如何使用 Vector 连接 Easysearch
Datadog 旗下的 Vector 是一款高性能的可观测性数据流水线工具,用于收集、转换和路由日志、指标和追踪数据。它通常用在需要高效处理大量可观测性数据的场景,并能替代 Logstash,且在性能、资源消耗等方面具有明显优势。
下面是一个表格,对比了 Vector 和 Logstash 的主要特性,帮助你快速了解它们的核心差异:
特性 | Vector | Logstash |
开发语言 | Rust | JRuby/Java |
性能 | 高性能,单节点吞吐量约 10-15万事件/秒 | 标准配置下单节点处理能力约 1-2万事件/秒 |
资源消耗 | 低内存占用(约 100-150MB/万事件/秒) | 高内存占用(约 500MB-1GB/万事件/秒) |
可靠性 | 支持至少一次(At-Least-Once)传输保证 | 依赖持久化队列 |
数据处理能力 | 强大的 VRL 语言,支持解析、转换、过滤、聚合等 | 丰富的过滤器插件(如 Grok、Mutate),支持 Ruby 脚本 |
配置方式 | TOML, YAML, JSON | 自定义配置文件格式 |
扩展性 | 组件化架构,支持自定义组件(需Rust) | 丰富的插件生态系统(Ruby) |
部署模式 | Agent, Aggregator, Sidecar, Daemon | 主要作为独立代理 |
Vector 的应用场景
Vector 的应用场景相当广泛,主要包括:
- 统一日志和指标收集:Vector 能同时处理日志(Logs)、指标(Metrics)和追踪(Traces)这三类可观测性数据 ,并支持从日志中提取指标 。
- 作为日志收集器:它可以替代 Fluentd、Logstash 等工具 ,从文件、Kafka、Syslog 等多种数据源采集日志,并进行解析、过滤、聚合等处理,然后发送到 Elasticsearch、ClickHouse、S3 等目的地 。
- 数据加工和路由:Vector 的 Transform 组件(特别是 VRL - Vector Remap Language)支持复杂的数据处理逻辑,例如:
- 解析非结构化日志:将原始的文本日志解析成结构化数据 。
- 字段操作:增删改字段、条件过滤、数据采样 。
- 数据路由:根据内容将数据分发到不同的存储或分析系统 。
- 部署灵活性:Vector 支持多种部署模式以适应不同架构:
- Agent 模式:以 DaemonSet 形式部署在每台主机上,统一收集该主机上所有容器的日志和指标 。
- Sidecar 模式:作为 Sidecar 容器与业务容器部署在同一个 Pod 中,更适合需要隔离或自定义收集策略的场景 。
- Aggregator 模式:作为中心聚合节点,接收来自多个 Agent 的数据,进行集中处理和转发 。
Vector 对比 Logstash 的优势
- 卓越的性能与极低的资源消耗:得益于 Rust 语言的高效内存管理和无垃圾回收(GC)机制,Vector 的吞吐量显著高于 Logstash(可达数倍甚至十倍),同时CPU和内存占用却低得多。这意味着在相同硬件条件下,Vector 能处理更多数据,尤其适合资源敏感的环境(如容器化部署)和高数据量场景。
- 更精细的数据处理能力 (VRL):Vector 的 VRL 语言语法简洁且功能强大,能够高效执行日志解析、字段操作、条件过滤等复杂逻辑 。虽然 Logstash 的 Filter 插件也非常丰富(如 Grok 解析),但在处理复杂逻辑时性能开销较大。
- 更高的可靠性与数据安全:Vector 内置了至少一次(At-Least-Once)传输保证,并提供磁盘缓冲(Buffer)机制(可在内存缓冲和磁盘缓冲间选择),这在网络波动或下游服务故障时能有效防止数据丢失。Logstash 虽然也支持持久化队列,但 Vector 的实现更现代化和高效。
- 部署灵活性与架构现代化:Vector 支持 Agent、Aggregator、Sidecar 等多种部署模式,能更好地适应云原生环境(如 Kubernetes),实现更灵活的数据收集与聚合方案 。
- 统一的数据处理:Vector 能够统一处理日志、指标和追踪数据,避免了维护多套数据收集链路的复杂性。
实战
为了演示,本篇采用 docker compose 的方式直接拉起 Graylog 和 Easysearch 相关的服务。
services:vector:image: "timberio/vector:0.49.0-debian"volumes:- "./vector.yaml:/etc/vector/vector.yaml:ro"networks:- vectordepends_on:easysearch:condition: "service_healthy"easysearch:image: "infinilabs/easysearch:1.13.1-2180"environment:- "cluster.name=es1"- "ES_JAVA_OPTS=-Xms1g -Xmx1g"- "bootstrap.memory_lock=true"- "EASYSEARCH_INITIAL_ADMIN_PASSWORD=changeme"- "elasticsearch.api_compatibility=true"#- "security.ssl.http.enabled=false"healthcheck:test: ["CMD", "curl", "-f","-kuadmin:changeme", "https://localhost:9200"]interval: 10stimeout: 5sretries: 3ulimits:memlock:hard: -1soft: -1nofile:soft: 65536hard: 65536ports:- "9222:9200"#- "9300:9300"restart: "on-failure"networks:- vectornetworks:vector:driver: "bridge"vector 使用的配置文件 vector.yaml 如下。
sources:demo_logs:type: demo_logsinterval: 1format: jsoncount: 5sinks:easysearch:inputs:- demo_logstype: elasticsearchendpoints:- "https://easysearch:9200"bulk:index: "vector-test"auth:strategy: "basic"user: "admin"password: "changeme"tls:verify_certificate: false这个 Vector 配置文件定义了一个简单的日志流水线:从模拟日志源(demo_logs)生成 JSON 格式的日志,并将其发送到 Easysearch,总共发送 5 条。
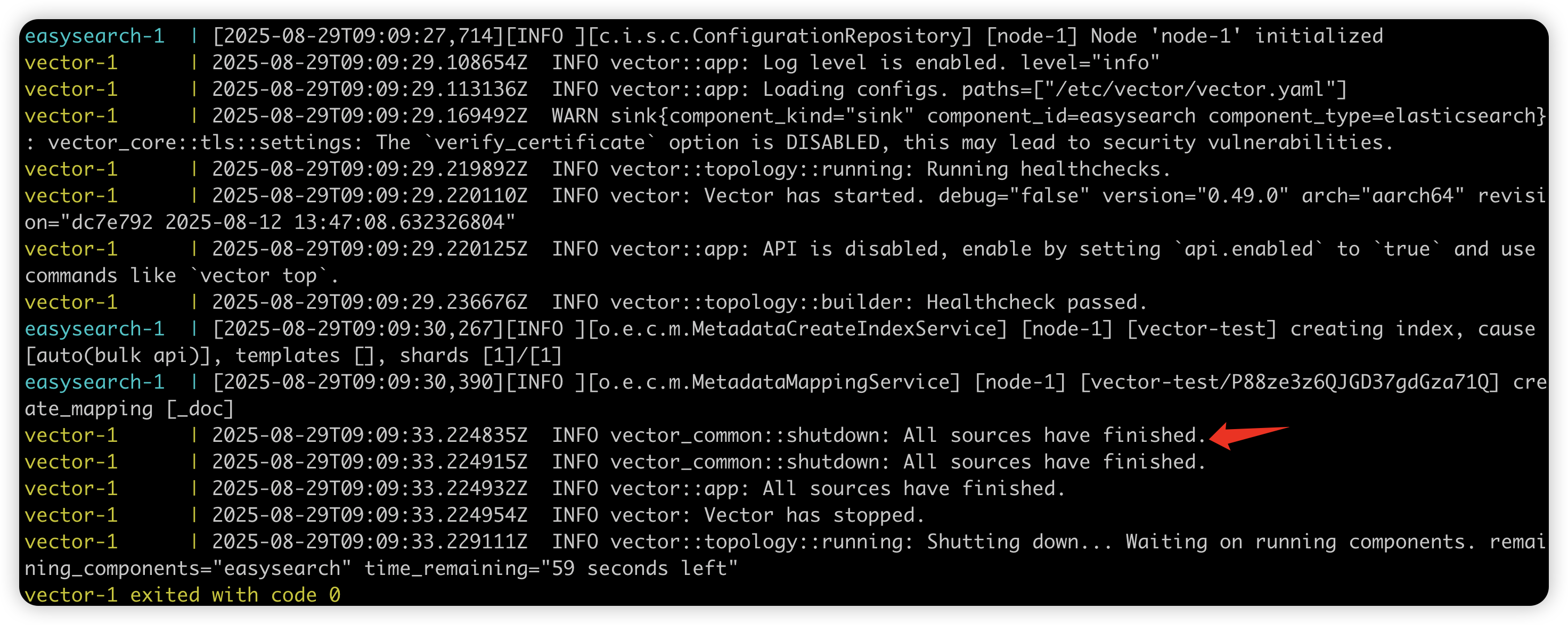
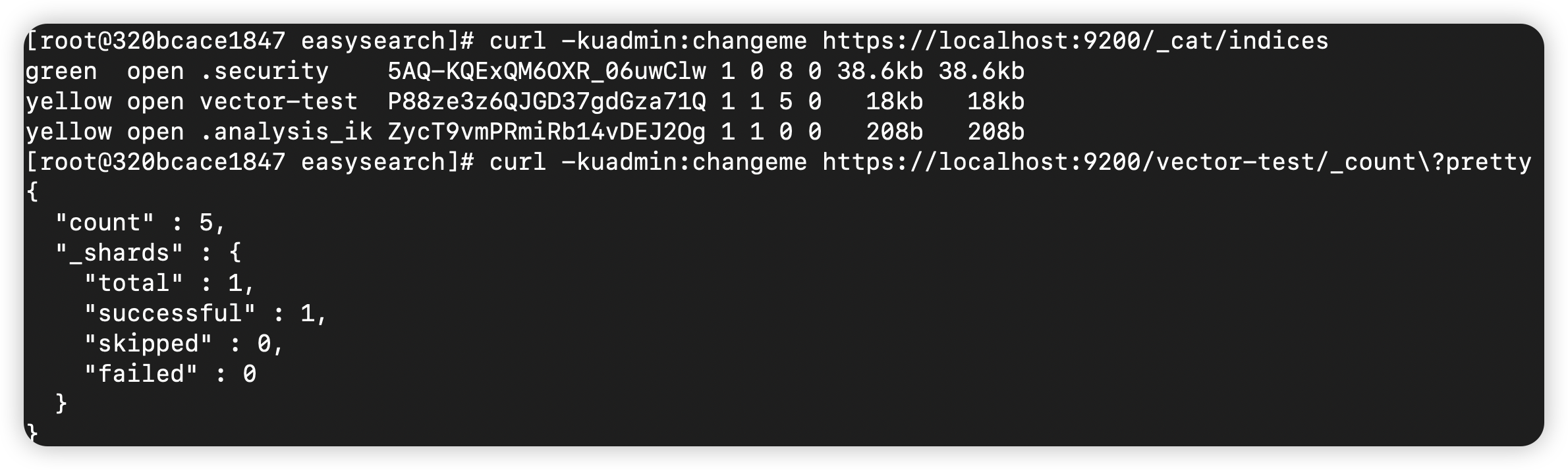
上面的 DEMO 只是简单的测试了数据写入,Vector 更多的数据解析、加工、计算部分的内容请参阅其官方文档。