KAG:通过知识增强生成提升专业领域的大型语言模型(四)
目录
摘要
Abstract
1 信息和知识层次结构
1.1 KG_cs
1.2 KG_fr
1.3 RC
2 kag_merger
3 kag_hybrid_executor
4 kag_output_executor
5 kag_deduce_executor
6 py_code_based_math_executor
总结
摘要
本周对KAG-solver中的知识层次结构和检索策略执行器的代码进行了解读,涵盖了多个组件的配置和实现。知识层次结构分为知识层(KG_cs)、图信息层(KG_fr)和原始块层(RC),三种层次结构用于不同情况的信息检索,检索准确性和逻辑严密程度依次下降,检索效率依次上升。知识合并器用于合并三种层次的知识信息,以方便检索器的检索。检索器除了在三种层次进行混合检索外,还可以进行推理检索执行和基于python的数学执行,并将输出结果转换为用户友好型的输出格式。
Abstract
This week, the code for the knowledge hierarchy and retrieval strategy executor in the KAG-solver was analyzed, covering the configuration and implementation of multiple components. The knowledge hierarchy is divided into three levels: knowledge layer (KG_cs), graph information layer (KG_fr), and raw block layer (RC). These three hierarchies are used for information retrieval in different scenarios, with retrieval accuracy and logical rigor decreasing in that order, while retrieval efficiency increases. The knowledge merger is used to combine knowledge information from all three layers to facilitate the retriever's searches. In addition to conducting mixed retrieval across the three layers, the retriever can also perform inferential retrieval execution and Python-based mathematical execution, converting the output results into a user-friendly output format.
1 信息和知识层次结构
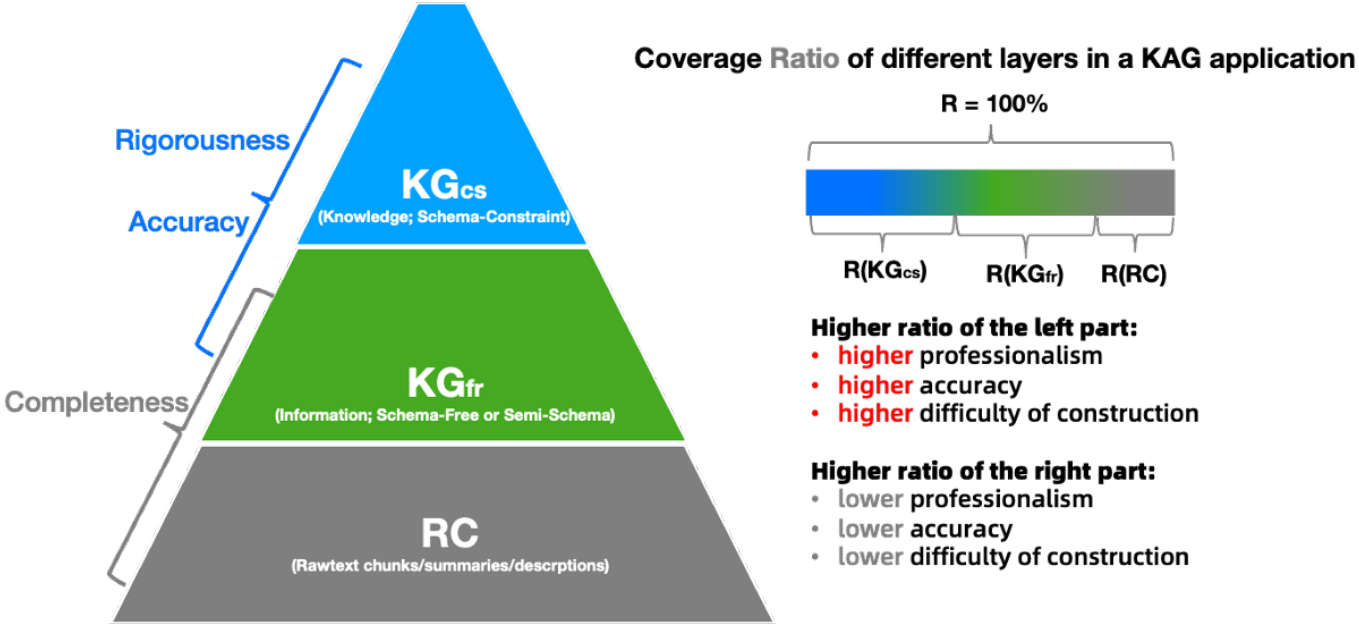
KAG将知识和信息表示分为三个层次:
- 知识层定义为KG_cs(KG Schema-constraint),它代表符合领域模式约束并经过总结、集成和评估的领域知识;
- 图信息层定义为KG_fr(KG schema-free),它代表通过信息提取获得实体和关系等图数据;
- 原始块层定义为RC(Raw Chunks),它代表语义分割后的原始文档块;
并且:
- KG_cs严格遵循SPG语义规范,并支持在严格的模式约束下构建知识体系和定义逻辑规则,SPG要求领域知识必须具有预定义的模式约束,确保了知识的高准确性和逻辑的严密性;然而,这种依赖于人工标注的构建方式,使得其构建成本较高,且信息的完整性有待提高;
- KG_fr与KG_cs共享实体类型、事件类型和概念体系,并为 提供了有效的信息补充;
- KG_fr与RC之间构建的支撑块、摘要和描述边,形成了基于图结构的倒排索引,极大地提高了RC的信息完整性,使其成为KG_fr的有力原始文本上下文补充。
1.1 KG_cs
KG_cs的结构如下:
- 检索组件:kg_cs_open_spg组件用于从封闭语义图谱中检索信息;
- 路径选择策略:使用精确一跳选择exact_one_hop_select策略,确保检索到的实体和关系在知识图谱中直接相连;
- 实体链接配置:在检索过程中进行实体链接,确保识别出的实体符合置信度要求,并排除不需要的实体类型。
kg_cs:type: kg_cs_open_spg # kag/solver/executor/retriever/local_knowledge_base/kag_retriever/kag_component/kg_cs/default_kg_cs_retriever.pypath_select:type: exact_one_hop_select # kag/tools/algorithm_tool/graph_retriever/path_select/exact_one_hop_select.pyentity_linking:type: entity_linking # kag/tools/algorithm_tool/graph_retriever/entity_linking.pyrecognition_threshold: 0.9exclude_types:- Chunkkg_cs_open_spg组件实现如下,从executor_task中获取查询,优先使用rewrite_query,否则使用query,调用self.template.invoke方法执行检索,传入查询、逻辑节点、图数据等参数,并设置is_exact_match为True表示精确匹配:
@FlowComponent.register("kg_cs_open_spg")
class KgConstrainRetrieverWithOpenSPG(KagLogicalFormComponent):def __init__(self,path_select: PathSelect = None,entity_linking=None,llm: LLMClient = None,**kwargs):super().__init__(**kwargs)self.name = kwargs.get("name", "kg_cs")self.llm = llm or LLMClient.from_config(get_default_chat_llm_config())self.path_select = path_select or PathSelect.from_config({"type": "exact_one_hop_select"})if isinstance(entity_linking, dict):entity_linking = EntityLinking.from_config(entity_linking)self.entity_linking = entity_linking or EntityLinking.from_config({"type": "default_entity_linking","recognition_threshold": 0.9,"exclude_types": ["Chunk"],})self.template = KgRetrieverTemplate(path_select=self.path_select,entity_linking=self.entity_linking,llm_module=self.llm,)def invoke(self,cur_task: FlowComponentTask,executor_task: Task,processed_logical_nodes: List[LogicNode],**kwargs) -> List[RetrievedData]:query = executor_task.arguments.get("rewrite_query", executor_task.arguments["query"])return [self.template.invoke(query=query,logic_nodes=[cur_task.logical_node],graph_data=cur_task.graph_data,is_exact_match=True,name=self.name,**kwargs)]其中:
- 参数:
- cur_task:当前任务,包含逻辑节点和图数据;
- executor_task:执行器任务,包含查询和其他参数;
- processed_logical_nodes:已处理的逻辑节点列表。
- 返回值:返回检索到的数据列表。
1.2 KG_fr
KG_fr的结构如下:
- 检索组件:kg_fr_open_spg组件用于从开放语义图谱中检索信息;
- 路径选择策略:
- 使用fuzzy_one_hop_select策略,允许一定程度的模糊匹配;
- 并使用语言模型客户端chat_llm。
- 文本块检索工具:
- 使用ppr_chunk_retriever,基于个性化页面排名(PPR)算法;
- 使用openie_llm作为语言模型客户端。
- 实体链接配置:在检索过程中进行实体链接,确保识别出的实体符合置信度要求,并排除不需要的实体类型。
kg_fr:type: kg_fr_open_spg # kag/solver/executor/retriever/local_knowledge_base/kag_retriever/kag_component/kg_fr/default_kg_fr_retriever.pytop_k: 20path_select:type: fuzzy_one_hop_select # kag/tools/algorithm_tool/graph_retriever/path_select/fuzzy_one_hop_select.pyllm_client: *chat_llmppr_chunk_retriever_tool:type: ppr_chunk_retriever # kag/tools/algorithm_tool/chunk_retriever/ppr_chunk_retriever.pyllm_client: *openie_llmentity_linking:type: entity_linking # kag/tools/algorithm_tool/graph_retriever/entity_linking.pyrecognition_threshold: 0.8exclude_types:- Chunkkg_fr_open_spg组件实现如下,从executor_task中获取查询,优先使用rewrite_query,否则使用query,调用self.template.invoke方法执行知识图谱检索,传入查询、逻辑节点、图数据等参数,生成子查询ppr_sub_query。然后,提取图数据中的实体和关系,执行基于PPR的文本块检索,传入查询、起始实体和顶级结果数量。并记录检索到的文本块数量和更新任务的逻辑节点结果,包括关系、文本块和子查询。如果提供了报告器,添加报告行以记录检索结果。最后,返回检索到的知识图谱数据和文本块数据:
@FlowComponent.register("kg_fr_open_spg")
class KgFreeRetrieverWithOpenSPG(KagLogicalFormComponent):def __init__(self,path_select: PathSelect = None,entity_linking=None,llm: LLMClient = None,ppr_chunk_retriever_tool: ToolABC = None,top_k=10,**kwargs,):super().__init__(**kwargs)self.name = kwargs.get("name", "kg_fr")self.llm = llm or LLMClient.from_config(get_default_chat_llm_config())self.path_select = path_select or PathSelect.from_config({"type": "fuzzy_one_hop_select"})if isinstance(entity_linking, dict):entity_linking = EntityLinking.from_config(entity_linking)self.entity_linking = entity_linking or EntityLinking.from_config({"type": "default_entity_linking","recognition_threshold": 0.8,"exclude_types": ["Chunk"],})self.template = KgRetrieverTemplate(path_select=self.path_select,entity_linking=self.entity_linking,llm_module=self.llm,)self.ppr_chunk_retriever_tool = (ppr_chunk_retriever_toolor PprChunkRetriever.from_config({"type": "ppr_chunk_retriever","llm_client": get_default_chat_llm_config(),}))self.top_k = top_kdef invoke(self,cur_task: FlowComponentTask,executor_task: Task,processed_logical_nodes: List[LogicNode],**kwargs,) -> List[RetrievedData]:reporter: Optional[ReporterABC] = kwargs.get("reporter", None)query = executor_task.arguments.get("rewrite_query", executor_task.arguments["query"])graph_data = self.template.invoke(query=query,logic_nodes=[cur_task.logical_node],graph_data=cur_task.graph_data,name=self.name,**kwargs,)ppr_sub_query = generate_step_query(logical_node=cur_task.logical_node,processed_logical_nodes=processed_logical_nodes,)entities = []selected_rel = []if graph_data is not None:s_entities = graph_data.get_entity_by_alias_without_attr(cur_task.logical_node.s.alias_name)if s_entities:entities.extend(s_entities)o_entities = graph_data.get_entity_by_alias_without_attr(cur_task.logical_node.o.alias_name)if o_entities:entities.extend(o_entities)selected_rel = graph_data.get_all_spo()entities = list(set(entities))ppr_queries = [query, ppr_sub_query]ppr_queries = list(set(ppr_queries))chunks, match_spo = self.ppr_chunk_retriever_tool.invoke(queries=ppr_queries,start_entities=entities,top_k=self.top_k,)logger.info(f"`{query}` Retrieved chunks num: {len(chunks)}")cur_task.logical_node.get_fl_node_result().spo = match_spo + selected_relcur_task.logical_node.get_fl_node_result().chunks = chunkscur_task.logical_node.get_fl_node_result().sub_question = ppr_sub_queryif reporter:reporter.add_report_line(kwargs.get("segment_name", "thinker"),f"begin_sub_kag_retriever_{cur_task.logical_node.sub_query}_{self.name}","","FINISH",component_name=self.name,chunk_num=len(chunks),nodes_num=len(entities),edges_num=len(selected_rel),desc="retrieved_info_digest",)return [graph_data] + chunks其中:
- 参数:
- cur_task:当前任务,包含逻辑节点和图数据;
- executor_task:执行器任务,包含查询和其他参数;
- processed_logical_nodes:已处理的逻辑节点列表。
- 返回值:返回检索到的数据列表,包括知识图谱数据和文本块数据。
1.3 RC
RC的结构如下:
- 检索组件:rc_open_spg组件用于原始文本块检索;
- 向量化工具:
- 使用vector_chunk_retriever,基于向量化的文本嵌入进行检索;
- 并使用向量化模型vectorize_model。
- 结果数量控制:通过top_k参数控制返回的顶级结果数量。
rc:type: rc_open_spg # kag/solver/executor/retriever/local_knowledge_base/kag_retriever/kag_component/rc/default_rc_retriever.pyvector_chunk_retriever:type: vector_chunk_retriever # kag/tools/algorithm_tool/chunk_retriever/vector_chunk_retriever.pyvectorize_model: *vectorize_modelvectorize_model: *vectorize_modeltop_k: 20kg_fr_open_spg组件实现如下,获取查询,优先使用rewrite_query,否则使用query,并生成子查询step_sub_query。使用ThreadPoolExecutor并行计算查询与文本块的相似性分数,合并相似性分数,筛选出最高分的文本块。如果提供了报告器,添加报告行以记录检索结果。最后返回检索到的文本块数据:
@FlowComponent.register("rc_open_spg")
class RCRetrieverOnOpenSPG(KagLogicalFormComponent):def __init__(self,top_k=10,vector_chunk_retriever: VectorChunkRetriever = None,vectorize_model: VectorizeModelABC = None,search_api: SearchApiABC = None,graph_api: GraphApiABC = None,**kwargs,):super().__init__(**kwargs)self.name = kwargs.get("name", "kg_rc")self.top_k = top_kself.vectorize_model = vectorize_model or VectorizeModelABC.from_config(KAG_CONFIG.all_config["vectorize_model"])self.text_similarity = TextSimilarity(vectorize_model)self.search_api = search_api or SearchApiABC.from_config({"type": "openspg_search_api"})self.graph_api = graph_api or GraphApiABC.from_config({"type": "openspg_graph_api"})self.vector_chunk_retriever = vector_chunk_retriever or VectorChunkRetriever(vectorize_model=self.vectorize_model, search_api=self.search_api)self.schema_helper: SchemaUtils = SchemaUtils(LogicFormConfiguration({"KAG_PROJECT_ID": KAG_PROJECT_CONF.project_id,"KAG_PROJECT_HOST_ADDR": KAG_PROJECT_CONF.host_addr,}))def recall_query(self, query):sim_scores_start_time = time.time()"""Process a single query for similarity scores in parallel."""query_sim_scores = self.vector_chunk_retriever.invoke(query, self.top_k * 20)logger.info(f"`{query}` Similarity scores calculation completed in {time.time() - sim_scores_start_time:.2f} seconds.")return query_sim_scoresdef invoke(self,cur_task: FlowComponentTask,executor_task: Task,processed_logical_nodes: List[LogicNode],**kwargs,) -> List[ChunkData]:segment_name = kwargs.get("segment_name", "thinker")component_name = self.namereporter: Optional[ReporterABC] = kwargs.get("reporter", None)query = executor_task.arguments.get("rewrite_query", executor_task.arguments["query"])logical_node = cur_task.logical_nodestep_sub_query = generate_step_query(logical_node=logical_node, processed_logical_nodes=processed_logical_nodes)dpr_queries = [query, step_sub_query]dpr_queries = list(set(dpr_queries))if reporter:reporter.add_report_line(segment_name,f"begin_sub_kag_retriever_{cur_task.logical_node.sub_query}_{component_name}",cur_task.logical_node.sub_query,"INIT",component_name=component_name,)sim_scores = {}doc_maps = {}with ThreadPoolExecutor() as executor:sim_result = list(executor.map(self.recall_query, dpr_queries))for query_sim_scores in sim_result:for doc_id, node in query_sim_scores.items():doc_maps[doc_id] = nodescore = node["score"]if doc_id not in sim_scores:sim_scores[doc_id] = scoreelif score > sim_scores[doc_id]:sim_scores[doc_id] = scoresorted_scores = sorted(sim_scores.items(), key=lambda item: item[1], reverse=True)matched_chunks = []for doc_id, doc_score in sorted_scores:matched_chunks.append(ChunkData(content=doc_maps[doc_id]["content"].replace("_split_0", ""),title=doc_maps[doc_id]["name"].replace("_split_0", ""),chunk_id=doc_id,score=doc_score,))if reporter:reporter.add_report_line(segment_name,f"begin_sub_kag_retriever_{cur_task.logical_node.sub_query}_{component_name}","","FINISH",component_name=component_name,chunk_num=min(len(matched_chunks), self.top_k),desc="retrieved_doc_digest",)return matched_chunksdef is_break(self):return self.break_flagdef break_judge(self, cur_task: FlowComponentTask, **kwargs):cur_task.break_flag = False其中:
- 参数:
- cur_task:当前任务,包含逻辑节点和图数据;
- executor_task:执行器任务,包含查询和其他参数;
- processed_logical_nodes:已处理的逻辑节点列表。
- 返回值:返回检索到的文本块数据列表。
2 kag_merger
kag_merger用于合并来自不同来源的检索结果,其中:
- kg_merger:用于合并来自不同来源的知识图谱数据;
- top_k:合并后的结果取前20个;
- 使用chat_llm作为语言模型模块,辅助合并和生成摘要;
- 使用default_thought_then_answer提示模板生成摘要;
- 使用指定的向量化模型进行文本嵌入;
kag_merger:type: kg_merger # kag/solver/executor/retriever/local_knowledge_base/kag_retriever/kag_component/kag_merger.pytop_k: 20llm_module: *chat_llmsummary_prompt:type: default_thought_then_answer # kag/solver/prompt/thought_then_answer.pyvectorize_model: *vectorize_modelkg_merger的实现如下,从每个输入组件中获取文本块及其分数,合并来自不同组件的文本块分数,并按分数排序并限制返回结果的数量。再更新任务的逻辑节点结果,包括合并后的文本块。如果提供了报告器,添加报告行以记录合并结果。最后生成摘要,如果未生成摘要则调用语言模型生成:
@FlowComponent.register("kg_merger")
class KagMerger(FlowComponent):def __init__(self,top_k,llm_module: LLMClient = None,summary_prompt: PromptABC = None,vectorize_model: VectorizeModelABC = None,**kwargs,):super().__init__(**kwargs)self.name = "kag_merger"self.top_k = top_kself.llm_module = llm_module or LLMClient.from_config(get_default_chat_llm_config())self.summary_prompt = summary_prompt or init_prompt_with_fallback("thought_then_answer", KAG_PROJECT_CONF.biz_scene)self.vectorize_model = vectorize_model or VectorizeModelABC.from_config(KAG_CONFIG.all_config["vectorize_model"])self.text_similarity = TextSimilarity(vectorize_model)def invoke(self,cur_task: FlowComponentTask,executor_task: Task,processed_logical_nodes: List[LogicNode],input_components: List[FlowComponentTask],**kwargs,) -> List[RetrievedData]:component_chunk_scores = []chunk_id_map = {}for component in input_components:chunks = get_chunks(component.result)chunk_scores = {}for c in chunks:chunk_id_map[c.chunk_id] = cchunk_scores[c.chunk_id] = c.scorecomponent_chunk_scores.append(chunk_scores)merged_docs = component_chunk_scores[0]for i in range(1, len(component_chunk_scores)):merged_docs = weightd_merge(chunk1=merged_docs, chunk2=component_chunk_scores[i], alpha=0.5)sorted_scores = sorted(merged_docs.items(), key=lambda item: item[1], reverse=True)merged_chunks = []for doc_id, score in sorted_scores:c = chunk_id_map[doc_id]c.score = scoremerged_chunks.append(c)limited_merged_chunks = merged_chunks[: self.top_k]cur_task.logical_node.get_fl_node_result().chunks = limited_merged_chunksreporter: Optional[ReporterABC] = kwargs.get("reporter", None)if reporter:reporter.add_report_line(kwargs.get("segment_name", "thinker"),f"begin_sub_kag_retriever_{cur_task.logical_node.sub_query}_{self.name}","","FINISH",component_name=self.name,chunk_num=len(limited_merged_chunks),desc=("kag_merger_digest"if len(limited_merged_chunks) > 0else "kag_merger_digest_failed"),)# summaryformatted_docs = []for doc in limited_merged_chunks:formatted_docs.append(f"{doc.content}")if len(formatted_docs) == 0:selected_rel = list(set(cur_task.graph_data.get_all_spo()))formatted_docs = [str(rel) for rel in selected_rel]deps_context = format_task_dep_context(executor_task.parents)if not cur_task.logical_node.get_fl_node_result().summary:summary_query = generate_step_query(logical_node=cur_task.logical_node,processed_logical_nodes=processed_logical_nodes,start_index=len(deps_context),)summary_response = self.llm_module.invoke({"cur_question": summary_query,"questions": "\n\n".join(deps_context),"docs": "\n\n".join(formatted_docs),},self.summary_prompt,with_json_parse=False,with_except=True,tag_name=f"begin_summary_{cur_task.logical_node.sub_query}_{self.name}",**kwargs,)cur_task.logical_node.get_fl_node_result().summary = summary_responsereturn limited_merged_chunks其中:
- 参数:
- cur_task:当前任务,包含逻辑节点和图数据;
- executor_task:执行器任务,包含查询和其他参数;
- processed_logical_nodes:已处理的逻辑节点列表;
-
input_components:输入组件列表,包含每个组件的检索结果。
- 返回值:返回合并后的检索结果列表。
3 kag_hybrid_executor
kag_hybrid_executor用于执行混合检索策略,结合了KG_cs、KG_fr和RC的检索结果,其中:
- type:使用kag_hybrid_executor混合检索的执行器;
- lf_rewriter:定义了逻辑形式重写器的配置:
- type:使用kag_spo_lf逻辑形式重写器;
- llm_client:使用的语言模型客户端;
- lf_trans_prompt:使用default_spo_retriever_decompose提示模板进行逻辑形式转换。
- flow:定义了数据处理流程:
- kg_cs->kg_fr->kag_merger:数据先经过KG_cs,然后传递给KG_fr,最后合并结果到kag_merger;
- rc->kag_merger:RC的结果直接传递给kag_merger。
kag_hybrid_executor: &kag_hybrid_executor_conftype: kag_hybrid_executor # kag/solver/executor/retriever/local_knowledge_base/kag_retriever/kag_hybrid_executor.pylf_rewriter:type: kag_spo_lf # kag/solver/executor/retriever/local_knowledge_base/kag_retriever/kag_component/kag_lf_rewriter.pyllm_client: *openie_llmlf_trans_prompt:type: default_spo_retriever_decompose # kag/solver/prompt/spo_retriever_decompose_prompt.pyvectorize_model: *vectorize_modelflow: |kg_cs->kg_fr->kag_merger;rc->kag_mergerkag_hybrid_executor的代码实现如下。
混合知识图检索执行程序,结合多种策略。并使用知识图谱和 LLM 功能将实体链接、路径选择和文本块检索相结合,以回答复杂的查询:
@ExecutorABC.register("kag_hybrid_executor")
class KagHybridExecutor(ExecutorABC):def __init__(self, flow, lf_rewriter: KAGLFRewriter, llm_module: LLMClient = None, **kwargs):super().__init__(**kwargs)self.lf_rewriter: KAGLFRewriter = lf_rewriterself.flow_str = flowself.solve_question_without_spo_prompt = init_prompt_with_fallback("summary_question", KAG_PROJECT_CONF.biz_scene)self.llm_module = llm_module or LLMClient.from_config(get_default_chat_llm_config())self.flow: KAGFlow = KAGFlow(flow_str=self.flow_str,)@propertydef output_types(self):"""执行程序响应的输出类型规范"""return KAGRetrievedResponsegenerate_answer用于根据给定的问题、知识图谱、文档和历史记录生成子答案:
- 参数:
- question (str):要回答的主要问题;
- knowledge_graph (list):知识图谱数据列表;
- docs (list):与问题相关的文档列表;
- history (list, optional):以前的查询-答案对的列表。默认为空列表。
- 返回:
- str:生成的 sub-answer。
@retry(stop=stop_after_attempt(3))def generate_answer(self, tag_id, question: str, docs: [], history_qa=[], **kwargs):prompt = self.solve_question_without_spo_promptparams = {"question": question,"docs": [str(d) for d in docs],"history": "\n".join(history_qa),}llm_output = self.llm_module.invoke(params,prompt,with_json_parse=False,with_except=True,tag_name=f"kag_hybrid_retriever_summary_{question}",segment_name=tag_id,**kwargs,)logger.debug(f"sub_question:{question}\n sub_answer:{llm_output} prompt:\n{prompt}")if llm_output:return llm_outputreturn "I don't know"def generate_summary(self, tag_id, query, chunks, history, **kwargs):history_qa = get_history_qa(history)if len(history) == 1 and len(history_qa) == 1:return history[0].get_fl_node_result().summaryreturn self.generate_answer(tag_id=tag_id, question=query, docs=chunks, history_qa=history_qa, **kwargs)invoke执行混合知识图谱检索,首先,初始化响应容器;再将查询转换为逻辑形式;然后创建KAGFlow对象,执行KAGFlow工作流;最后生成摘要并存储结果:
def invoke(self, query: str, task: Any, context: Context, **kwargs):reporter: Optional[ReporterABC] = kwargs.get("reporter", None)task_query = task.arguments["query"]logic_node = task.arguments.get("logic_form_node", None)logger.info(f"{task_query} begin kag hybrid executor")# 1. 初始化响应容器logger.info(f"Initializing response container for task: {task_query}")start_time = time.time() # 添加开始时间记录kag_response = initialize_response(task)tag_id = f"{task_query}_begin_task"flow_query = logic_node.sub_query if logic_node else task_querytry:logger.info(f"Response container initialized in {time.time() - start_time:.2f} seconds for task: {task_query}")# 2. 