关系实验课--笛卡尔积
import sympy as sym
a, b = sym.symbols('a b') # 定义符号 a 和 b
A = sym.FiniteSet(a,b) # 创建包含 a 和 b 的有限集合
B = sym.FiniteSet(1,2,3,4)
AxB = sym.cartes(A,B) # 返回迭代器。迭代器不会直接显示内容,而是需要手动遍历或转换为其他数据类型(如列表)。
print("A=",A)
print("B=",B)
print("AxB1=",AxB) # 输出:<itertools.product object at 0x0DB35328>
AxB = A * B # 计算笛卡尔积, SymPy 中 * 运算符表示笛卡尔积.
# SymPy 会直接显示笛卡尔积的符号表示,而非具体组合。
print("AxB2=",AxB)
print("AxB3=",list(AxB)) # 转换为列表输出
print("AxB4={",end='')
for index, pair in enumerate(AxB):print(f"({pair[0]}, {pair[1]})", end=", " if index < len(AxB) - 1 else " ")
print("}",end='\n') # 这将添加一个换行符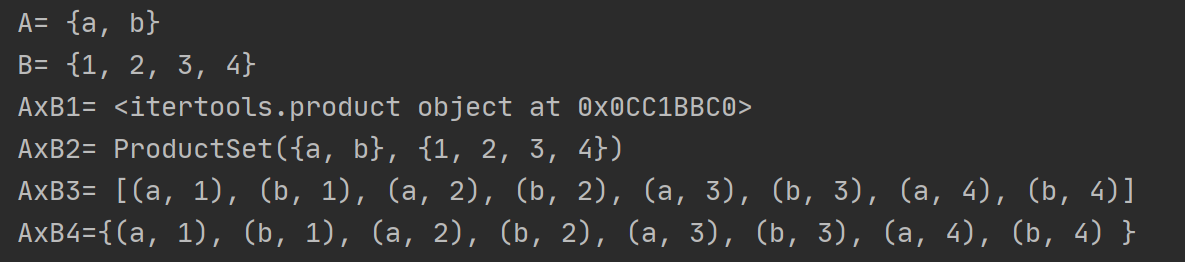
-
首先,使用
print("{", end="")开始打印一个左大括号{,但不换行,以便在同一行继续打印笛卡尔积的元素。 -
接着,通过一个
for循环遍历AxB中的每个元素。AxB是两个集合A和B的笛卡尔积,每个元素都是一个元组。 -
在循环中,使用
enumerate(AxB)来获取每个元素的索引(index)和值(pair)。index用于后续判断是否为最后一个元素,pair是笛卡尔积中的元组。 -
使用
print(f"({pair[0]}, {pair[1]})", end=", " if index < len(AxB) - 1 else " ")来打印每个元组。这里的f"({pair[0]}, {pair[1]})"是一个格式化字符串,用于打印元组的两个元素。end=", "表示在打印完每个元组后,默认加上逗号和空格,以便在同一行继续打印下一个元组。 -
但是,为了避免在最后一个元组后面也加上逗号,使用了
if index < len(AxB) - 1 else " "条件判断。如果当前元素不是最后一个元素,就加上逗号和空格;如果是最后一个元素,则只打印元组,不加上逗号和空格。 -
最后,使用
print("}")在所有元素打印完毕后,打印一个右大括号},完成整个笛卡尔积的输出。
综上所述,这段代码的目的是以正确的格式(即在每个元素后面加上逗号,除了最后一个元素)打印两个集合的笛卡尔积。例如,如果A包含符号a和b,而B包含数字1、2、3和4,那么输出将会是:
{(a, 1), (a, 2), (a, 3), (a, 4), (b, 1), (b, 2), (b, 3), (b, 4)}
这段代码通过结合enumerate函数和条件表达式,实现了对笛卡尔积输出的精确控制。
一、基础用法:让遍历更智能
1.1 什么是 enumerate?
Enumerate 是 Python 内置的一个函数,其名称来源于英语中的“枚举”(Enumeration),即“逐个列举”的含义。它的核心功能是为可迭代对象(如列表、字符串等)中的每个元素添加一个索引编号,从而在遍历时同步获取“位置”与“值”。
简单比喻:
想象你在超市的货架前,货架上的商品按顺序排列,但没有明确的编号。Enumerate 就像在每个商品旁贴上一个标签,标签上写着“第1个”“第2个”……这样当你需要快速找到某个商品时,既知道它的位置,又知道它的具体信息。
1.2 基本语法与示例
语法结构:
enumerate(iterable, start=0)
- 参数:
iterable:需要遍历的可迭代对象(如列表、元组、字符串)。start(可选):索引的起始值,默认为0。
示例代码:
fruits = ["apple", "banana", "cherry"]
for index, fruit in enumerate(fruits): print(f"索引 {index} 对应的水果是:{fruit}") 1.3 为什么需要 enumerate?
在没有 enumerate 时,开发者通常需要手动维护一个计数器变量来记录索引,例如:
fruits = ["apple", "banana", "cherry"]
index = 0
for fruit in fruits: print(f"索引 {index} 对应的水果是:{fruit}") index += 1
这种方式不仅代码冗长,还容易因忘记更新索引变量导致错误。而 enumerate 的出现,直接简化了这一流程,使代码更清晰、高效。