array和模板进阶(详细使用)
一.array
这个就是一个静态数组,它就是通过模板来完成的。
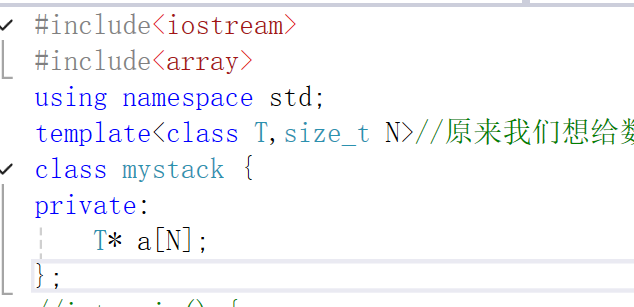
就是用一个N,每次用多少开多少。
原来我们想给数组一个大小,用我们的#define N 10 这样是写死的,我们如果把它写在栈的数组中,一个如果需要100,一个需要10,那么就会浪费90个空间了,所以我们又搞了个模板参数size_t类型的,其他类型不行,c++20才有double类型的,其他类型都不行。
它有自己的一些优点,但是不常用,它的最显著的优点就是越界的检查。

我们看一下这个,我们用array创建的数组,不会直接初始化数组,而都是随机值。
我们看一下下面的普通数组,前两个10和11都越界了可以检查出来,但是到了12却检查不出来了,这是因为普通数组的越界检查就是抽查,普通数组对越界的检查太不敏感了,只能检查写,不能检查读,我们下面读arr1[10]此时编译器都没有检查出来越界了,所以很不安全,我们的这个array数组可以很好的检查出来越界,对越界的检查非常敏感,也能检查出来读的越界。
二.模板进阶
2.1 模板的特化
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些 错误的结果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板。
函数模板的特化步骤:
1. 必须要先有一个基础的函数模板
2. 关键字template后面接一对空的尖括号<>
3. 函数名后跟一对尖括号,尖括号中指定需要特化的类型
4. 函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇
怪的错误。
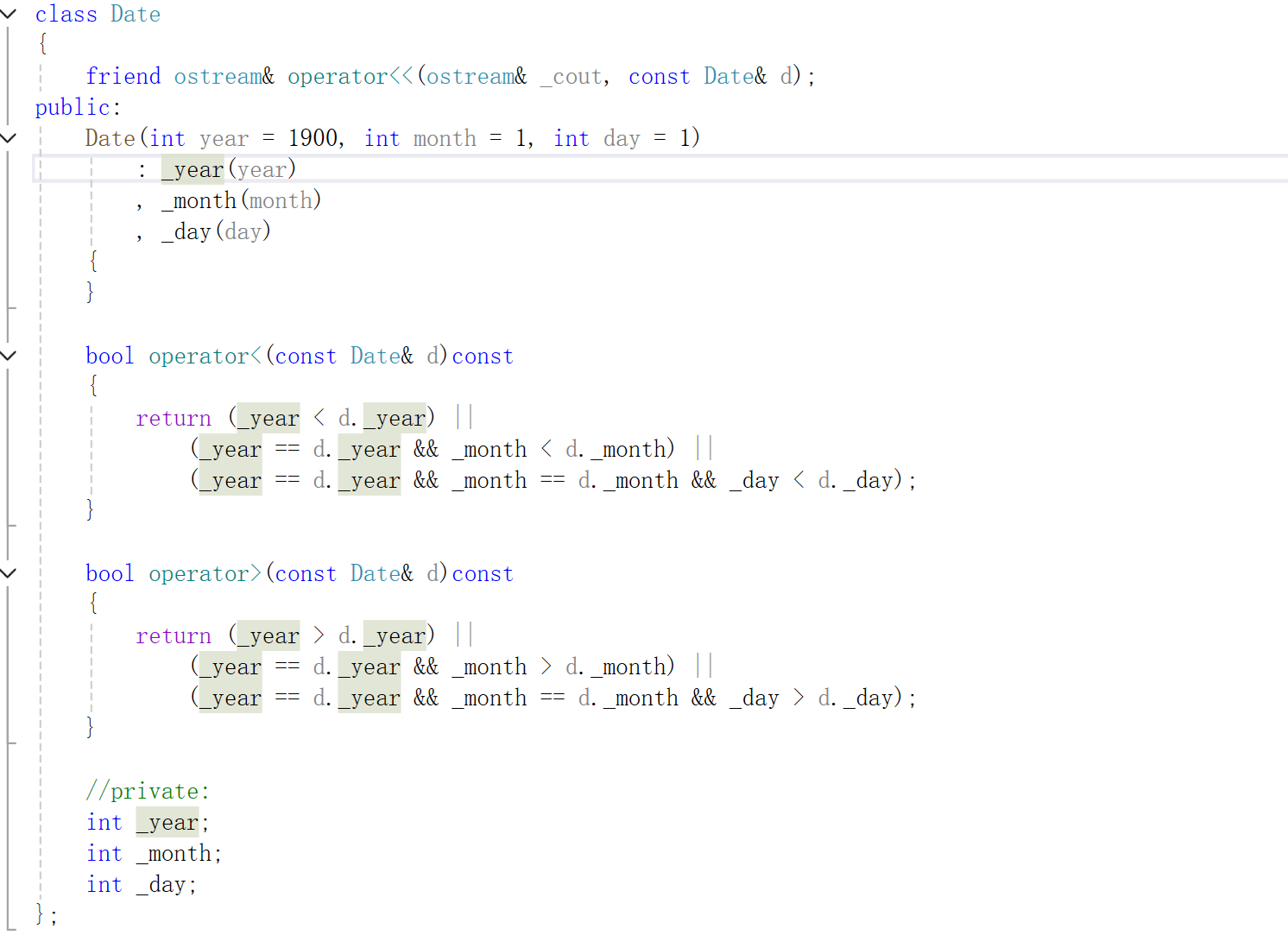
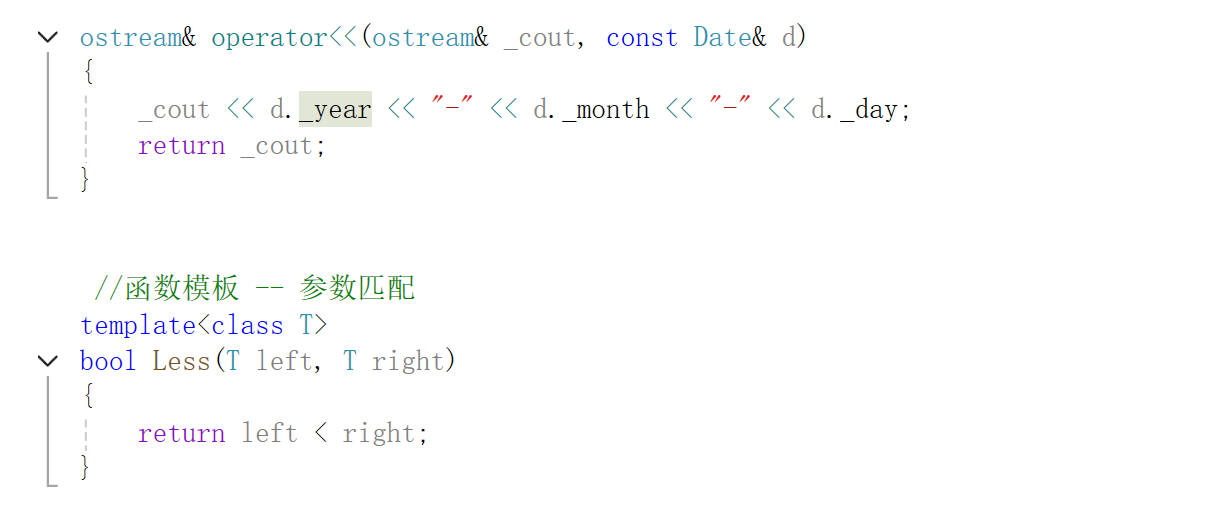
就是这个,我们上个博客也说了,如果我们传入Date*的形式,此时的比较就会出现问题,达不到我们的预期结果,我们上个博客的解决方案是自己写了一个仿函数,但是我们也可以用模板特化来解决。

