深度估计研究方向常用数据集介绍
目录
一、深度估计研究方向简介
二、深度估计常用数据集整理
1. KITTI 系列
2. NYU Depth V2
3. ScanNet
4. Make3D
5. Cityscapes
6. Middlebury Stereo Dataset
7. SUN RGB-D
8. DIODE
9. MegaDepth
10. ReDWeb
其他补充数据集
数据集选择建议
一、深度估计研究方向简介
深度估计(Depth Estimation)是计算机视觉中的核心任务之一,旨在从单目、双目或多视角图像中恢复场景的三维几何信息。根据输入数据的不同,深度估计可分为以下方向:
-
单目深度估计:仅用单张图像预测深度(无需多视角或传感器)。
-
立体匹配(双目深度估计):利用双目图像视差恢复深度。
-
多视角深度估计:基于多个视角的图像或视频序列(如SLAM、MVS)。
-
传感器融合:结合RGB图像与激光雷达(LiDAR)、ToF相机等传感器数据。
应用场景:自动驾驶、机器人导航、增强现实(AR/VR)、3D重建等。
二、深度估计常用数据集整理
以下按应用场景和数据类型分类,逐个介绍主流数据集及其特点、适用任务和获取方式:
1. KITTI 系列
-
简介:自动驾驶领域最经典的数据集,由德国卡尔斯鲁厄理工学院于2012年发布。
-
数据内容:
-
双目RGB图像(分辨率1242×375)。
-
64线LiDAR点云(稀疏但高精度)。
-
GPS/IMU轨迹数据。
-
-
特点:
-
室外道路场景(城市、乡村、高速公路)。
-
深度真值通过LiDAR投影到图像坐标系生成,但分辨率较低(仅覆盖部分区域)。
-
-
适用任务:单目/双目深度估计、自动驾驶感知、SLAM。
-
获取方式:KITTI官网(需签署协议)。

2. NYU Depth V2
-
简介:室内场景深度数据集,由微软Kinect传感器采集(2012年)。
-
数据内容:
-
464个室内场景的RGB-D视频序列(分辨率640×480)。
-
密集深度图(含噪声,需后处理)。
-
语义分割标注。
-
-
特点:
-
覆盖复杂室内环境(办公室、家庭等)。
-
深度真值通过Kinect的ToF相机获取,但存在噪声和缺失区域。
-
-
适用任务:单目深度估计、室内场景理解、语义分割联合任务。
-
获取方式:NYU Depth V2下载页。

3. ScanNet
-
简介:大规模室内3D重建数据集,包含2.5K+场景(2017年)。
-
数据内容:
-
RGB-D视频序列(1280×960分辨率)。
-
高精度3D网格真值(通过结构光扫描生成)。
-
语义和实例分割标注。
-
-
特点:
-
真值密集且精确,适合训练深度网络。
-
场景多样(浴室、图书馆、商店等)。
-
-
适用任务:多视角深度估计、3D重建、语义深度联合学习。
-
获取方式:ScanNet官网(需申请权限)。
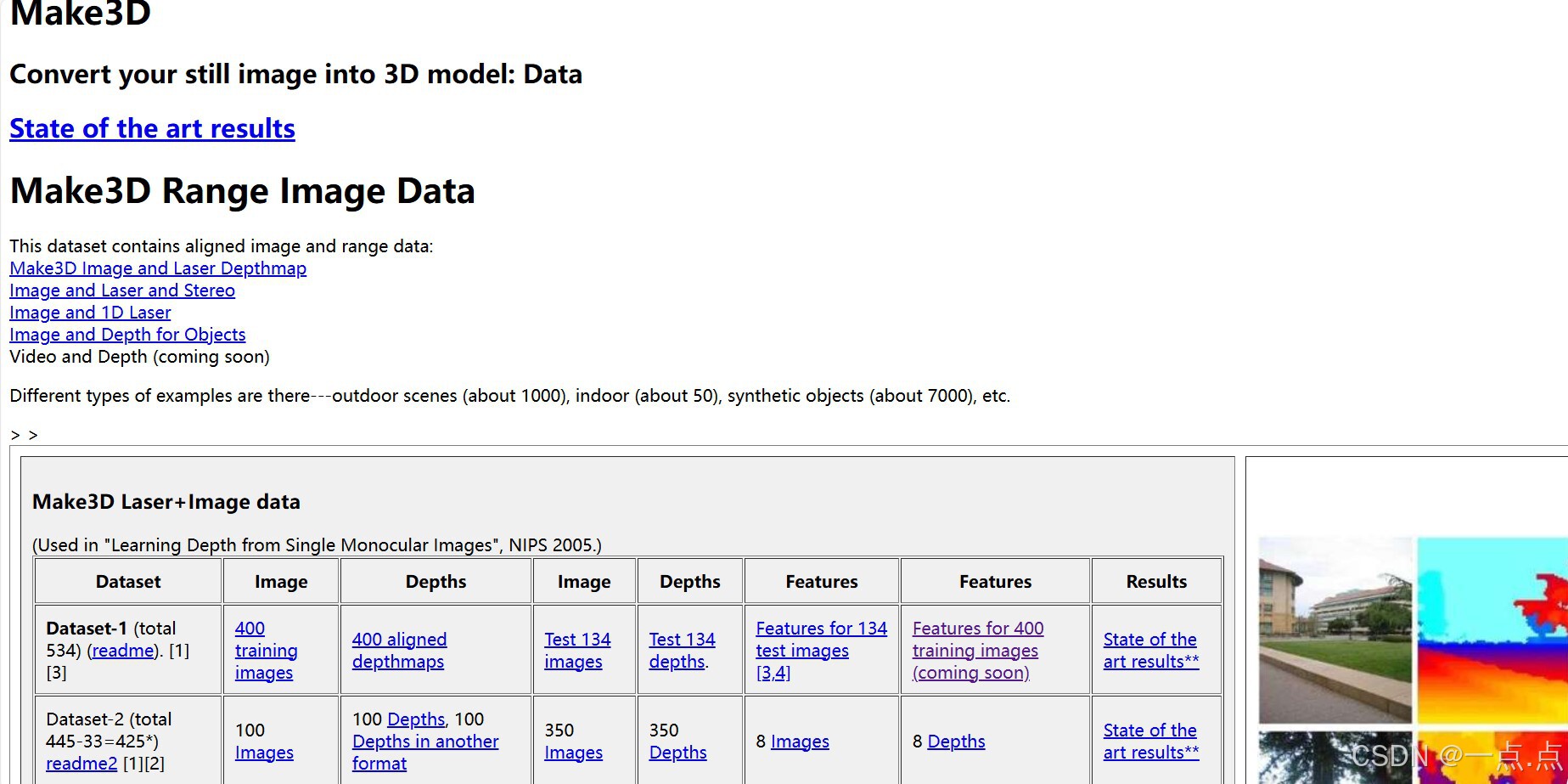
4. Make3D
-
简介:早期单目深度估计数据集(2008年),适用于学术研究。
-
数据内容:
-
534张室外场景图像(分辨率2272×1704)。
-
激光雷达生成的稀疏深度图。
-
-
特点:
-
图像分辨率高,但深度图稀疏且场景单一(多为校园环境)。
-
-
适用任务:单目深度估计基础算法验证。
-
获取方式:Make3D官网。
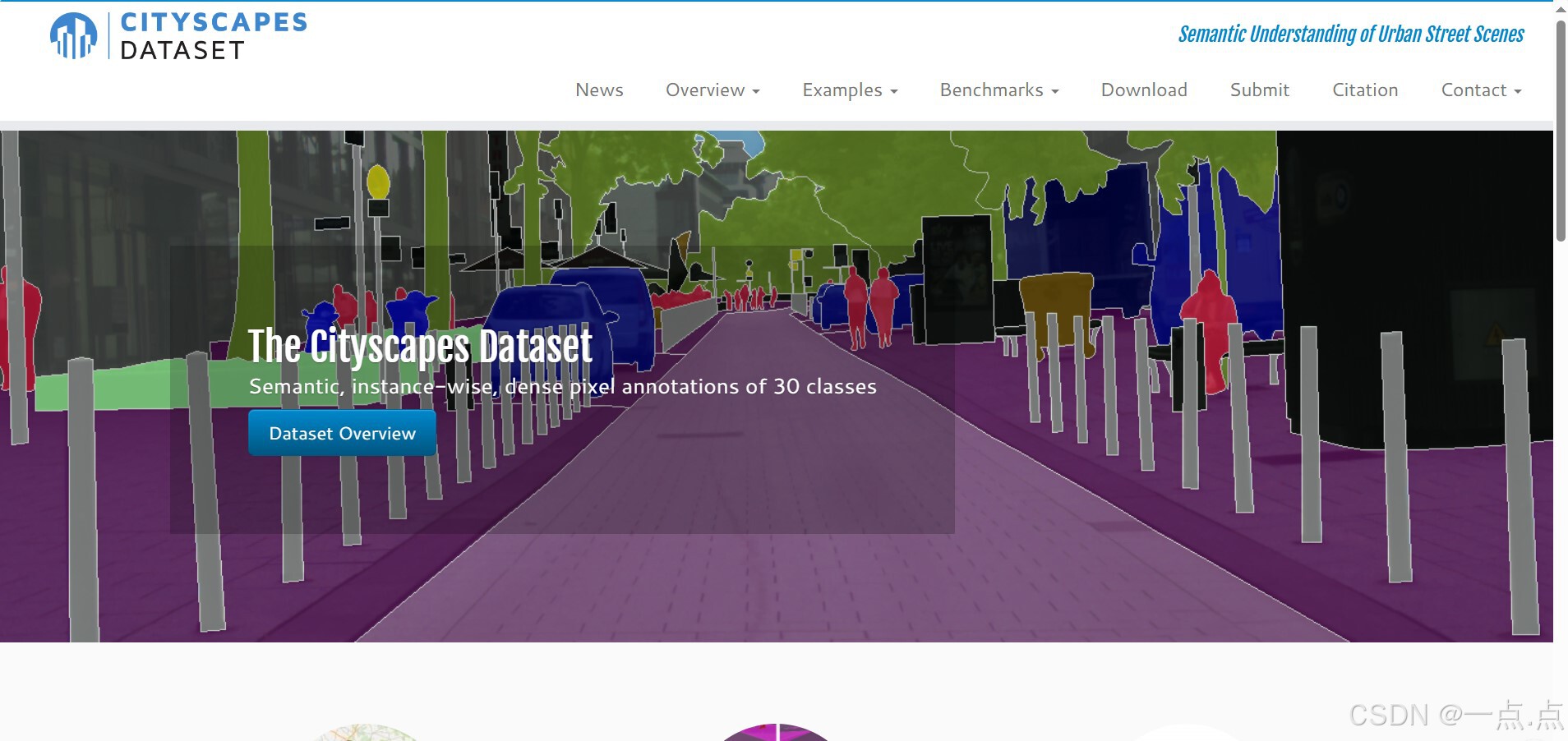
5. Cityscapes
-
简介:城市场景语义分割数据集,包含深度扩展(2016年)。
-
数据内容:
-
双目图像(分辨率2048×1024)。
-
伪深度图(通过立体匹配生成)。
-
精细语义分割标注。
-
-
特点:
-
高分辨率图像,但深度图依赖立体匹配算法,可能存在误差。
-
-
适用任务:双目深度估计、语义与深度联合学习。
-
获取方式:Cityscapes官网。
6. Middlebury Stereo Dataset
-
简介:传统立体匹配基准数据集,以高精度真值著称(2001-2014年)。
-
数据内容:
-
双目图像(高分辨率,最高3000×2000)。
-
密集深度图(通过结构光扫描生成)。
-
-
特点:
-
真值精度极高(毫米级),但场景数量少(约30组)。
-
包含不同光照和纹理挑战。
-
-
适用任务:立体匹配算法验证、深度网络精度测试。
-
获取方式:Middlebury官网。

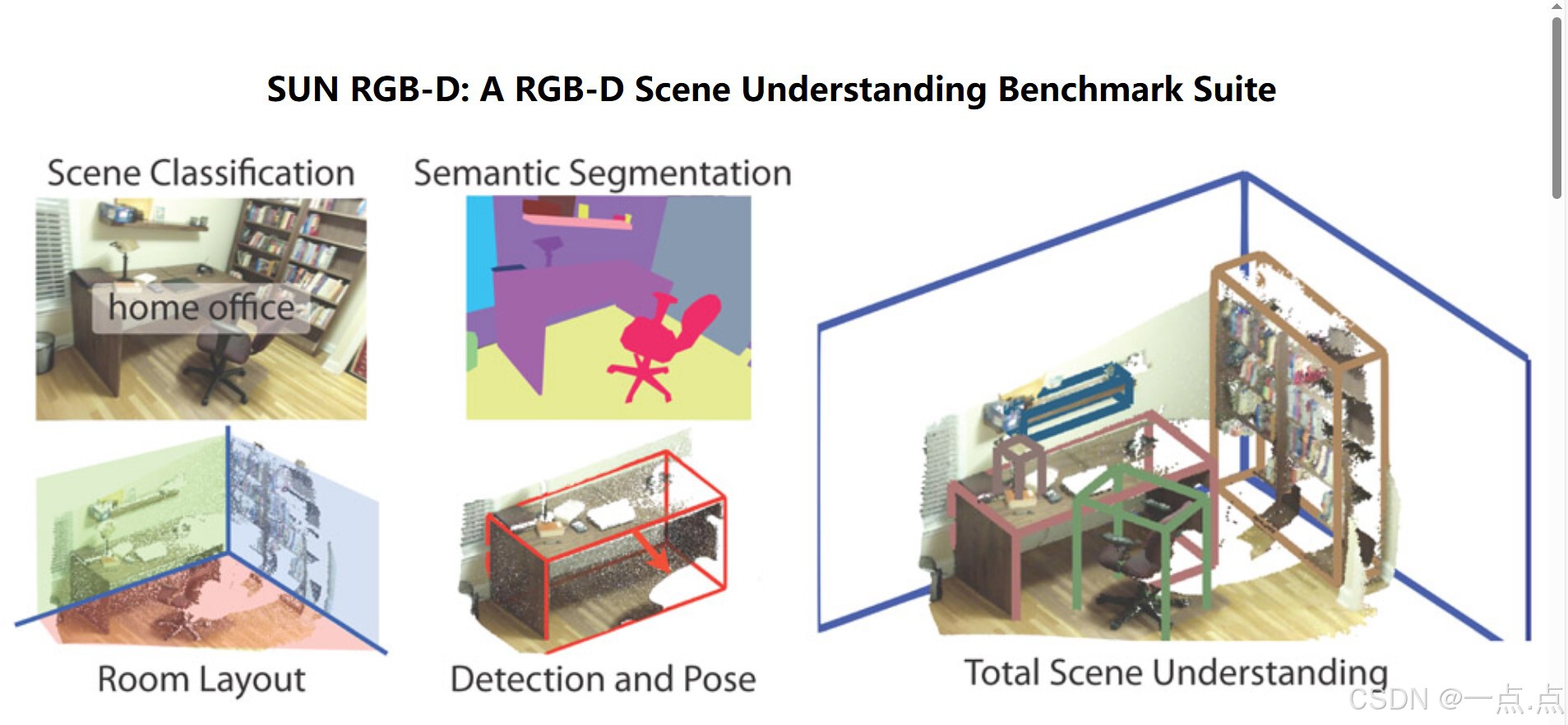
7. SUN RGB-D
-
简介:室内场景多传感器数据集(2015年),包含RGB-D图像和3D标注。
-
数据内容:
-
10,000+ RGB-D图像(来自Kinect v1、Intel RealSense等)。
-
3D物体包围框、语义分割标注。
-
-
特点:
-
多传感器数据融合,适合研究传感器差异对深度估计的影响。
-
-
适用任务:单目/多传感器深度估计、场景理解。
-
获取方式:SUN RGB-D官网。
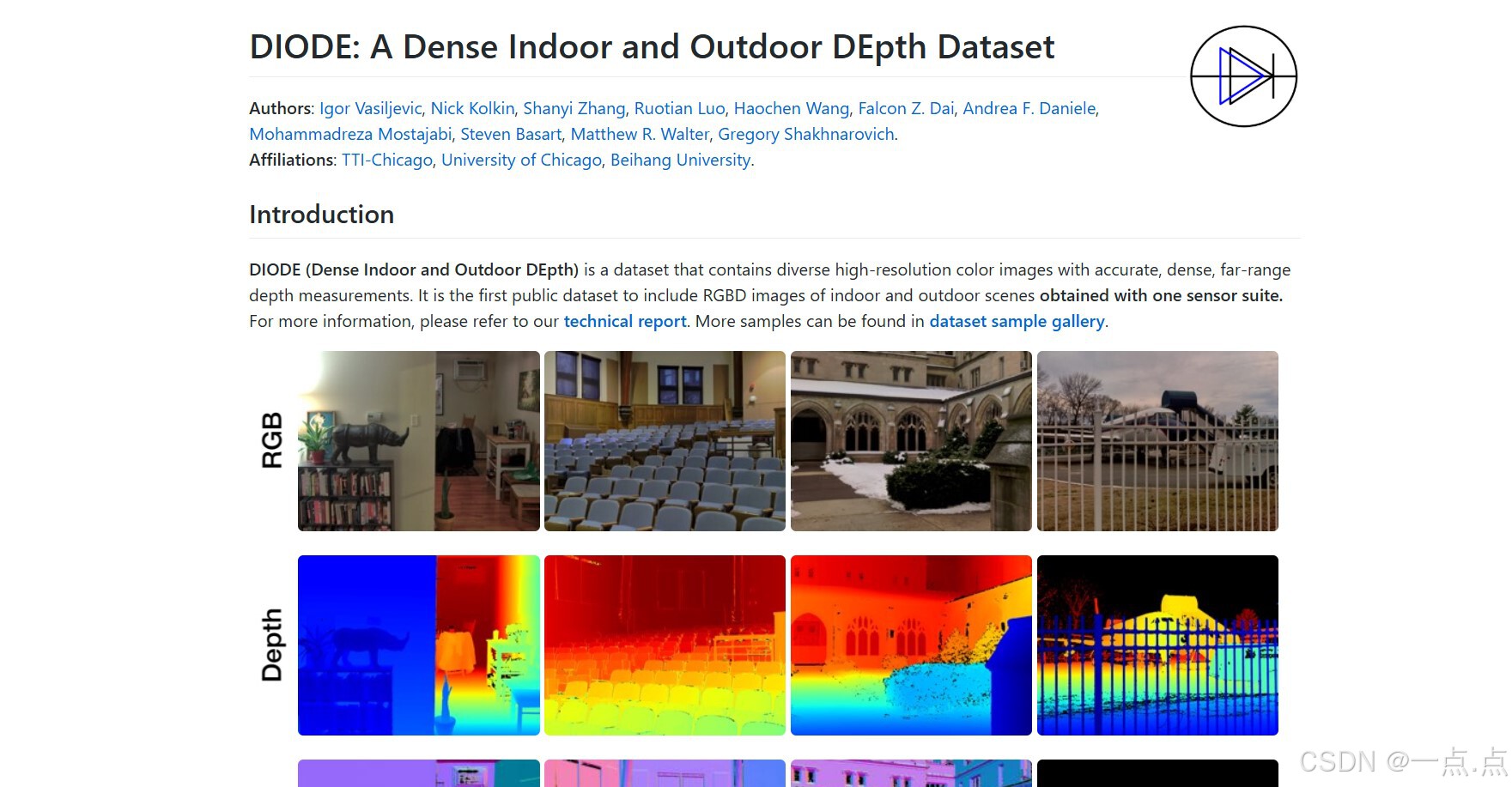
8. DIODE
-
简介:多样化室内外场景数据集(2019年),覆盖复杂几何结构。
-
数据内容:
-
高分辨率RGB图像(多视角采集)。
-
密集深度图(通过激光扫描生成)。
-
-
特点:
-
包含室内(走廊、楼梯)和室外(街道、公园)场景。
-
数据规模较小(约1000张),但标注质量高。
-
-
适用任务:单目深度估计泛化性测试。
-
获取方式:DIODE官网。
9. MegaDepth
-
简介:利用网络照片和SfM(运动恢复结构)生成的大规模数据集(2018年)。
-
数据内容:
-
200,000+单目图像(来自Flickr)。
-
通过SfM生成的稀疏深度图(部分稠密化)。
-
-
特点:
-
数据量大且多样,但深度真值为稀疏点云。
-
适合自监督或弱监督深度估计训练。
-
-
适用任务:单目深度估计自监督学习。
-
获取方式:MegaDepth GitHub。
10. ReDWeb
-
简介:基于单目视频的相对深度数据集(2018年)。
-
数据内容:
-
3,600张网络视频帧(含动态物体)。
-
通过众包标注的相对深度关系(非绝对深度值)。
-
-
特点:
-
强调相对深度排序,适合无需绝对尺度的应用。
-
-
适用任务:相对深度估计、视频深度预测。
-
获取方式:ReDWeb官网。
其他补充数据集
| 数据集 | 特点 | 适用任务 |
|---|---|---|
| TUM RGB-D | 动态物体少,适合SLAM | 深度估计与SLAM联合任务 |
| ETH3D | 高分辨率、混合室内外场景 | 多视角立体匹配 |
| Virtual KITTI 2 | 合成数据,真值完美 | 算法验证与极端场景测试 |
| SceneNet RGB-D | 大规模合成室内场景(10万+图像) | 深度网络预训练 |
| Waymo Open Dataset | 自动驾驶大规模LiDAR数据 | 多传感器融合深度估计 |
| DDAD | 多模态数据(LiDAR、双目、雷达) | 自动驾驶深度感知 |
| Hypersim | 高质量合成室内场景(光线模拟逼真) | 复杂光照下的深度估计 |
| OmniDepth | 360度全景图像深度数据集 | 全景深度估计 |
| TartanAir | 多模态合成数据(双目、事件相机) | 鲁棒深度估计挑战 |
| KITTI-360 | KITTI扩展版,覆盖连续驾驶场景 | 长序列深度预测 |
数据集选择建议
-
自动驾驶:优先选择KITTI、Waymo、DDAD、KITTI-360。
-
室内场景:NYU Depth V2、ScanNet、SUN RGB-D。
-
算法验证:Middlebury(高精度)、Virtual KITTI 2(合成数据)。
-
自监督学习:MegaDepth、ReDWeb。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!