损失函数的选择和技术分析:深度学习模型训练的指南
摘要: 在深度学习模型训练过程中,损失函数(Loss Function)或目标函数(Objective Function)扮演着至关重要的角色。它衡量了模型预测结果与真实值之间的差异,并为模型的参数优化指明方向。选择合适的损失函数是成功训练模型的关键一步,不同的任务类型和数据特点需要匹配不同的损失函数。
本文将深入探讨常见损失函数的原理、技术细节、选择依据以及它们对模型训练的影响,并提供相应的 PyTorch 代码示例。
1. 什么是损失函数?为什么它如此重要?
损失函数 是一个用于量化模型预测( y ^ \hat{y} y^)与对应真实标签( y y y)之间不一致程度的函数。其输出是一个非负的标量值,通常损失值越小,表示模型的预测结果越接近真实值。
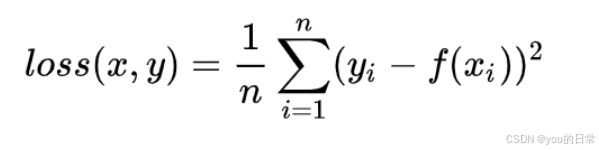
损失函数的重要性在于:
- 指导优化: 模型的训练过程本质上是一个优化问题,目标是找到一组最优的模型参数( θ \theta θ),使得损失函数最小化。
θ ∗ = arg min θ L ( y , y ^ ( x ; θ ) ) \theta^* = \arg \min_{\theta} L(y, \hat{y}(x; \theta)) θ∗=argθminL(y,y^(x;θ))
其中, L L L 代表损失函数, y y y 是真实标签, y ^ ( x ; θ ) \hat{y}(x; \theta) y^(x;θ) 是模型在输入 x x x 和参数 θ \theta θ 下的预测结果。 - 衡量模型性能: 在训练过程中,损失函数的值可以作为监控模型学习进度的指标。
- 定义任务目标: 不同的损失函数对应着不同的任务目标。例如,用于回归的损失函数关注预测值与连续真实值之间的距离,而用于分类的损失函数关注预测类别与真实类别之间的匹配程度或概率分布的相似性。
2. 如何选择合适的损失函数?
选择损失函数的首要依据是您的机器学习任务类型。主要任务类型包括:
-
回归 (Regression): 预测一个连续的数值,如房价预测、股票价格预测。
-
分类 (Classification): 预测一个离散的类别标签。又可以细分为:
- 二分类 (Binary Classification): 只有两个类别,如判断邮件是否为垃圾邮件。
- 多分类 (Multi-class Classification): 预测样本属于多个类别中的一个,且样本只能属于一个类别,如识别图片中的物体(猫、狗、鸟)。
- 多标签分类 (Multi-label Classification): 预测样本可能同时属于多个类别,如一篇文章可能同时被打上“人工智能”、“深度学习”、“自然语言处理”等标签。
-
其他任务: 如排名 (Ranking)、聚类 (Clustering)、生成模型 (Generative Models) 等,有各自特定的损失函数。
确定了任务类型后,还需要结合数据的特点、模型的输出层设计以及对模型性质的偏好来进一步选择。
3. 常见损失函数详解与技术分析
3.1 回归问题中的损失函数
在回归问题中,我们关心预测值 y ^ \hat{y} y^ 与真实值 y y y 之间的数值差异。模型的输出通常是未经激活或使用线性激活函数。
a. 均方误差 (Mean Squared Error, MSE) / L2 Loss
计算预测值与真实值之差的平方的平均值。

L MSE = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 L_{\text{MSE}} = \frac{1}{N} \sum_{i=1}^N (y_i - \hat{y}_i)^2 LMSE=N1i=1∑N(yi−y^i)2
在 PyTorch 中,可以使用 torch.nn.MSELoss 来计算 MSE。
import torch
import torch.nn as nn# 假设一批次有 3 个样本
N = 3
# 假设每个样本预测一个连续值
predicted = torch.tensor([1.5, 2.3, 3.1])
target = torch.tensor([1.0, 2.5, 3.0])# 初始化 MSE 损失函数
mse_loss_fn = nn.MSELoss()# 计算损失
loss_value = mse_loss_fn(predicted, target)print(f"MSE 预测值: {predicted}")
print(f"MSE 真实值: {target}")
print(f"MSE Loss: {loss_value.item():.4f}")# 手动计算验证
manual_mse = torch.mean((predicted - target)**2)
print(f"手动计算 MSE Loss: {manual_mse.item():.4f}")
- 技术分析:
- 优点: 函数光滑,处处可导,梯度随误差大小线性变化,易于优化,收敛速度快。
- 缺点: 对异常值(Outliers)非常敏感。由于误差是平方项,较大的误差会被放大,导致模型倾向于去拟合异常值,从而影响对大多数正常样本的拟合。
- 联系: 对应于假设误差服从高斯分布时的最大似然估计。
b. 平均绝对误差 (Mean Absolute Error, MAE) / L1 Loss
计算预测值与真实值之差的绝对值的平均值。
L MAE = 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ L_{\text{MAE}} = \frac{1}{N} \sum_{i=1}^N |y_i - \hat{y}_i| L