python实战项目65:drissionpage采集boss直聘数据
python实战项目65:drissionpage采集boss直聘数据
- 一、需求简介
- 二、流程分析
- 三、完整代码
一、需求简介
boss直聘网站近期改版,改版之后代码需要做相应的升级维护。drissionpage采集网页数据是一种不错的方式,笔者认为比Selenium好用,使用方法大家可以自行查阅资料。boss直聘改版之后的页面如下:
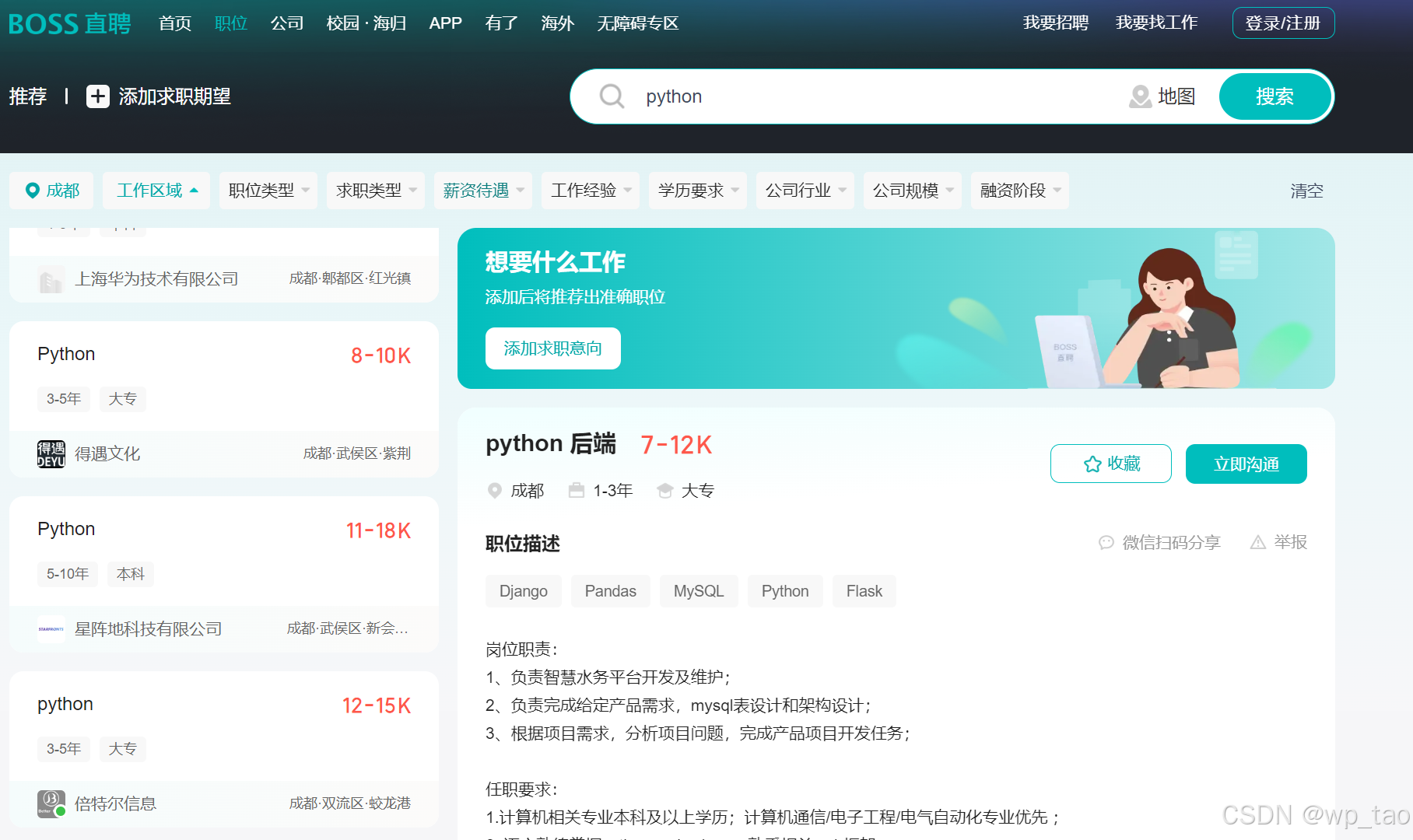
二、流程分析
drissionpage采集页面数据的流程无非是操作浏览器打开页面(第一次打开页面时需要登录),逐个点击职位元素,监听数据包,获取数据及保存数据。抓包,找到职位信息所在的数据包:
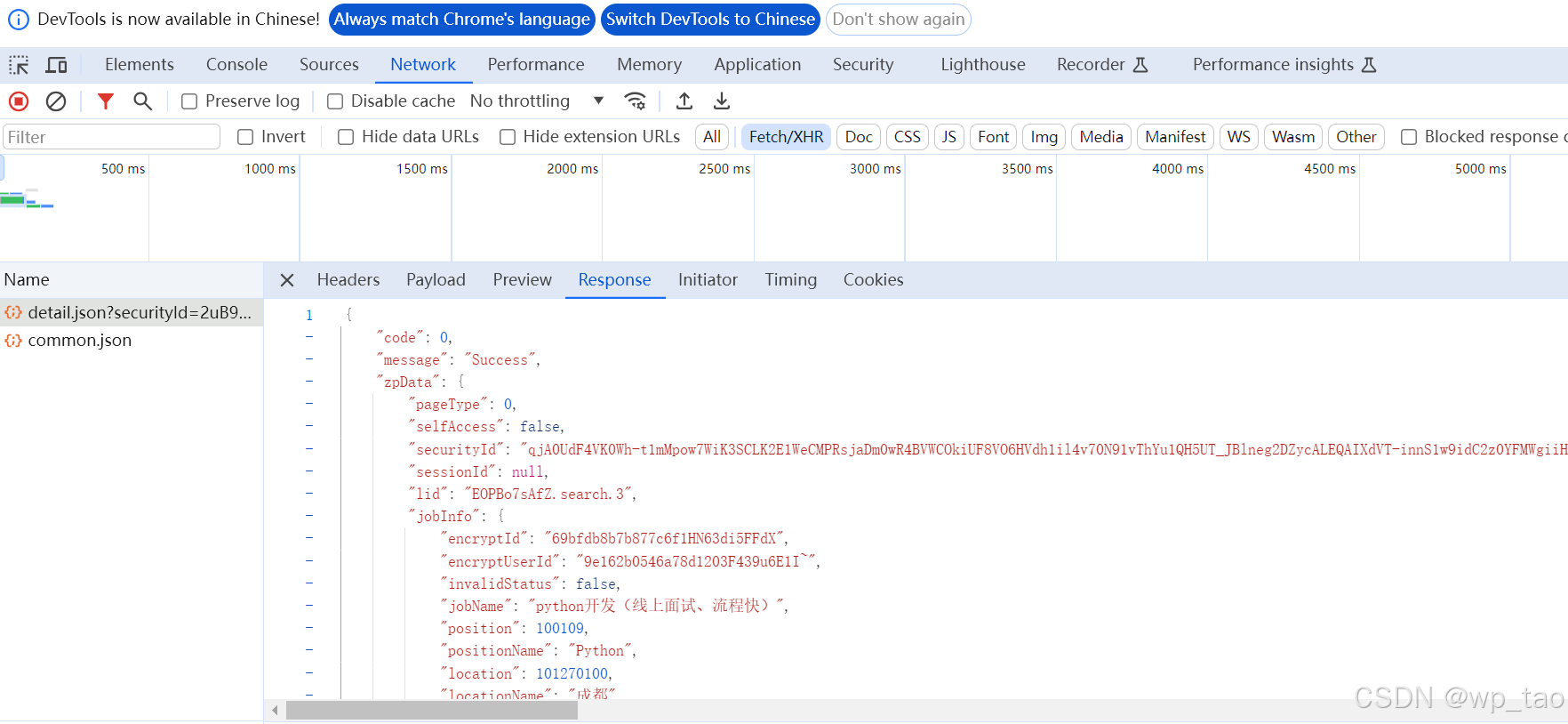
三、完整代码
代码编写的过程不再赘述,代码编写过程比较简单,需要注意的是,drissionpage定位及点击元素时,xpath表达式之前要添加“x:”。完整代码如下: