Linux 文件(3)
文章目录
- 1. Linux下一切皆文件
- 2. 文件缓冲区
- 2.1 缓冲区是什么
- 2.2 缓冲区的刷新策略
- 2.3 为什么要有缓冲区
- 2.4 一个理解缓冲区刷新的例子
- 3. 标准错误
1. Linux下一切皆文件
在刚开始学习Linux的时候,我们就说Linux下一切皆文件——键盘是文件,显示器是文件,网卡是文件,硬盘也是文件。
可这到底该如何理解呢?为什么Linux下一切皆文件呢?
从操作系统的角度而言,操作系统必须要管理好各种硬件资源,所以必须先描述,再组织,而Linux下一切皆文件,所以描述硬件,同样使用struct file来进行描述。
而硬件又是如何被访问的呢?我们用户想要访问硬件,一定是通过进程进行访问的,而硬件在操作系统中以struct file的形式被描述,一切皆文件,进程访问硬件,其实就是在访问文件。
然而,有一个问题必须要考虑:不同的硬件必然具有不同的读写方式,都使用struct file进行封装,又如何区别不同的硬件之间的读写方式呢?
Linux中,使用函数指针来实现。在struct file结构体中,有一个这样的成员变量:

这是一个指针变量,指向一个结构体,这个结构体中包含的是硬件的操作方法集,即各种函数指针,指向读操作的函数,写操作的函数,重定位的函数等等。
所以,虽然不同的硬件都是用struct file进行描述,但是依然能够通过不同的读写方式去操作不同的硬件。OS在为各个硬件创建struct file时,就自动为不同的硬件分配了其所对应的操作方法集。
所以,在进程的角度,只需要直接对文件进行操作,在进程看来,都是struct file,而不用去区分具体硬件之间的不同。
这就是Linux下一切皆文件的核心。站在进程的角度,一切都是struct file,一切都可以通过同一套文件操作接口进行操作,而不用去区分实际差别。
实际上,在进程角度的struct file,是Linux中所设计的虚拟文件系统,即VFS,Linux中封装了这么一层软件层后,开发者通过进程,只需要一套文件操作接口,就可以调度Linux中的大部分资源,这就是Linux内核设计的高明之处,是多态思想的重要体现。
2. 文件缓冲区
Linux下在打开文件时,为相应文件创建struct file,而在struct file有三个核心点:文件属性,文件内核缓冲区和文件操作方法集。
文件内核缓冲区是什么呢?之前我们说,我们使用系统调用接口read或者write,不是直接从文件读或向文件写,而是向文件的内核缓冲区写,从文件的内核缓冲区读。那么接下来,我们就重点来谈一谈缓冲区这个概念。
2.1 缓冲区是什么
缓冲区本质上就是一段内存空间。
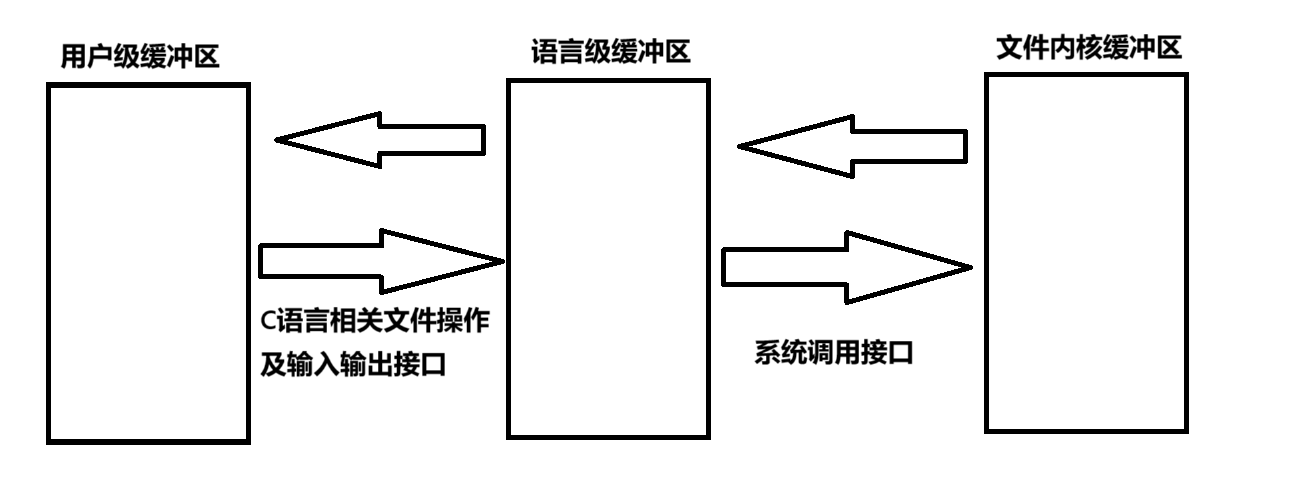
缓冲区通常会有三种:用户级缓冲区,语言级缓冲区和内核文件缓冲区。
用户级缓冲区,就是指开发者自己开辟并用于存储数据的一段空间;语言级缓冲区,是指各种编程语言在为我们封装文件时,内部所提供的缓冲区。
对于语言级缓冲区,我们以C语言为例。
C语言中,封装了FILE这个结构体,C语言的相关文件操作接口,都要设计到FILE。而在FILE中,除了会涉及到文件描述符,即fileno外,还会有一个输入缓冲区和一个输出缓冲区char* in_buffer 和 char* out_buffer。这两个缓冲区,就是语言级别的缓冲区。
实际上,我们使用C语言的相关文件接口进行读和写时,都是从语言级的缓冲区中读写,而不涉及到文件内核缓冲区。
我们以写文件为例。我们使用printf向标准输出中写,首先是将用户级缓冲区中的内容,写到语言级缓冲区中,而每一个缓冲区都会具有一定的刷新策略,当满足相应条件时,语言级缓冲区就会通过系统调用write,将其中的内容刷新到文件内核缓冲区中。就进程而言,将内容写到文件内核缓冲区后,即可认为成功写入,因为文件内核缓冲区的刷新,主要由操作系统管理(当然开发者也可以通过fsync系统调用刷新)。
2.2 缓冲区的刷新策略
就语言级别的缓冲区而言,写入时的刷新策略主要有二种:
- 行缓冲。在写入内容时遇到换行符即做刷新。否则,缓冲区写满再刷新。
- 全缓冲。直到缓冲区写满后,缓冲区才做刷新。
另外,在进程退出时,也会刷新语言级别的缓冲区;当然,我们也可以使用fflush主动刷新语言级缓冲区。
就文件内核缓冲区而言,写入时的刷新策略也主要是行缓冲和全缓冲,但是文件内核缓冲区主要由操作系统进行管理,刷新策略实际会更加复杂,会涉及到一些动态刷新等。
另外,在文件关闭时,文件内核缓冲区也会被刷新;当然,我们也可以使用fsync系统调用,主动刷新文件内核缓冲区。
对于显示器文件而言,相关缓冲区一般是行缓冲;对于普通文件而言,相关缓冲区一般是全缓冲。
2.3 为什么要有缓冲区
为什么要有语言级别的缓冲区?
如果没有语言级别的缓冲区,直接从用户缓冲区向文件内核缓冲区中写,会频繁使用系统调用write,而系统调用的使用成本是很高的,消耗太大,会降低编程语言的运行效率,因此必须要有语言级别的缓冲区。
那为什么要有文件内核缓冲区呢?
如果没有文件内核缓冲区,即无法做到多次输入,一次刷新,就会频繁地进行磁盘级I/O,而磁盘级I/O的效率是很低的,那么这样,整个程序的运行效率也会下降。
总而言之,缓冲区的存在,是为了提高进程运行的效率,避免无意义的消耗。
2.4 一个理解缓冲区刷新的例子
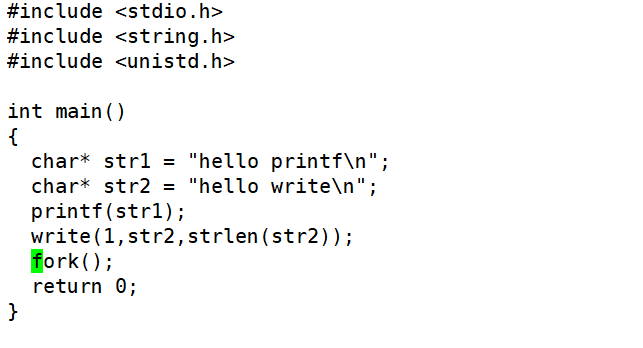
来看上述代码重定向前与重定向后运行结果的不同:
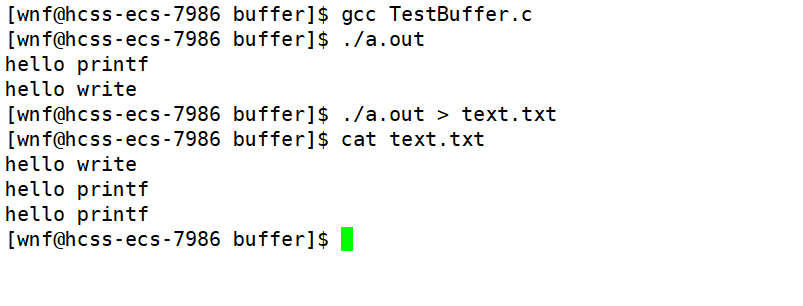
为什么重定向前后的输出结果会不同呢?这就涉及到缓冲区刷新策略不同的问题了。
