数据结构(3)线性表-链表-单链表
我们学习过顺序表时,一旦对头部或中间的数据进行处理,由于物理结构的连续性,为了不覆盖,都得移,就导致时间复杂度为O(n),还有一个潜在的问题就是扩容,假如我们扩容前是100个大小的元素空间,一旦扩容以后(我们就说二倍的扩),那就是200,但我们实际上就只存105个元素,那不就有95个元素所对应的空间被浪费了吗?怎样才能解决这样的问题呢?
带着疑问,来学习线性表的其中之一,链表。
一、链表
链表是物理存储结构上非连续的线性表,数据元素的逻辑顺序是通过链表中的指针来实现的。
按照指针方向链表分为单向链表,双向列表和循环链表。
按内存管理的话还是静态链表和动态链表
二、单链表
本次就进行单链表的学习。
1.单链表概述
单链表一般作Single List
单链表是什么东西呢?
单链表就好像是火车一样,火车的每个单位是车厢,车头是动力,车厢与车厢之间存在有结构连接。
为什么要这么对比呢?
单链表的基本单位就是结点,结点与结点之间由指针连接起来,这是静态的看;火车在淡旺季可以选择加车厢和减车厢,而我们的单链表对应的操作就是增加或者删除结点。
单链表属于链表,根据指针的方向取名单链表,单链表结点间的指针方向是只有一个的。

我们在申请顺序表的大小的时候用的是realloc,第一个参数是需要修改的内存的地址,第二个参数是改为的内存空间的大小,这个内存空间我们申请的时候直接是一整块全部申请下来,但是对于单链表则不同,如上面画的图,我们每次申请都仅仅申请一个结点,任意取出来逻辑上相邻的两个结点:
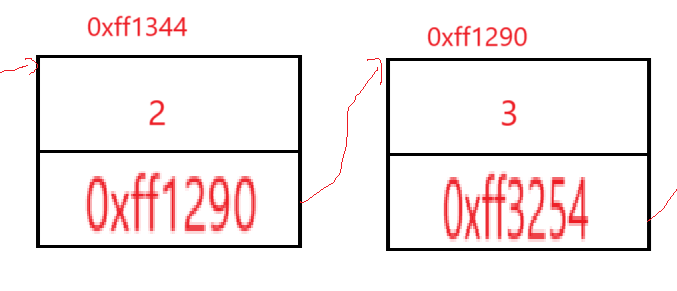
现在视角落在存储了整型2的这个结点上,这个结点存储了两个东西,一个是数据,一个是下一个结点的地址,由此我们的单链表的结点就是一个结构体变量,一个是存储的数据,一个是结点结构体类型的指针(因为通过这个指针访问下一个结点时,还是一个结点结构体,所以必须是结点结构体类型的指针变量)。
2.链表的性质
由这个简略图给出链表的通用特性:
①链表在逻辑上是连续的,物理空间上不一定连续
②结点一般是在堆上申请的
③从堆上申请的空间不一定连续
了解即可。
3.单链表结点结构的创建
非常清晰了,直接给出来:
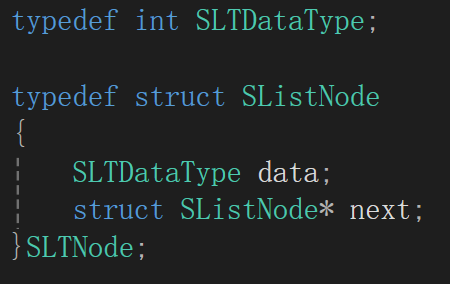
为了单链表存储数据类型的可修改性,一个typedef,为了后续与结点这个结构体操作的简便性,再来一个typedef,这点在顺序表中已经见过了,不多解释。
不管是先前的图片还是后续的创建,都展示出了结点的两个属性,一般存放数据的被称作数据域,存放下一个结点地址的叫做指针域。
4.单链表的打印
有了单链表的结点,如果要实现我们所画的图片的效果应该是这样的:
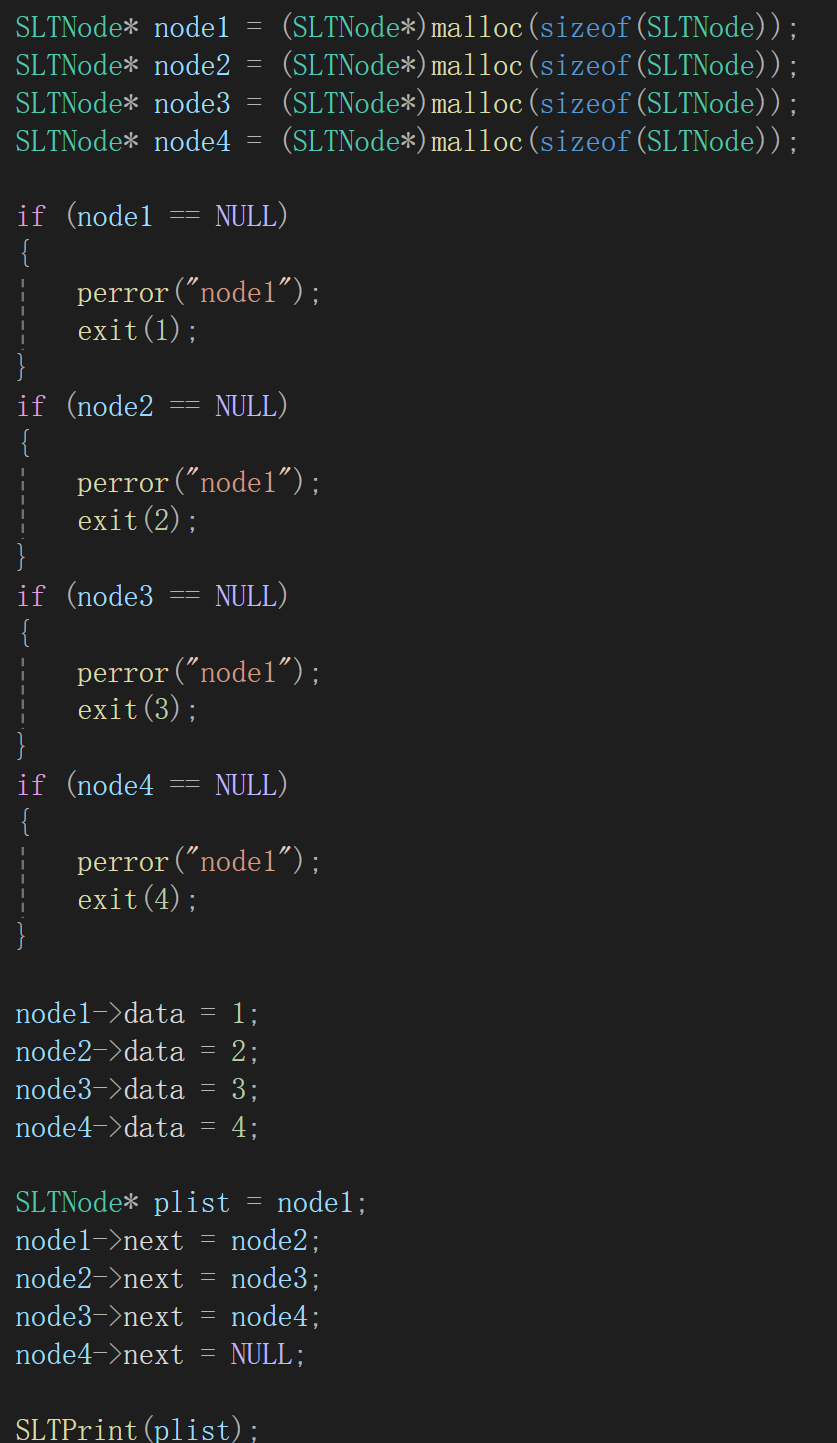
为每一个结点创建内存空间,并且赋值,实际上发现,我们逻辑上的1,2,3,4是通过指针来实现的。
如果对于这样的一个链表,我们该如何实现遍历打印呢?
通过plist开始访问链表的数据,进去打印该结点的数据,并且将指针该为下一个结点的地址,最终下一个结点的next指针为空则遍历完成。

进去就打印,并且跳到下一个链表结点里,如果不为空则继续打印,为空说明已经遍历到尾,可以停止。
当然,其实可以把assert换一下,因为如果链表为空,直接打印个NULL,也可以:

5.单链表的插入结点操作
①单链表的尾插
先想尾插的参数,肯定得把单链表的地址传过去吧,然后你插什么总得告诉我吧。
所以就俩参数,一个是单链表的地址(如上面的plist),还有想要插入的元素是什么。
进去第一件事可不是去插入,就像顺序表插入一样,你总得看看有没有地方让你插入吧,类比过来,就得先生成个结点,这个结点专门用来存放本次插入的值,指针的话由于尾插,所以肯定是NULL。
有了这个结点以后就得把它像连接火车车厢一样接上去,很显然,需要先找到链表尾,其实我们打印的时候用的while循环结束后,指针已经到了单链表的尾了,所以拿过来即可,找到尾以后把原来的尾的指针从NULL变成新创建的结点的地址即可。
思路有了,代码表达:

逢开辟必检查。
而链表的插入分为空链表的尾插和非空链表的尾插,至于为什么,先往下看:
非空:
拿着链表地址,遍历到最后,把创建的新结点地址赋给尾结点即可。
但是如果是空链表呢:
你非空确实传过来地址,我顺着地址修改值就行,但是如果是空的链表呢?你传过来的是什么,是NULL,那你再修改,对实际的链表根本就是无济于事啊。所以为了对真正的链表的里面的值进行修改,我们不能传值了,只能传过来这个空链表的指针的地址(为了通过这个地址去修改这个指针)
地址的地址,或者说一级指针的地址应该用二级指针来承接,所以形参写的时候应该是二级指针,修改为:
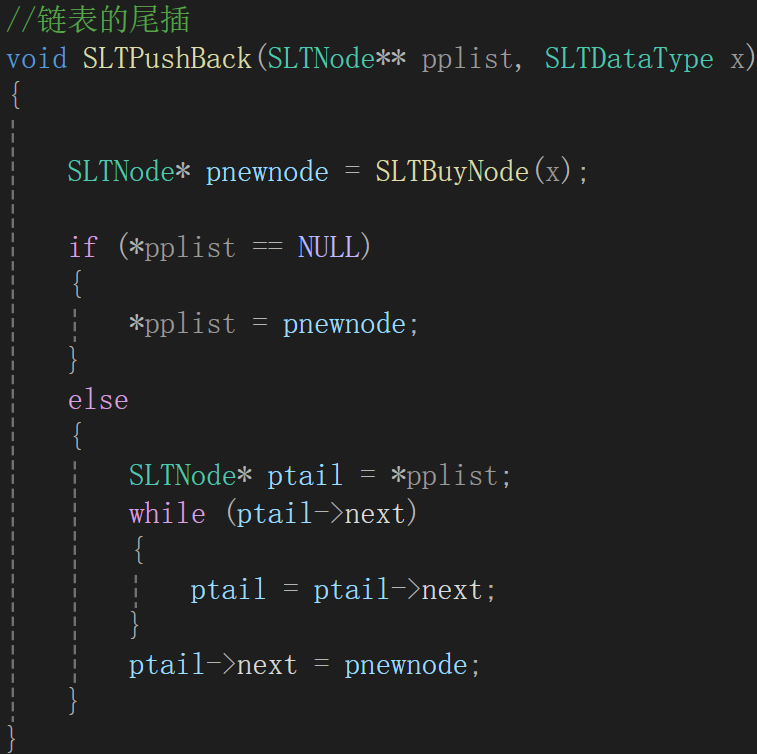
其中,链表不为空需要遍历到链表尾部的地址,因为后续需要用这个地址去修改NULL,这样的话到尾结点就该停,而尾结点与其他结点的不同就是下一个结点的地址为空。
测试代码如下:
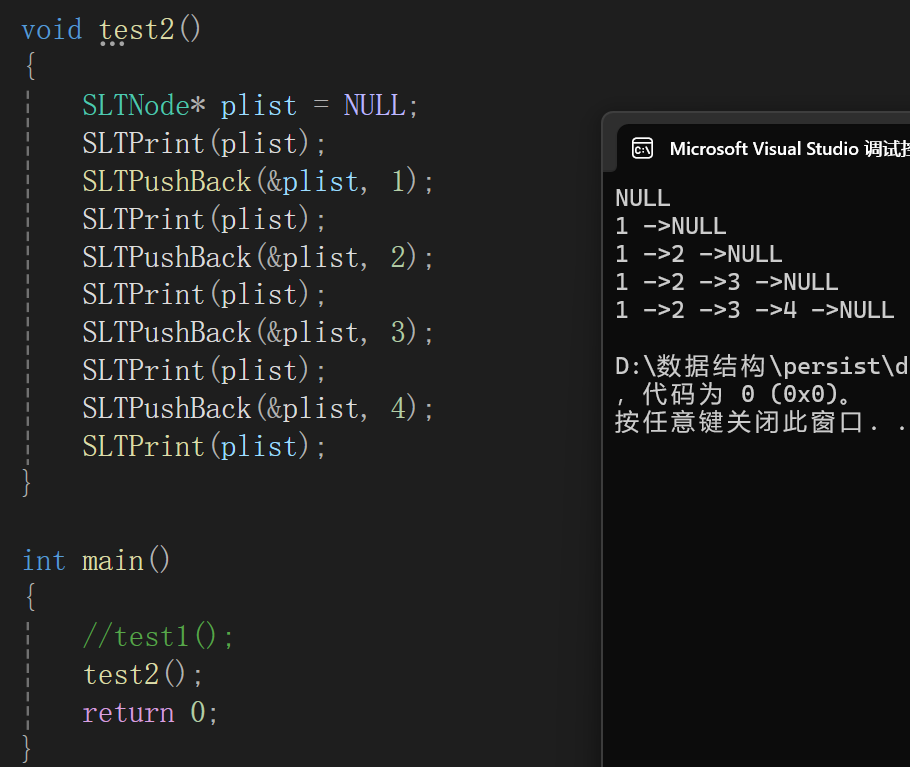
说明确实插入了。
当然,还得防范一下传过来的指针,毕竟plist可以为空(即链表为空),但是pplist存的可是链表的地址的啊,这玩意为空算哪门子事:
加个assert防范一下。
②单链表的头插
还是有了经验以后,参数还是pplist,并且分开链表为空和链表不为空的情况:
首先还是不为空:
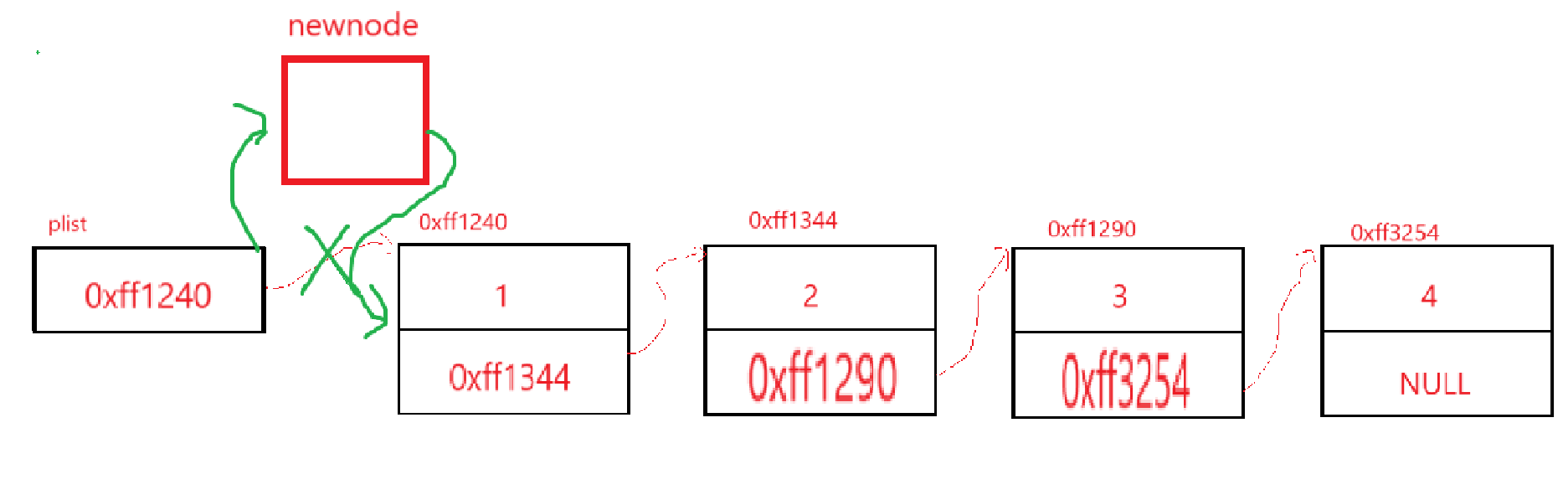
让plist指向我们的newnode,newnode指向我们的第一个结点,这样的话赋值就得先把plist的值赋给newnod->next了,然后再把plist的值修改了:

而且发现,如果链表为空,plist为NULL,赋过去,newnode地址给plist,也没毛病。
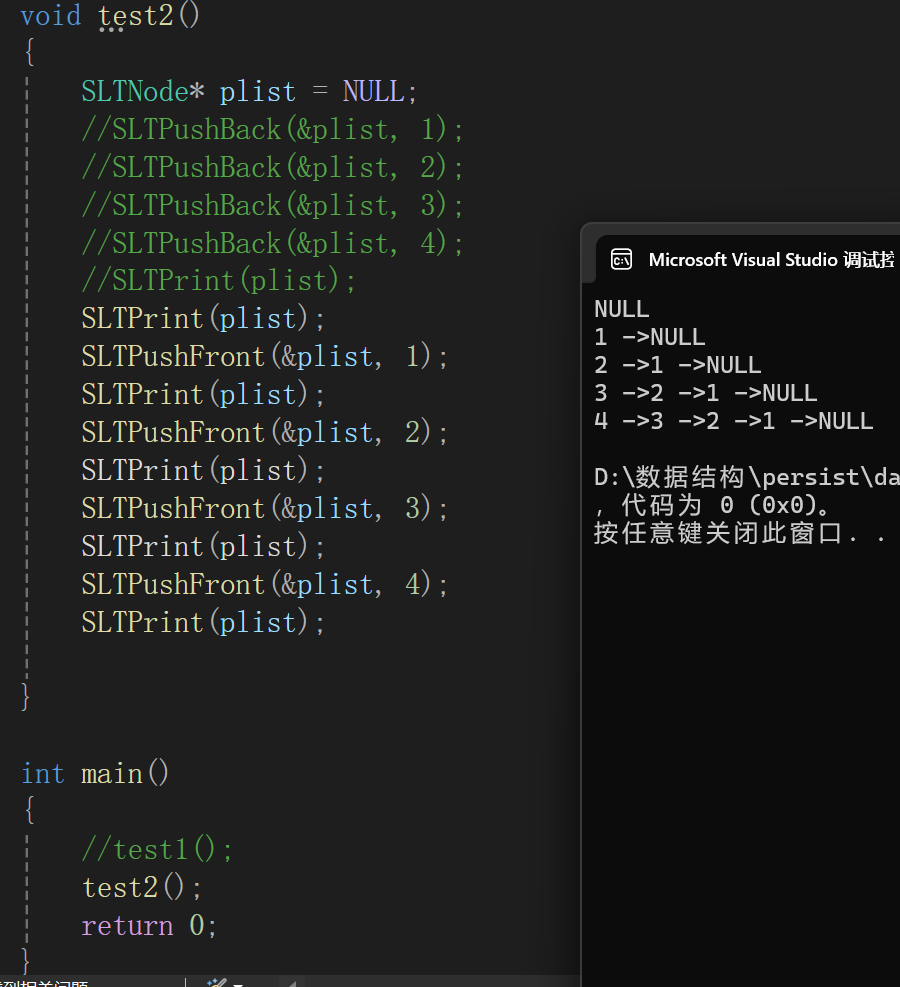
调试完毕,没啥问题
6.单链表的删除结点操作
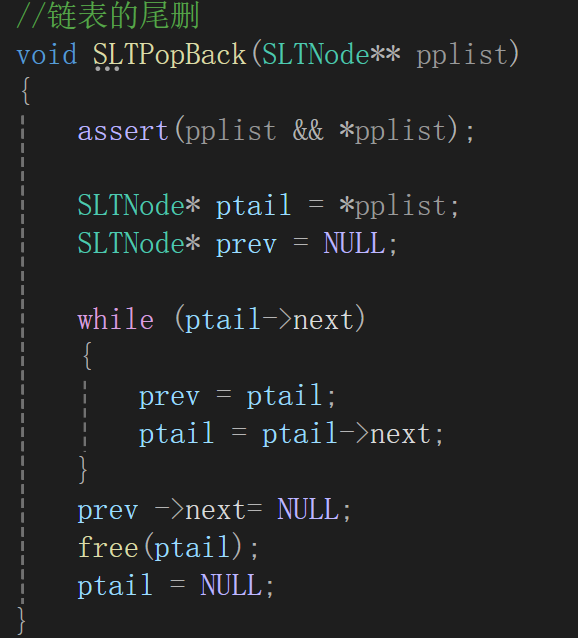
①单链表的尾删
 释放最后一块空间,并将尾结点的前一个结点的next指针改成NULL。
释放最后一块空间,并将尾结点的前一个结点的next指针改成NULL。
这就要求你必须找到两个位置的指针,一个是ptail,一个是ptail前的prev,我们以这样的思路来想办法遍历,示意图:
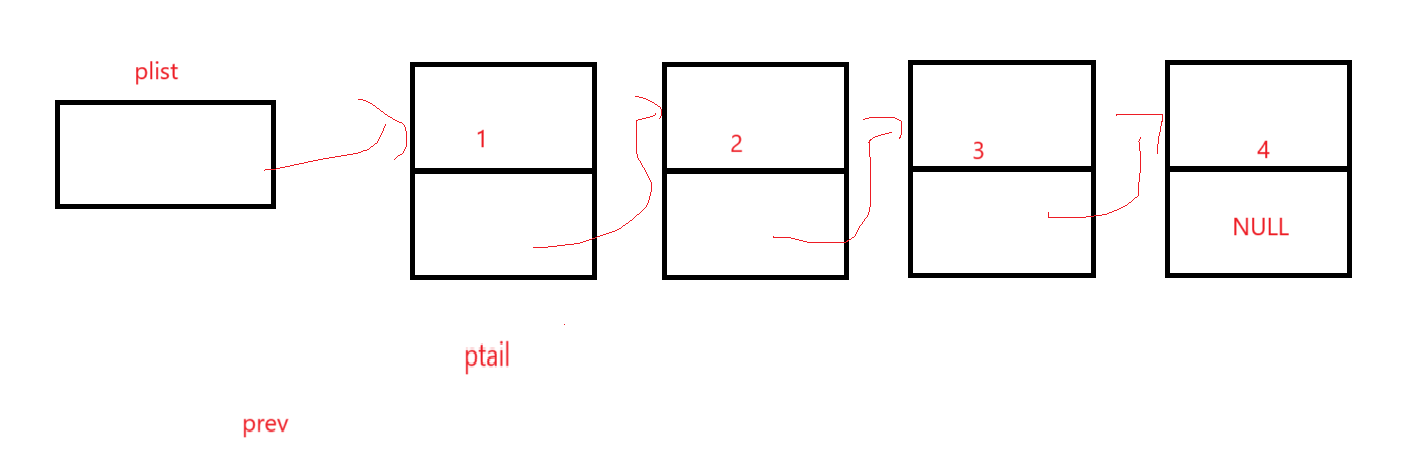
ptail开始指向第一个元素,prev由于必须在ptail前,此时应该为空;
进入检测以后看看这个结点是不是尾结点,是的话就该停止遍历了,即判断条件为ptail->next != NULL。
问题就在于循环体如何实现ptail往后走的同时来让prev在ptail前,很简单,可以说是keep up with:

如果不是尾结点的话,prev先站到现在ptail的位置,因为下一步就是后移,这样出了循环就是一个在前一个在后的效果,如:
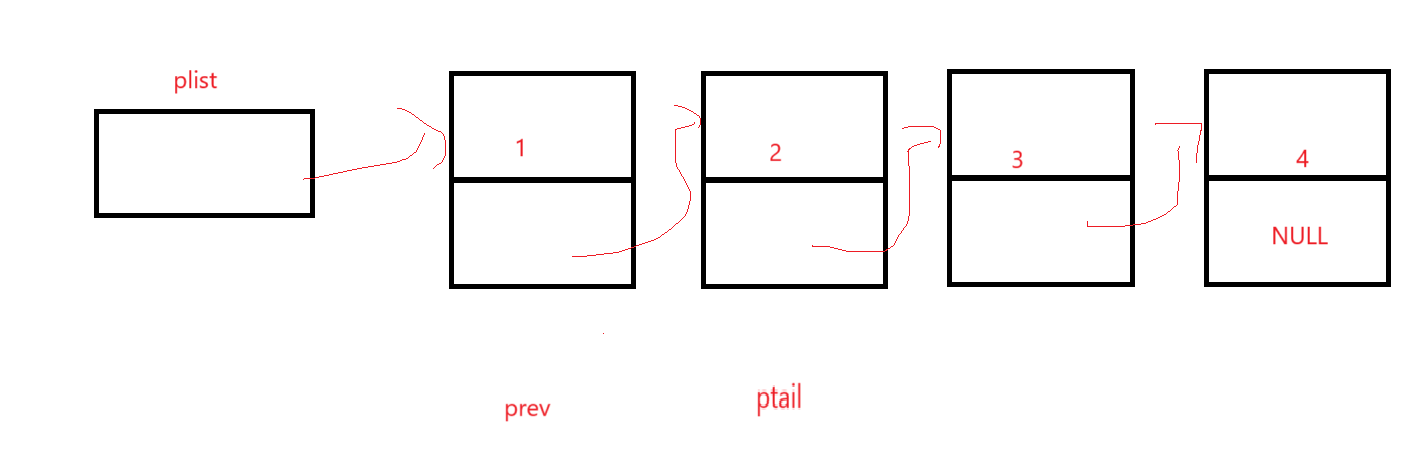
当然不能忘了释放空间和防范野指针:
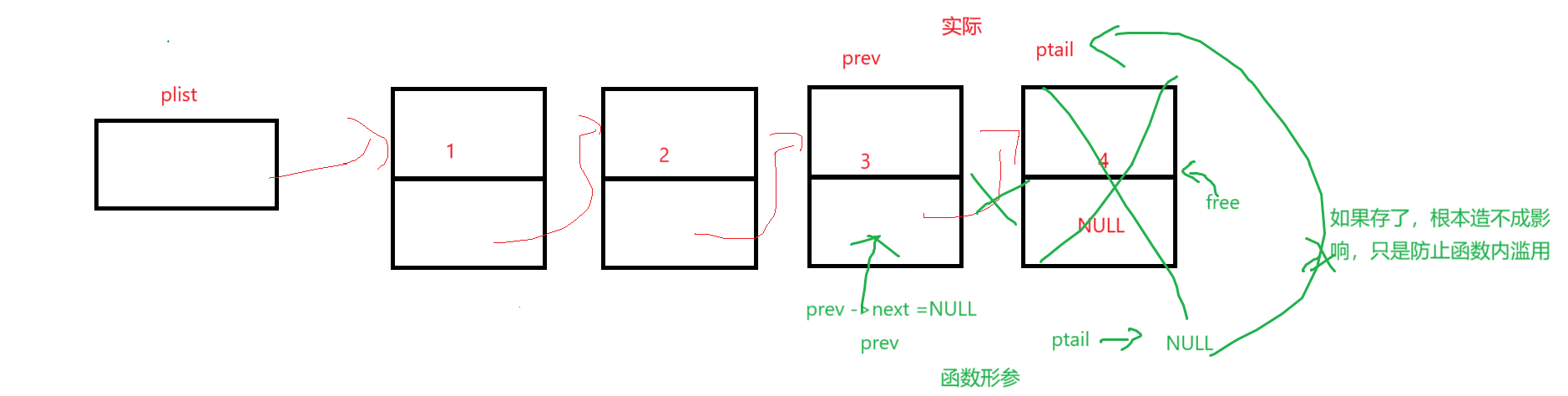
最后三条解释一下,prev->next = NULL确实是修改了链表的实际结构,因为prev是尾结点前那个结点的地址,顺着地址肯定能修改成功实际的链表;有了尾结点地址,free不用多解释;重点在于ptail = NULL,它可不是真的把尾结点指针置空了,或者说它即使置空也不影响实际链表中的地址还存在(如果存了的话),只是free以后习惯置空,作用是防止在函数内部再被调用。
画图解释:
正如我们插入操作的时候需要防范链表是不是空链表一样,对应过来就是,我们删除的恰好就是唯一的一个结点,即第一个结点,代码思路还行不行得通: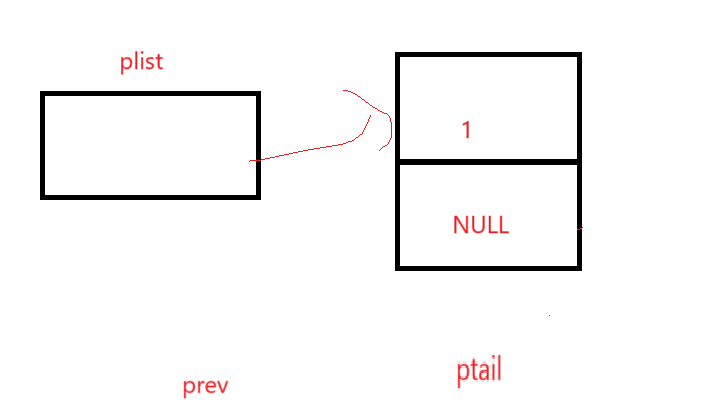
就盯着这个看,很明显,上来就是NULL,这么一搞,prev直接就是随机值。
所以如果只有一个结点的话,直接free并且赋plist为空即可(当然,在函数里是*pplist)。
完善:
测试:
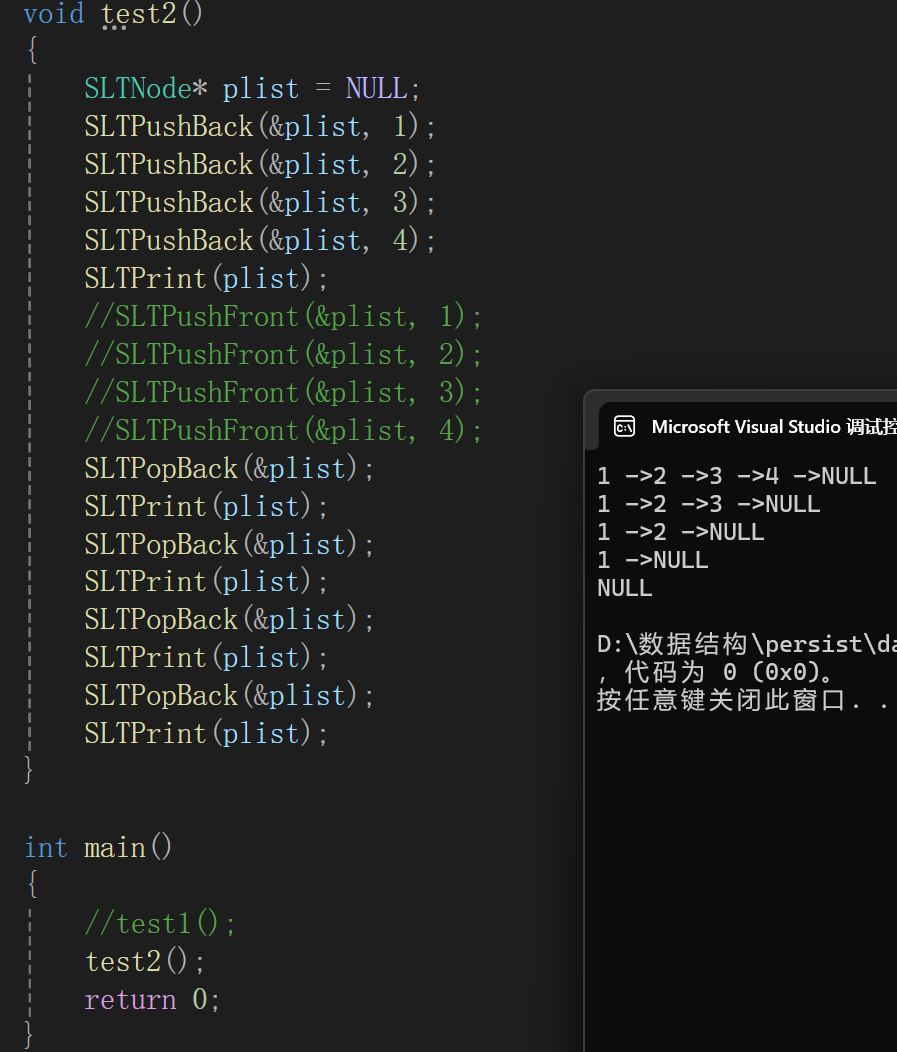
两端代码都成功。
②单链表的头删
头删其实没什么可多说的,把plist修改为原plist->next,再对原plist的空间释放即可:

测试代码:
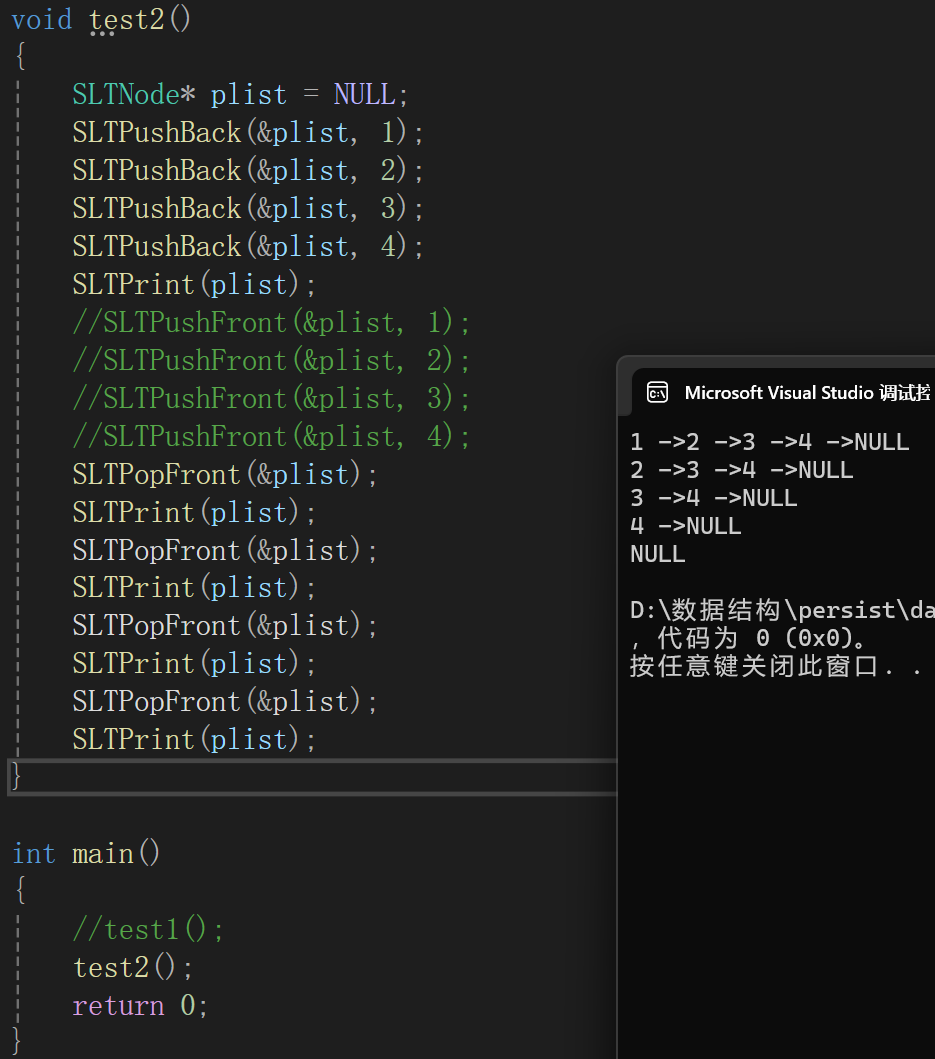
没啥好讲的,连图都不用画,空想一下就能想出来。
7.单链表的查找操作
参数:你想查哪个链表,地址给我,你想查链表里哪个元素,元素也给我,所以就俩参数,而且不会对链表的结构产生改变,传值即;上面都没说返回值的事,因为不管是打印还是对链表结构的改变,不需要返回什么,但是查找,你找到了给我个地址让我知道啊,找不到你总得告诉我找不到吧。
查找我写了两个版本:
第一个版本是这样的:
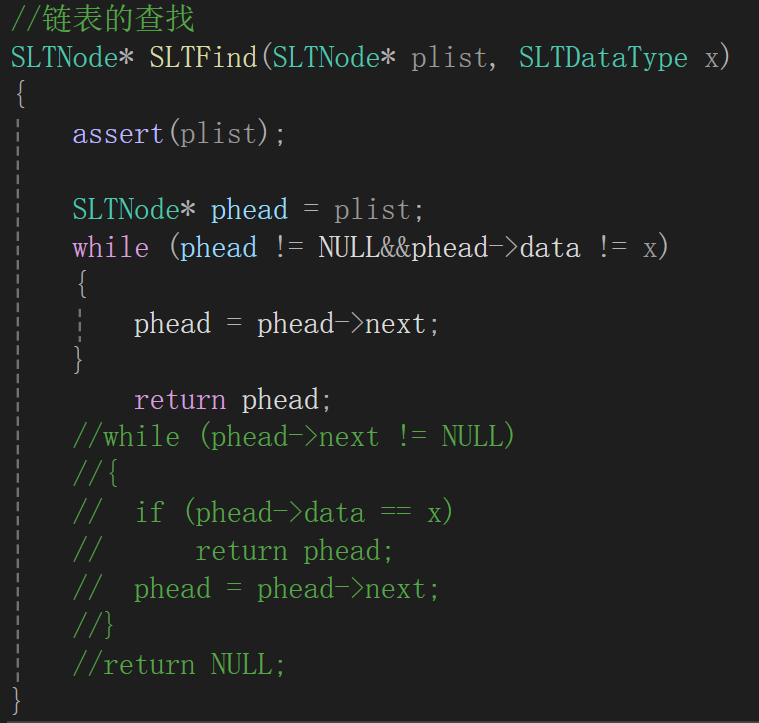
最开始实际上我写的是:
while (phead->data != x)
{
phead = phead->next;
}if(phead == NULL)
return NULL;
else
return phead;
思路就是,要是这个结点的值不是我要的值,就往死里给我遍历,跳出循环以后有俩情况,一个就是为空了都,那说明找完都没找到,直接返回NULL就行;一个就是找到了,跳出循环即可。
问题有俩,一个是遍历到尾了,phead就是NULL,再解引用去判断data与x相等不相等就不礼貌了,再来就是其实我写的if-else语句其实就是return phead的意思,(我刚开始就意识到了if-else的化简,丝毫没有发现第一个问题,最后代码报错检查了检查才发现)
第一次检查修改为:
while (phead->data != x)
{
phead = phead->next;
}return phead;
然后发现空指针解引用问题:
while (phead->data != x && phead != NULL)
{
phead = phead->next;
}return phead;
加上了还给我整事,后来想了想,这就是当时学逻辑运算符的短路问题,如果遍历完都找不到你先解引用才去检验是不是空,这样代码当然还是会报错,所以还得:
while (phead != NULL && phead->data != x)
{
phead = phead->next;
}return phead;
才没毛病。
第二个版本是这样的:
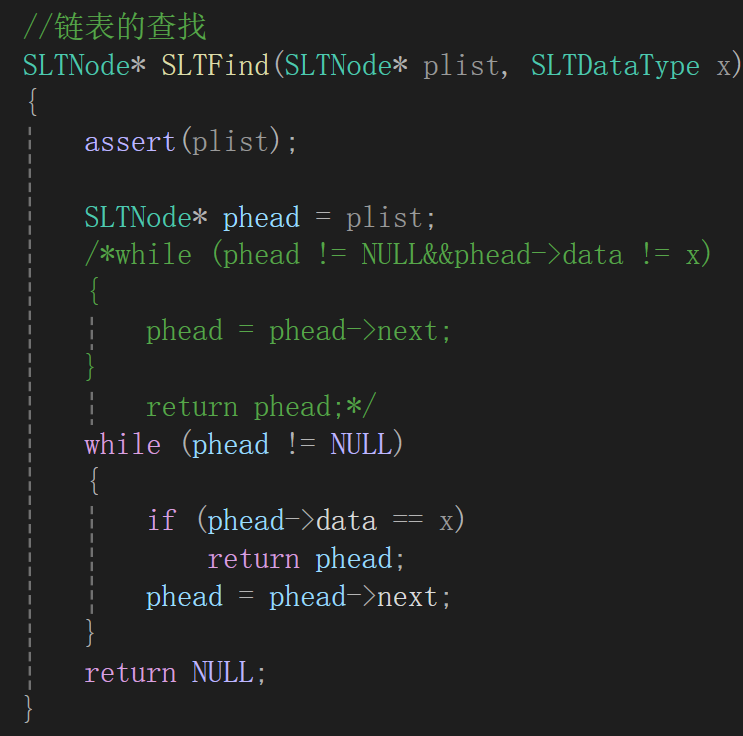
while循环疯狂遍历,每次遍历到的结点去检测一下data,如果遍历完都没找到,直接返回NULL。
这个版本写出来其实是因为想放弃第一个版本了,但是又因为自己不服气,就有了上面的修改过程。
8.单链表指定位置的插入和删除操作
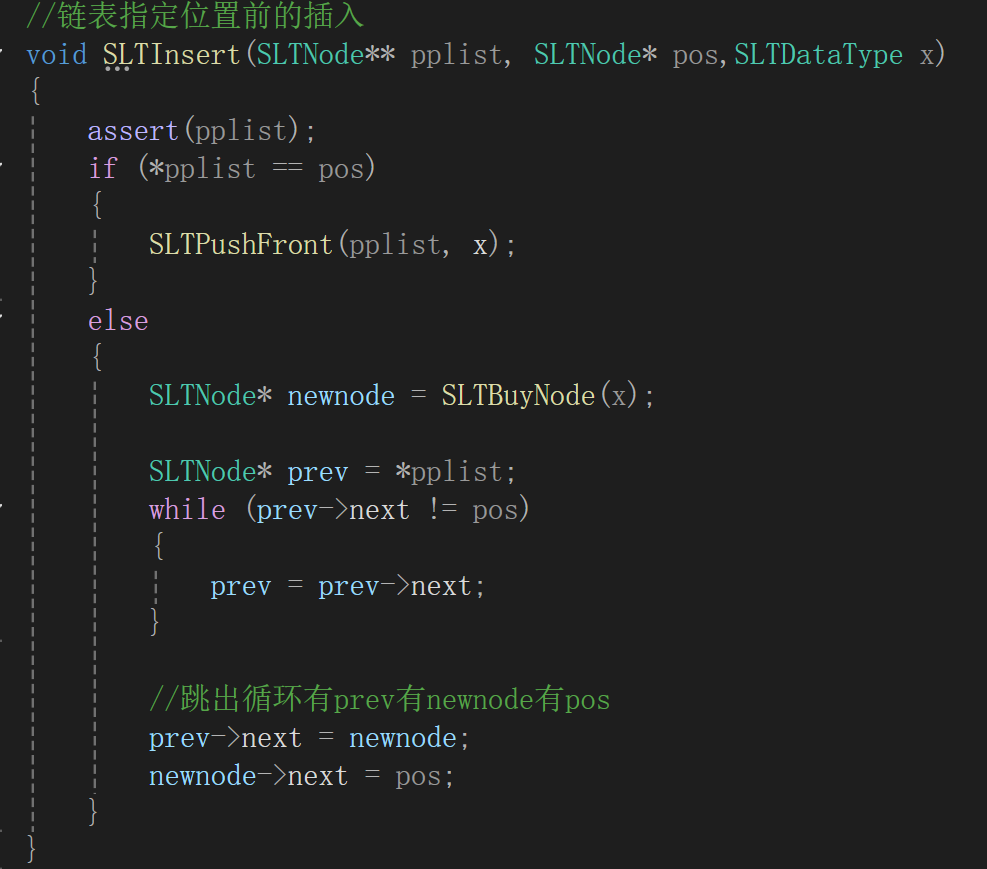
①指定位置之前插入数据
指定位置的插入和删除,肯定是在某个特定的值前才进行,所以链表在这种情况下不会为空
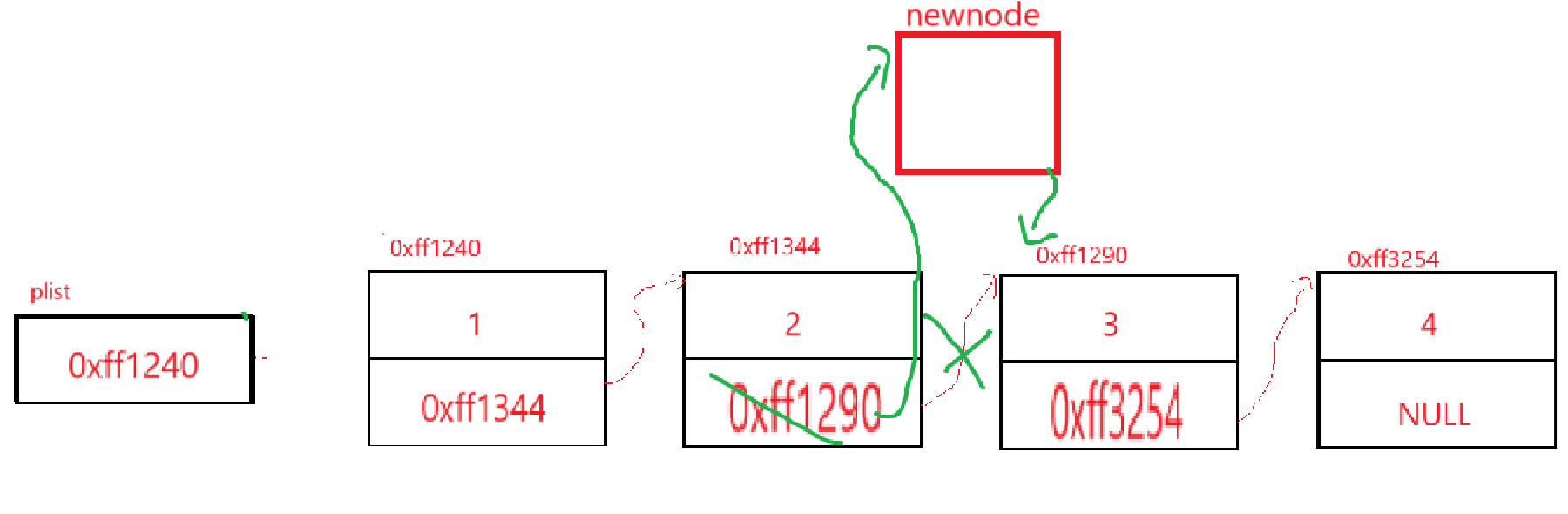
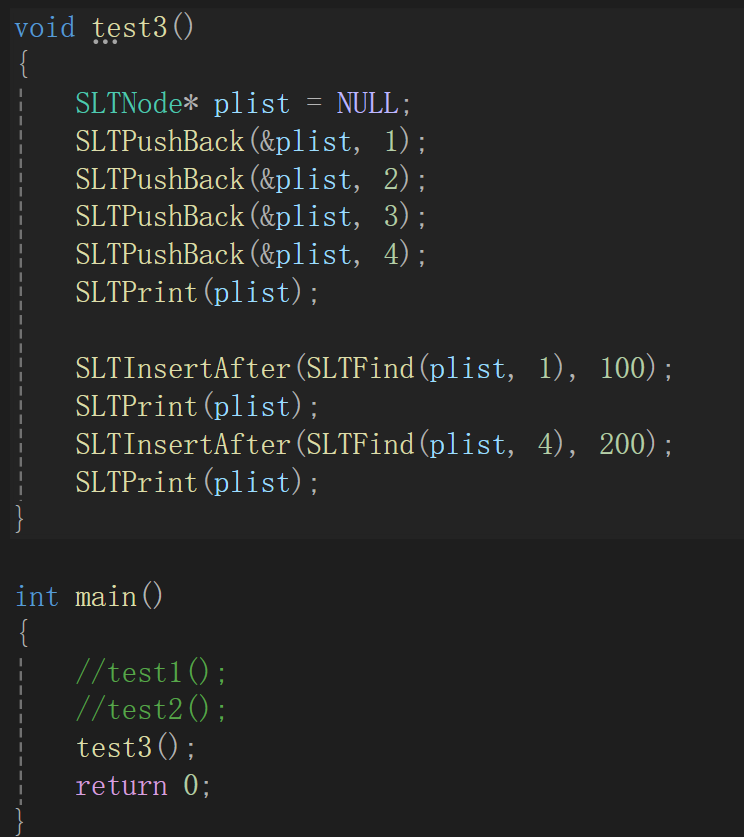
这点意味着要在3这个结点前插结点,创建新结点就不说了,来看指针怎么变,这种情况下传的肯定是链表中某个节点的地址,这样看来的话newnode->next不成问题,但是前面一个结点的next指针可就炸缸了啊,因为你给我的是3的指针,给了这个我往后遍历顺着走就行,往前遍历可就得想想办法了,还是得写一循环遍历,当该指针next为3这个结点就停手,给目标节点起名pos,给目标节点前一个结点起名prev(取自previous)。
准备工作:

准备好结点,准备好要改变的值以后,就是赋值

最后:
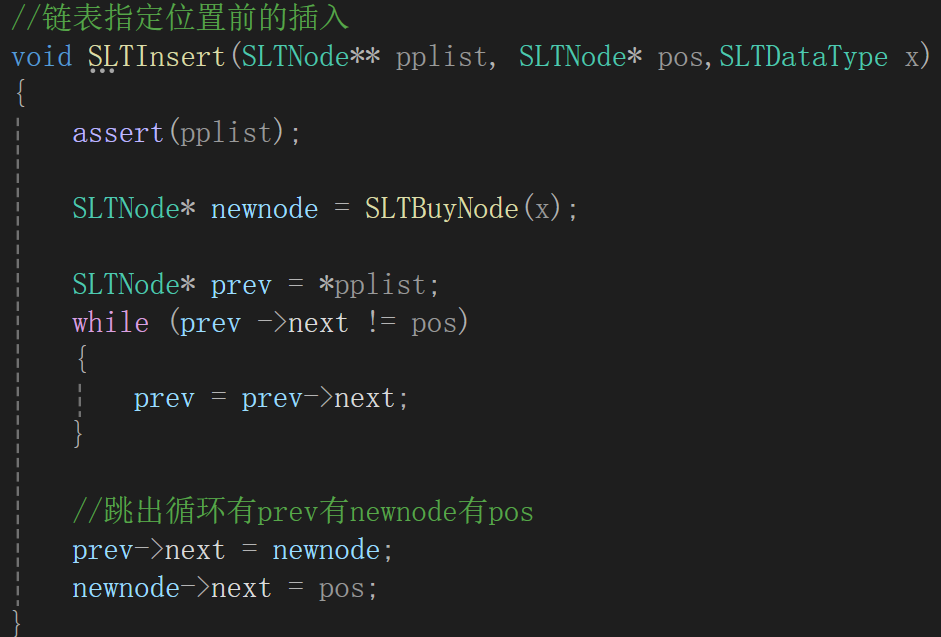
但有一特例,如果指定位置前是链表的头呢:

这个时候的prev->next永远不会是pos,就会无休止的找下去,这样的话会导致出错,干脆如果plist==pos,直接调头插去,懒得再写逻辑了,反正也跟写头插一样:
测试代码:
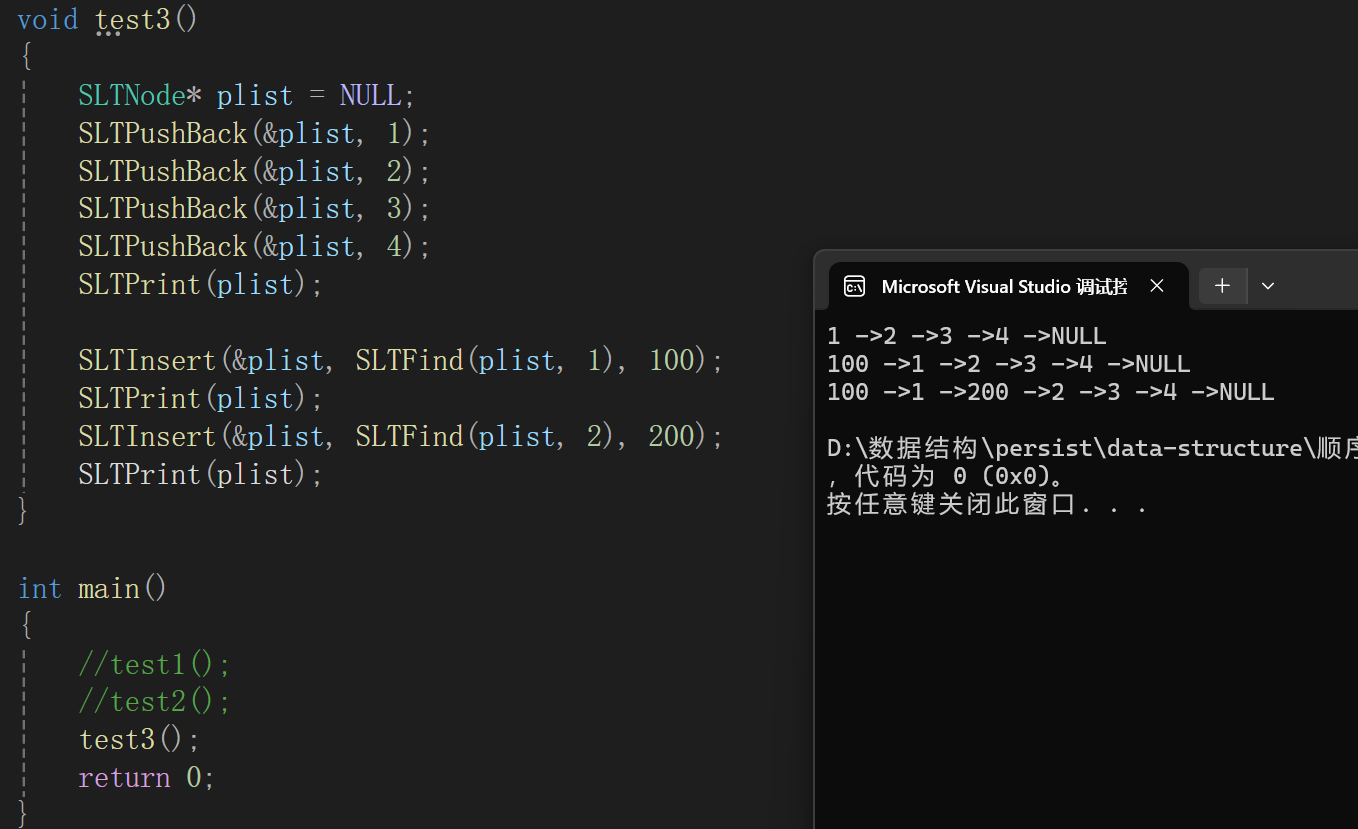
不管头插还是中间的插入都没啥大毛病。
②指定位置之后插入数据

注意参数即可,因为链表的结点的成员是一个data,一个next指针,所以往后插根本不需要指定位置的前一结点的地址,也就不需要链表的头结点地址。
先按照正常元素往中间插的思路写:
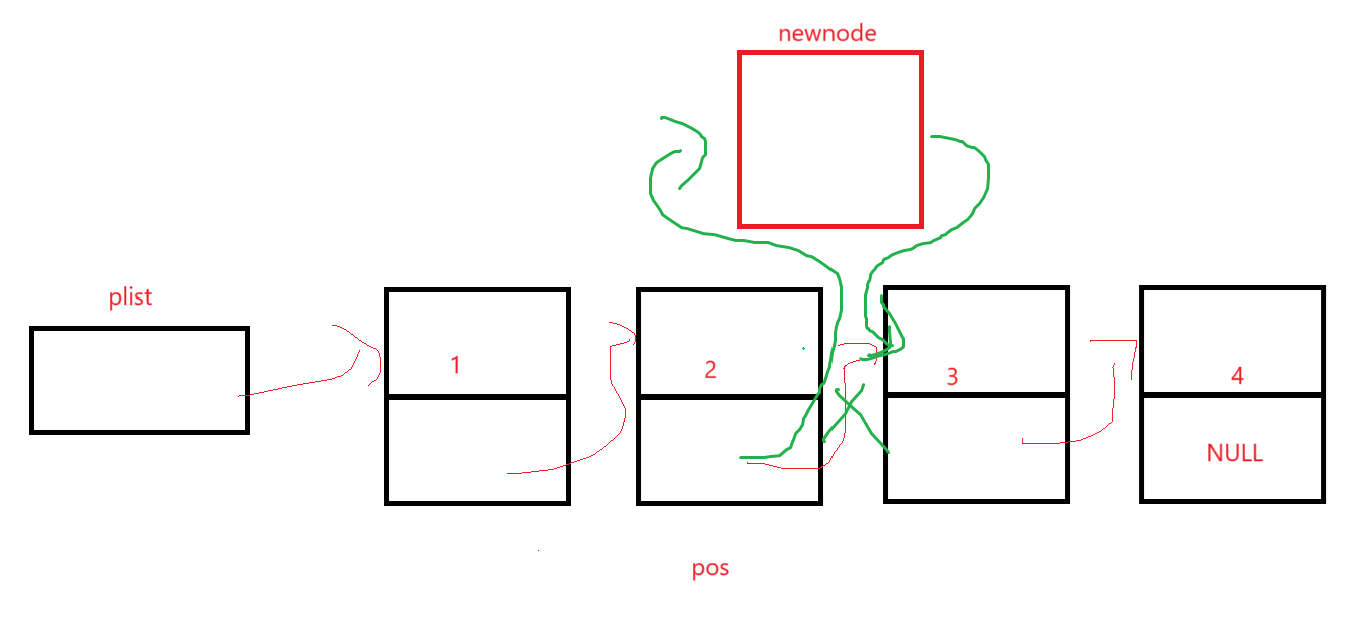
newnode->next指向pos->next,pos->next指向newnode即可,一定要注意顺序。
newnode->next = pos ->next;
pos->next = newnode;
和
pos->next = newnode;
newnode ->next= pos ->next;
真按照下面的干了,直接炸了,因为pos->next直接被你用newnode覆盖了,导致第二句代码newnode->next指的还是newnode自己。

直接写出来就行,但是插入还得小心点(空就不用考虑了,肯定是查找后的指针,不可能为空,即有pos就不用验空),想想第一个结点插入,由于是之后,那跟找中间的插也没啥区别;想想尾结点插入:
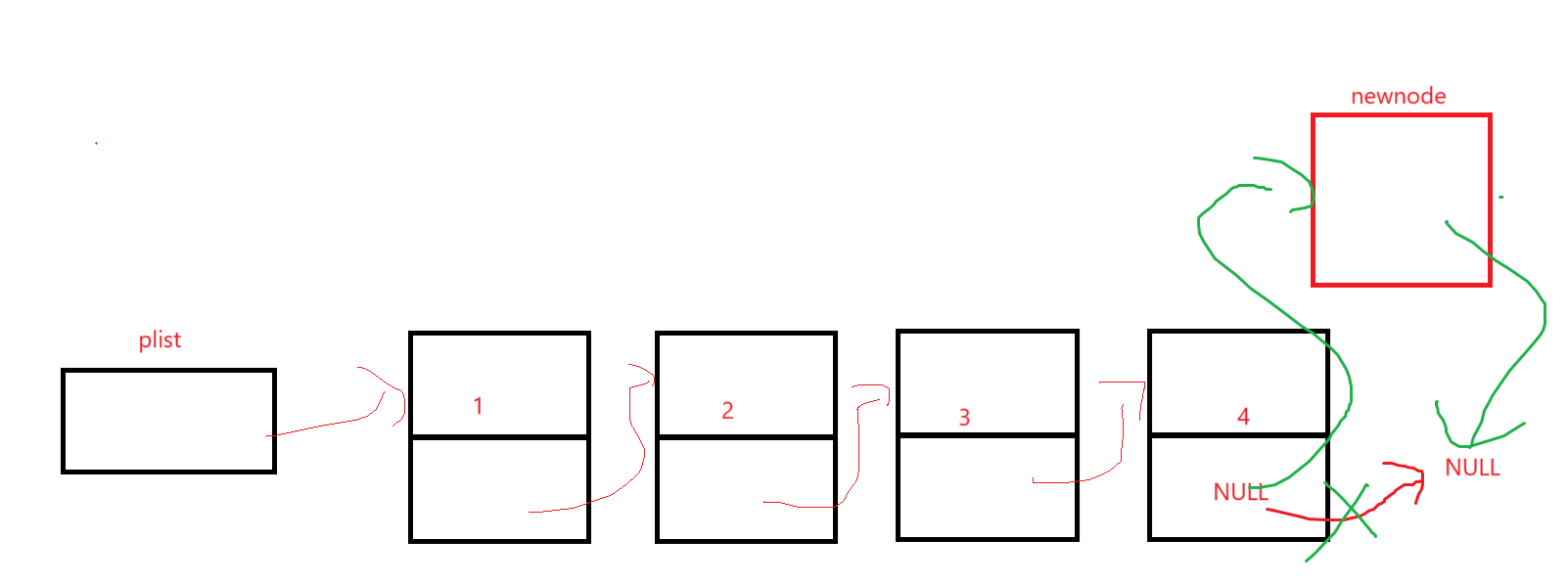
对着代码看,也没啥毛病。
测试一下:
没犯啥毛病,成功了。
③删除指定位置的结点
一个遍历到pos前,一个赋值改指针指向,一个释放:
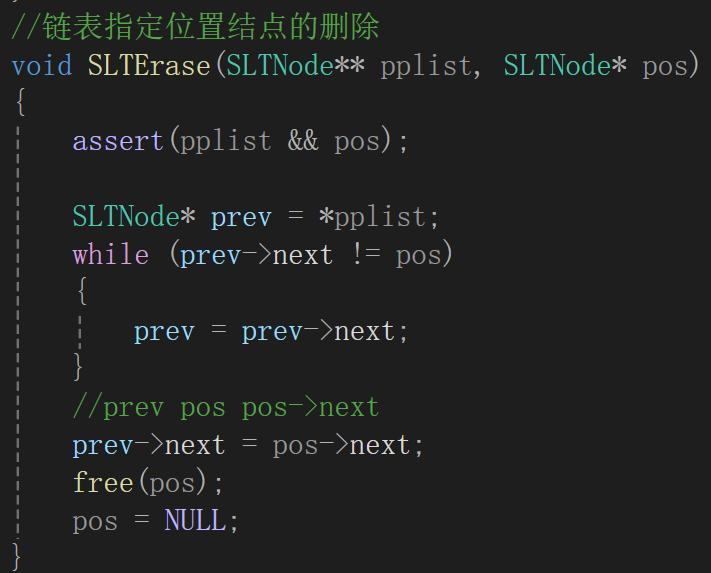
然后就是看看首或者尾会不会出幺蛾子:
上来就发现了,我们的逻辑是prev->next是不是pos,根本无法检测pos刚好为头的情况,所以还是写个if-else去头删:
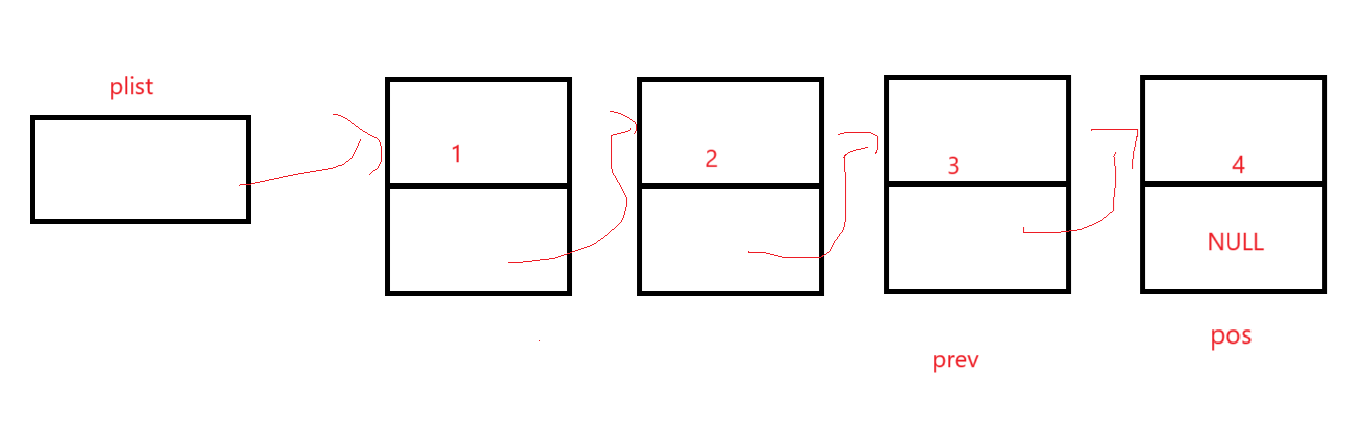
尾结点没炸。
测试:
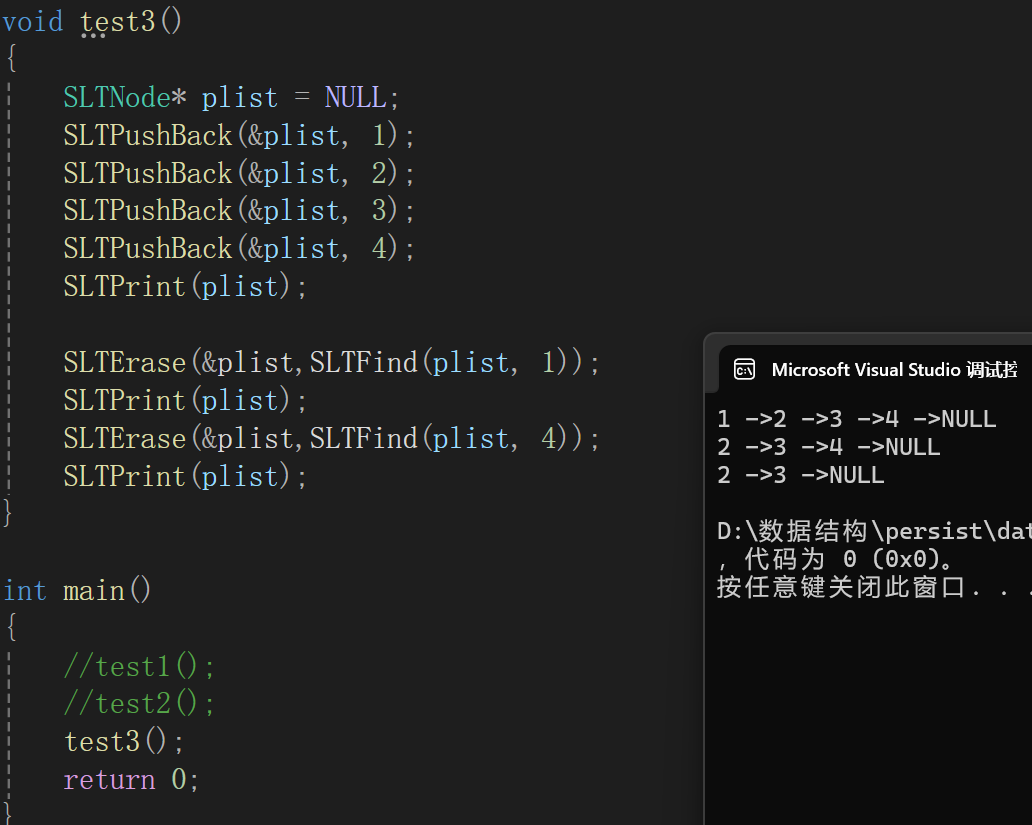
④删除指定位置后的结点

