Spark-Streaming核心编程内容总结
一、有状态转化操作
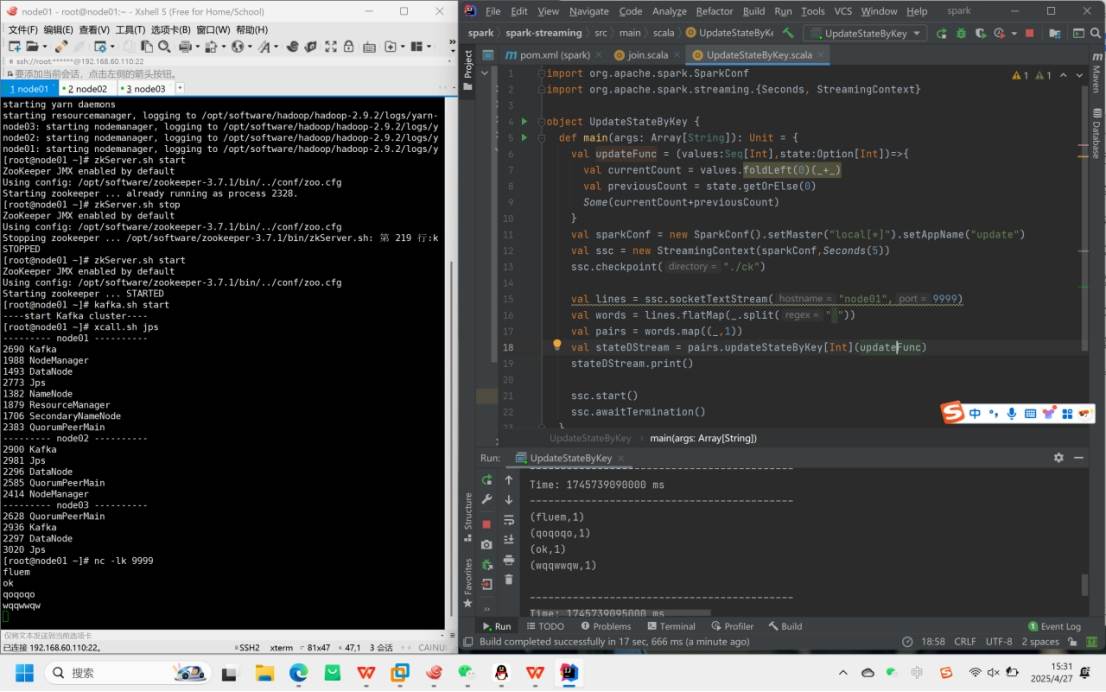
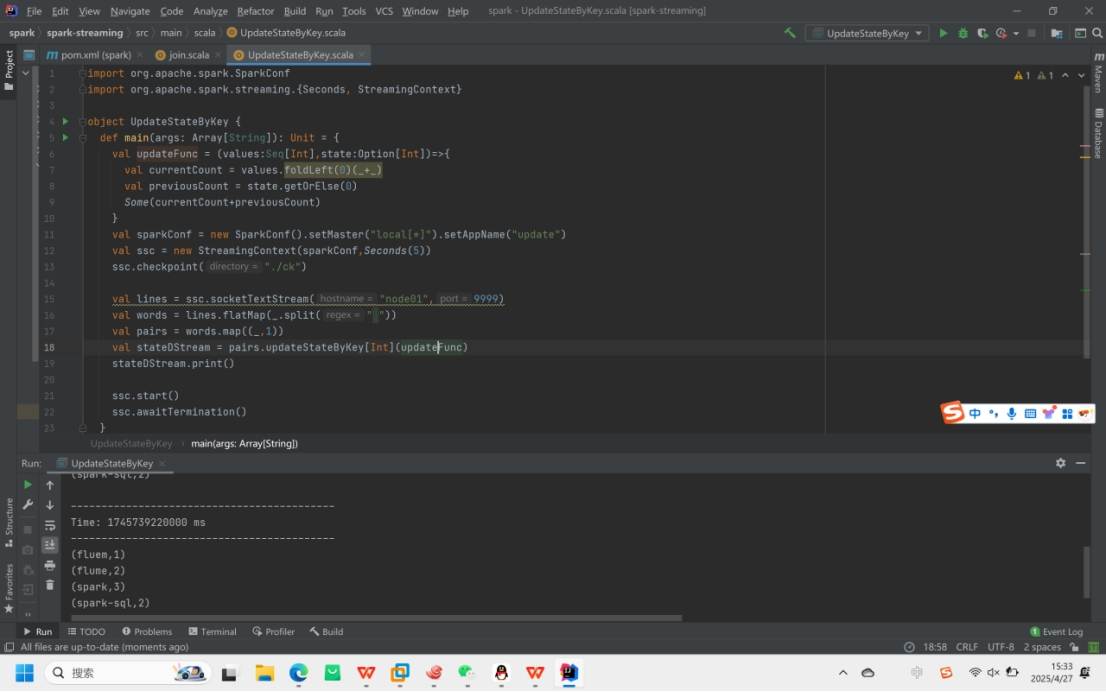
1.UpdateStateByKey
功能:用于跨批次维护状态(如累加wordcount),通过访问状态变量处理键值对形式的DStream。。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
2.关键点:
定义状态(任意数据类型)
定义状态更新函数(结合之前状态和输入流新值更新状态)
必须配置检查点目录保存状态
 二、WindowOperations
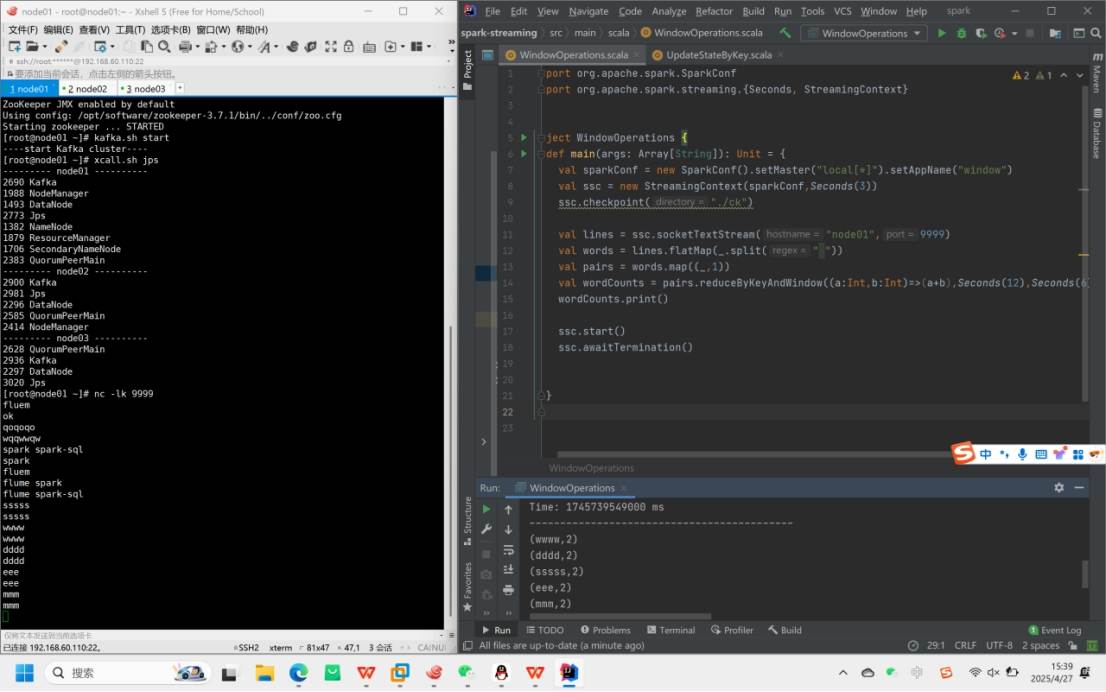
二、WindowOperations
1.功能:通过设置窗口大小和滑动间隔动态获取Streaming的允许状态
2.参数:
窗口时长:计算内容的时间范围
滑动步长:触发计算的间隔时间
注意:两者必须是采集周期大小的整数倍
三、DStream输出操作
1.主要输出操作:
print():在驱动结点上打印每批次前10个元素(用于开发调试)
saveAsTextFiles(prefix, [suffix]):以text文件形式存储
saveAsObjectFiles(prefix, [suffix]):以Java对象序列化方式存储
saveAsHadoopFiles(prefix, [suffix]):存储为Hadoop文件
foreachRDD(func):最通用的输出操作,对每个RDD应用任意计算
2.foreachRDD使用注意事项:
连接不能写在driver层面(序列化问题)
避免在foreach中为每条数据创建连接(性能差)
推荐使用foreachPartition,在分区级别创建连接
通用输出模式:foreachRDD允许重用Spark中的所有行动操作,常见用例是将数据写入外部数据库(如MySQL)。