【项目】—高并发内存池
一、项目介绍
当前项⽬是实现一个高并发的内存池,原型是google的一个开源项目tcmalloc,tcmalloc全称 Thread-Caching-Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,我们这个项目是把tcmalloc最核心的框架简化后拿出来,模拟实现出⼀个自己的高并发内存池。
- 项目涉及到的知识:C/C++、数据结构(链表、哈希桶)、操作系统内存管理、单例模式、多线程、互斥锁等等⽅⾯的知识。
二、什么是内存池
2.1池化技术
所谓“池化技术”,就是程序先向系统申请过量的资源,然后自己管理,以备不时之需。之所以要申 请过量的资源,是因为每次申请该资源都有较⼤的开销,不如提前申请好了,这样使⽤时就会变得非常快捷,大大提⾼程序运⾏效率。
在计算机中,有很多使用“池”这种技术的地⽅,除了内存池,还有连接池、线程池等。 以服务器上的线程池为例,它的主要思想是:先启动若⼲数量的线程,让它们处于睡眠状态,当接收到客户端的请求时,唤醒池中某个睡眠的线程,让它来处理客⼾端的请求,当处理完这个请求,线程⼜进⼊睡眠状态。
2.2内存池
内存池是指程序预先从操作系统申请⼀块足够大内存,此后,当程序中需要申请内存的时候,不是直接向操作系统申请,而是直接从内存池中获取;同理,当程序释放内存的时候,并不真正将内存返回给操作系统,而是返回内存池。当程序退出时,内存池才将之前申请的内存真正释放。
主要解决的是效率问题,尽可能的减少内存碎片的产生。
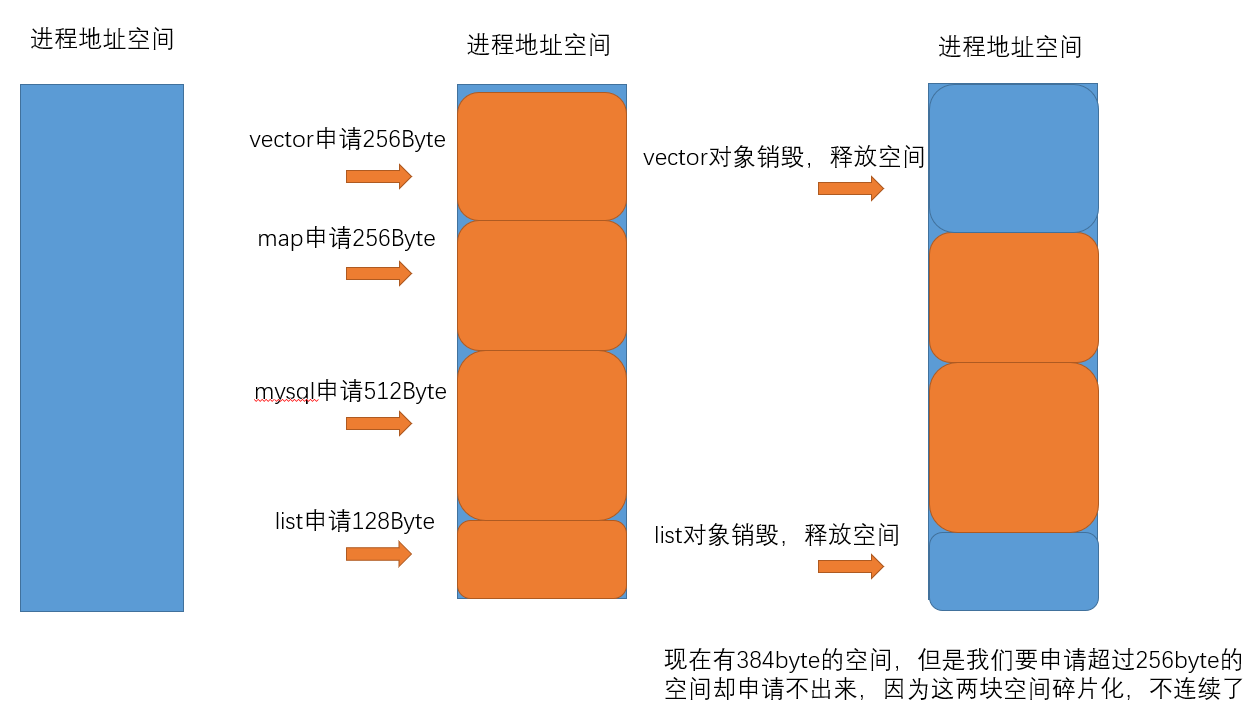
- 外部碎片是⼀些空闲的连续内存区域太小,这些内存空间不连续,以至于合计的内存足够,但是不能满足⼀些的内存分配申请需求。
- 内部碎片是由于⼀些对⻬的需求,导致分配出去的空间中⼀些内存⽆法被利⽤。
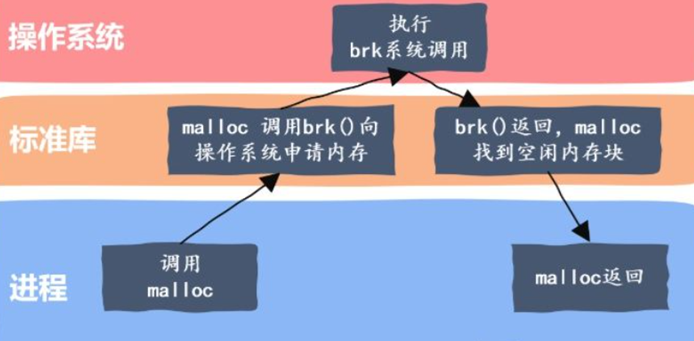
2.2.1malloc
在C/C++中我们要动态申请内存都是通过malloc去申请内存,malloc就是⼀个内存池。malloc()相当于向操作系统“批发”了⼀块较⼤的内存空间,然后“零售”给程序⽤。当全部“售完”或程序有⼤量的内存需求时,再根据实际需求向操作系统“进货”。
2.2.2高并发内存池
这里大家就会问不是有了malloc,为什么还要再设计一个tcmalloc?
tcmalloc用于优化C++写的多线程程序,在多线程的程序中使用tcmalloc要比使用malloc要快。
三、设计与实现定长内存池
针对一种类型定义出属于该类型的定长内存池,申请一个类型的对象就去找指定类型的定长内存池,而malloc可以申请各种大小的对象。一上来先实现定长内存池一是为了简单熟悉一下内存池是如何控制的,二定长内存池是作为整个项目的基础组件(在实现高并发内存池的程序时会动态开辟内存,为了不使用C++中的定位new来动态开辟,而是使用自己实现的定长内存池)。
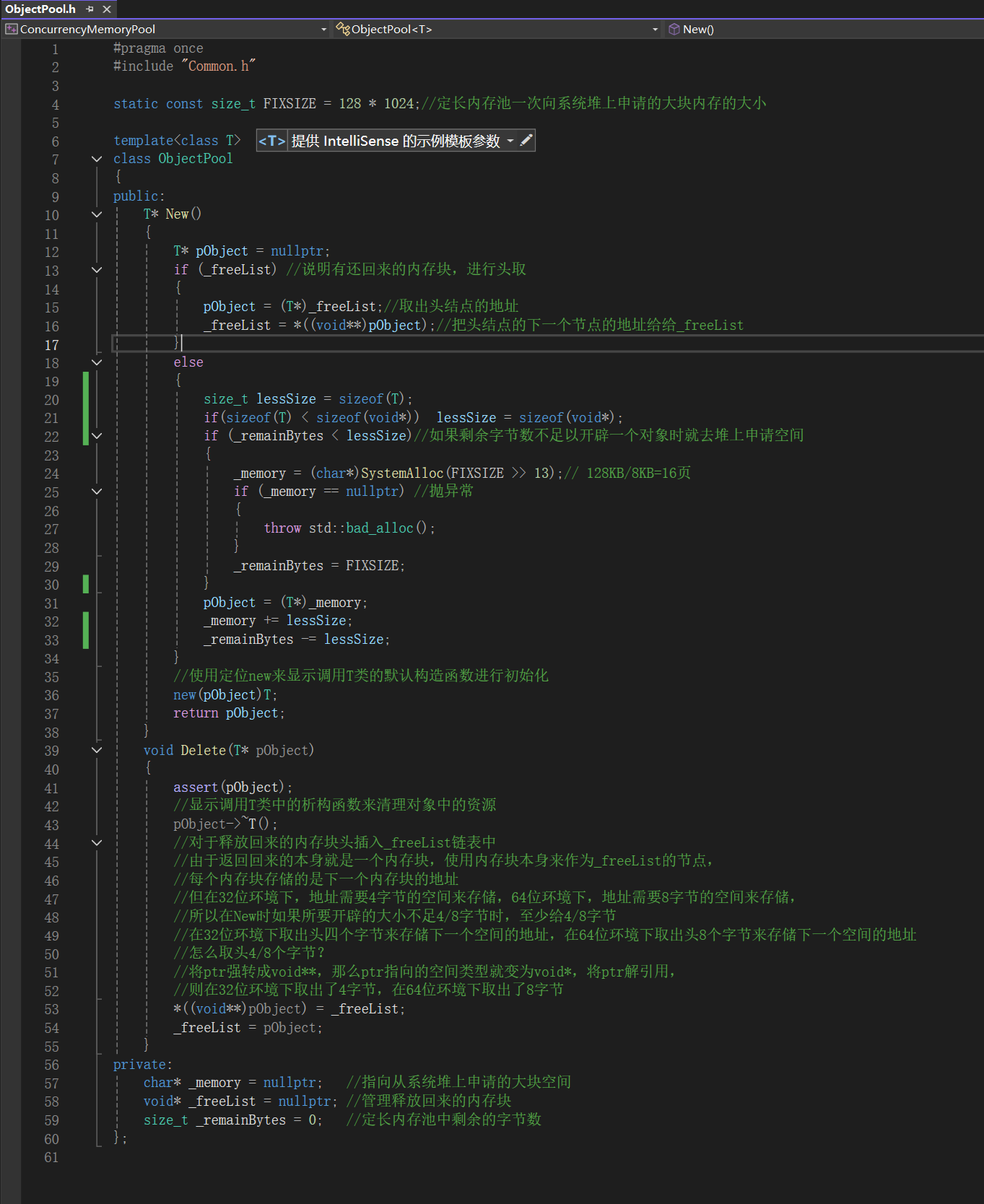
3.1实现定长内存池
3.2自主实现的定长内存池和malloc、free的性能对比
性能测试代码
#include "Common.h"
#include "ObjectPool.h"
#include <vector>
#include <time.h>struct TreeNode
{int _val;TreeNode* _left;TreeNode* _right;TreeNode():_val(0), _left(nullptr), _right(nullptr){}
};
void TestObjectPool()
{// 申请释放的轮次const size_t Rounds = 5;// 每轮申请释放多少次const size_t N = 100000;std::vector<TreeNode*> v1;v1.reserve(N);size_t begin1 = clock();for (size_t j = 0; j < Rounds; ++j){for (int i = 0; i < N; ++i){v1.push_back(new TreeNode);}for (int i = 0; i < N; ++i){delete v1[i];}v1.clear();}size_t end1 = clock();std::vector<TreeNode*> v2;v2.reserve(N);ObjectPool<TreeNode> TNPool;size_t begin2 = clock();for (size_t j = 0; j < Rounds; ++j){for (int i = 0; i < N; ++i){v2.push_back(TNPool.New());}for (int i = 0; i < N; ++i){TNPool.Delete(v2[i]);}v2.clear();}size_t end2 = clock();std::cout << "new cost time:" << end1 - begin1 << std::endl;std::cout << "object pool cost time:" << end2 - begin2 << std::endl;
}
int main()
{TestObjectPool();return 0;
}
- 在代码中,我们先用new申请若干个TreeNode对象,然后再用delete将这些对象再释放,通过clock函数得到整个过程消耗的时间。(new和delete底层就是封装的malloc和free)

- 可以看到在这个过程中,定长内存池消耗的时间比malloc/free消耗的时间要短。这就是因为malloc是一个通用的内存池,而定长内存池是专门针对申请定长对象而设计的,因此在这种特殊场景下定长内存池的效率更高。
四、Thread Cache层
4.1Thread Cache层的实现
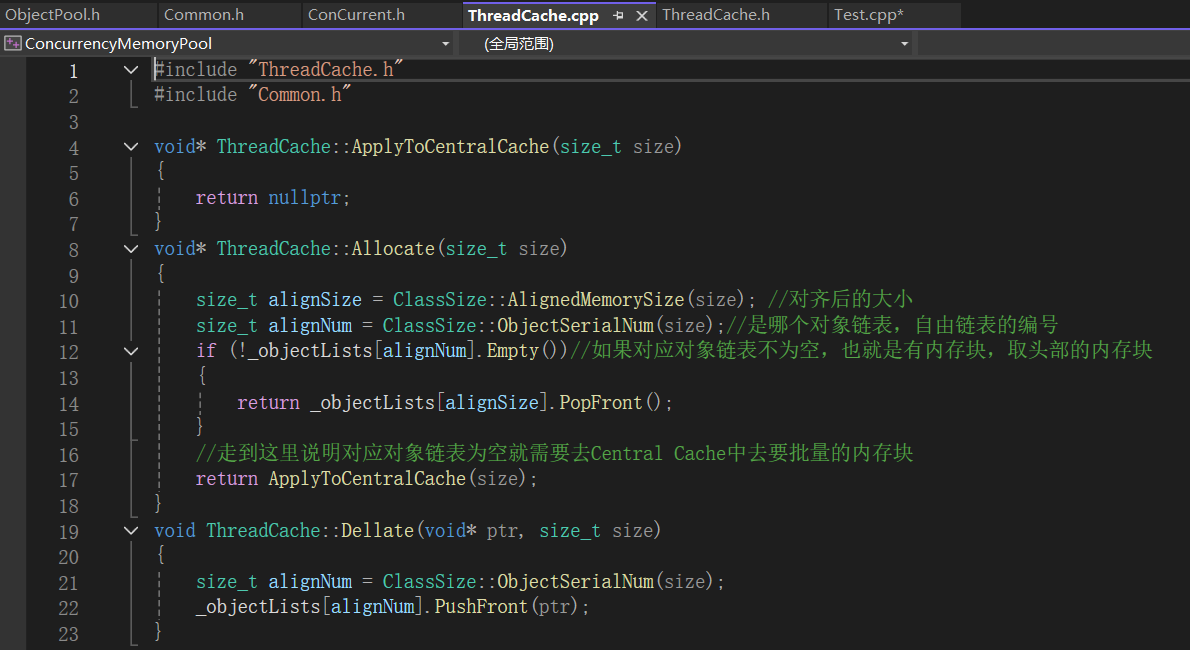
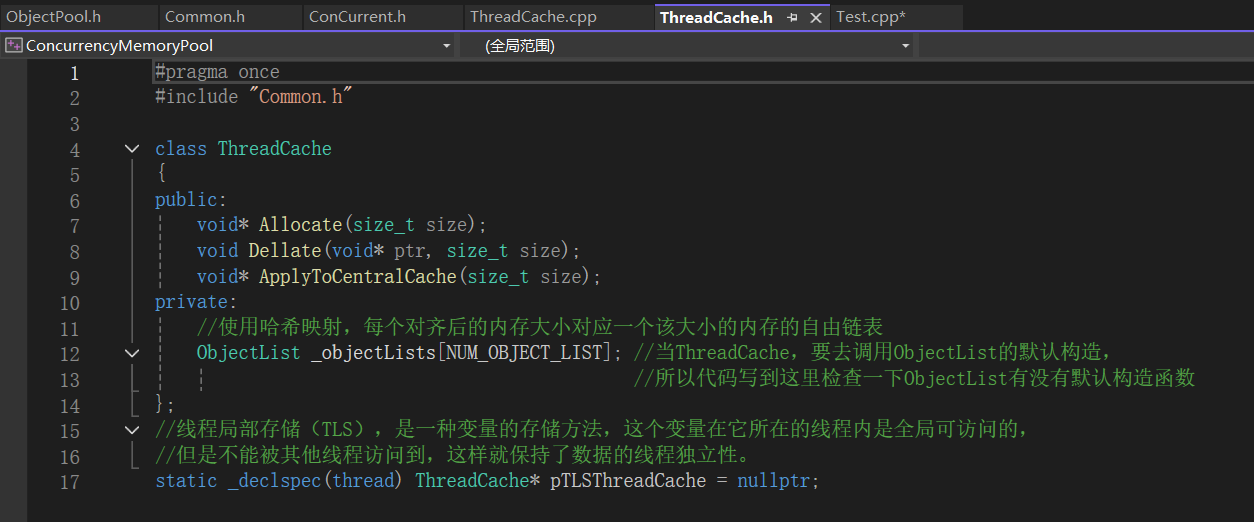
4.2Thread Cache层代码调试
对已经写了的代码进行调试,看代码逻辑是否正确,如果一口气写了很多代码,如果出现问题查找起来不是很容易,在代码量少的情况下,更容易发现问题。
测试代码
void Alloc1()
{for (size_t i = 0; i < 5; ++i){void* ptr = ConCurrentAlloc(6);}
}
void Alloc2()
{for (size_t i = 0; i < 5; ++i){void* ptr = ConCurrentAlloc(9);}
}
void TLSTest()
{std::thread t1(Alloc1);t1.join();std::thread t2(Alloc2);t2.join();
}int main()
{//TestObjectPool();TLSTest();return 0;
}
进行单步调试
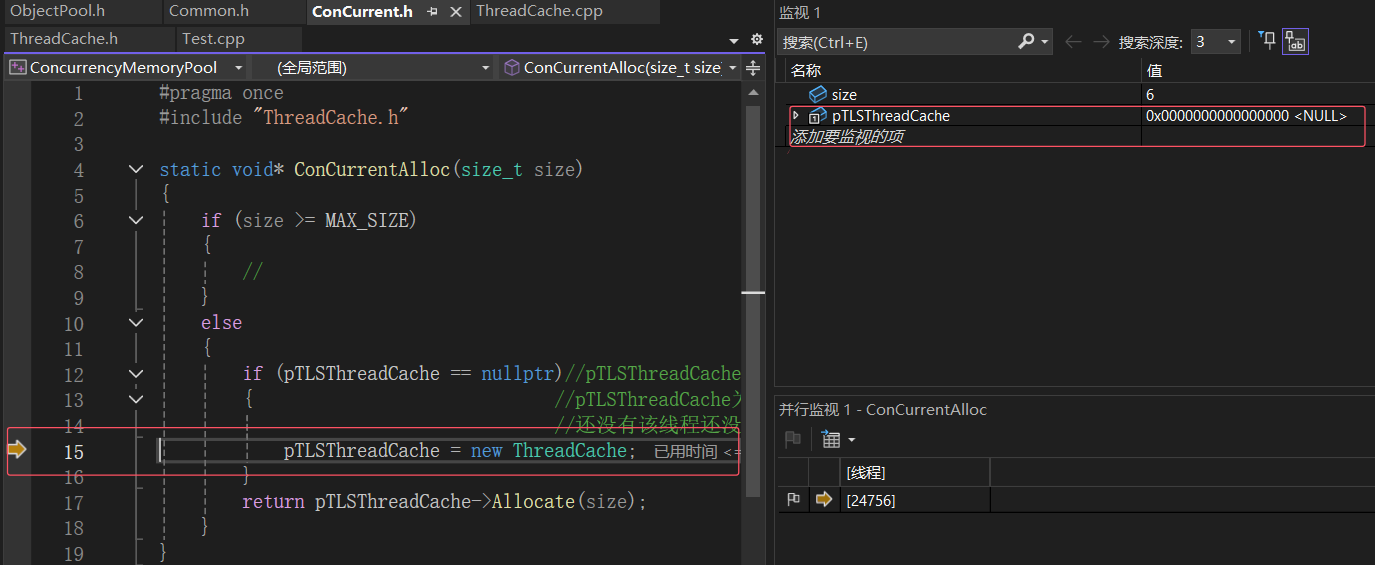
- 发现结果和我们预想的一样,线程1第一次申请空间pTLSThreadCache为空,线程1应该new一个属于自己私有的ThreadCache对象(这里的new会在基本逻辑走通之后处理细节问题时讲解,将new替换为用定长内存池创建对象)
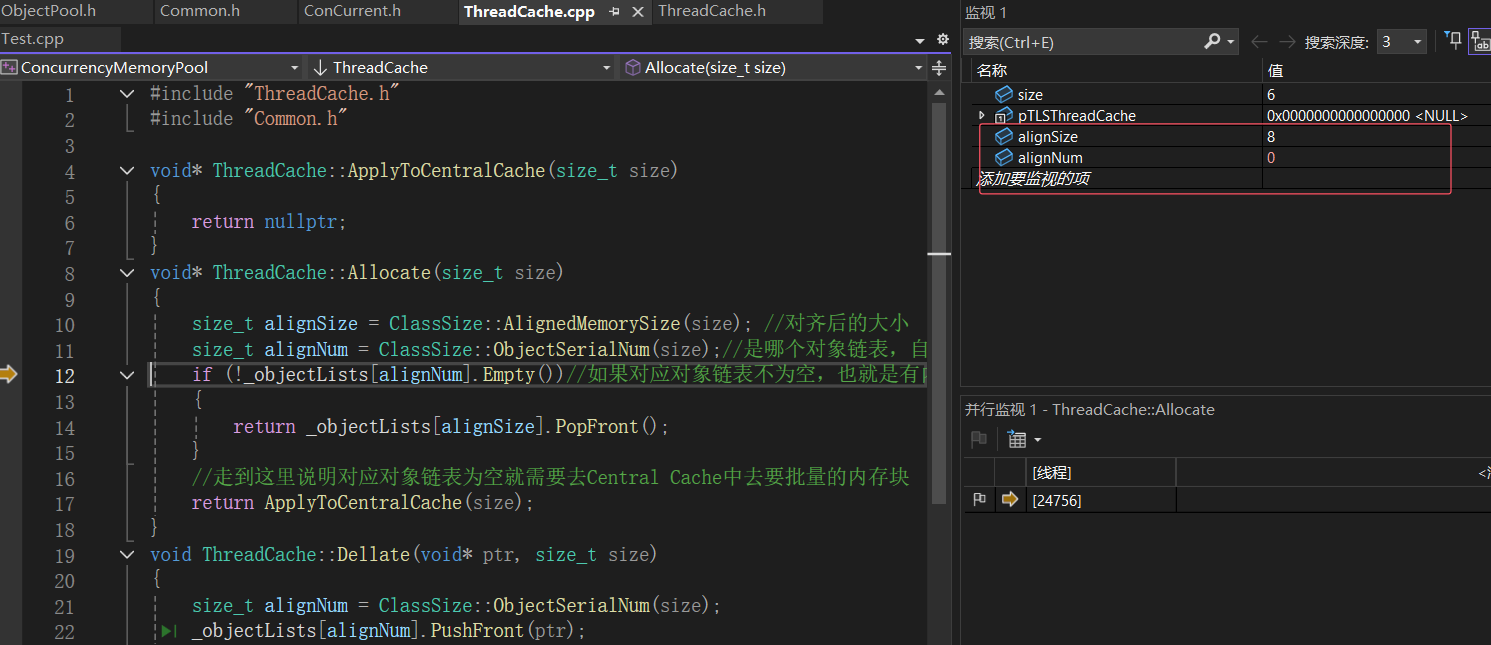
- 由于申请的是6字节大小的空间,所以对齐后的大小为8,对应到0号桶下,目前逻辑是对的
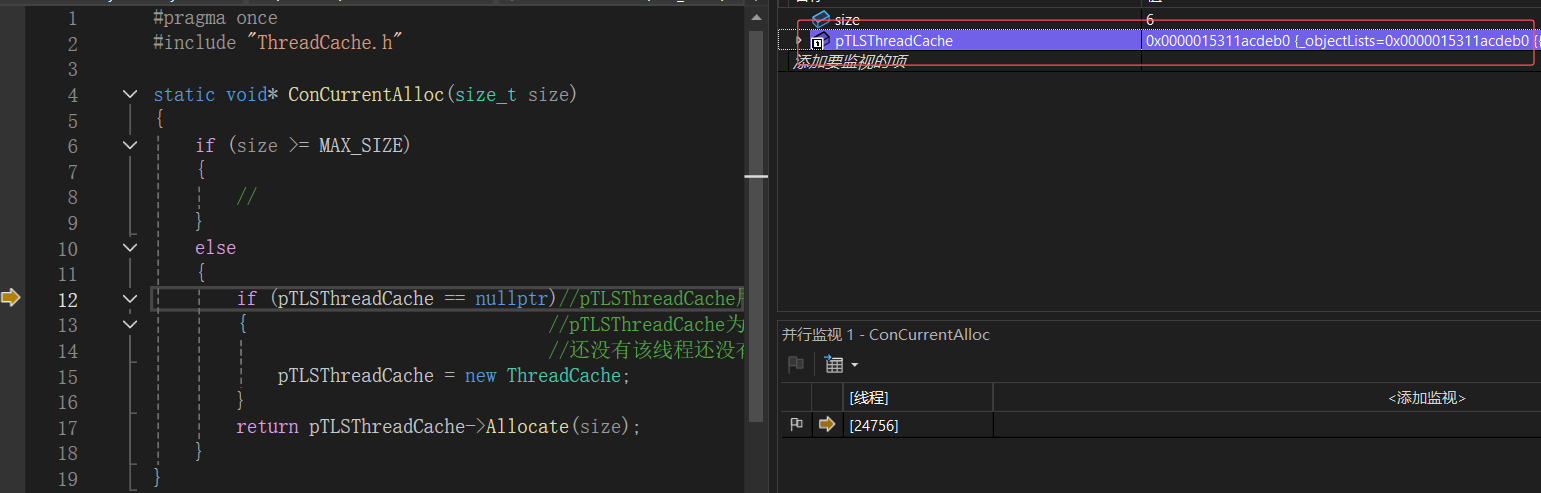
- 线程1再次申请空间线程1中的pTLSThreadCache不为空,符合逻辑
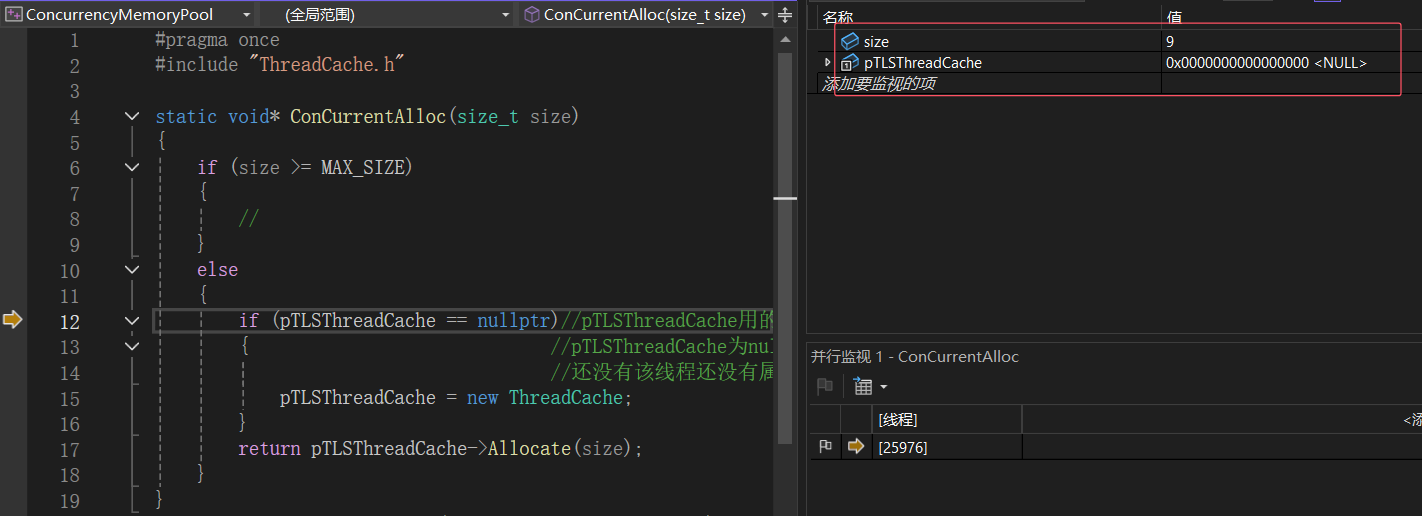
- 线程2第一次申请9个字节的空间,线程2的pTLSThreadCache为空,所以应该给线程2new个自己的ThreadCache对象
五、申请内存过程、释放内存过程、细节处理实现
5.1申请内存过程、释放内存过程、细节处理代码实现
5.1.1公共文件

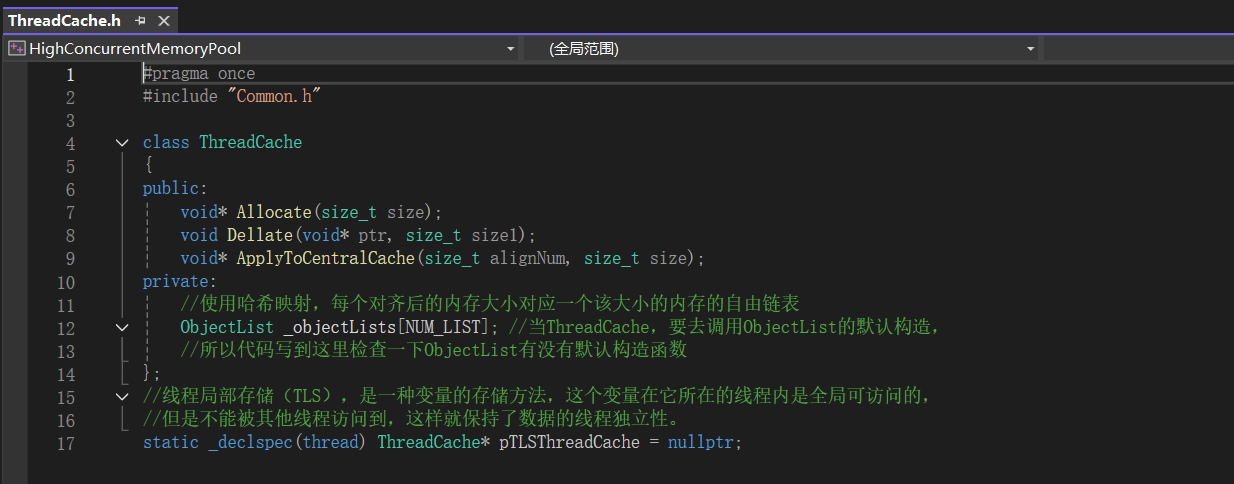
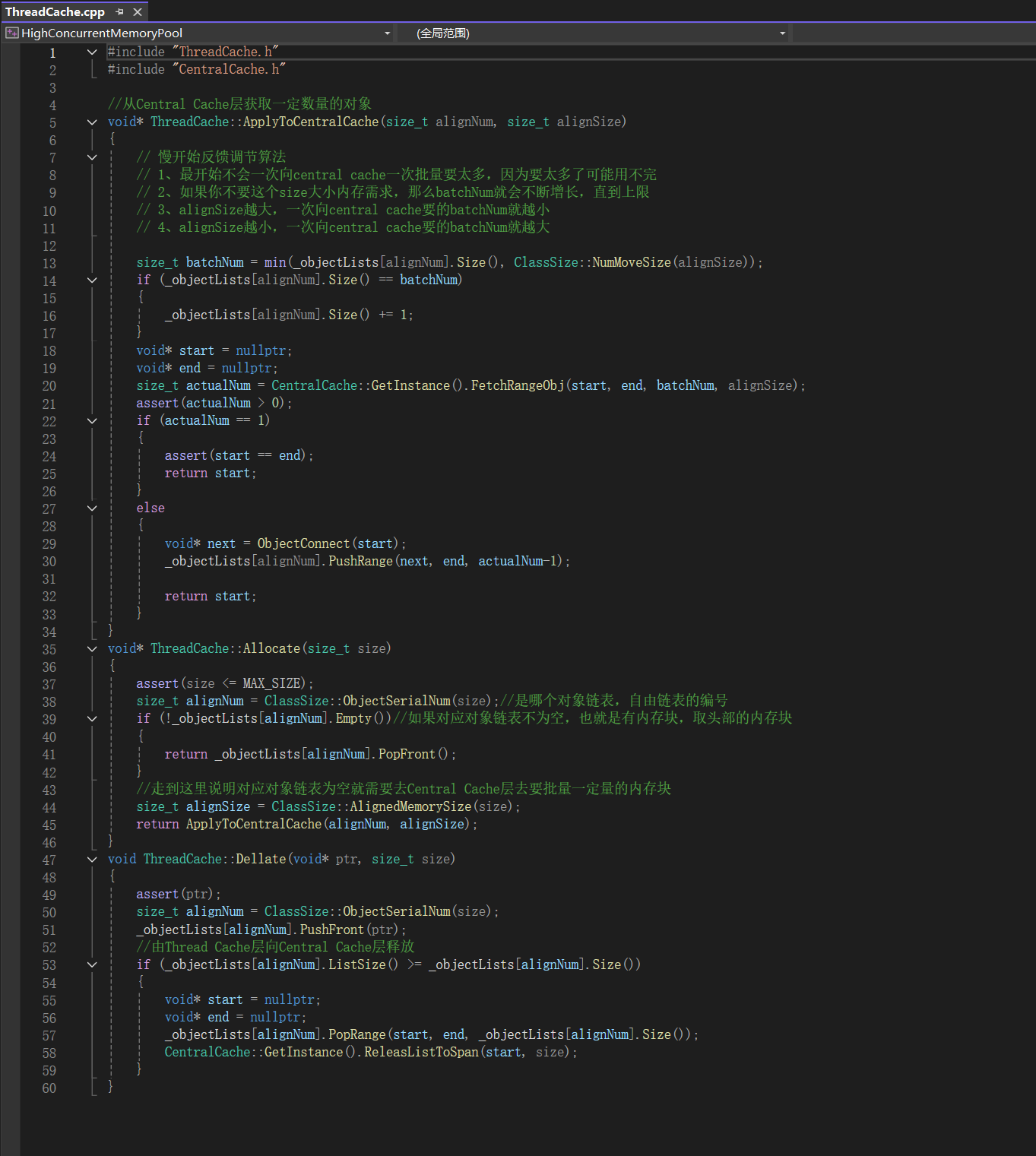
5.1.2Thread Cache层
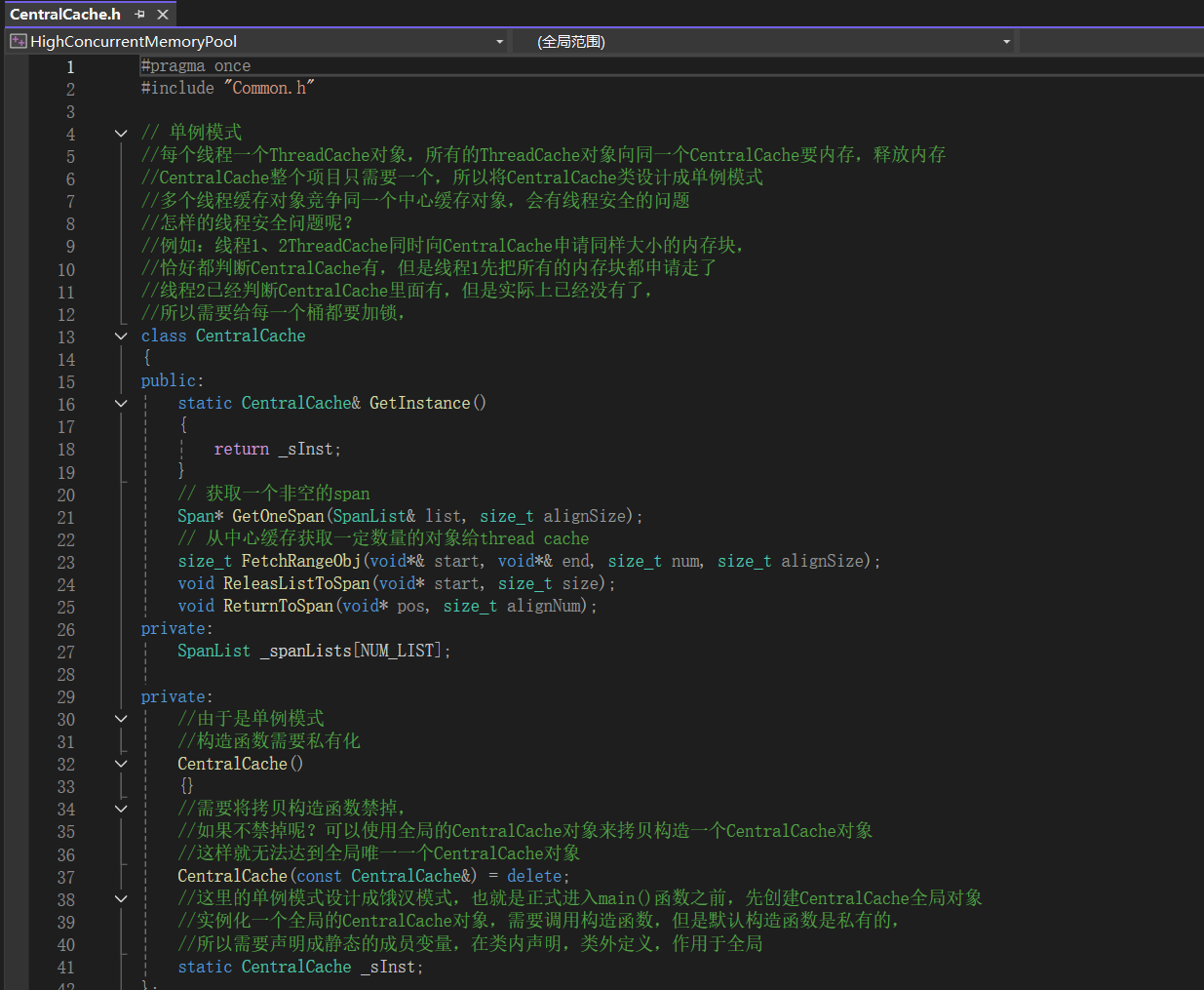
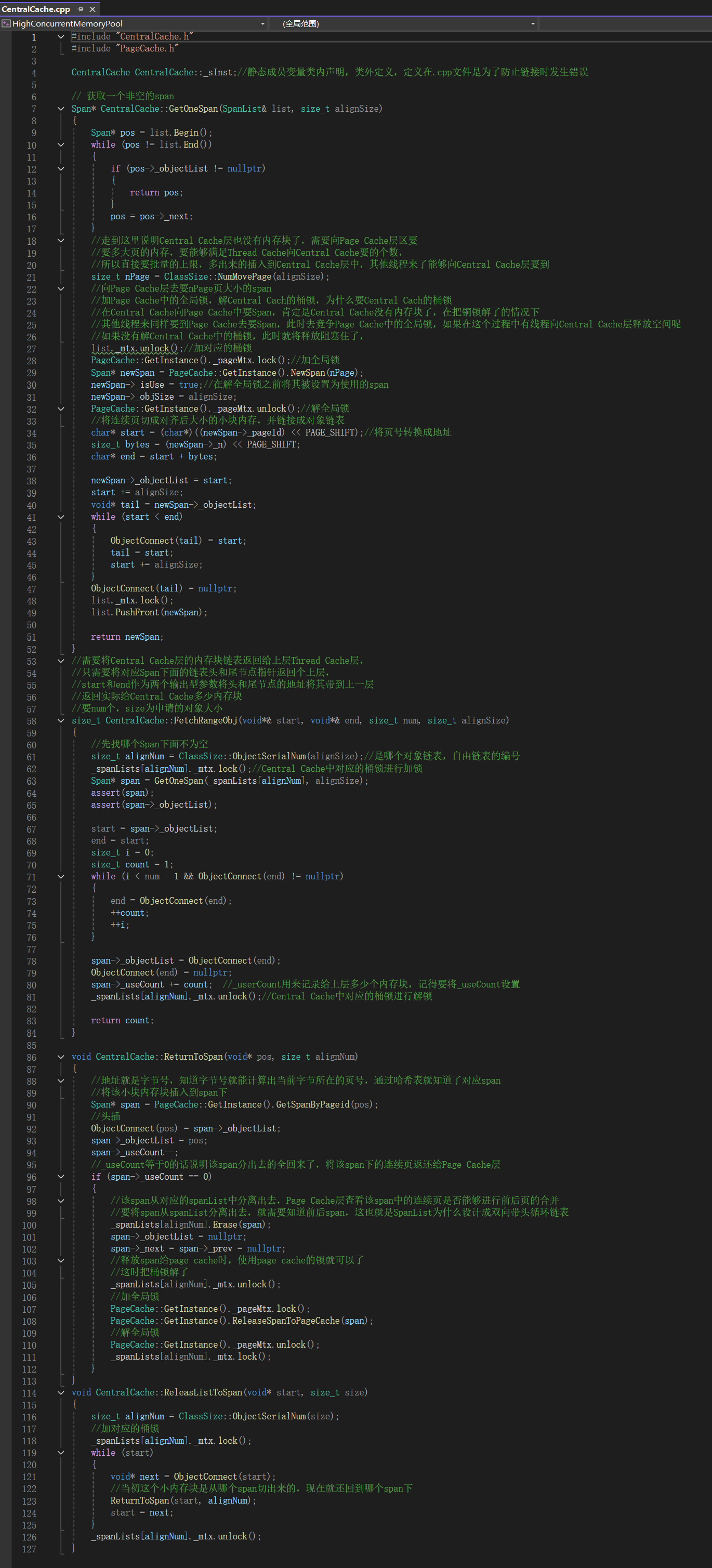
5.1.3Central Cache层
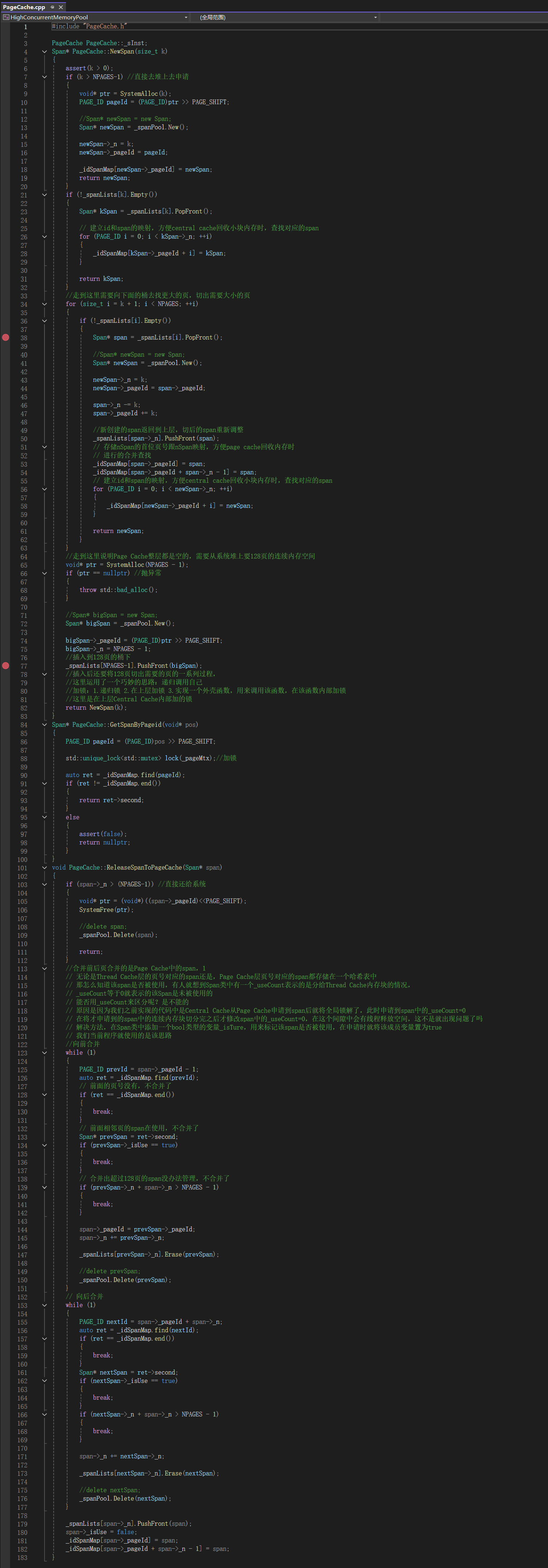
5.1.4Page Cache层
六、性能测试及其优化
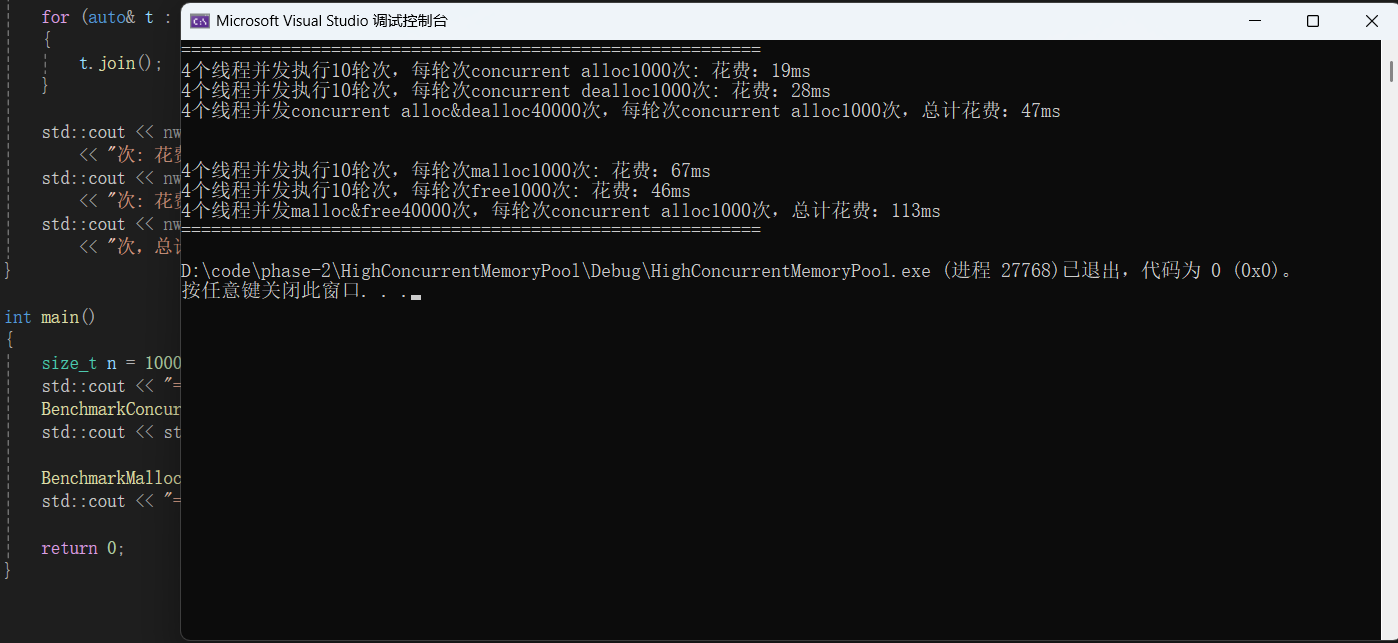
6.1多线程环境下对比malloc测试
我们当前的项目是仿照tcmalloc来实现的,tcmalloc中有很多的细节,有很多的优化,不要指望我们实现的高并发内存池性能上有多好。
性能测试代码
#include "Common.h"
#include "ConCurrent.h"
#include <stdio.h>/*
* 创建 nworks个线程,每个线程下执行rounds轮,每一轮需要申请ntimes次释放ntimes次
*/
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(malloc(16));//v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}std::cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次malloc" << ntimes<< "次: 花费:" << malloc_costtime << "ms" << std::endl;std::cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次free" << ntimes<< "次: 花费:" << free_costtime << "ms" << std::endl;std::cout << nworks << "个线程并发malloc&free" << nworks * rounds * ntimes << "次,每轮次concurrent alloc" << ntimes<< "次,总计花费:" << malloc_costtime + free_costtime << "ms" << std::endl;
}// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(ConCurrentAlloc(16));//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConCurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}std::cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次concurrent alloc" << ntimes << "次: 花费:" << malloc_costtime << "ms" << std::endl;std::cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次concurrent dealloc" << ntimes << "次: 花费:" << free_costtime << "ms" << std::endl;std::cout << nworks << "个线程并发concurrent alloc&dealloc" << nworks * rounds * ntimes << "次,每轮次concurrent alloc" << ntimes<< "次,总计花费:" << malloc_costtime + free_costtime << "ms" << std::endl;
}int main()
{size_t n = 1000;std::cout << "==========================================================" << std::endl;BenchmarkConcurrentMalloc(n, 4, 10);std::cout << std::endl << std::endl;BenchmarkMalloc(n, 4, 10);std::cout << "==========================================================" << std::endl;return 0;
}
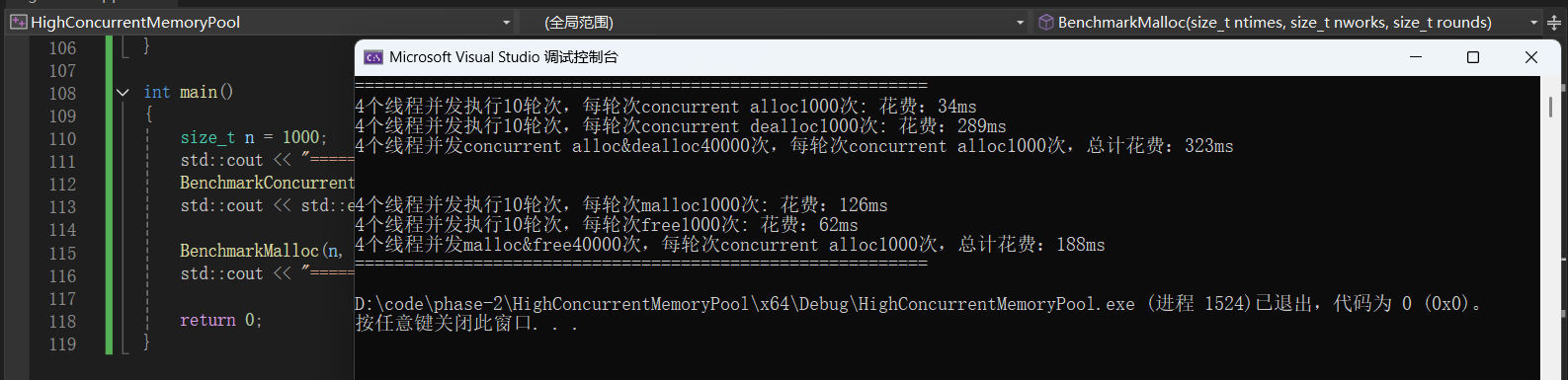
- 性能比malloc和free还要差一些
6.2性能瓶颈分析
操作步骤:
这里做性能分析主要是找到哪个函数消耗的时间长,然后针对性的进行修改。在做性能分析时要保证是在debug下,并把向malloc申请内存的部分注释掉。然后做如下操作:
右键项目打开属性,然后做如下配置:
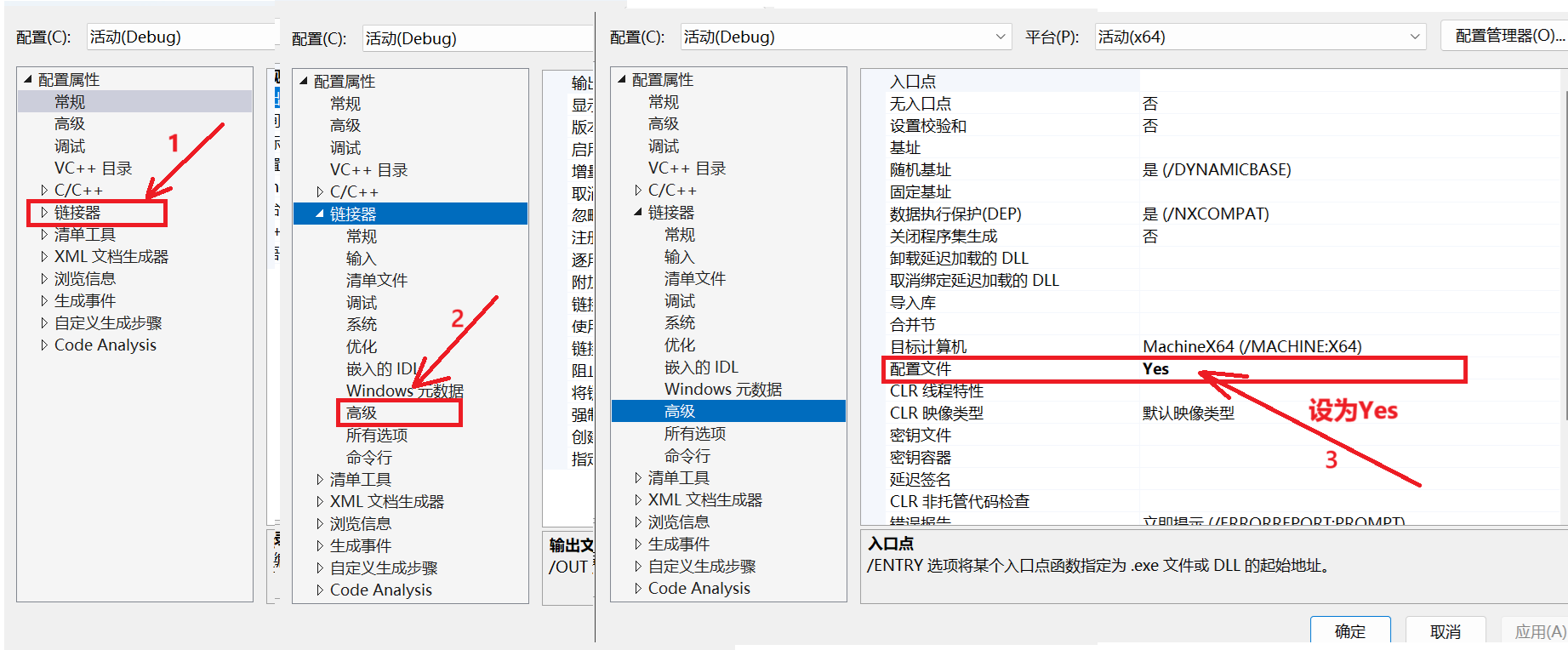
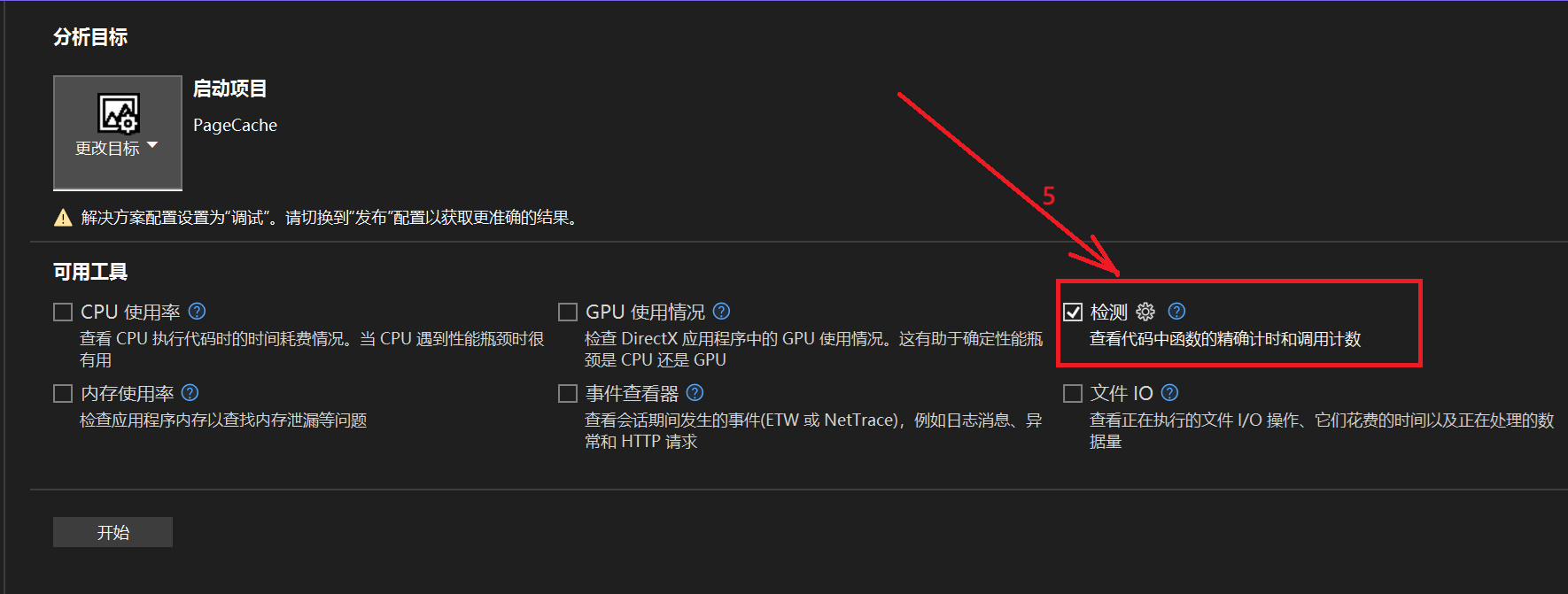
打开调试性能探查器
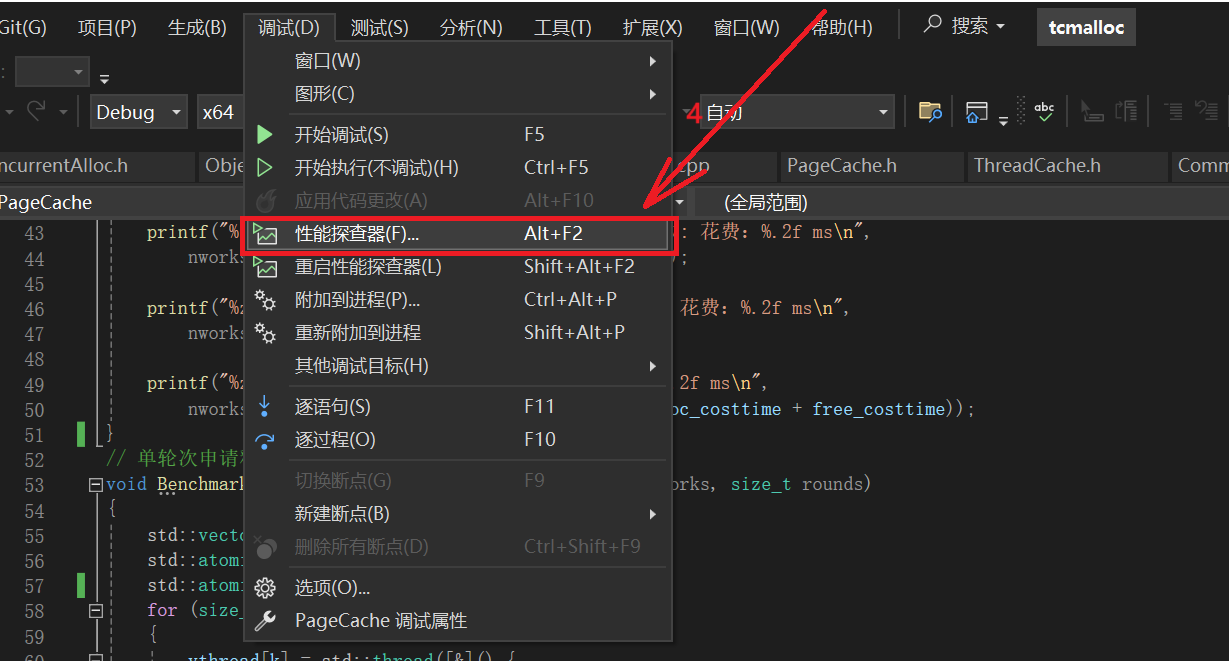
打开检测
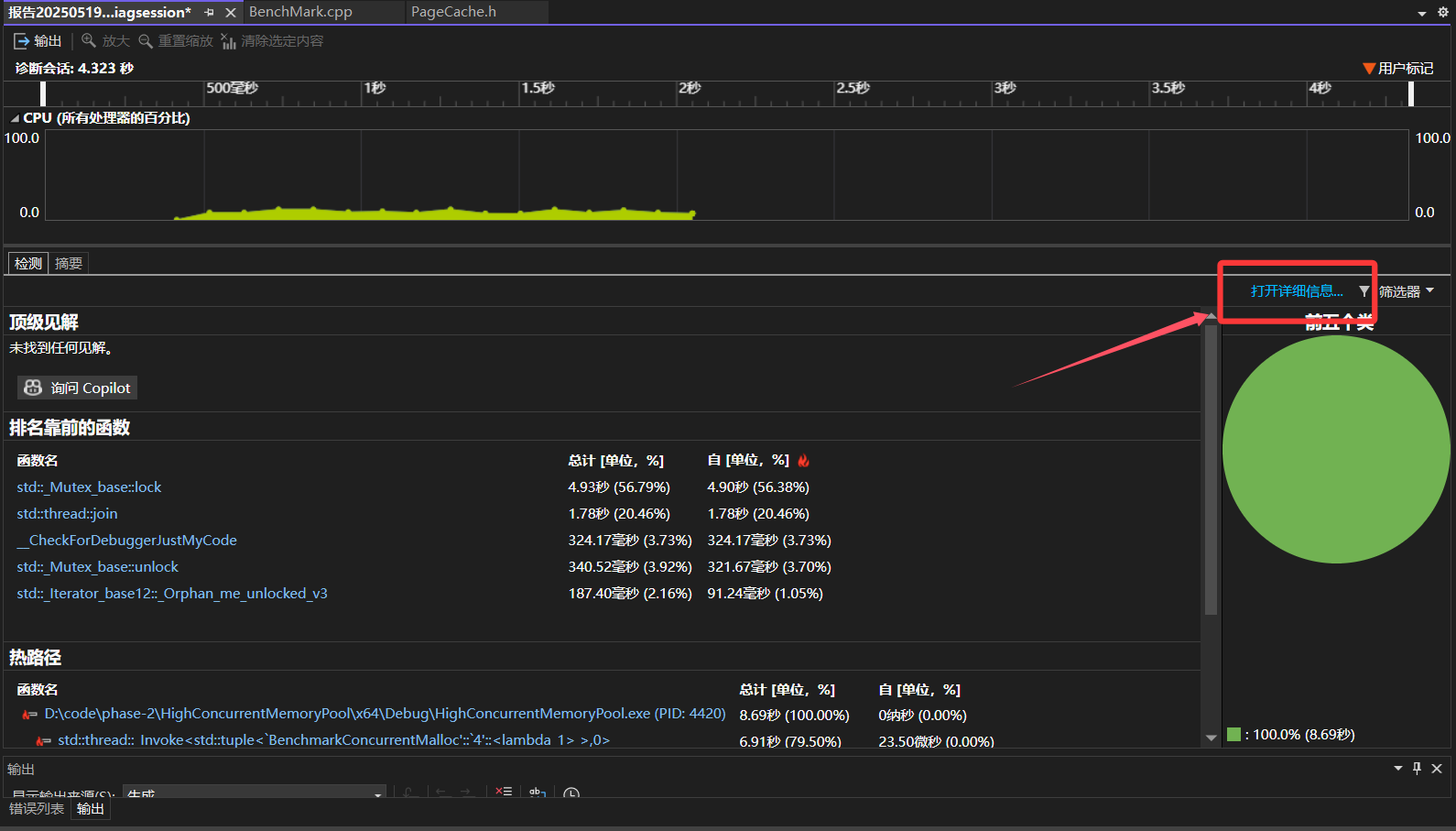
打开详细信息
打开火焰图
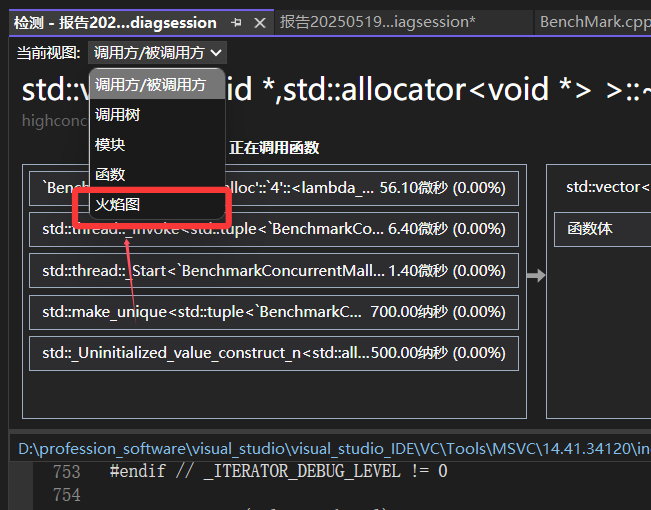
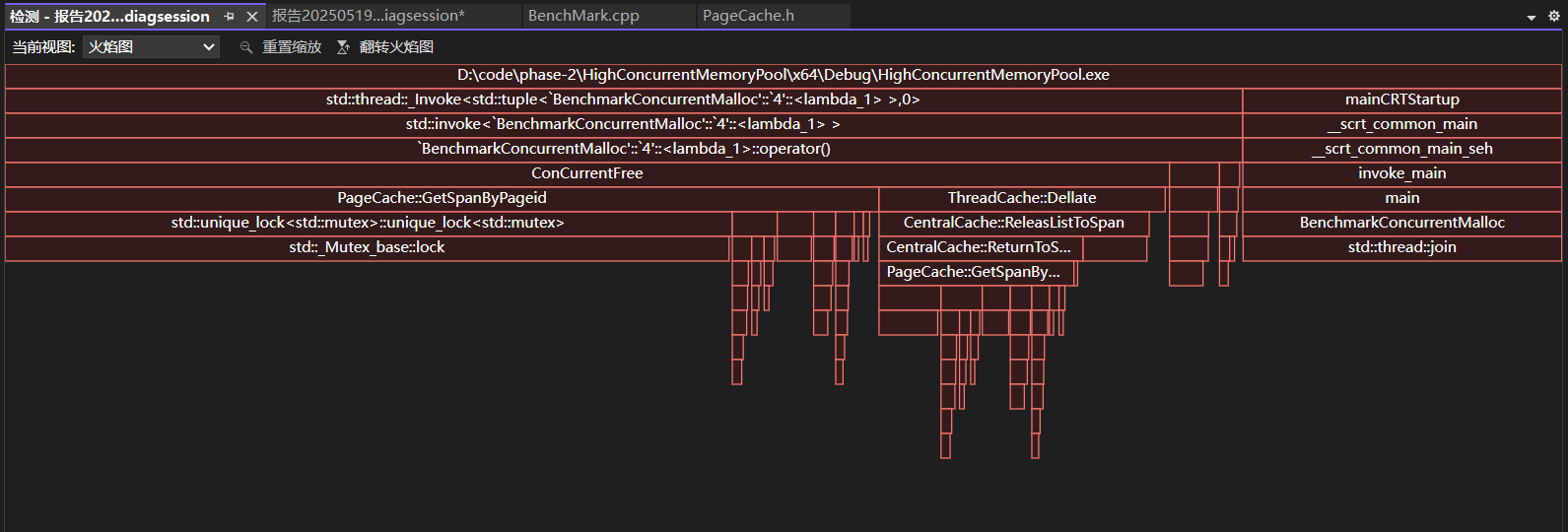
