【T2I】PLACE: Adaptive Layout-Semantic Fusion for Semantic Image Synthesis
CODE: CVPR 2024
cszy98/PLACE: [CVPR 2024 Highlight] PLACE: Adaptive Layout-Semantic Fusion for Semantic Image Synthesis
Abstract
近年来,大规模预训练文本图像模型的发展使语义图像合成取得了显著进展。然而,合成具有一致语义和布局的高质量图像仍然是一个挑战。在本文中,我们提出了自适应布局语义融合模块(PLACE),它利用预先训练的模型来缓解上述问题。具体来说,我们首先使用布局控制映射来忠实地表示特征空间中的布局。随后,我们以时间步长自适应的方式将布局和语义特征结合起来,合成具有真实细节的图像。在微调过程中,我们提出了语义对齐(SA)损失来进一步增强布局对齐。此外,我们引入了无布局先验保存(LFP)损失,它利用未标记的数据来保持预训练模型的先验,从而提高合成图像的视觉质量和语义一致性。大量的实验表明,我们的方法在视觉质量、语义一致性和布局对齐方面表现良好。
Introduction
语义图像合成旨在生成与给定语义图对齐的高质量图像。它为用户提供了使用语义地图精确控制合成图像空间布局的灵活性,同时在内容创建[5,6,50],图像编辑[17,18,22]和数据增强[46]中具有重要应用。
大规模文本到图像模型[27,28,30]在开放词汇文本提示下显示出高质量和多样化的生成结果。基于这些预训练的文本到图像模型(如Stable Diffusion), ControlNet和T2I - adapter引入了一个额外的适配器来注入布局指导,以实现高质量的语义图像合成。然而,这些适配器未能准确地将文本语义与相应区域进行整合,导致生成的结果布局不一致,如图图所示。

为了促进布局的一致性,FreestyleNet提出了一个RCA模块,该模块强制每个中间图像令牌关注各自的文本语义,同时使用RCA对扩散模型进行微调。然而,RCA中使用的语义图是直接适应潜伏扩散中的中间图像特征的,这比其原始尺寸要小得多(例如,与512×512相比为64 × 64),导致不可避免的布局信息丢失。此外,RCA机制破坏了图像和文本令牌之间的全局交互,阻碍了高质量图像的合成。
为了缓解上述问题,提出了自适应布局语义融合模块(称为PLACE),如图图所示,它利用预训练的稳定扩散进行高质量和忠实的语义图像合成。首先,受空间文本表示[1]的启发,我们引入了在低分辨率特征空间中忠实地表示布局信息的布局控制图(LCM)。具体而言,在中间图像特征中探索每个图像标记的感受野内每个语义成分的比例,并利用由这些比例组成的向量作为该图像标记的布局特征。该布局控制图将布局信息准确地保留在特征空间中,然后与文本特征结合,指导语义图像的合成。
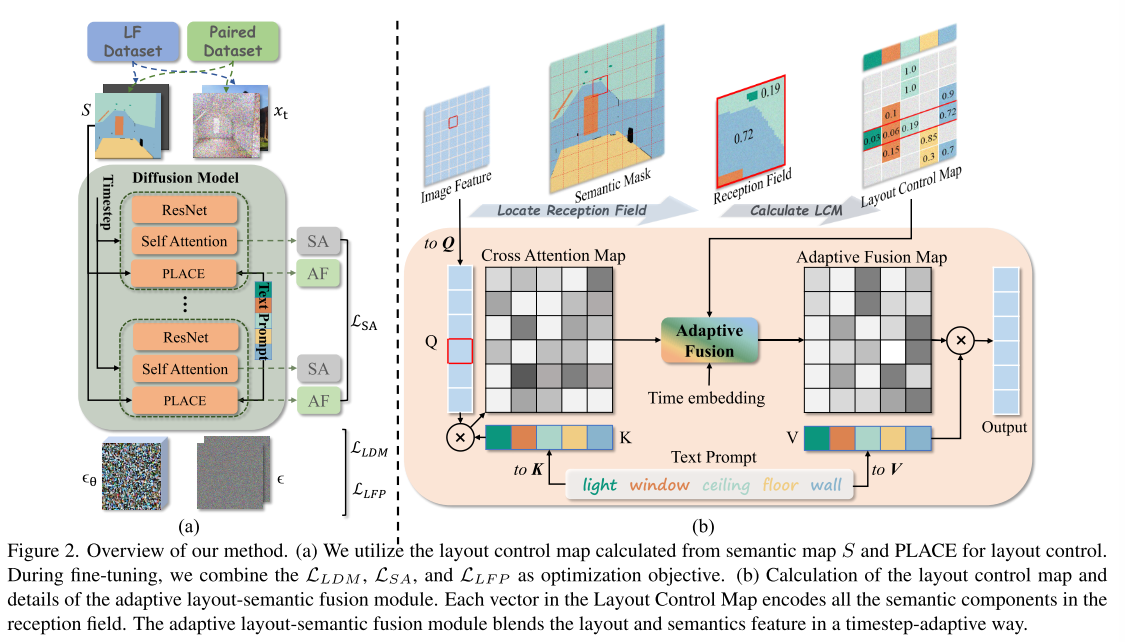
使用布局控制图手动约束受每个语义组件影响的区域,允许对合成图像的布局进行操作。然而,我们注意到它也限制了图像标记和全局文本标记之间的交互,影响了合成细节的视觉质量。为了有效地集成布局控制图,同时保留有益的交互以获得更好的视觉质量,我们开发了一个时间步适应布局语义融合模块。具体来说,对于每个融合模块,从时间嵌入中学习一个自适应的融合参数。随后,利用该参数自适应地将我们的布局控制映射与封装全局语义的原始交叉注意映射结合起来。由此产生的自适应融合地图不仅包含忠实的布局信息,而且保持上下文文本标记的影响,从而提高生成图像的视觉质量。
此外,我们提出了有效的语义对齐(SA)损失和无布局先验保存损失来促进微调。SA损失约束了自适应融合图和自注意图的加权聚合结果尽可能接近原自适应融合图。它增强了相同或相关语义区域内图像标记的内部交互,从而提高了布局的一致性和视觉质量。由于数据集的规模有限,预训练模型的先验在微调时容易受到扰动。我们提出的LFP损失有助于在微调期间不涉及布局注释的情况下保留先验。具体来说,我们使用文本-图像对以无布局的方式计算去噪损失,以保留嵌入在预训练模型中的语义概念。由于增强了语义先验的保存和利用,即使在新的领域,我们的方法也表现出更好的视觉质量和语义一致性(如图图所示)。
贡献:
• 引入布局控制图作为可靠的布局表示,提出自适应布局-语义融合模块,自适应集成布局和语义特征,实现语义图像合成。
• 提出了有效的SA和LFP损失。前者增强了生成图像的布局一致性,而后者有助于保留具有现成文本-图像对的预训练模型的语义先验。
Related Work
Semantic Image Synthesis
语义图像合成的目的是在给定的语义掩模下合成真实的图像。以往的工作主要是通过生成对抗网络(Generative Adversarial Networks, GANs)[7]实现对生成图像的布局控制。
Pix2pix是第一个提出使用编解码器生成器和PatchGAN鉴别器进行语义图像合成的。Pix2pixHD采用粗粒度发生器和多尺度鉴别器实现高分辨率图像合成。SPADE[23]提出使用从语义映射中学习到的空间自适应变换来调制特征,显著提高了图像质量。随后,CC-FPSE[16]引入了基于语义布局的条件卷积核参数预测,并利用特征金字塔语义嵌入判别器来激励生成器生成具有更高质量细节和更好语义对齐的图像。最近,SCGAN[40]学习了一个语义向量来参数化条件卷积核和归一化参数。LGGAN[35]引入了利用局部特定类别和全局图像级生成对抗网络来单独学习每个对象类别和全局图像的外观分布。OASIS[34]创新地设计了一个基于分割网络的鉴别器,为生成器提供更有效的反馈,从而生成具有更高保真度的语义对齐图像。此外,也有一些方法[19,25,32,36,41]通过挖掘语义图中的结构和形状信息来提高图像质量。
尽管以前的方法在语义图像合成方面取得了重大成就,但由于训练规模和语义布局表示的限制,生成的图像质量和多样性仍然有限。
Layout Controllable Text-to-Image Synthesis
文本到图像合成的重点是根据给定的文本提示生成图像。得益于强大的扩散模型[11,33]和广泛的文本-图像训练数据,文本-图像合成在图像质量、多样性和与所提供文本的一致性方面取得了前所未有的成功[21,27,28,30]。其中,LDM[28]的效率与质量之间的平衡备受关注,成为许多可控[47,48]或定制图像合成作品的基础模型[8,29,42]。
随后的工作研究了利用预训练模型实现布局可控的文本到图像合成[1,13,24,43,44]。eDiff-I[2]和Two Layout Guidance[4]迭代优化约束交叉注意图与目标布局之间的对齐。然而,它们只能粗略地控制合成对象的定位。ControlNet[47]和T2I-Adapter[20]用一个额外的布局编码器编码语义映射。然而,受布局编码器泛化能力的限制,它们无法克服布局一致性的限制。另一类方法以不需要训练的方式控制合成图像的布局。FreestyleNet[45]引入了纠正交叉注意(Rectified Cross Attention, RCA)来取代稳定扩散中的交叉注意模块,使每个文本令牌能够与相应的图像特征区域进行专门的交互。随后,对预训练的稳定扩散模型在特定域上进行微调以适应RCA。FreestyleNet在语义一致性和布局对齐方面取得了进展。然而,由于在使用RCA语义图时丢失了布局信息,生成的图像缺乏足够的布局对齐。此外,由于交叉注意的修改和微调数据集的规模有限,FreestyleNet在预训练模型中容易丢失先验,并且在视觉质量和语义一致性方面仍然存在局限性。
Proposed Method
给定具有C个语义类的语义映射S∈RH×W×C,语义图像合成的目的是合成与S对齐良好的逼真图像。C的值由用户指定的语义类别的数量决定,而不是由预定义的封闭集的基数决定。为了实现具有理想布局的可控图像合成,我们首先采用忠实的布局控制映射作为特征空间中的布局表示。然后,我们提出了PLACE自适应整合布局和语义特征,如图图 (b)所示。在微调过程中,我们进一步引入语义对齐(SA)损失来增强布局对齐和无布局先验保存(LFP)损失来提高视觉质量和语义一致性的性能。在下面的小节中,我们首先简要介绍了我们使用的预训练文本到图像模型,即Stable Diffusion[28]。然后我们提供我们的地点和学习目标的细节。
Preliminary: Stable Diffusion
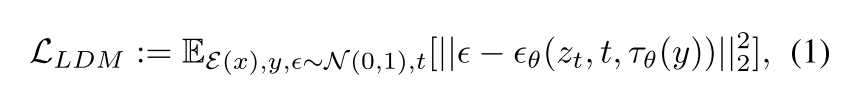
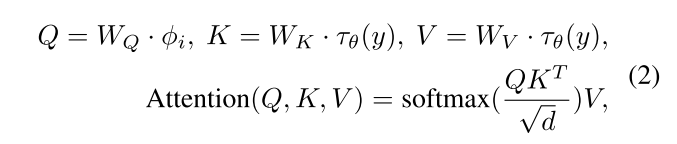
Adaptive Layout-Semantic Fusion Network
在本小节中,我们将首先介绍我们提出的布局控制图,然后介绍我们的自适应布局语义融合模块的细节。
Layout control map. 已经注意到,在稳定扩散中的交叉注意图与合成图像的布局密切相关[1,2]。具体来说,交叉注意图Aca∈R(HW)×N中的Aca i,j决定了第i个图像标记与第j个文本标记之间的关联强度,从而影响合成图像的布局。以前的工作大致是通过约束交叉注意图中特定token的影响区域来控制合成图像中特定对象的位置。然而,由于LDM中中间图像特征的尺寸(小于或等于64 × 64)明显小于给定的语义布局(512 × 512或更大),简单地调整语义地图的大小以适应中间特征的大小,不可避免地会导致细节失真甚至丢失。例如,如图所示,即使使用朴素的最近邻插值将语义图的大小调整为原始大小的1/8,“植物”的细节也会被扭曲,一些“光”的实例也会丢失。此外,来自较深层的图像特征具有较小的维度,这使得合成与给定语义图精确对齐的图像具有挑战性。

为了解决上述问题,我们提出了一种在低分辨率特征空间中编码布局信息的布局控制图,减少了布局信息的丢失。对于中间图像特征的每个标记,我们研究了其感受野内的所有语义成分,以及每个类所占的比例。然后,我们使用由这些比例组成的矢量作为这个令牌的布局特征。如图图 (b)顶部所示,在红色边框所选择的图像标记的感受野内,存在“墙”、“天花板”、“窗户”和“光”四个语义类别,每个类别对应不同的比例。由比例组成的向量忠实地编码该图像标记的感受野内的布局信息。给定从![]() 重构的语义映射
重构的语义映射![]() ,布局控制映射
,布局控制映射![]() 的计算公式如下:
的计算公式如下:
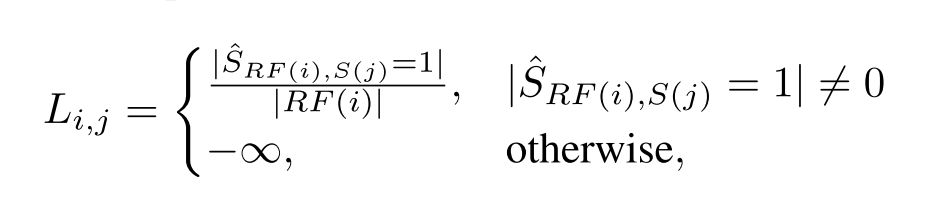
式中,RF(i)表示第i个图像标记的感受野,S(j)表示第j个文本标记对应的语义通道。|·|表示集合中元素的个数。从图中可以看出,我们的布局控制图编码了忠实的布局细节,包括植物的枝叶和微妙的照明,从而合成的图像具有更丰富和准确的细节。
.
Adaptive fusion of layout and semantics. 虽然使用布局控制图手动限制每个语义组件的影响区域可以操纵合成对象的位置,但特定对象的合成无法从全局文本上下文中受益。为了将我们的布局表示适当地整合到图像合成过程中,并合成具有所需布局的高质量图像,我们提出了一个自适应布局语义融合模块(PLACE)。如图图 (b)所示,在每个融合模块中,将时间嵌入送入线性层以预测自适应融合参数α,然后使用该参数对布局控制图L和交叉注意图Aca进行积分,生成自适应融合图F和最终输出特征O:
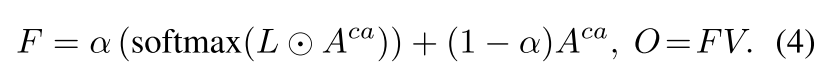
通过采用时间步长自适应参数α作为权值来融合布局特征和语义特征,维持了稳定扩散中图像标记和文本标记之间的全局交互。交互机制允许每个图像令牌从更大的文本令牌集访问上下文信息。这种布局和语义的自适应集成不仅有助于控制合成图像的布局,而且有利于高质量细节的合成。学习自适应α随时间步长的变化趋势验证了我们方法的有效性。如图图 (a)所示,在采样的早期阶段,α值相对较大,这表明布局控制图在确定初始布局中起着至关重要的作用。然而,在后期,自适应α逐渐减小,这表明布局控制图的影响随着过程的进行而减弱。