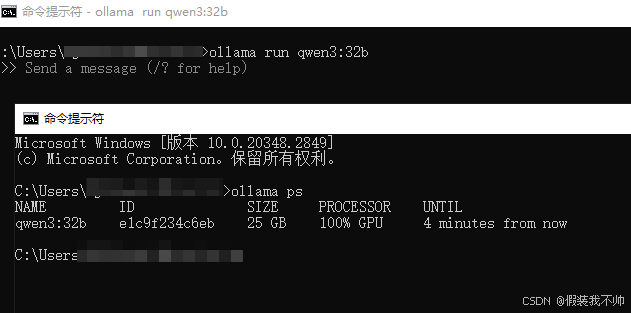
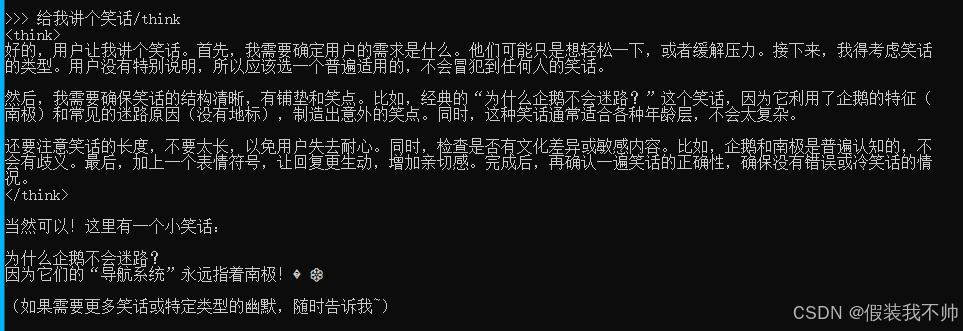
当前位置: 首页 > web >正文 ollama运行qwen3 web 2025/7/3 20:12:32 环境 windows server GPU 32G 内存 40G 升级ollama 需要版本 0.6.6以上 ollama --version 拉取模型 ollama pull qwen3:32b 时间比较长,耐心等待 运行模型 ollama run qwen3:32b 运行起来之后发现GPU是可以跑起来的,发个你好看看 默认是深度思考的,不想深度思考,加上/no_think 又想深度思考了,加上/think即可 查看全文 http://www.xdnf.cn/news/3072.html 相关文章: 【Leetcode 每日一题】2962. 统计最大元素出现至少 K 次的子数组 如何对多维样本进行KS检验 UNIAPP项目记录 【大厂实战】API网关进化史:从统一入口到智能AB分流,如何构建灰度无感知系统? 【工具变量】上市公司30w+过度负债数据集(2004-2023年) 【嘉立创EDA】如何无限制挖槽,快捷设计挖槽 Linux系统配置JDK 哈工大《工程伦理》复习文档 存储过程补充——定义条件、处理程序及游标使用 PID速度、电流、位置闭环 swagger2升级至openapi3的利器--swagger2openapi Linux 用户管理 数据处理方式 之 对数变换 和Box-Cox变换以及对应逆变换【深度学习】 JavaScript基础 使用C# ASP.NET创建一个可以由服务端推送信息至客户端的WEB应用(1) Qwen3术语解密 【SAM2代码解析】数据集处理2 go打印金字塔 探索行业的新可能 - 你有遇到这些挑战吗? 创新应用 | 食堂餐牌显示的“秒变”革新 Python深度挖掘:openpyxl和pandas的使用详细 优雅的酸碱中和反应动画演示工具 仿腾讯会议——注册登录UI docker 使用 数据采集脱硫脱硝除尘实验装置 DTO,VO,PO,Entity 第一个机器人程序 C语言教程(二十):C 语言 typedef 关键字详解 AVL树左旋右旋的实现 C语言加餐--浮点数比较
环境 windows server GPU 32G 内存 40G 升级ollama 需要版本 0.6.6以上 ollama --version 拉取模型 ollama pull qwen3:32b 时间比较长,耐心等待 运行模型 ollama run qwen3:32b 运行起来之后发现GPU是可以跑起来的,发个你好看看 默认是深度思考的,不想深度思考,加上/no_think 又想深度思考了,加上/think即可