这个就是对一些特殊情况的处理,编译器会调用最匹配的,遇到特殊情况直接就走这个函数了。

当然也可以这样解决这个问题。
这个和函数模板是可以同时存在的,Date*时会优先走这个,因为这个更匹配。
我们下面来看一种很恶心的情况。
就是假设我们上面的那个类传参的时候需要涉及到深拷贝问题的话,我们就需要加上引用了,但是又无法传入常量了,此时就需要加上const了。
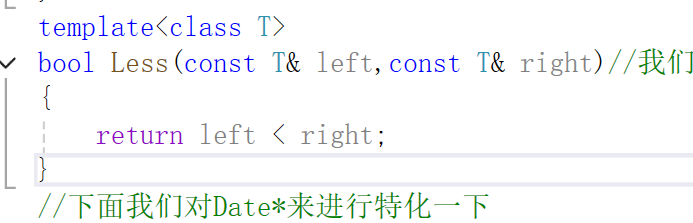
就是这种形式了。
下面我们来特化一下。

此时我们发现报错了,我们来分析一下,为什么会报错呢?
因为上面的函数模板的const修饰的是left这个引用本身,表示left指向的内容不能改变,而下面的const修饰的是这个*left,表示指针指向的内容不能改变,类型不同所以就报错了。
如果理解不了上面说的我来举个例子。
- 指针所指向的内容不可变:这种情况的写法是
const int* p或者int const* p。这两种写法是等价的,都表示指针p可以指向不同的地址,但是不能通过p来修改其所指向的整型值。例如:
- 此时const指向*p,表示指向的内容不能改变,也就是a的值不能改变。
- 指针本身不可变(指向不能改变):写法是
int* const p。此时指针p的指向在初始化后就不能再改变,但是可以通过p来修改其所指向的内容。例如:
- 就是这种了,const修饰的是指针,表示我们指针指向不能改变,就是我们的p指针只能指向a的地址不能改变,但是a的值此时是可以改变的。
上面就是这个道理。

此时这样就ok了。
2.1.1 全特化
我们下面来看一下类模板的特化吧。

这是我们的类模板,它是无法像函数模板那样重载的。
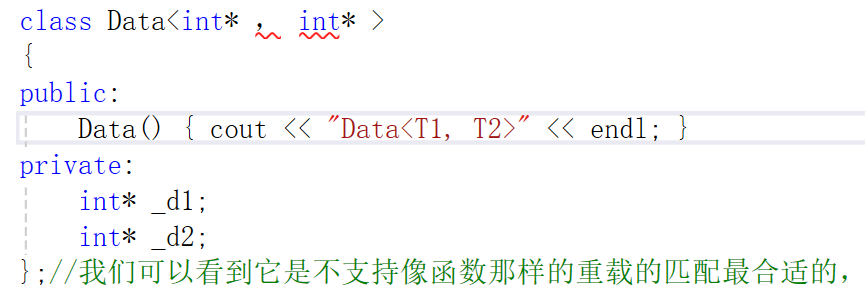
我们可以看到它是不支持像函数那样的重载的匹配最合适的,类是需要实例化的,所以这时候我们只能用特化了。
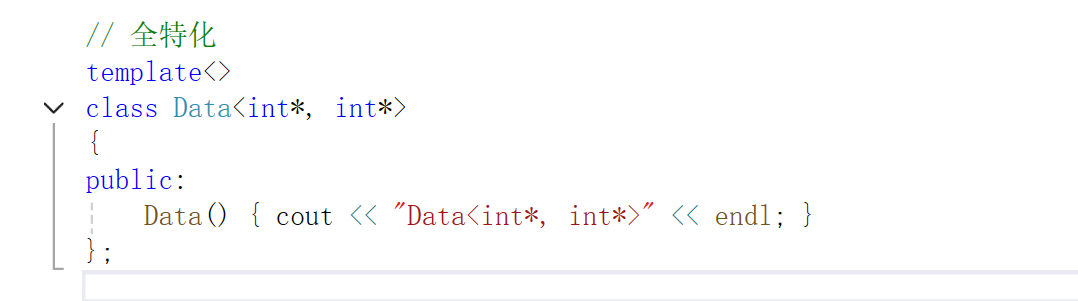
这样就可以了。
2.1.2 偏特化
这是全特化,还用偏特化呢。

这个就是表示,如果你第二个参数传的是int,就优先使用这个特化,这种叫做偏特化。
这里为什么模板参数只有一个呢?
如果下面有不确定的类,此时就需要先声明一个模板参数了
下面还有几种偏特化的例子,我们来看一下吧。

这个就是,如果传的是指针的话就优先使用。
我们来测试的看一下吧。

大家可以看一下应该输出什么结果。

大家可以对一下答案。
2.2 模板分离编译
2.2.1 什么是分离编译?


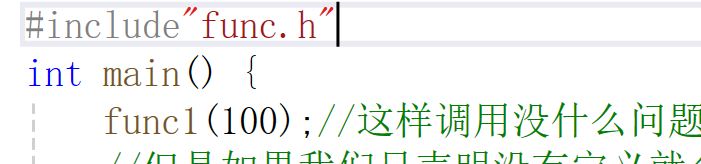

我们发现运行是没有问题的。接下来我们先来讲一下它是如何运行的,方便我们一会儿的讲解。

简单来看一下吧,就是先会预处理展开头文件,为了保证效率,它只会在一个文件中去找,不会和其他文件进行交互,完成预处理之后,它会编译,看看代码是否有语法错误,生成汇编代码,然后再汇编,就是形成编译器能看懂的形式,如果上面的步骤都没问题,那么这个函数就会进入一个叫符号表的地方,存放着它的名字和地址,调用函数的时候,链接的时候,通过call这个函数名字的形式,在符号表中找到地址,此时就会找到这个函数进行调用了。
这个其实是个比较复杂的过程,我只讲了大概。