这使得图像标记可以主动与全局文本标记交互,从而合成更逼真的细节和高质量的结果。图 (c)显示了固定α (α = 1)和自适应α在图像合成过程中预测的x0的变化。可以看到,在早期采样阶段,确定了x0的布局,而在后期阶段,模型主要是合成现实细节。此外,与固定α = 1的情况相比,自适应融合允许图像标记从更多的文本标记中提取信息,从而能够合成具有更丰富和更真实细节的图像,例如图中所示的“道路”中的“行人过街”。图(b)也证实了这一点,其中文本标记“人行道”不仅影响其相应的语义区域,还影响其他上下文区域,如“道路”类。而在固定α条件下,则不能观察到这种相互作用。
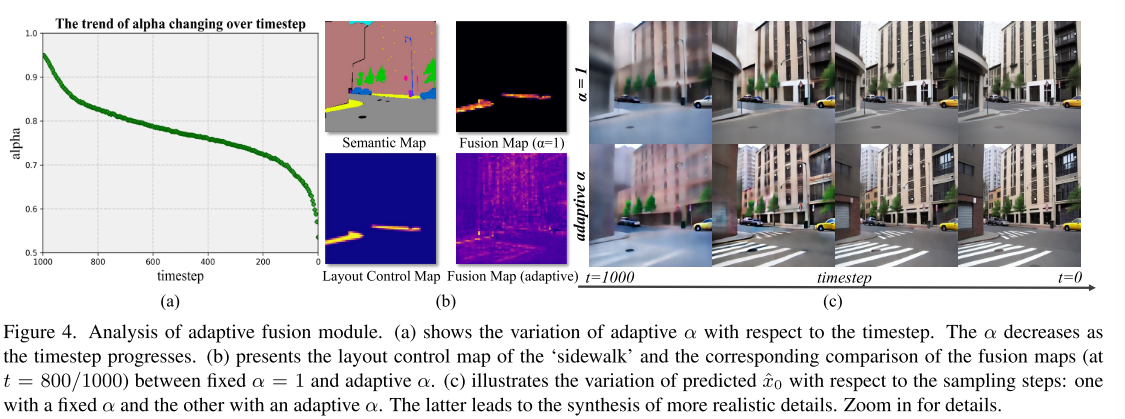
自适应融合模块分析。(a)为自适应α随时间步长的变化。α随时间步长增加而减小。(b)给出了“人行道”的布局控制图,以及在t = 800/1000时固定α = 1和自适应α的融合图的相应比较。(c)说明了预测的x0随采样步长的变化:一个具有固定的α,另一个具有自适应的α。后者导致更现实的细节合成。放大查看细节。


Learning Objective
在微调阶段,除了原始文本图像去噪损失外,我们还引入了语义对齐(SA)损失和无布局先验保存(LFP)损失来促进学习。
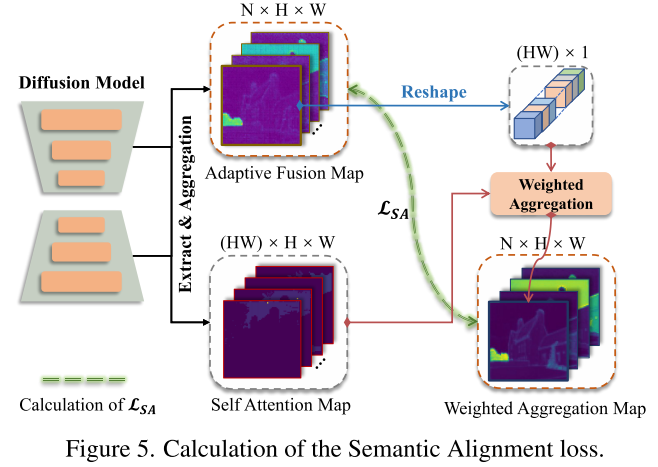
Semantic Alignment Loss. 为了进一步增强合成图像的布局对齐性,我们提出了语义对齐损失LSA。如图所示,我们首先利用自适应融合图F∈RN×H×W作为权重,对自注意力机制图Asa∈R(HW)×H×W进行聚合,得到加权聚合图W∈RN×H×W。然后,我们的目标是最小化它们与原始自适应融合图之间的差异,其可表述为:
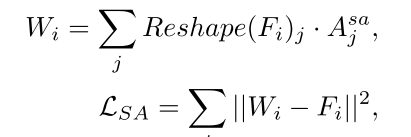
其中,Reshape(·) denotes the flatten operation,重塑(Fi)∈R(HW)×1。LSA有效地鼓励图像令牌与自注意力机制模块中相同且相关的语义区域进行更多的交互,从而进一步改善生成图像的布局对齐。
Layout-Free Prior Preservation Loss. 由于微调数据集的规模有限,模型不可避免地会遭受语义先验的损失,从而导致语义一致性和视觉质量的次优性能。扩大微调数据集的规模是解决这个问题的一种可能方法。然而,获得大量带有语义掩码注释的真实图像并非易事。
我们引入了无布局预先保存(LFP)损失来缓解这个问题。它完全依赖文本-图像数据对来帮助保留预训练模型的先验知识,这相对更容易获得。在每次微调迭代中,除了对具有语义掩码注释< zt, S, y, t >的常规配对训练数据进行采样外,我们还从Layout Free (LF)数据集中提取一组额外的文本数据对< z ' t, y ', t ' >以馈入网络,如图图 (a)所示。我们在合成图像时明确地将自适应融合参数α设置为0。原始去噪损失LLDM和我们的LFP损失LLFP可以计算如下:
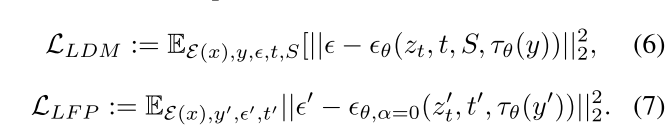
我们从openimages[14]和Laion-5b[31]数据集中收集了大约300,000个文本图像对作为Layout Free数据集。关于LFP损耗实施的更多细节可在补充材料中找到。
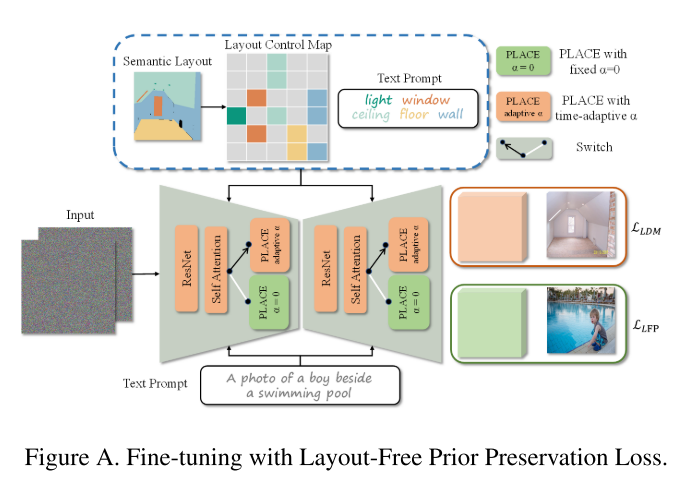
通过使用LFP损失,即使没有语义掩模的参与,预训练模型中的语义概念也能在微调过程中得到更好的保留。实验结果表明,该模型可以生成多种图像,并在视觉质量和语义一致性方面表现出较好的性能。
优化目标可由方程 5、方程 6、方程 7总结如下:
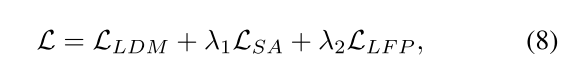
其中λ1和λ2是权系数。它们被默认设置为1。


Experiments
Experimental Details
Datasets. ADE20K和COCO-Stuff。ADE20K包含150个语义类别。它有20,210张用于训练的图像和2,000张用于验证的图像。COCO-Stuff包含182个语义类别,涵盖了不同的场景。它包括118287张训练图像和5000张验证图像。在训练过程中,图像和语义图的大小都被调整为512 × 512。图像中的所有语义类与空格连接在一起,形成输入文本提示符。
Implementation Details. 我们使用预训练的V1-4稳定扩散模型[28]作为初始化权值,并以5×10−6的学习率对其进行微调。所有的实验都是在带有4个NVIDIA V100 32G gpu的服务器上进行的。我们微调了大约30万次迭代,批大小为4。在采样过程中,我们采用50个PLMS采样步骤,无分类器引导标度为2。
Evaluation Metrics.在之前对语义图像合成[45]的研究之后,我们定量地评估了使用Fr´cheet Inception Distance (FID)[9]和平均Intersection over Union (mIoU)进行分布内合成的结果。FID评估生成图像的视觉质量,而mIoU衡量语义和布局的一致性。此外,得益于预训练模型的优越先验性,我们的方法还显示出了分布外综合的能力。我们从新对象、新样式和新属性三个角度来评价这种能力。对于新对象合成,我们使用在ADE20K上微调的模型来合成只出现在COCO-Stuff中的语义类别(即,不包含在ADE20K中的类别)。采用FID和mIoU来评估结果的质量和一致性。在新样式和新属性合成方面,我们用相同的模型合成了260张具有8种新全局样式和6种特定对象属性的图像。我们使用CLIP[26]文本-图像相似性(即文本对齐)来测量具有特定样式或属性的合成结果的一致性。更多的细节可以在补充材料中找到。
Evaluation of In-distribution Synthesis
Quantitative comparisons.