还是说,指定位置后可以直接通过pos找到,就不需要传plist了。
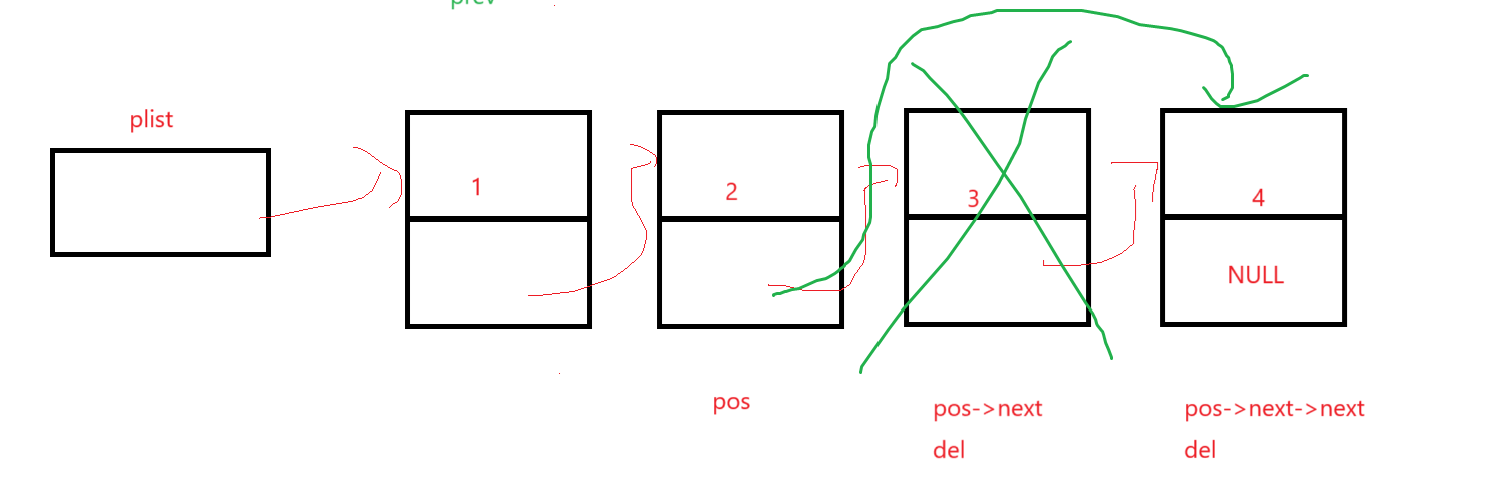
不想写那么多next就将要删去的结点的地址存到del里,方便自己看以及方便改指针和释放:

这么写增加代码可读性。
想想头尾会不会出啥问题,头的话头后删,跟我们从中间找一个结点删效果一样;尾结点后面没结点,想了想指定位置后结点删去不能有尾结点,所以加到assert里:

测试:
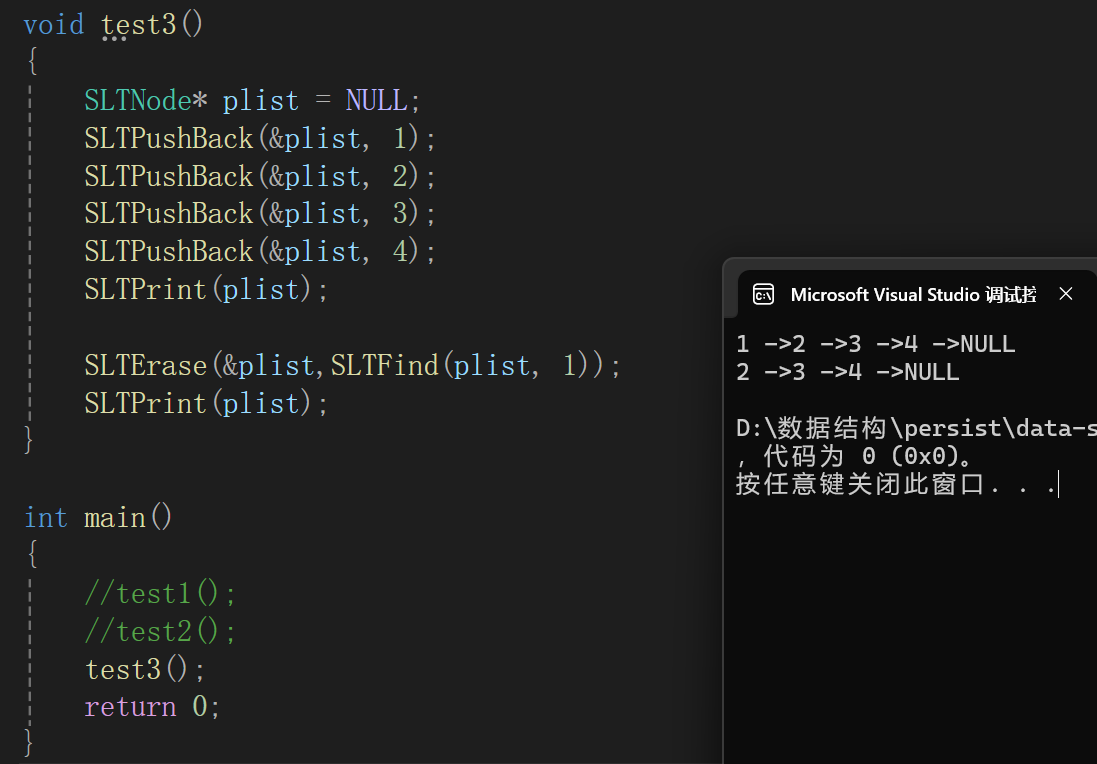
9.单链表的销毁
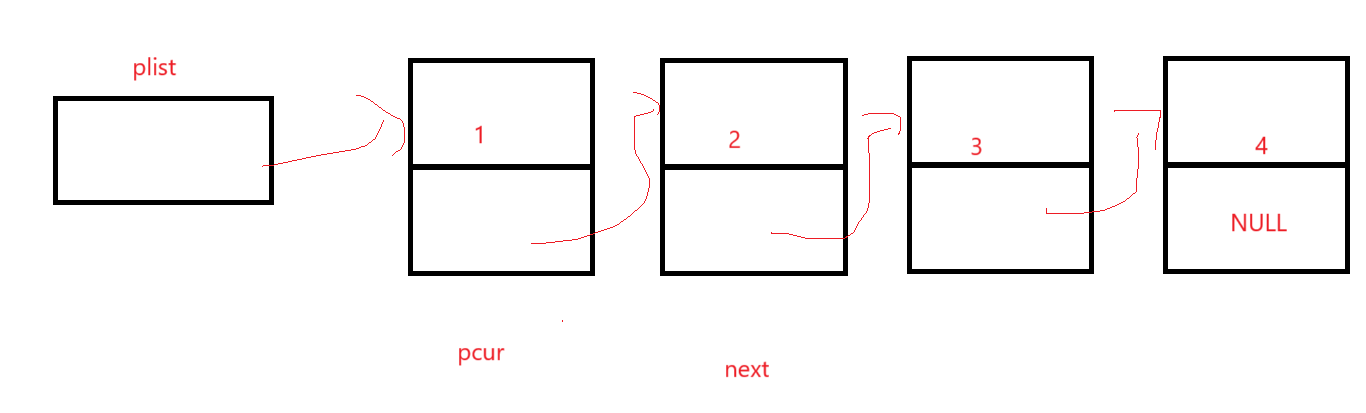
销毁单链表就把头结点的地址传过来。
很明显,如果直接free掉plist那么后面的结点全部都丢了,所以在free结点前记录下一个结点,直到下一个结点为NULL再停止:

三、对比顺序表和单链表
刚刚学完,可谓是手感火热,顺序表和单链表都有插入和删除操作。
其中顺序表的头插头删由于其空间的连续性,所以必须先将已有元素后移,才能插入,后移就会用一个循环,时间复杂度是O(n);
顺序表的尾插尾删,不需要移动数据,所以也不需要循环,插就一句根据地址赋值的事,尾删更简单,直接size--即可。时间复杂度是O(1)
单链表的头插头删,头插由于不需要将其他元素后移,直接针对链表头结点所给指针改变一下next指针;头删就先改头结点指向地址,再free即可。
单链表的尾插尾删,最影响时间复杂度的就是while循环去找尾结点的指针ptail,导致时间复杂度为O(n)。
我们现在就学了这两种数据结构,已经可以看出来,没有哪一种数据结构就能一招鲜吃遍天,各有各的优点,你尾部频繁的增删改,那就用顺序表,头部频繁增删改那就单链表。
解释这个就是为了解释我最开始所说的,学习各种各样的数据结构,是为了算法里选择最优的数据结构。
另外,单链表由于每个结点都是在堆区申请独立的空间,所以不会存在内存浪费的情况,这种优势是针对顺序表来说的,因为在顺序表里有一开辟内存的函数叫CheckCapacity,二倍扩容空间如果不用,那就会浪费。