当前位置: 首页 > web >正文 spark和hadoop的区别 web 2025/7/14 15:26:04 一、spark概述 二、处理速度 三、 编程模型 四、实时性处理 五、spark内置模块 六、spark的运行模式 查看全文 http://www.xdnf.cn/news/865.html 相关文章: 【C++游戏引擎开发】第19篇:Compute Shader实现Tile划分 计组1.2.2——各个硬件的工作原理 硬件工程师面试常见问题(4) 操作系统期中复习 车载软件架构 --- 二级boot设计说明需求规范 序列号绑定的SD卡坏了怎么办? AI驱动下的企业学习:人力资源视角下的范式重构与价值觉醒 Materials Studio(二)——无机分子建模 当try遇见catch:前端异常捕获的边界与突围 ADB -> pull指令推送电脑文件到手机上 24. git revert [渗透测试]渗透测试靶场docker搭建 — —全集 【Linux】轻量级命令解释器minishell 计算机组成原理笔记(十九)——4.4定点乘法运算 CentOS 7进入救援模式——VirtualBox虚拟机 深入解析Vue3响应式系统:从Proxy实现到依赖收集的核心原理 Kubernetes 创建 Jenkins 实现 CICD 配置指南 目标检测中的损失函数(二) | BIoU RIoU α-IoU k8s之 kube-prometheus监控 6N60-ASEMI机器人功率器件专用6N60 RabbitMQ 进程控制(linux) Tailwind 武林奇谈:bg-blue-400 失效,如何重拾蓝衣神功? CSS零基础入门笔记:狂神版 http 文件下载和上传服务 Android RK356X TVSettings USB调试开关 LabVIEW数据采集与传感系统 【项目管理】成本类计算 笔记 离线安装rabbitmq全流程 postman乘法计算,变量赋值

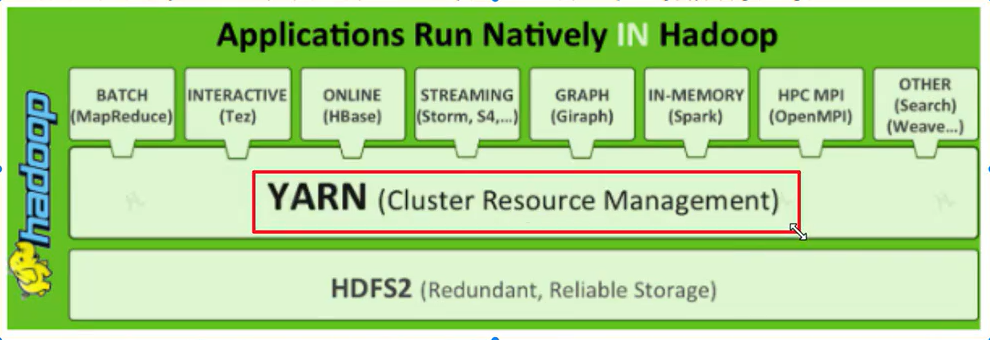 二、处理速度
二、处理速度

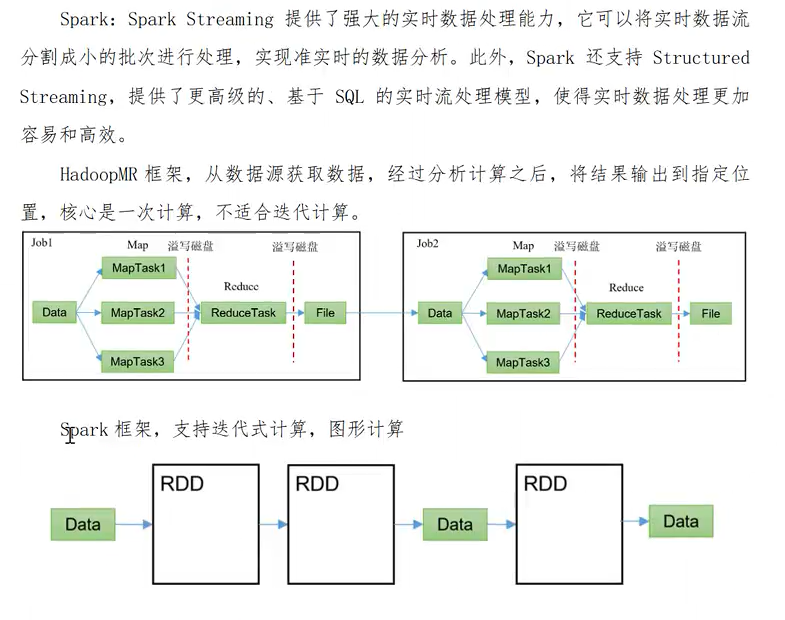


 二、处理速度
二、处理速度