Qualitative comparisons.

Evaluation of Out-distribution Synthesis
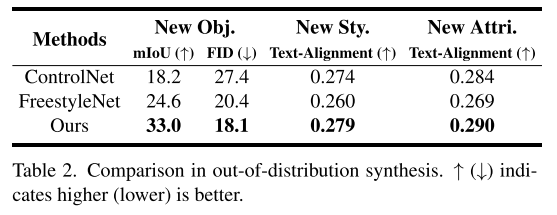
表2和图7分别给出了分布外合成结果的定量和定性比较。非分布综合评价包括新对象、新样式和新属性三个方面。如图所示,与ControlNet和FreestyleNet相比,我们的方法在所有三个方面都取得了更好的定量分数。特别是在新对象类别中,与FreestyleNet相比,我们的方法实现了8.4的显著mIoU改进。从视觉对比中可以看出,我们的方法合成的分布外图像不仅与给定条件(即新语义、新样式和新属性)具有更好的语义一致性,而且在布局对齐方面保持了良好的性能。例如,在图中,第一行的“动漫”样式,第三行的“彩虹”样式,第四行的“鸟”样式都忠实地符合所提供的条件。第四行中的“鸟”和“熊”显示了强大的布局对齐。更多的结果可以在补充资料中找到。

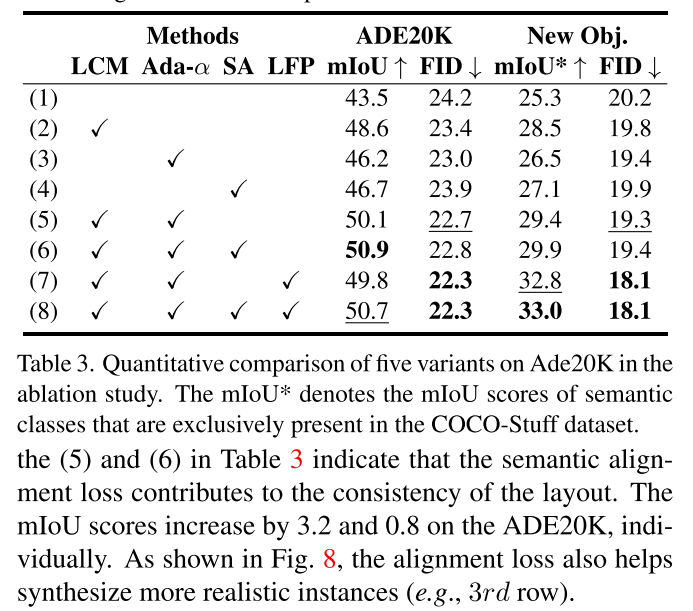
Ablation Study
Layout control map.
Adaptive α for fusion.
Semantic Alignment loss.
Layout Free Prior Preservation loss.

Limitation
尽管PLACE在视觉质量、语义一致性和布局对齐方面取得了进步,但仍然存在一些限制。首先,与基于gan的方法相比,基于扩散的方法的推理速度仍然较慢。在V100 GPU上,ControlNet、FreestyleNet和PLACE使用PLMS采样50步合成图像的平均时间分别约为7.5秒、5.9秒和6.1秒。我们相信,随着优质采样器和潜在一致性模型的发展,这一问题将在很大程度上得到缓解。此外,受预训练稳定扩散能力的限制,当单个类的提示太长或包含不常见的标记时,合成的图像可能与给定的文本不一致。更高性能的文本到图像模型可能会潜在地改善这个问题。