《深度学习实践教程》[吴微] ch-5 3/5层全连接神经网络
一、练习课本上3层全连接神经网络识别手写数字。

答案代码:
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 定义一些超参数
batch_size = 64
learning_rate = 0.02class Batch_Net(nn.Module):"""在上面的Activation_Net的基础上,增加了一个加快收敛速度的方法——批标准化"""def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):super(Batch_Net, self).__init__()self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.BatchNorm1d(n_hidden_1), nn.ReLU(True))self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.BatchNorm1d(n_hidden_2), nn.ReLU(True))self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))def forward(self, x):x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)return x# 数据预处理。transforms.ToTensor()将图片转换成PyTorch中处理的对象Tensor,并且进行标准化(数据在0~1之间)
# transforms.Normalize()做归一化。它进行了减均值,再除以标准差。两个参数分别是均值和标准差
# transforms.Compose()函数则是将各种预处理的操作组合到了一起
data_tf = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5])])# 数据集的下载器
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_tf, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_tf)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 选择模型
#model = net.simpleNet(28 * 28, 300, 100, 10)
# model = Activation_Net(28 * 28, 300, 100, 10)
model = Batch_Net(28 * 28, 300, 100, 10)
#if torch.cuda.is_available():# model = model.cuda()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)# 训练模型
epoch = 0
for data in train_loader:img, label = dataimg = img.view(img.size(0), -1)if torch.cuda.is_available():img = img.cuda()label = label.cuda()else:img = Variable(img)label = Variable(label)out = model(img)loss = criterion(out, label)print_loss = loss.data.item()optimizer.zero_grad()loss.backward()optimizer.step()epoch+=1if epoch%100 == 0:print('epoch: {}, loss: {:.4}'.format(epoch, loss.data.item()))# 模型评估
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:img, label = dataimg = img.view(img.size(0), -1)if torch.cuda.is_available():img = img.cuda()label = label.cuda()out = model(img)loss = criterion(out, label)eval_loss += loss.data.item()*label.size(0)_, pred = torch.max(out, 1)num_correct = (pred == label).sum()eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(test_dataset)),eval_acc / (len(test_dataset))
))运行结果:

……
二、课后练习
设计一个5层全连接神经网络,实现给MNIST数据集的分类,其中:
batch_size = 32, learning_rate = 0.01, epochs = 100, input_size = 28*28,
hidden_size1 = 400, hidden_size2 = 300, hideen_size3 = 200, hidden_size4 = 100.
隐藏层中要带有激励函数ReLU()和批标准化函数。
答案代码:
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 定义一些超参数
batch_size = 32
learning_rate = 0.01class Batch_Net(nn.Module):"""在上面的Activation_Net的基础上,增加了一个加快收敛速度的方法——批标准化"""def __init__(self, in_dim, n_hidden_1, n_hidden_2, n_hidden_3, n_hidden_4,out_dim):super(Batch_Net, self).__init__()self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.BatchNorm1d(n_hidden_1), nn.ReLU(True))self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.BatchNorm1d(n_hidden_2), nn.ReLU(True))self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, n_hidden_3), nn.BatchNorm1d(n_hidden_3), nn.ReLU(True))self.layer4 = nn.Sequential(nn.Linear(n_hidden_3, n_hidden_4), nn.BatchNorm1d(n_hidden_4), nn.ReLU(True))self.layer5 = nn.Sequential(nn.Linear(n_hidden_4, out_dim))def forward(self, x):x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.layer5(x)return x# 数据预处理。transforms.ToTensor()将图片转换成PyTorch中处理的对象Tensor,并且进行标准化(数据在0~1之间)
# transforms.Normalize()做归一化。它进行了减均值,再除以标准差。两个参数分别是均值和标准差
# transforms.Compose()函数则是将各种预处理的操作组合到了一起
data_tf = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5])])# 数据集的下载器
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_tf, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_tf)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 选择模型
#model = net.simpleNet(28 * 28, 300, 100, 10)
# model = Activation_Net(28 * 28, 300, 100, 10)
model = Batch_Net(28 * 28, 400, 300,200, 100, 10)
#if torch.cuda.is_available():# model = model.cuda()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)# 训练模型
epoch = 0
for data in train_loader:img, label = dataimg = img.view(img.size(0), -1)if torch.cuda.is_available():img = img.cuda()label = label.cuda()else:img = Variable(img)label = Variable(label)out = model(img)loss = criterion(out, label)print_loss = loss.data.item()optimizer.zero_grad()loss.backward()optimizer.step()epoch+=1if epoch%100 == 0:print('epoch: {}, loss: {:.4}'.format(epoch, loss.data.item()))# 模型评估
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:img, label = dataimg = img.view(img.size(0), -1)if torch.cuda.is_available():img = img.cuda()label = label.cuda()out = model(img)loss = criterion(out, label)eval_loss += loss.data.item()*label.size(0)_, pred = torch.max(out, 1)num_correct = (pred == label).sum()eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(test_dataset)),eval_acc / (len(test_dataset))
))运行结果:
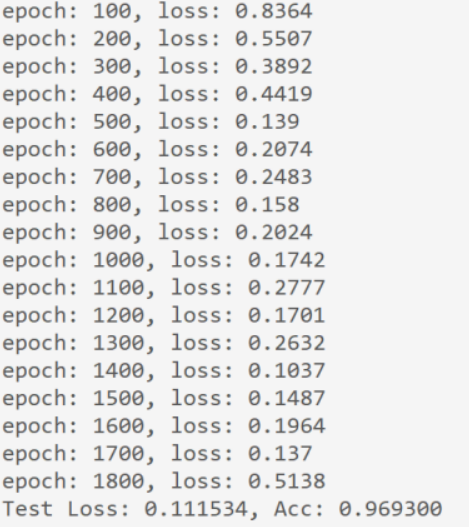
从程序运行结果来看,loss为0.111534,准确率为96.93%。
声明:文章仅供学习使用。著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。