我们可以观察到有很大的消耗来自于GetSpanByPageid(void* pos)函数,原因是因为内部需要加锁、解锁,STL中的unordered_map查找有些慢。
怎么优化呢?
调用GetSpanByPageid(void* pos)函数不需要加锁和解锁,不使用STL中的unordered_map,将其替换成使用基数树。
6.3针对性能瓶颈使用基数树进行优化
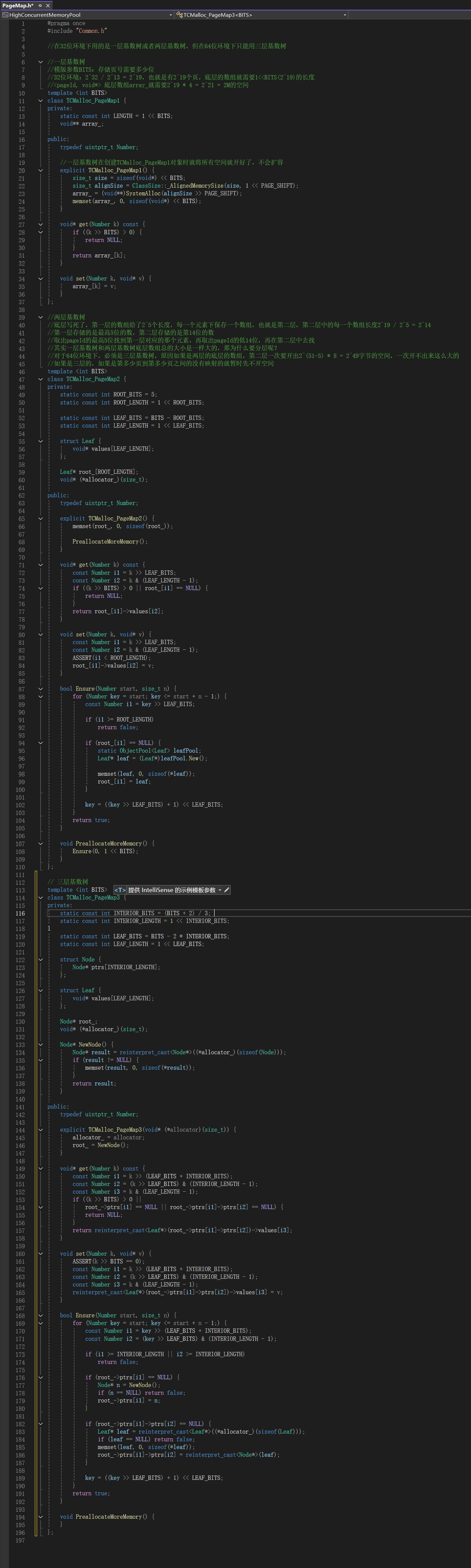
调整后代码
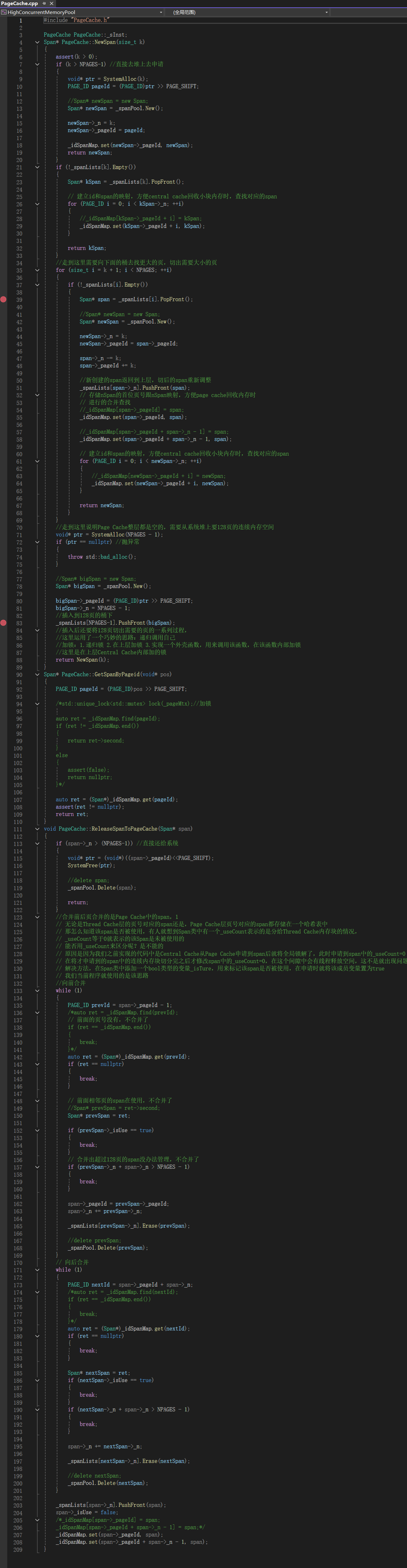
为什么读取基数树映射关系时不需要加锁?
当某个线程在读取映射关系时,可能另外一个线程正在建立其他页号的映射关系,而此时无论我们用的是C++当中的map还是unordered_map,在读取映射关系时都是需要加锁的。
因为C++中map的底层数据结构是红黑树,unordered_map的底层数据结构是哈希表,而无论是红黑树还是哈希表,当我们在插入数据时其底层的结构都有可能会发生变化。比如红黑树在插入数据时可能会引起树的旋转,而哈希表在插入数据时可能会引起哈希表扩容。此时要避免出现数据不一致的问题,就不能让插入操作和读取操作同时进行,因此我们在读取映射关系的时候是需要加锁的。
而对于基数树来说就不一样了,基数树的空间一旦开辟好了就不会发生变化,因此无论什么时候去读取某个页的映射,都是对应在一个固定的位置进行读取的。并且我们不会同时对同一个页进行读取映射和建立映射的操作,因为我们只有在释放对象时才需要读取映射,而建立映射的操作都是在page cache进行的。也就是说,读取映射时读取的都是对应span的_useCount不等于0的页,而建立映射时建立的都是对应span的_useCount等于0的页,所以说我们不会同时对同一个页进行读取映射和建立映射的操作。
再次对比malloc进行测试
还是同样的代码,只不过我们用基数树对代码进行了优化,这时测试内存的申请和释放的结果如下: