【Redis 进阶】集群
思维导图:
一、Redis集群概述
(一)广义集群与狭义集群的定义
- 广义集群:指由多个机器组成的分布式系统,例如前面提到的主从模式和哨兵模式。
- 狭义集群:Redis提供的集群模式,主要用于解决存储空间不足的问题。
(二)Redis集群的核心思想
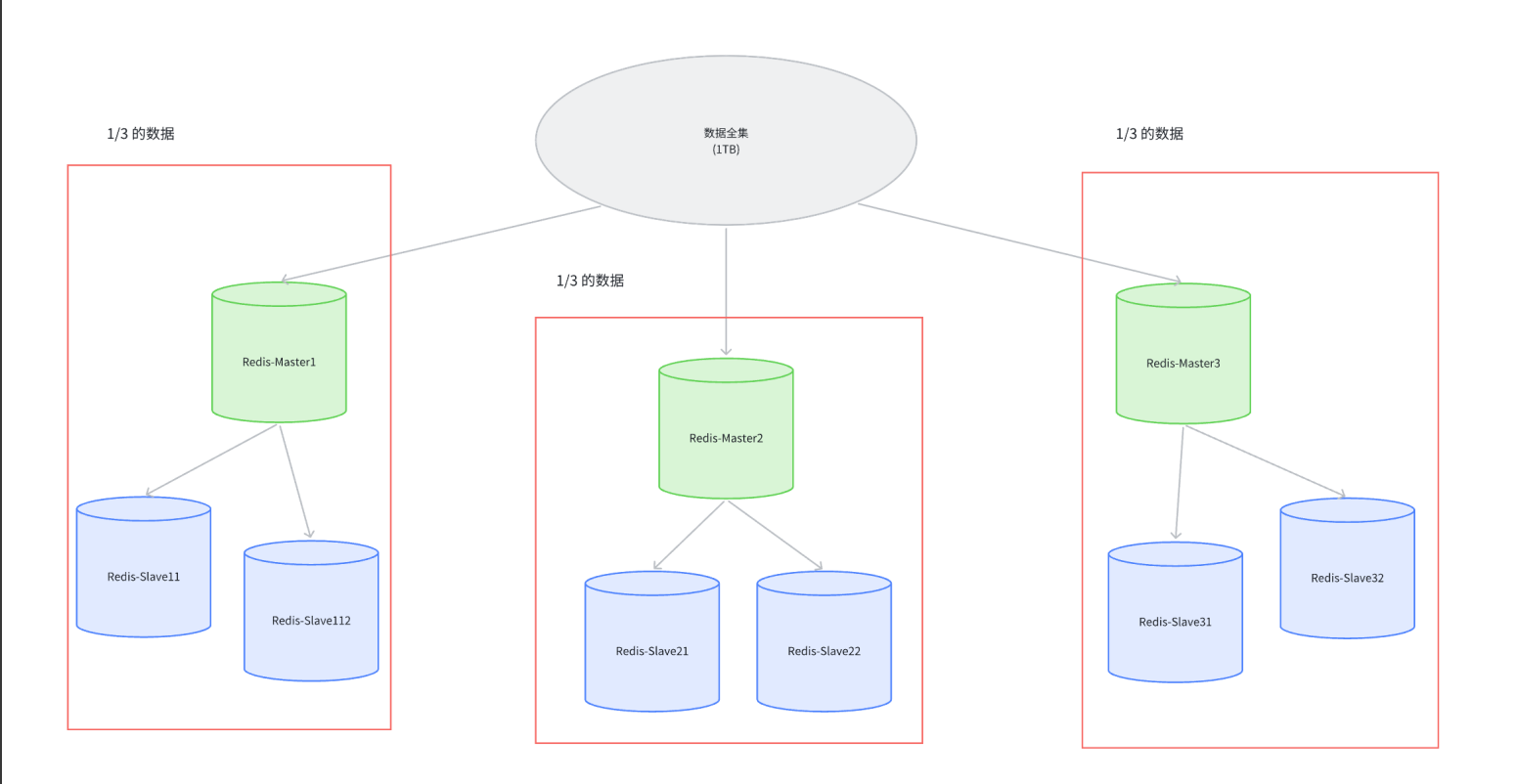
Redis集群通过引入多组Master/Slave架构,每组Master/Slave负责存储数据全集的一部分,从而实现数据的分布式存储和高可用性。
图片中的每一个红框,都可以称作一个分片,也就是说,理论上如果数据量进一步增加,只要继续增加分片的数量即可。
那么接下来的问题就是,给定一个数据,这个数据应该放在哪个分片上呢,取数据的时候又应该到哪个片段读取?
二、数据分片算法
(一)哈希求余算法
- 原理:通过哈希函数对数据key进行映射,得到的整数再对分片数量求余,确定数据所在分片。
节点位置 = hash(key) % 节点数量 - 缺点:由于数据的分布是随机的,在加入一个切片后,所有的数据需要重新分配区间,大量的数据需要迁移。数据迁移成本高,尤其在数据量过大时。
(二)一致性哈希算法
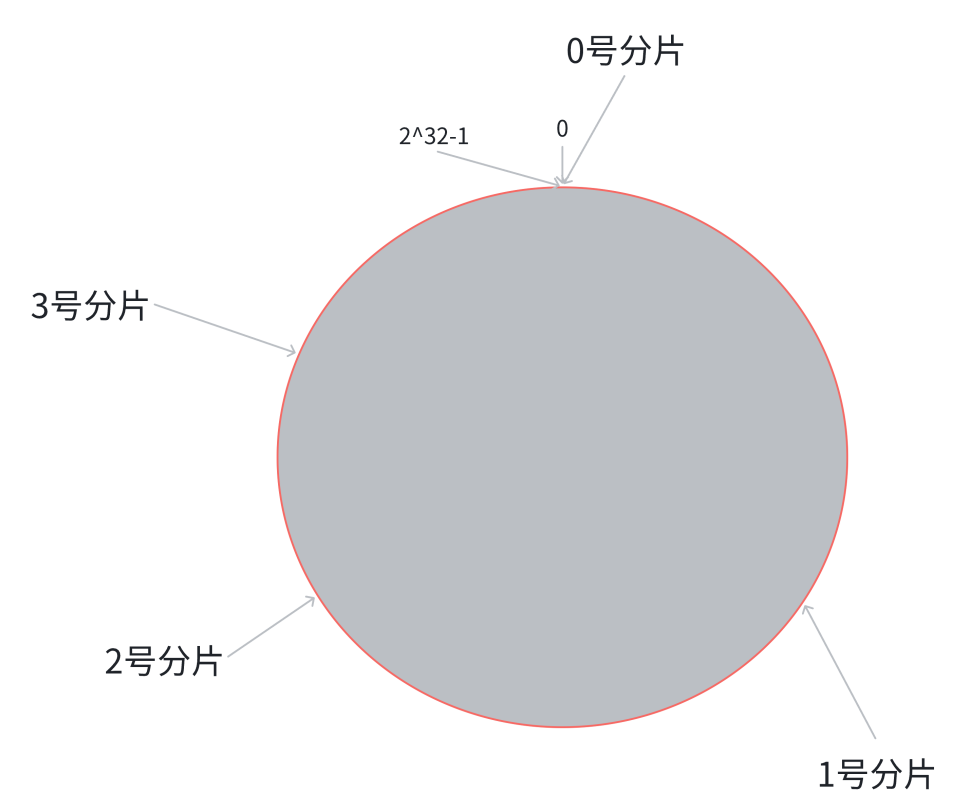
- 原理:
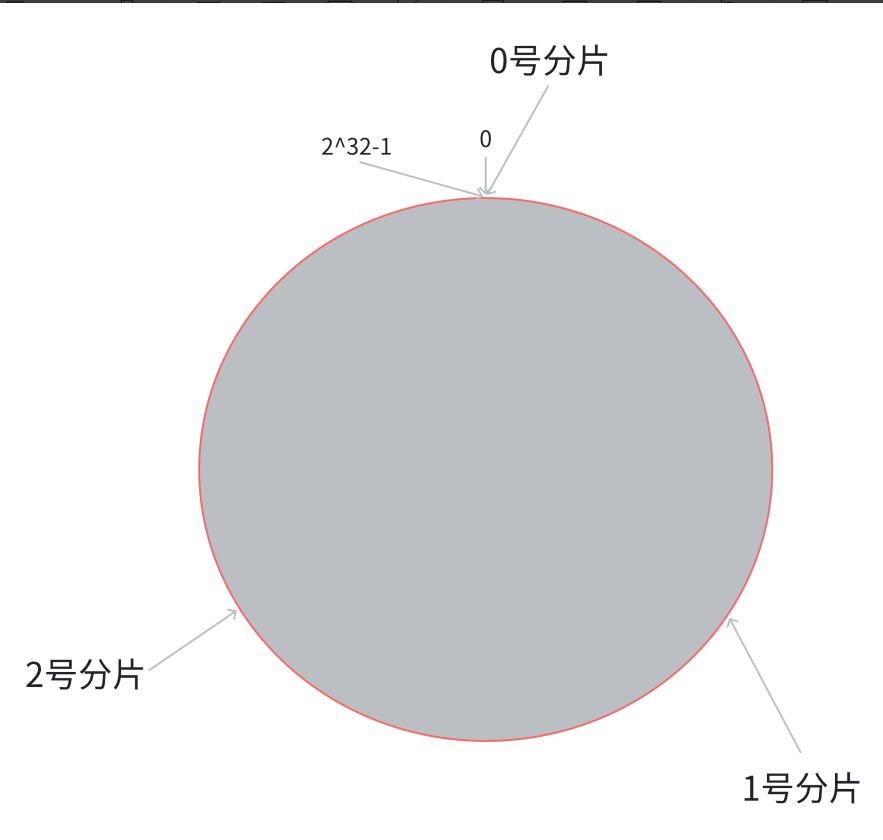
1.将1 ~ 2^32 - 1均匀分布在一个圆环上。

2.将整个圆划分为三个分片
3.找到相应分片的方法就是找到数据的 hash 值,落到某个点,然后顺时针旋转,对应的分片就是所属分片
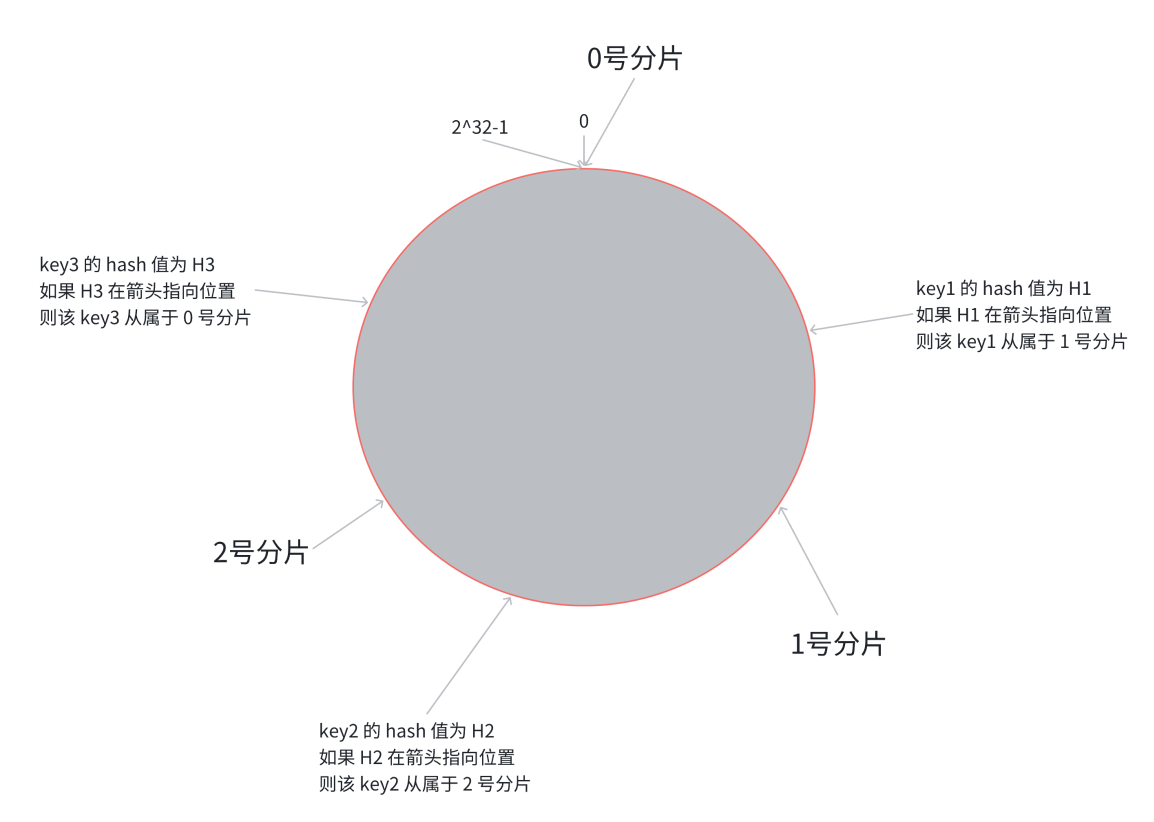
- 缺点:在这种情况下,如果想进行扩容操作,那就可以在 0 号分片和 2 号分片中间插入 3 号分片,然后把原属于 0 号 和 2 号的部分数据迁移到 3 号,这样数据迁移的数量就会大大降低。但是同时也带来了一个问题,那就是分片的数据不均匀,导致数据倾斜。
(三)哈希槽分区算法
- 原理:
- Redis集群采用哈希槽分区算法,将整个数据集划分为16384个槽位,每个节点负责一部分槽位。
- 假设当前有三个分片,一种可能的分配方式:
- 0号分片: [0, 5461],共5462个槽位。
- 1号分片: [5462, 10923],共5462个槽位。
- 2号分片: [10924, 16383],共5460个槽位。
这里的分片规则是很灵活的,每个分片持有的槽位不一定连续。每个分片的节点使用位图来表示自己持有哪些槽位。对于16384个槽位来说,需要2048个字节(2KB)大小的内存空间表示。
- 如果需要进行扩容,比如新增一个3号分片,就可以针对原有的槽位进行重新分配。例如一种可能的分配方式:
- 0号分片: [0, 4095],共4096个槽位。
- 1号分片: [5462, 9557],共4096个槽位。
- 2号分片: [10924, 15019],共4096个槽位。
- 3号分片: [4096, 5461] + [9558, 10923] + [15019, 16383],共4096个槽位。
在实际使用Redis集群分片的时候,不需要手动指定哪些槽位分配给某个分片,只需要告诉某个分片应该持有多少个槽位即可,Redis会自动完成后续的槽位分配,以及对应的key搬运的工作。
- 优点:扩展性强,数据分布均匀。
数据分片相关问题
-
Redis集群最多时有16384个分片吗?
- 虽然理论上可以支持16384个分片,但实际应用中建议不超过1000个分片,以避免数据倾斜和系统不稳定。
- 分片过多会导致服务程序涉及的机器数量激增,增加系统不稳定性。
-
为什么是16384个槽位?
- 节点间通过心跳包通信,心跳包需包含分片对应的槽位信息。
- 使用位图表示槽位信息,占用2KB大小,适合频繁交互的心跳包,减少网络带宽消耗。
三、基于Docker在云服务器上搭建Redis集群
(一)创建目录和配置
- YAML文件:使用Docker Compose定义集群节点和服务配置。
- Shell脚本:批量创建每个节点的配置文件。
(二)创建Redis节点
- 使用Docker创建11个Redis节点(9个集群节点,2个扩容节点)。
(三)创建集群
- 使用
redis-cli --cluster create命令创建集群。 cluster nodes命令查看集群信息。
四、故障转移机制
(一)故障判定
Redis集群中的故障判定依赖于节点间的心跳包通信。每个节点每秒会随机向部分节点发送心跳包(避免全量发送导致的指数级增长)。心跳包包含节点ID、所属分片、包含的槽位等信息。
- 主观下线(PFAIL)
- 当一个节点(如A)向另一个节点(如B)发送ping包后,如果在规定时间内未收到B的pong包回复,A会重置与B的连接并再次发送ping包。
- 若再次发送后仍未收到回复,A就会主观地认为B下线了,将B标记为PFAIL状态。
- 客观下线(FAIL)
- 当一个节点将某个节点标记为PFAIL后,它会通过Redis内置的Gossip协议与其他节点进行通信,询问它们对目标节点状态的看法。
- 如果超过半数的节点都认为该目标节点处于PFAIL状态,那么这个目标节点就会被判定为FAIL状态,此时故障转移流程将被触发。
(二)故障迁移
当主节点发生故障被判定为FAIL后,故障迁移过程如下:
- 从节点参选资格判断
- 故障主节点的从节点会根据自身与主节点的数据差异等因素判断是否有参选资格。
- 休眠与拉票
- 具有参选资格的从节点会进入休眠状态,休眠时间计算方式为:500ms基础时间+【0 - 500】随机时间+排名 * 1000ms(offset越大,排名越靠前,即越小)。
- 当某个从节点先醒来后,会向其他节点发送拉票请求,但只有主节点能够参与投票。
- 新主节点选举
- 当某个从节点的票数超过当前主节点(故障主节点)的半数时,该从节点就会晋升为新主节点。
- 新主节点确定后,会将其信息同步给其他节点,同时哨兵节点会通知客户端更新连接信息,以确保后续操作指向新的主节点。
(三)集群宕机情况
- 某个分片的主从节点全部挂掉。
- 主节点挂掉且无从节点。
- 超过半数的master节点故障。
五、集群扩容
(一)新主节点加入与槽位重分配
- 新主节点加入:将新的Redis节点加入到集群中。
- 槽位重分配:通过
redis-cli --cluster reshard命令重新分配槽位,将部分槽位从现有节点迁移到新节点。 - 在这个过程中,对于集群中的key,大部分是不用搬运的,在搬运的过程中,未搬运的key可以被客户端访问。对于正在搬运的key,可能就会出现访问出错的情况。就比如你正重定向到某个切片,但这个切片上的对应数据已经被搬运走了。所以为了更高的可用性,除了扩容,也可以搭建新的集群(一组新的机器),然后从旧的集群中克隆数据,使用新的集群代替旧的集群。(成本高)
(二)添加从节点
- 给新的主节点添加从节点以提高数据冗余和高可用性。