深度学习—BP神经网络
文章目录
- @[TOC](文章目录)
- 一、基本概念
- 二、 网络结构
- 三、BP神经网络的原理
- 总结
- 特点:
- 应用场景
- 优缺点
文章目录
- @[TOC](文章目录)
- 一、基本概念
- 二、 网络结构
- 三、BP神经网络的原理
- 总结
- 特点:
- 应用场景
- 优缺点
一、基本概念
BP 神经网络(Backpropagation Neural Network)是一种基于误差反向传播算法的多层前馈神经网络,由输入层、隐藏层(一层或多层)和输出层组成。其核心思想是通过前向传播计算预测值,再通过反向传播将误差逐层传递,利用梯度下降调整权重和偏置,从而最小化损失函数。
BP 网络是深度学习的基础,能够处理非线性问题,广泛应用于分类、回归、图像识别、自然语言处理等领域。
二、 网络结构
输入层:接收原始数据(如特征向量),节点数由输入数据维度决定。
隐藏层:包含多层神经元,每层神经元通过权重与前一层连接,引入非线性激活函数(如 Sigmoid、Tanh、ReLU),使网络具备拟合复杂非线性关系的能力。
输出层:根据任务类型(分类或回归)选择激活函数(分类常用 Softmax,回归常用线性函数),输出预测结果。
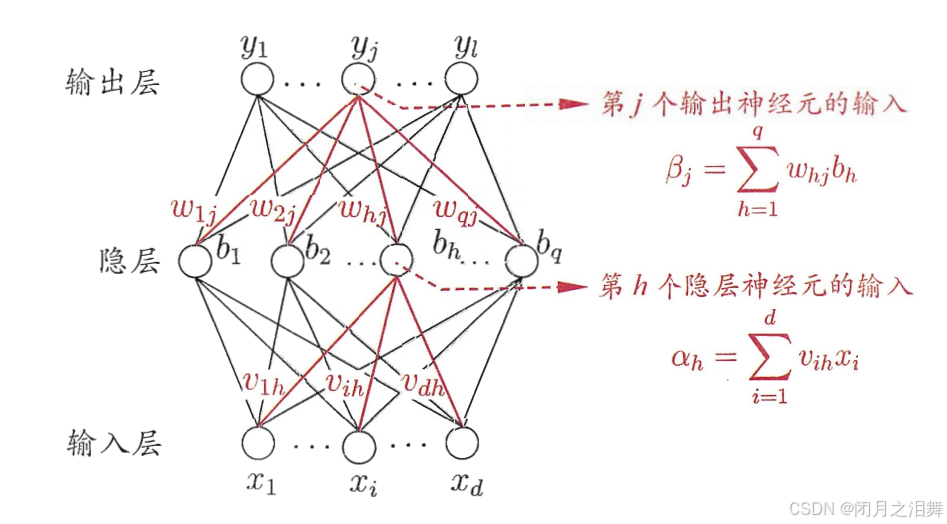
v,w分别的输入层到隐藏层,隐藏层到输出层的是权重
对于上图的只含一个隐层的神经网络模型:BP神经网络的过程主要分为两个阶段,第一阶段是信号的正向传播,从输入层经过隐含层,最后到达输出层;第二阶段是误差的反向传播,从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。
三、BP神经网络的原理
BP(Back-propagation,反向传播)前向传播得到误差,反向传播调整误差,再前向传播,再反向传播一轮一轮得到最优解的。
反向传播的目标是计算损失函数对每个权重和偏置的梯度,从而通过梯度下降更新参数。过程分为两步:前向传播和反向传播。