对于write而言,是直接向文件描述符为1的文件内核缓冲区中写;而对于printf,虽然默认也是向标准输出中写,但是它首先会将内容写到C语言自身设计的语言级缓冲区中。
未重定向前,write和printf都是最终写入到标准输出中,即显示器文件,而标准输出所对应的语言级缓冲区和文件内核缓冲区都是以行缓冲的形式进行刷新,所以 printf 输出的字符串,会被立刻由用户级缓冲区刷新到文件内核缓冲区,再刷新到显示器文件中;而write输出的字符串,则直接由文件内核缓冲区刷新到显示器文件中。多进程的创建并不影响整个过程。
重定向后,文件描述符1不再对应标准输出文件,而是对应普通文件,因此语言级缓冲区和文件内核缓冲区的刷新策略都变为全缓冲。多进程的创建对于直接写入到内核缓冲区中的write没有影响(从进程的角度,认为写入到内核缓冲区后,即完成写入),但对于写入语言级缓冲区的printf,此时就有影响了。
由于不再是行缓冲,因此printf写入语言缓冲区后,不会立刻刷新。而当创建多进程后,父子进程之间共享代码和数据,而当进程结束时,语言级缓冲区会被刷新,由于子进程会先于父进程结束,而刷新会对语言缓冲区做出更改,为了确保父子进程间的独立性,就会发生写时拷贝,这样子进程就不再与父进程共享同一个语言缓冲区,这也就意味着,子进程结束,刷新语言缓冲区后,父进程语言缓冲区中的内容并没有被刷新,这也就是为什么上述将打印内容重定向到文件后,会出现两个hello printf 的原因,本质还是因为发生了写时拷贝。
3. 标准错误
下面,我们来简单聊聊标准错误。
标准输入一般对应键盘文件,刷新策略为行缓冲;而标准输出和标准错误一般对应显示器文件,标准输出为行缓冲,标准错误则通常无缓冲,输出即刷新。
既然标准输出和标准错误都对应显示器文件,那为什么要专门区分它们呢?
区分标准输出(fd为1)和标准错误(fd为2),最主要还是为了区分输出流和错误流,即区分正确输出和错误输出。
我们来看下面的一个示例:

我们在命令行中,使用输出重定向来区分标准输出和标准错误。
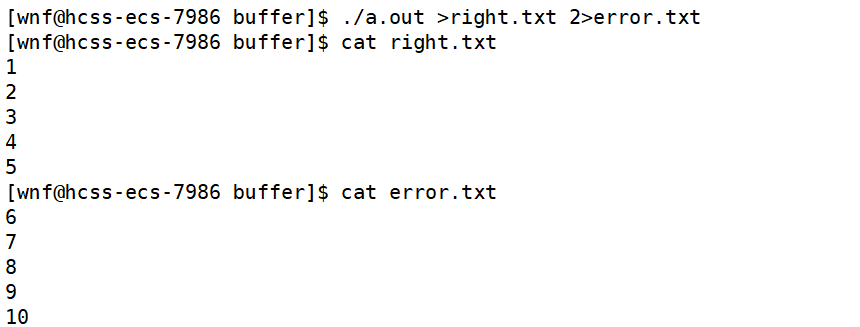
这样,我们就区分出了标准输出和标准错误。
在上述代码中,值得一提的是,如果不指明具体进行重定向的文件描述符,默认是将1号文件描述符,即标准输出进行重定向。
如果不想区分标准输出和标准错误,而想将这两者全部重定向到某个文件中,我们可以在命令行中进行如下操作:
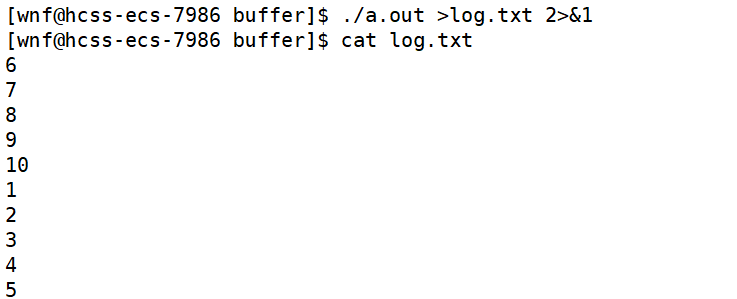
在上述命令行中,我们先将stdout重定向到log.txt中,再将stderr重定向到文件描述符1多对应的文件中,也就是log.txt中。
至于为什么log.txt中,数字的顺序与我们程序的逻辑不太符合,这个不用太在意,因为这个涉及到文件内核缓冲区更加复杂的刷新机制。