篇章九 消息持久化(一)
目录
1.消息存储格式设计
1.1 为什么不在数据库中存储消息
1.2 消息如何在文件中存储
2.消息垃圾回收的设计
2.1 为什么要消息垃圾回收
2.2 如何进行消息垃圾回收
2.3 什么时候触发GC
3. 思考:消息文件拆分合并
1.消息存储格式设计
1.1 为什么不在数据库中存储消息
1.消息操作并不涉及到复杂的增删改查
2.消息数量可能非常多 数据库的访问效率并不高
故直接把消息存储到文件中
1.2 消息如何在文件中存储
整体存储文件目录结构
首先消息是依附于队列的,因此存储的时候就把消息按照队列维度展开。此时我们数据库那边有一个 数据目录 ./data,所以在data中创建一些子目录:每个队列有一个子目录,子目录的名字就是队列名。如下图所示:
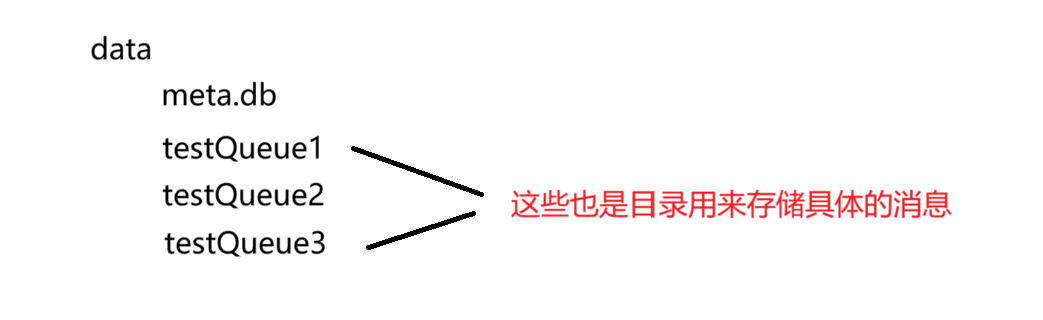
此处,每个队列的子目录下,再分配两个文件,来存储消息
第一个文件:queue_data.txt 这里保存消息的内容
第二个文件:queue_stat.txt 这里保存消息的统计消息
对queue_data.txt 文件做出约定:
queue_data 这个文件将包含若干消息,每个消息以二进制的方式存储,每个消息格式如下图:

此处的Message序列化 将使用标准库的序列化来实现
消息的二进制数据 存储格式:
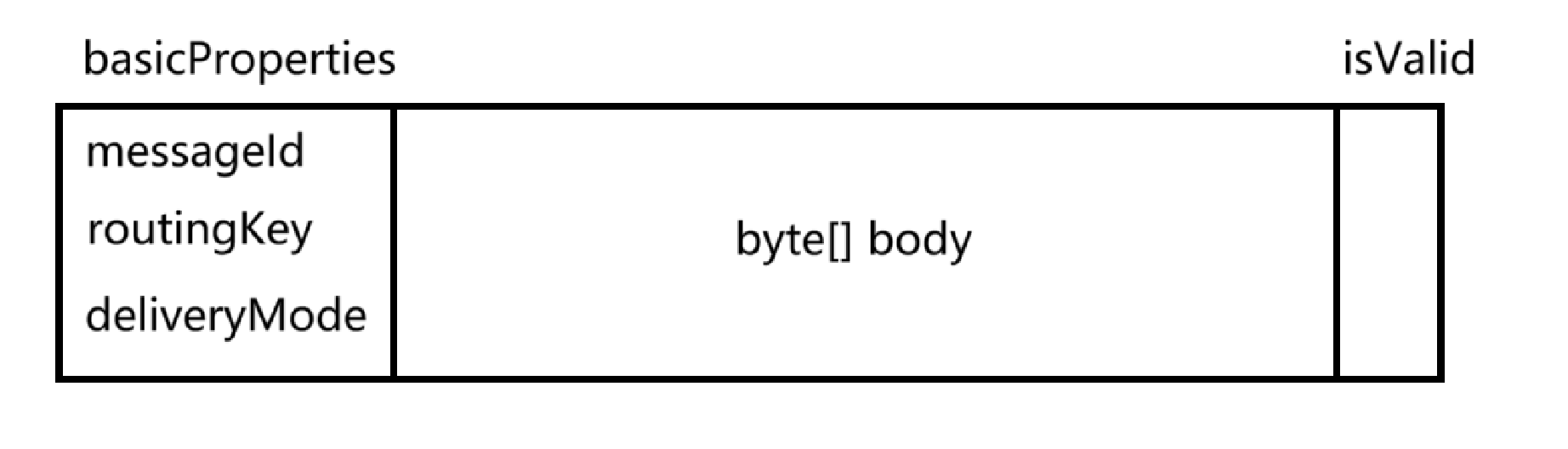
Message对象没有具体的长度(因为正文部分不固定长度,是个字节数据)
此处采用 offsetBeg 和 offsetEnd字段 来解决这个变长问题
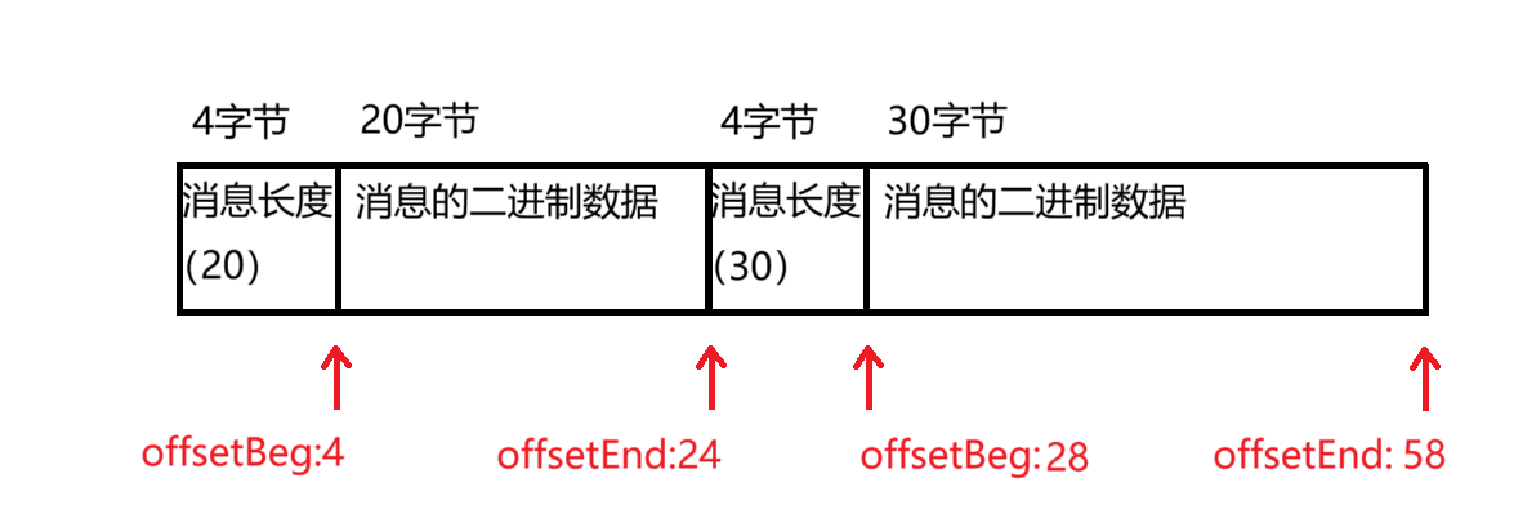
Message对象 在内存中存一份,在硬盘中存一份。内存中的那一份要记录 offsetBeg 和 offsetEnd字段。 以便随时 找到内存中的 Message对象,就能找到对应的硬盘上的 Message对象
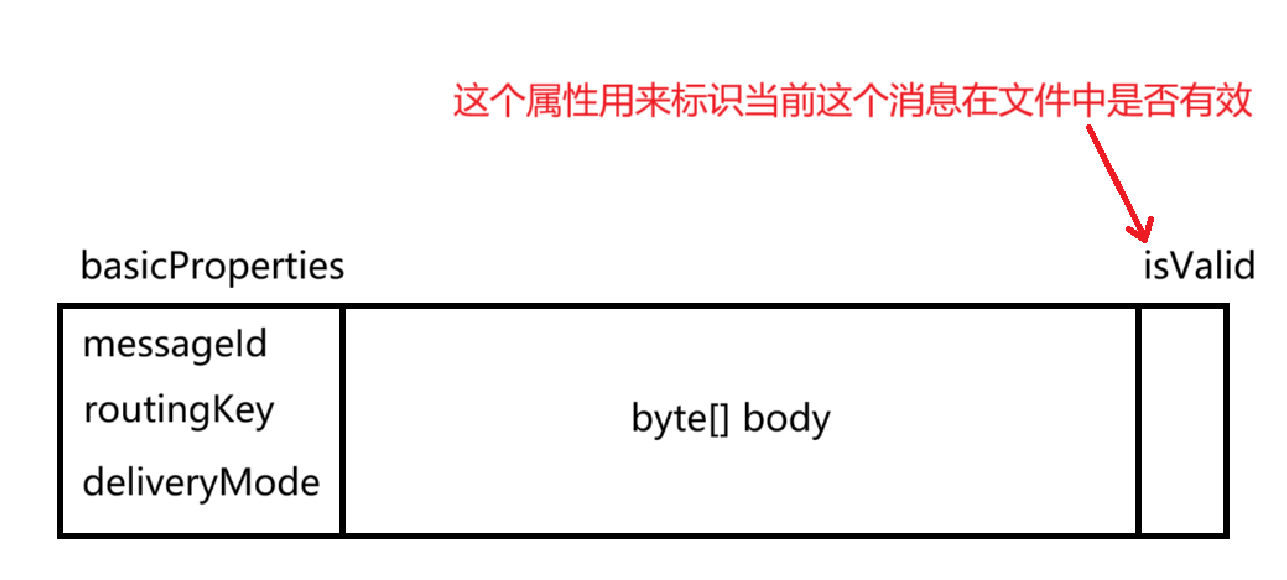
isValid字段的解析:
对于Broker Server 来说消息是需要新增,也需要删除的。
生产者生产一个消息需要新增,消费者消费一个消息需要删除。
新增和删除对于内存来说很好办(使用集合类),但是在文件中怎么办?
新增:直接把新消息追加到文件末尾
删除:
1.方案一——直接删除:文件表可以视为一个“顺序表”这样的结构。如果直接删除中间元素,就需要设计到类似于“顺序表搬运”的操作,效率很低。因此此方案不合适。
2.方案二——逻辑删除:采用isValid字段 ,并随消息存储到文件中
1 有效消息
0 无效消息(已经被删除)
对 queue_stat.txt 文件做出约定:
使用这个文件来 保存消息的统计信息
只存一行数据(文本格式):
一行 两列
第一列:queue_data.txt 中 消息数目
第二列:queue_data.txt 中 有效消息数目
两者使用 \t 分割
如下图所示:
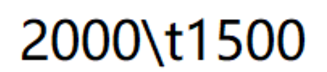
2.消息垃圾回收的设计
2.1 为什么要消息垃圾回收
采用上述方案二,随着时间的推移,这个消息文件会越来越大,并且,这里可能大部分都是无效消息,针对这种情况,就需要考虑对当前的消息数据文件,进行垃圾回收
2.2 如何进行消息垃圾回收
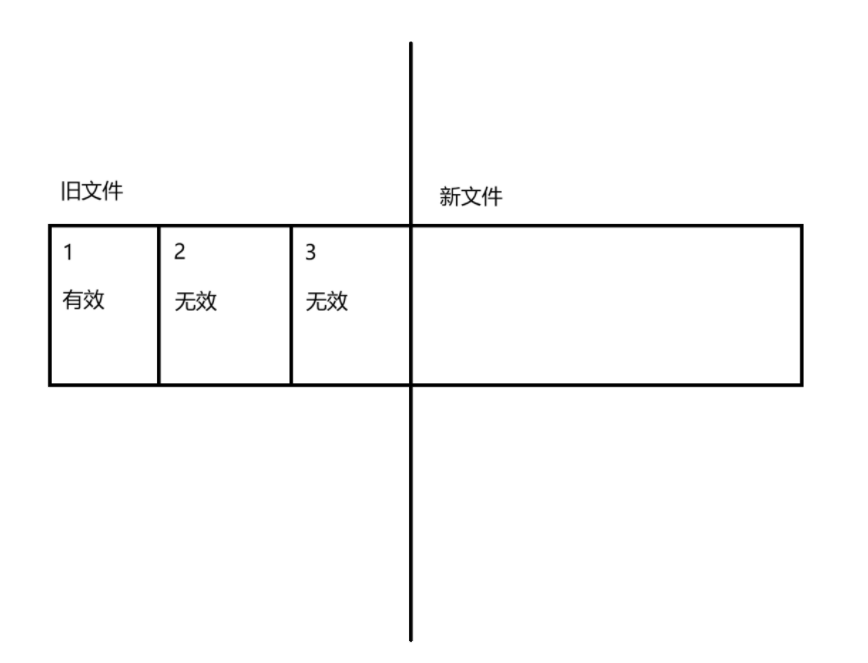
方案 :复制算法
如下图所示:
原始数据:
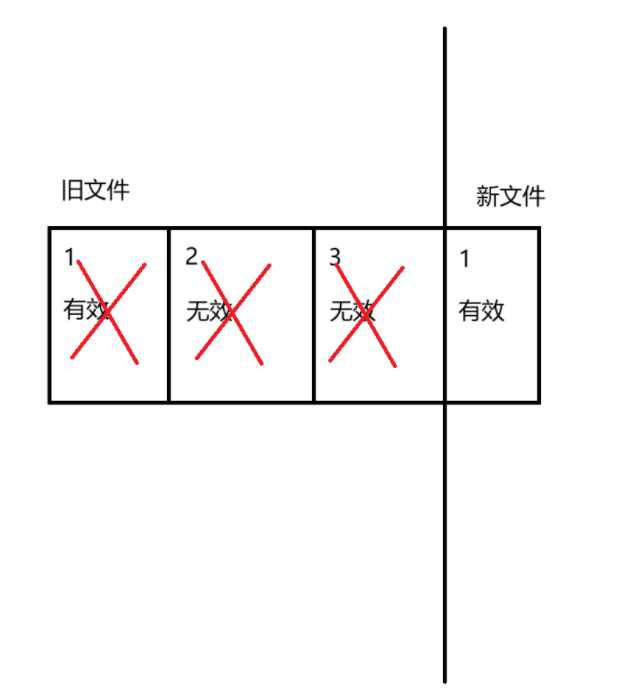
使用复制算法进行垃圾回收:
方案综述:
直接遍历原有的消息数据文件,把所有有效的数据拷贝到一个新的文件中,再把之前整个旧的文件都删除。
2.3 什么时候触发GC
很显然你不能频繁触发它,毕竟它的开销很大,那么什么时候触发比较合适呢?
为了避免频繁触发GC,此处做出约定,当消息数目超过 2000,并且有效消息数目低于总消息数目的 50%,就触发一次GC。上述的数字很显然可以灵活调整,先由程序员自己决定,最后根据项目测试得出一个比较合适的数值进行优化。
3. 思考:消息文件拆分合并
很显然上述的思路还有些欠缺,但是已经并不影响我们消息文件的存储了。这里提出一个可行的优化方案,如果后续时间充足就可以把它实现(RabbitMQ实现了):
如果某个队列,消息特别多,而且还都是有效消息怎么办?
此时就会导致整个消息的数据文件特别大,后续针对这个文件的操作,成本迅猛提升。
而RabbitMQ 的解决方案是,把一个较大的文件拆成若干个小的文件。
文件拆分:当单个文件长度达到一定阈值之后,就会拆分成两个文件。
文件合并:每个单独的文件都会进行 GC, 如果GC后,文件变小了很多,就可以和相邻文件合并
这样做的好处就是:可以在消息特别多的时候也能保证性能上的及时响应。
如何实现:
实现这个机制的大致思路:
1.需要专门的数据结构 来存储当前队列有多少个数据文件,每个文件的大小,消息数目,无效消息数目。
2.策略:什么时候触发文件拆分,什么时候触发文件合并