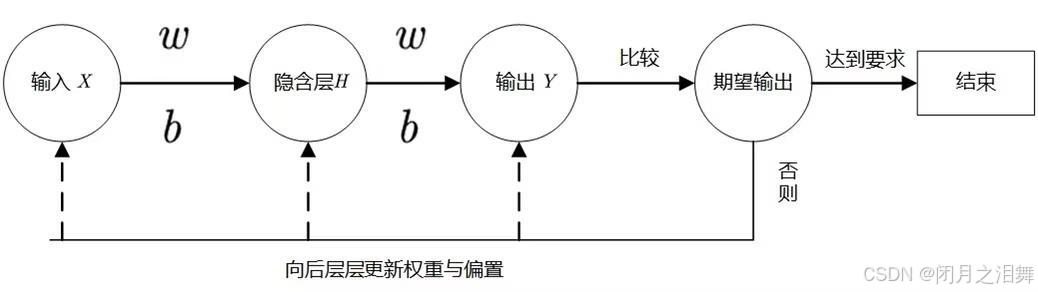
1、前向传播(Forward Propagation)
从输入层开始,逐层计算加权和与激活值,直到输出层得到预测值y^。
2、反向传播(Backward Propagation)
损失函数:常用均方误差(MSE,回归任务)或交叉熵损失(分类任务)。

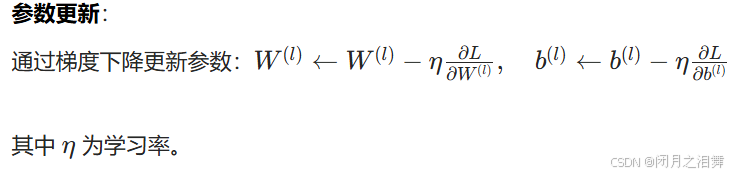
步骤:
1、计算正向传播输出的结果。
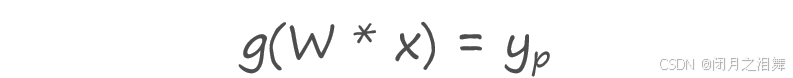
2、计算损失函数
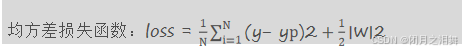
3、计算w值的梯度下降
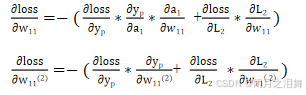
4、误差反向传播
将每个维度偏导数导入本次的w值,初次w值为随机初始化,并乘以步长,即得到新的w值。
5、循环调整w的值,直到损失值小于允许的范围。
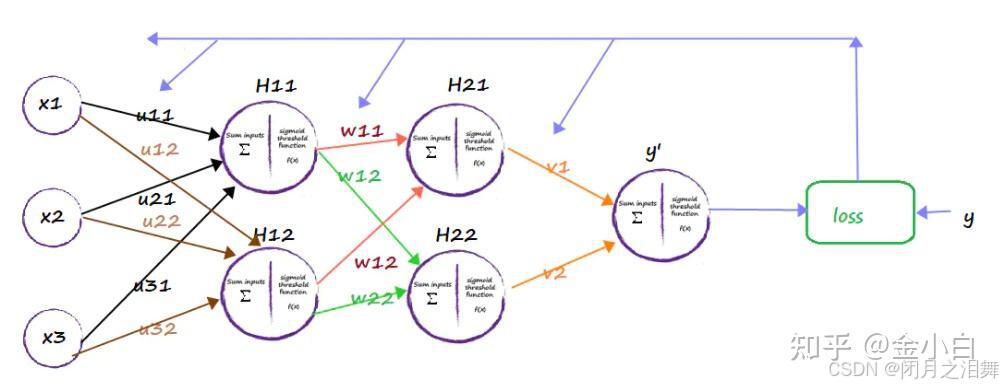
总结
特点:
处理非线性问题:通过多层隐藏层和非线性激活函数,BP 网络可拟合任意复杂的非线性映射(万能近似定理)。
梯度消失问题:早期 BP 网络使用 Sigmoid/Tanh 激活函数时,深层网络的梯度会随着反向传播逐渐衰减,导致底层参数更新缓慢(可通过 ReLU 激活函数、批量归一化、残差连接等缓解)。
监督学习:需标注数据训练,依赖损失函数的梯度计算。
应用场景
分类任务:图像分类(如手写数字识别)、文本分类、语音识别。
回归任务:房价预测、时间序列分析。
复杂问题:深度神经网络(如 CNN、RNN)均基于 BP 算法进行训练。
优缺点
优点:
强大的拟合能力,适用于非线性数据。
理论成熟,可通过反向传播高效计算梯度。
缺点:
易过拟合:需结合正则化(L2、Dropout)、早停等策略。
计算复杂度高:深层网络训练耗时,需优化算法(如 Adam 优化器)或硬件加速(GPU)。
依赖初始参数:随机初始化可能导致局部最优解。