i}P'_i\cdot \mu_{i|j} = \sum_{i}[P_i+(\hat x_{j0}-x_i)\times (\hat x_{j0}-x_i)^T]\cdot \mu_{i|j} \end{equation} P^j=i∑Pi′⋅μi∣j=i∑[Pi+(x^j0−xi)×(x^j0−xi)T]⋅μi∣j
再来理解一下这些变量的含义, u 13 , u 23 , u 33 u_{13},u_{23},u_{33} u13,u23,u33是所有模型转移到模型3的概率,记
c ˉ j = u 1 j + u 2 j + u 3 j = ∑ i μ i j = ∑ i p i j u i \bar c_j=u_{1j}+u_{2j}+u_{3j}=\sum_i \mu_{ij}=\sum_i p_{ij}u_i cˉj=u1j+u2j+u3j=i∑μij=i∑pijui
Step 2: Filtering
在Step1中,都是在k-1时刻发生的,因为模型本身并没有进行时域上的前推,现在我们需要对每个模型都通过模型参数预测(前推)一步,所以Step2要进行时序的推演,则状态和协方差的转移可以表述为: ∀ j ∈ M f \forall j \in M_f ∀j∈Mf,
x ^ j ( k ∣ k − 1 ) = F j ( k − l ) x ^ j ( k − 1 ∣ k − 1 ) + Γ j ( k − i ) v ˉ j ( k − 1 ) \hat x_j(k|k-1)=F_j(k - l)\hat x_j(k - 1|k - 1)+ \Gamma_j(k-i)\bar v_j(k-1) x^j(k∣k−1)=Fj(k−l)x^j(k−1∣k−1)+Γj(k−i)vˉj(k−1)
其中 Γ \Gamma Γ是过程噪声增益矩阵。
由于公式中的变量为了描述时序信息(k/k-1),看起来有点混乱,为了便于理解,可以描述为:
x ^ j ( k ) = F j x ^ j ( k − 1 ) + Γ j v ˉ j \hat x^{(k)}_j=F_j\hat x^{(k-1)}_j+ \Gamma_j\bar v_j x^j(k)=Fjx^j(k−1)+Γjvˉj
同理,协方差的推演表述为:
P j ( k ) = F j P j ( k − 1 ) F j T + Γ j Q j Γ j T P^{(k)}_j=F_jP^{(k-1)}_jF^T_j+\Gamma_j Q_j \Gamma_j^T Pj(k)=FjPj(k−1)FjT+ΓjQjΓjT
其中 Q J Q_J QJ为过程噪声方差。
以上是都是在k-1时刻观测下进行的计算和推演,当来到了k时刻,有了新的观测,就需要进行Correct操作了,这时候的观测时序变成了k,可以,表述为:
x ^ j ( k ∣ k ) = x ^ j ( k ∣ k − 1 ) + W j ( k ) r j ( k ) P j ( k ∣ k ) = P j ( k ∣ k − 1 ) − W j ( k ) S j ( k ) W j ( k ) T \hat x_j(k|k)=\hat x_j(k|k-1) + W_j(k)r_j(k) \\ P_j(k|k)=P_j(k|k-1)-W_j(k)S_j(k)W_j(k)^T x^j(k∣k)=x^j(k∣k−1)+Wj(k)rj(k)Pj(k∣k)=Pj(k∣k−1)−Wj(k)Sj(k)Wj(k)T
其中:
- r j ( k ) = z j ( k ) − z ^ j ( k ∣ k − 1 ) r_j(k)=z_j(k)-\hat z_j(k|k-1) rj(k)=zj(k)−z^j(k∣k−1)表达了观测残差,计算方式为:
z ^ j ( k ∣ k − 1 ) = H j ( k ) x ^ j ( k ∣ k − 1 ) \hat z_j(k|k-1)=H_j(k)\hat x_j(k|k-1) z^j(k∣k−1)=Hj(k)x^j(k∣k−1) - R j ( k ) R_j(k) Rj(k)为测量方差
- S j ( k ) S_j(k) Sj(k)为残差方差,计算方式为
S j ( k ) = H j ( k ) P j ( k ∣ k − 1 ) H j ( k ) T + R j ( k ) S_j(k)=H_j(k)P_j(k|k-1)H_j(k)^T+R_j(k) Sj(k)=Hj(k)Pj(k∣k−1)Hj(k)T+Rj(k) - W j ( k ) W_j(k) Wj(k)表示滤波器增益矩阵,计算方式为
W j ( k ) = P j ( k ∣ k − 1 ) H j ( k ) S j ( k ) − 1 W_j(k)=P_j(k|k-1)H_j(k)S_j(k)^{-1} Wj(k)=Pj(k∣k−1)Hj(k)Sj(k)−1
根据观测的残差,可以根据残差计算出模型j的likehood,
Λ j ( k ) = N ( r j ( k ) , 0 , S j ( k ) ) \Lambda_j(k)=N(r_j(k), 0, S_j(k)) Λj(k)=N(rj(k),0,Sj(k))
根据模型j的likehood,来更新模型j的概率
μ j ′ ( k ) = Λ j ( k ) c ˉ j \mu'_j(k)=\Lambda_j(k)\bar c_j μj′(k)=Λj(k)cˉj
归一化之后为
μ j ( k ) = μ j ′ ( k ) ∑ i μ i ′ ( k ) \begin{equation} \mu_j(k)=\frac{\mu'_j(k)}{\sum_i \mu'_i(k)} \end{equation} μj(k)=∑iμi′(k)μj′(k)
总结下,Step2主要进行了:
- 基于模型的推演,得到推演后模型的状态估计及协方差
- 基于推演模型状态和观测的残差,得到每个模型的likehood
- 基于likehood,推演出每个模型新的概率
Step3: Combination
Combination这一步非常简单,就是将多个模型的输出加权,得到对外的最终输出估计,即
x ^ ( k ∣ k ) = ∑ j x ^ j ( k ∣ k ) μ j ( k ) \hat x(k|k) = \sum_j \hat x_j(k|k)\mu_j(k) x^(k∣k)=j∑x^j(k∣k)μj(k)
同理,输出的协方差为
P ( k ∣ k ) = ∑ j P j ′ ( k ∣ k ) μ j ( k ) P(k|k)=\sum_j P'_j(k|k)\mu_j(k) P(k∣k)=j∑Pj′(k∣k)μj(k)
其中 P j ′ ( k ∣ k ) = P j ( k ∣ k ) + [ x ^ ( k ∣ k ) − x ^ j ( k ∣ k ) ] × [ x ^ ( k ∣ k ) − x ^ j ( k ∣ k ) ] T P'_j(k|k)=P_j(k|k)+[\hat x(k|k) - \hat x_j(k|k)]\times[\hat x(k|k) - \hat x_j(k|k)]^T Pj′(k∣k)=Pj(k∣k)+[x^(k∣k)−x^j(k∣k)]×[x^(k∣k)−x^j(k∣k)]T
以上,就是IMM的整个过程。
注:Step3 的结果只用来输出,以及通过状态量只用来更新协方差
3. 示例描述
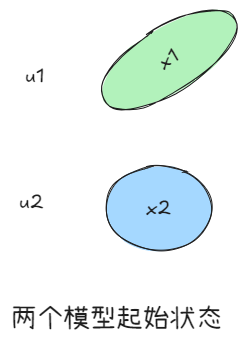
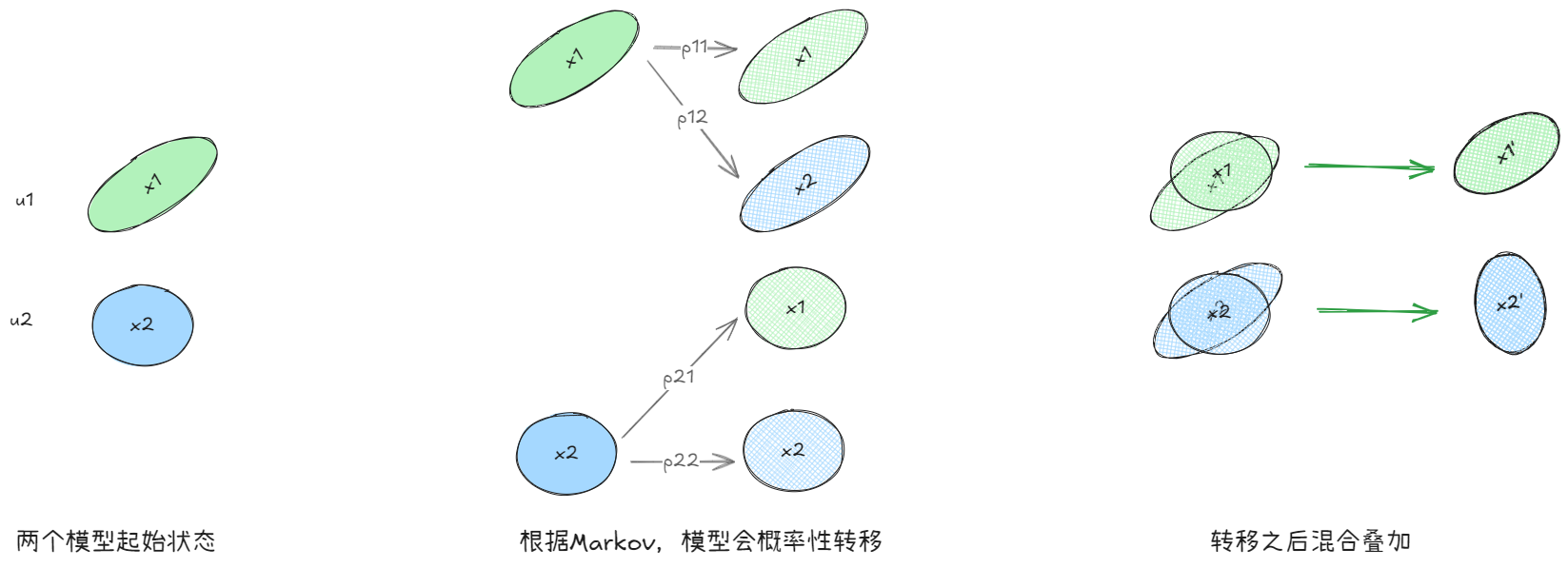
假设我们使用两个模型1和2来对一个观测进行估计,假设两个模型是二维高斯模型,初始状态如下,分别表示两个模型的状态、方差和概率
Step1:混合
如图,每个模型都有一定概率转移到另一个模型,我们对转移后的模型态进行混合叠加,在这个过程中,需要更新的变量有:
- 状态量 x x x,基于模型概率和转移概率
- 协方差 P P P,基于初始协方差和转移叠加后的误差
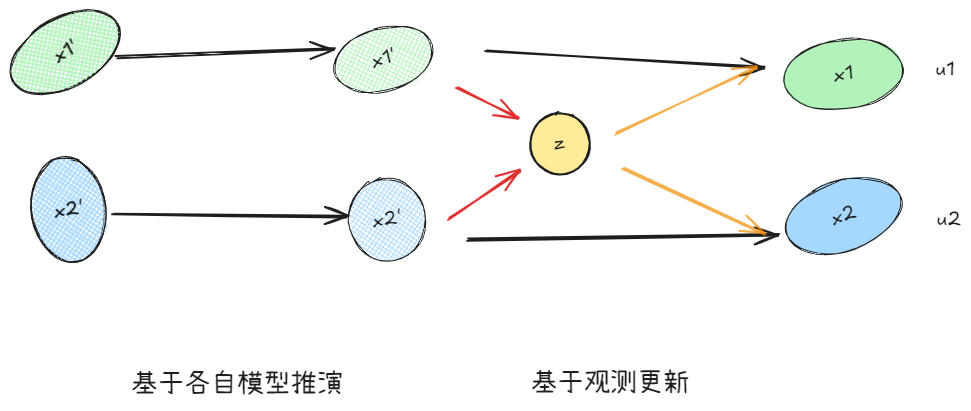
Step2:滤波/更新
如图,基于当前的观测z,分别对两个模型进行更新,这个过程更新的变量包括:
- 状态量 x x x,基于模型推演,并根据观测更新
- 协方差 P P P,基于推演转移,即观测残差
- 模型概率 μ \mu μ,基于残差的likehood
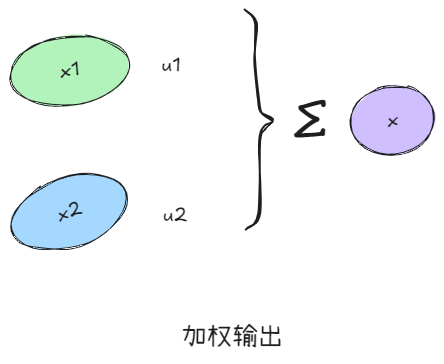
Step3:合并
这一步比较简单,将更新的状态和概率直接加权混合,得到最终输出状态估计值,这个过程中更新的变量包括:
- 状态量 x x x,基于加权后的最优估计
- 协方差 P P P,基于加权后最优估计与当前模态值的残差
参考文献
[^1] E. Mazor, A. Averbuch, Y. Bar-Shalom and J. Dayan, “Interacting multiple model methods in target tracking: a survey,” in IEEE Transactions on Aerospace and Electronic Systems, vol. 34, no. 1, pp. 103-123, Jan. 1998, doi: 10.1109/7.640267