将查询转换为逻辑形式logger.info(f"Converting query to logical form for task: {task_query}")start_time = time.time() # 添加开始时间记录self.report_content(reporter,"thinker",tag_id,f"{flow_query}\n","INIT",step=task.name,)if not logic_node:logic_nodes = self._convert_to_logical_form(flow_query, task, reporter=reporter)else:logic_nodes = [logic_node]logger.info(f"Query converted to logical form in {time.time() - start_time:.2f} seconds for task: {task_query}")# 3. 创建KAGFlow对象logger.info(f"Creating KAGFlow for task: {task_query}")start_time = time.time()logger.info(f"KAGFlow created in {time.time() - start_time:.2f} seconds for task: {task_query}")# 4. 执行KAGFlowlogger.info(f"Executing KAGFlow for task: {task_query}")start_time = time.time()graph_data, retrieved_datas = self.flow.execute(flow_id=task.id,nl_query=flow_query,lf_nodes=logic_nodes,executor_task=task,reporter=reporter,segment_name=tag_id,)kag_response.graph_data = graph_dataif graph_data:context.variables_graph.merge_kg_graph(graph_data)kag_response.chunk_datas = retrieved_dataslogger.info(f"KAGFlow executed in {time.time() - start_time:.2f} seconds for task: {task_query}")self.report_content(reporter,"reference",f"{task_query}_kag_retriever_result",kag_response,"FINISH",)# 5. 处理逻辑节点结果logger.info(f"Processing logic nodes for task: {task_query}")start_time = time.time() # 添加开始时间记录for lf_node in logic_nodes:kag_response.sub_retrieved_set.append(lf_node.get_fl_node_result())logger.info(f"Logic nodes processed in {time.time() - start_time:.2f} seconds for task: {task_query}")kag_response.summary = self.generate_summary(tag_id=tag_id,query=task_query,chunks=kag_response.get_chunk_list(),history=logic_nodes,**kwargs,)logger.info(f"Summary Question {task_query} : {kag_response.summary}")# 6. 最终存储logger.info(f"Storing results for task: {task_query}")if logic_node and isinstance(logic_node, GetSPONode):context.variables_graph.add_answered_alias(logic_node.s.alias_name.alias_name, kag_response.summary)context.variables_graph.add_answered_alias(logic_node.p.alias_name.alias_name, kag_response.summary)context.variables_graph.add_answered_alias(logic_node.o.alias_name.alias_name, kag_response.summary)start_time = time.time() # 添加开始时间记录store_results(task, kag_response)logger.info(f"Results stored in {time.time() - start_time:.2f} seconds for task: {task_query}")logger.info(f"Completed storing results for task: {task_query}")self.report_content(reporter,"thinker",tag_id,"","FINISH",step=task.name,overwrite=False,)except Exception as e:logger.warning(f"{self.schema().get('name')} executed failed {e}", exc_info=True)store_results(task, kag_response)self.report_content(reporter,"thinker",tag_id,f"{self.schema().get('name')} executed failed {e}","ERROR",step=task.name,overwrite=False,)logger.info(f"Exception occurred for task: {task_query}, error: {e}")raise eschema为OpenAI函数调用的函数架构定义,返回OpenAI函数格式的Schema定义:
def schema(self) -> dict:return {"name": "Retriever","description": "Retrieve relevant knowledge from the local knowledge base.","parameters": {"query": {"type": "string","description": "User-provided query for retrieval.","optional": False,},},}
4 kag_output_executor
kag_output_executor为输出执行器,用于将知识图谱检索的结果转换为用户友好的输出格式:
@ExecutorABC.register("kag_output_executor")
class KagOutputExecutor(ExecutorABC):def __init__(self, llm_module: LLMClient = None, summary_prompt: PromptABC = None, **kwargs):super().__init__(**kwargs)self.llm_module = llm_module or LLMClient.from_config(get_default_chat_llm_config())self.summary_prompt = summary_prompt or init_prompt_with_fallback("output_question", KAG_PROJECT_CONF.biz_scene)@propertydef output_types(self):return strinvoke执行输出转换,首先获取逻辑节点的别名,并从上下文中检索答案;如果没有找到答案,使用语言模型生成答案,最后更新任务结果:
def invoke(self, query: str, task: Any, context: Context, **kwargs):reporter: Optional[ReporterABC] = kwargs.get("reporter", None)task_query = task.arguments["query"]logic_node = task.arguments.get("logic_form_node", None)self.report_content(reporter,"thinker",f"{task_query}_begin_task",f"{task_query}\n","INIT",step=task.name,)if not logic_node or not isinstance(logic_node, GetNode):self.report_content(reporter,"thinker",f"{task_query}_begin_task","not implement!","FINISH",overwrite=False,step=task.name,)returnresult = []for alias in logic_node.alias_name_set:if context.variables_graph.has_alias(alias.alias_name):result.append(context.variables_graph.get_answered_alias(alias.alias_name))if not result:dep_context = []for p in task.parents:dep_context.append(p.get_task_context())result = self.llm_module.invoke({"question": query, "context": dep_context},self.summary_prompt,with_json_parse=False,segment_name=f"{task_query}_begin_task",tag_name=f"{task_query}_output",**kwargs,)self.report_content(reporter,"thinker",f"{task_query}_begin_task","","FINISH",overwrite=False,step=task.name,)task.update_result(result)5 kag_deduce_executor
kag_deduce_executor为推理执行器,用于执行推理任务,使用知识图谱和 LLM 功能将实体链接、路径选择和文本块检索相结合,以回答复杂的查询:
@ExecutorABC.register("kag_deduce_executor")
class KagDeduceExecutor(ExecutorABC):def __init__(self,llm_module: LLMClient = None,deduce_choice_prompt: PromptABC = None,deduce_entail_prompt: PromptABC = None,deduce_extractor_prompt: PromptABC = None,deduce_judge_prompt: PromptABC = None,deduce_multi_choice_prompt: PromptABC = None,**kwargs,):super().__init__(**kwargs)self.llm_module = llm_module or LLMClient.from_config(get_default_chat_llm_config())self.deduce_choice_prompt = deduce_choice_prompt or init_prompt_with_fallback("deduce_choice", KAG_PROJECT_CONF.biz_scene)self.deduce_entail_prompt = deduce_entail_prompt or init_prompt_with_fallback("deduce_entail", KAG_PROJECT_CONF.biz_scene)self.deduce_extractor_prompt = (deduce_extractor_promptor init_prompt_with_fallback("deduce_extractor", KAG_PROJECT_CONF.biz_scene))self.deduce_judge_prompt = deduce_judge_prompt or init_prompt_with_fallback("deduce_judge", KAG_PROJECT_CONF.biz_scene)self.deduce_multi_choice_prompt = (deduce_multi_choice_promptor init_prompt_with_fallback("deduce_multi_choice", KAG_PROJECT_CONF.biz_scene))self.prompt_mapping = {"choice": self.deduce_choice_prompt,"multiChoice": self.deduce_multi_choice_prompt,"entailment": self.deduce_entail_prompt,"judgement": self.deduce_judge_prompt,"extract": self.deduce_extractor_prompt,}其中包含多种prompt,例如选择题、蕴含推理、信息提取、判断、多选题等prompt。
invoke来执行推理任务,首先,获取逻辑节点的内容和目标,提取内容中的参数并替换为知识图谱中的实际值,然后对每个操作类型调用方法,执行推理;最后,将结果存储在上下文中并更新任务结果:
def invoke(self, query: str, task: Any, context: Context, **kwargs):reporter: Optional[ReporterABC] = kwargs.get("reporter", None)tag_id = f"{task.arguments['query']}_begin_task"task_query = task.arguments.get("rewrite_query", task.arguments["query"])logic_node = task.arguments.get("logic_form_node", None)self.report_content(reporter,"thinker",tag_id,f"{task_query}\n","INIT",step=task.name,)if not logic_node or not isinstance(logic_node, DeduceNode):self.report_content(reporter,tag_id,f"{task_query}_deduce","not implement!","FINISH",step=task.name,overwrite=False,)returndeduce_query = f"{logic_node.sub_query}\ntarget:{logic_node.target}"kg_graph = context.variables_graphcontent = logic_node.contenttry:content_l = re.findall("`(.*?)`", content)except Exception as e:# breakpoint()content_l = []contents = []for c in content_l:if kg_graph.has_alias(c):values = kg_graph.get_answered_alias(c)if values:c = f"{c}={str(values)}"else:continuecontents.append(c)contents = "input params:\n" + "\n".join(contents) if contents else ""result = []final_if_answered = Falsefor op in logic_node.ops:if_answered, answer = self.call_op(deduce_query, contents, op, segment_name=tag_id, **kwargs)result.append(answer)final_if_answered = if_answered or final_if_answeredres = ";".join(result)context.variables_graph.add_answered_alias(logic_node.alias_name, f"{task_query}\n{res}")task.update_result(res)self.report_content(reporter,"thinker",tag_id,"","FINISH",step=task.name,overwrite=False,)6 py_code_based_math_executor
py_code_based_math_executor为数学执行器,用于执行基于python代码的数学计算。使用语言模型客户端,用于生成 Python 代码,并设置重试次数,默认为 3 次:
@ExecutorABC.register("py_code_based_math_executor")
class PyBasedMathExecutor(ExecutorABC):def __init__(self, llm: LLMClient, tries: int = 3, **kwargs):super().__init__(**kwargs)self.llm = llmself.tries = triesself.expression_builder = init_prompt_with_fallback("expression_builder", KAG_PROJECT_CONF.biz_scene)def run_once(self, query: str, context: str, error: str, **kwargs):python_code = self.gen_py_code(query, context, error, **kwargs)if not python_code:raise RuntimeError("python code generate failed")code_result = run_py_code(python_code, **kwargs)return code_resultgen_py_code:根据查询、上下文和错误生成Python代码:
@retry(stop=stop_after_attempt(3), reraise=True)def gen_py_code(self, query: str, context: str, error: str, **kwargs):return self.llm.invoke({"question": query,"context": context,"error": error,},self.expression_builder,with_json_parse=False,**kwargs,)invoke执行查询、生成和运行python代码,处理结果或错误。 首先,获取逻辑节点的内容和目标,并提取内容中的参数并替换为知识图谱中的实际值;再生成 Python 代码并执行,如果执行成功,更新任务结果并存储在上下文中,如果执行失败,记录错误信息并重试:
def invoke(self, query: str, task: Task, context: Context, **kwargs):reporter: Optional[ReporterABC] = kwargs.get("reporter", None)logic_node = task.arguments.get("logic_form_node", None)tag_id = f"{task.arguments['query']}_begin_task"task_query = task.arguments.get("rewrite_query", task.arguments["query"])if logic_node and isinstance(logic_node, MathNode):kg_graph = context.variables_graphcontent = logic_node.contenttry:content_l = re.findall("`(.*?)`", content)except Exception as e:# breakpoint()content_l = []contents = []for c in content_l:if kg_graph.has_alias(c):values = kg_graph.get_answered_alias(c)if values:c = f"{c}={values}"else:continuecontents.append(c)contents = "input params:\n" + "\n".join(contents) if contents else ""math_query = f"{logic_node.sub_query}\n target:{logic_node.target}"else:contents = ""math_query = task_queryself.report_content(reporter,"thinker",tag_id,f"{task_query}\n","INIT",step=task.name,)parent_results = format_task_dep_context(task.parents)parent_results = "\n".join(parent_results)parent_results += "\n\n" + contentstries = self.trieserror = Nonewhile tries > 0:tries -= 1rst, error, code = self.run_once(math_query,parent_results,error,segment_name=tag_id,tag_name=f"{task_query}_code_generator",**kwargs,)if rst is not None:if "i don't know" not in rst.lower():result = f"""```python
{code}
```
code result:{logic_node.alias_name}={rst}"""task.update_result(result)self.report_content(reporter,tag_id,f"{task_query}_end_math_executor_{task.id}",rst,"FINISH",)self.report_content(reporter,"thinker",tag_id,"","FINISH",step=task.name,overwrite=False,)if logic_node and isinstance(logic_node, MathNode):context.variables_graph.add_answered_alias(logic_node.alias_name, rst)return resultif tries > 0:error = f"Please retry with: Best-effort code generation using analogous implementations or educated-guess fallbacks where needed."else:error = rsterror = f"""code:
```python
{code}
```
error:
{error}"""context.variables_graph.add_answered_alias(logic_node.alias_name, error)task.update_result(error)self.report_content(reporter,f"{task_query}_begin_task",f"{task_query}_end_math_executor_{task.id}",error,"FINISH",)self.report_content(reporter,"thinker",f"{task_query}_begin_task","","FINISH",step=task.name,overwrite=False,)总结
本周的工作重点是对KAG_solver中知识层次结构和检索执行器相关代码的解读,涵盖了从封闭语义图谱(KG_cs)、开放语义图谱(KG_fr)到原始文本块(RC)的多种检索策略,以及结果合并和推理执行。通过结合封闭语义图谱、开放语义图谱和原始文本块,确保了检索结果的全面性和准确性。还拥有灵活的检索策略,支持精确匹配和模糊匹配,适应不同场景的需求。通过知识图谱合并和推理执行器,提高了结果的相关性和可信度。还支持基于 Python 代码的数学计算,增强系统的计算能力。
下周继续对KAG_solver中问题规划、结果推理、答案生成、迭代求解等相关代码进行进一步学习解读。