Ascend的aclgraph(八)AclConcreteGraph:capture_end
1 回顾
在上一章Ascend的aclgraph(七)AclConcreteGraph:capture_begin中提到了对capture_begin做了了解,现在继续看下capture_end。
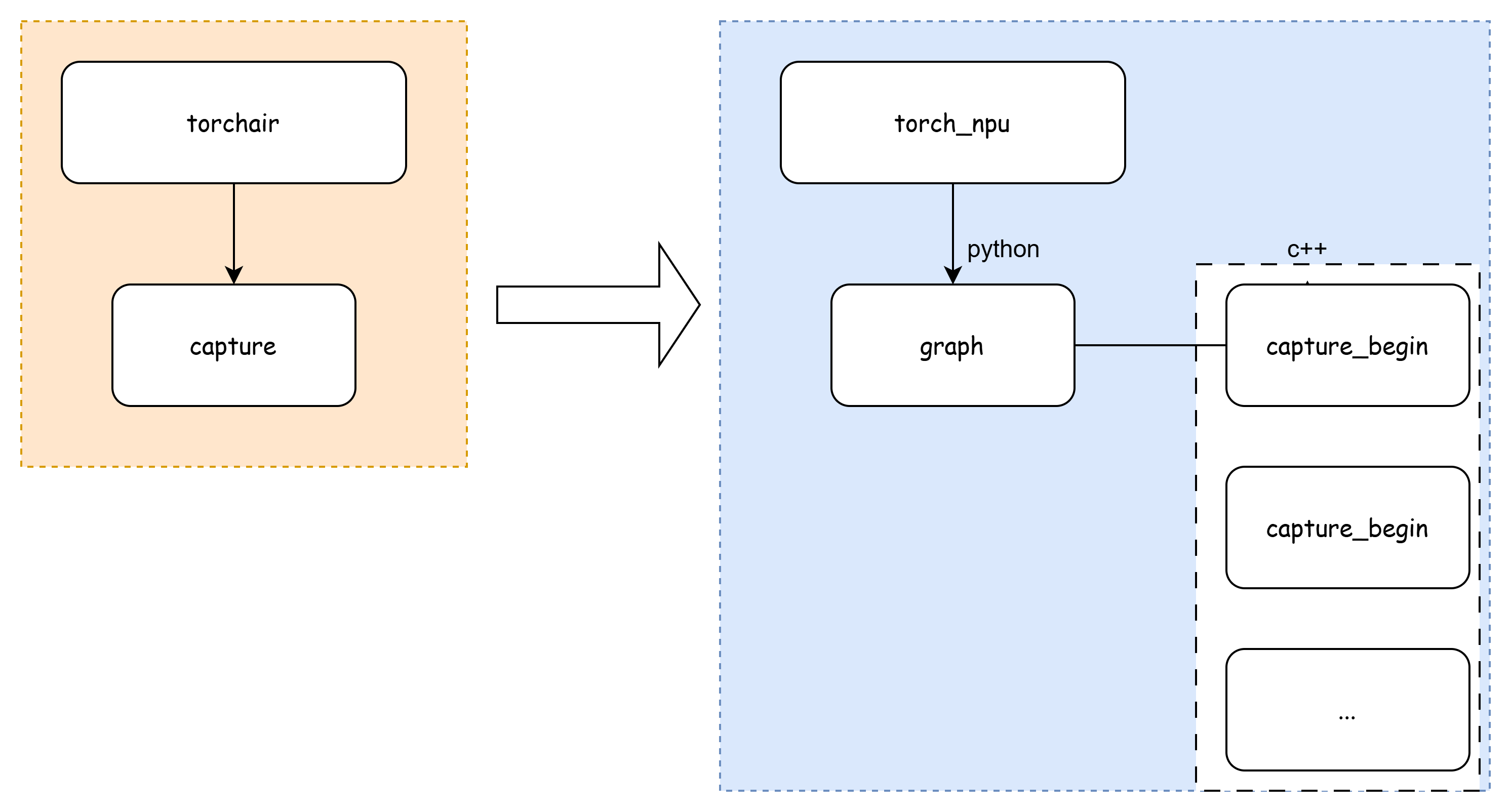
torchair->torch_npu流程图如下:
def __enter__(self):# Free as much memory as we can for the graphtorch.npu.synchronize()gc.collect()torch.npu.empty_cache()# Stackoverflow seems comfortable with this patternself.stream_ctx.__enter__()self.npu_graph.capture_begin(*self.pool, capture_error_mode=self.capture_error_mode)def __exit__(self, exc_type, exc_value, traceback):self.npu_graph.capture_end()self.stream_ctx.__exit__(exc_type, exc_value, traceback)
2 capture_end
.def("capture_end",torch::wrap_pybind_function_no_gil(&c10_npu::NPUGraph::capture_end))
如上述代码所示,在做时候,并没有其他额外逻辑,直接是调用到了c++侧的capture_end。
wrap_pybind_function_no_gil是先去掉python的gil锁,以防死锁。
代码如下:
void NPUGraph::capture_end()
{auto stream = c10_npu::getCurrentNPUStream();TORCH_CHECK(stream == capture_stream_,"Capture must end on the same stream it began on.");aclmdlRI model_ri;NPU_CHECK_ERROR(c10_npu::acl::AclmdlRICaptureEnd(capture_stream_, &model_ri));c10_npu::NPUCachingAllocator::endAllocateToPool(capture_dev_, mempool_id_);TORCH_CHECK(model_ri == model_ri_, "Invalid end capture model id: ", model_ri);// In typical graph usage some tensors (e.g. the tensors used for graph IO) are not freed// between replays.// If Pytorch compiles and runs with a CUDA 11.4+ toolkit, there's a chance the allocator backend// is cudaMallocAsync.// cudaMallocAsync is generally graph-safe, but if some tensors are not freed between replays,// the graph's internal bookkeeping requires that we instantiate with// cudaGraphInstantiateFlagAutoFreeOnLaunch. See// cudaGraphLaunch// cudaGraphInstantiateWithFlagshas_graph_exec_ = true;uint32_t num_graph_nodes = 0;
}
流程图如下:
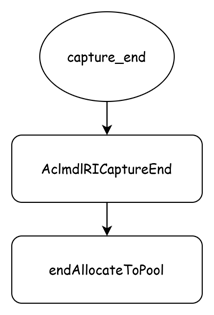
AclmdlRICaptureEnd与AclmdlRICaptureBegin是相对的,调用的是libascendcl.so中的AclmdlRICaptureEnd方法。
aclError AclmdlRICaptureEnd(aclrtStream stream, aclmdlRI *modelRI)
{typedef aclError (*AclmdlRICaptureEnd)(aclrtStream, aclmdlRI *);static AclmdlRICaptureEnd func = nullptr;if (func == nullptr) {func = (AclmdlRICaptureEnd) GET_FUNC(aclmdlRICaptureEnd);}TORCH_CHECK(func, "Failed to find function aclmdlRICaptureEnd", PTA_ERROR(ErrCode::NOT_FOUND));return func(stream, modelRI);
}
在昇腾官网上搜索到如下信息:
https://www.hiascend.com/document/detail/zh/canncommercial/81RC1/apiref/appdevgapi/aclcppdevg_03_1784.html
函数原型

接口解释
结束Stream的捕获动作,并获取模型的运行实例,该模型用于暂存所捕获的任务。
本接口需与其它接口配合使用,以便捕获Stream上下发的任务,暂存在内部创建的模型中,用于后续的任务执行,以此减少Host侧的任务下发开销,配合使用流程请参见aclmdlRICaptureBegin接口处的说明。
还有个一个函数是endAllocateToPool,给出函数定义
// Called by NPUGraph::capture_end
void endAllocateToPool(MempoolId_t mempool_id)
{std::lock_guard<std::recursive_mutex> lock(mutex);for (auto it = captures_underway.begin(); it != captures_underway.end(); ++it) {if (it->first == mempool_id) {captures_underway.erase(it);return;}}TORCH_CHECK(false, "endAllocatePool: not currently recording to mempool_id");
}
这里就是从captures_underway删除此次使用的mempool_id。这个操作与beginAllocateToPool中的emplace操作是相对应的。
3 总结
capture_end的逻辑相对简单。
下一步,梳理清楚torch.compile中的FX graph和AclmdlRICaptureBegin与AclmdlRICaptureEnd抓的图是什么关系。