我们可以看到出现了链接错误,这是怎么回事呢?
因为这里的T没有实例化,不知道是什么类型,他不会编译也不会进入符号表,所以找不到这个函数的地址,我们上面也说了,它只会在单文件中编译,它在头文件中编译的时候,不知道T是什么类型,所以无法编译,最后也不会进入到符号表中,导致链接找地址的时候,找不到这个函数的地址,所以报错了。
解决方法一:

在.cpp文件中加个模板声明。
这个的作用就是告诉编译器这是个模板,然后把它初始化为了int去编译,但是还是有缺陷的,如果你用double啥的,还是会报错,这是它的一个缺陷。
解决方法二:
第二种方案就是直接定义,cpp库中大多都是这样实现的,如果是函数的话,直接定义,如果是类函数的话,短的函数就弄成内敛,长的函数就弄成声明和定义分离,在一个文件中完成。

此时就是直接在.h函数中完成了模板的定义和声明分离,此时,在这个文件中完成定义,此时它就会有地址了,分配空间了,此时就会直接被编译成指令就不会通过链接去找地址了,直接编译为指令,直接call地址。
这种方案是更好的,什么都可以传,没有上面第一种的那种约束。
2.3 typename的使用

![]()
发现是没有问题的。

此时发生了报错,因为类型不匹配,此时可以用到模板。

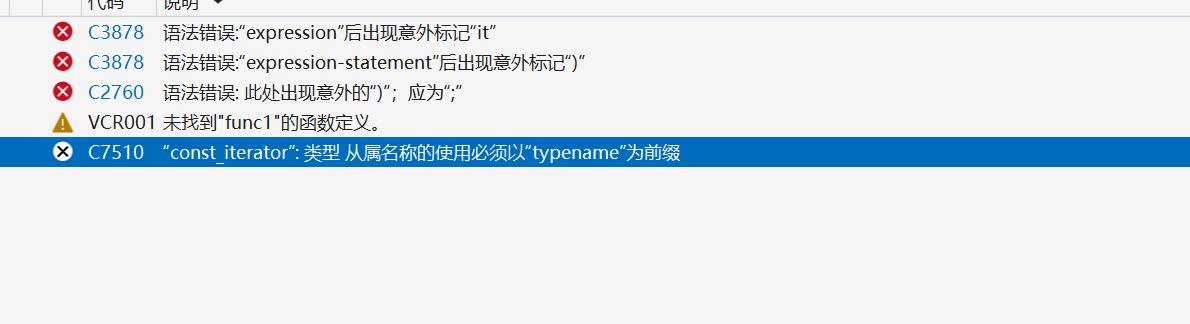
我们运行还是发生了错误。
这是为什么呢?当编译器解析模板代码时,它需要知道 vector<T>::const_iterator 是一个类型。在模板实例化之前,编译器并不知道 T 具体是什么类型,也就无法确定 vector<T>::const_iterator 是不是一个类型。加上 typename 关键字是为了告诉编译器,vector<T>::const_iterator 是一个类型,而不是一个成员变量或者其他东西。
我们只需要加上typename即可。
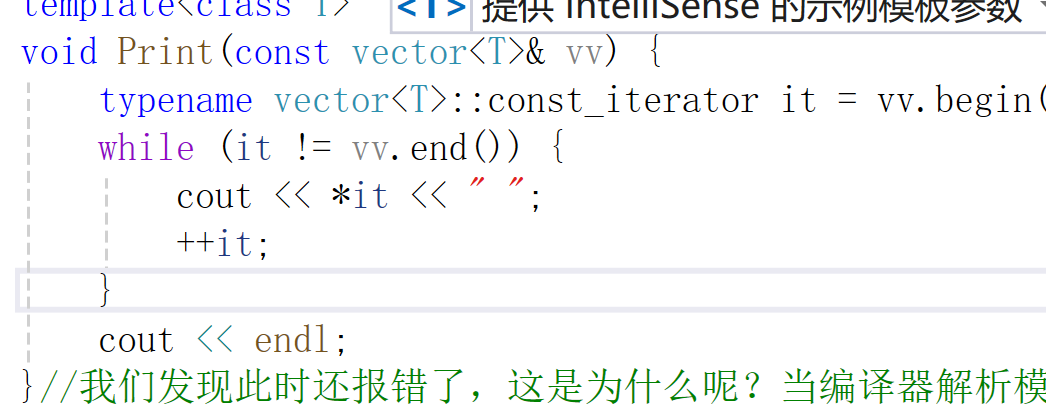

没问题了。

我们要是还想打印链表该怎么办呢?
只需要改变一下参数的使用即可。

此时就完成了操作。

没有问题。
三.结束语
感谢大家的查看,希望可以帮助到大家,做的不是太好还请见谅,其中有什么不懂的可以留言询问,我都会一一回答。 感谢大家的一键三连。
