2026届大数据毕业设计选题推荐-基于Python的出行路线规划与推荐系统 爬虫数据可视化分析
🔥作者:it毕设实战小研🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
- 1、出行路线规划与推荐系统数据可视化分析-前言介绍
- 1.1背景
- 1.2课题功能、技术
- 1.3 意义
- 2、出行路线规划与推荐系统数据可视化分析-研究内容
- 3、出行路线规划与推荐系统数据可视化分析-开发技术与环境
- 4、出行路线规划与推荐系统数据可视化分析-功能介绍
- 5、出行路线规划与推荐系统数据可视化分析-论文参考
- 6、出行路线规划与推荐系统数据可视化分析-成果展示
- 6.1演示视频
- 6.2演示图片
- 7、代码展示
- 8、结语(文末获取源码)
本次文章主要是介绍基于Python的出行路线规划与推荐系统 爬虫数据可视化分析
1、出行路线规划与推荐系统数据可视化分析-前言介绍
1.1背景
随着城市化进程不断加快和人口密度持续增长,传统出行方式已难以满足用户日益多样化的出行需求,交通拥堵、路线选择困难等问题日益凸显。现有的出行规划平台多数缺乏个性化推荐机制,无法根据用户历史偏好和实时交通状况提供精准的路线建议,导致用户出行效率低下且体验不佳。基于上述问题,开发一套智能化的出行路线规划与推荐系统显得尤为重要。
1.2课题功能、技术
本系统采用Python作为核心开发语言,运用Django后端框架与Vue前端技术构建了完整的Web应用架构;通过协同过滤算法实现个性化路线推荐功能,结合网络爬虫技术获取实时交通数据,利用Echarts技术构建可视化分析模块。系统主要包含用户端的路线查询、实时导航、周边服务等功能模块,管理端涵盖用户管理、路线维护、系统监控等核心业务,同时提供大屏数据分析功能,支持交通状况统计、用户偏好分析、道路类型分布等多维度数据展示。
1.3 意义
该系统的构建不仅能够有效解决用户个性化出行规划需求,提升出行效率和用户体验,还能为城市交通管理部门提供决策支持数据,具有重要的实用价值和社会意义。通过智能推荐算法的应用,系统能够持续学习用户行为模式,逐步优化推荐精度,为构建智慧交通生态系统奠定了坚实基础。
2、出行路线规划与推荐系统数据可视化分析-研究内容
1、交通数据采集与预处理:系统运用爬虫技术从各大地图平台和交通信息网站实时获取路况数据,包括道路拥堵指数、平均通行时间、事故信息等关键指标。采集到的原始数据通过Python进行深度清洗,剔除无效和重复信息,标准化地理坐标格式,补全缺失的路段信息,为后续的路线规划算法提供可靠的数据基础。
2、用户行为数据存储:基于MySQL数据库构建用户出行偏好存储体系,记录用户历史路线选择、出行时间段、交通方式偏好等行为特征数据,通过合理的数据库设计确保查询效率和数据一致性。
3、协同过滤推荐算法实现:核心算法模块采用协同过滤技术分析用户相似度和路线相似度,通过计算用户-路线评分矩阵生成个性化推荐结果。算法结合实时交通状况和用户历史偏好,动态调整推荐权重,提升推荐精度和实用性。
4、可视化分析与展示:前端采用Vue框架结合Echarts技术构建交互式数据可视化界面,实时展示交通流量分布、用户出行热力图、道路类型统计等多维度分析结果。后端Django框架负责数据接口设计、用户权限管理、推荐算法调用等核心业务逻辑处理。
5、系统集成与性能优化:完成各功能模块开发后,进行全面的功能测试、兼容性测试和负载测试,验证系统在高并发场景下的稳定性表现,优化数据库查询效率和算法响应速度,确保用户获得流畅的使用体验。
3、出行路线规划与推荐系统数据可视化分析-开发技术与环境
- 开发语言:Python
- 后端框架:Django
- 大数据:Hadoop+Spark+Hive
- 前端:Vue
- 数据库:MySQL
- 算法:协同过滤推荐算法
- 开发工具:pycharm
4、出行路线规划与推荐系统数据可视化分析-功能介绍
亮点:(协同过滤推荐算法、爬虫【】、Echarts可视化)
1、用户功能:登录注册、查看路线路线、查看出行路线、查看实时路线、查看周边导航。
2、管理员:用户管理、路线类型管理、出行路线管理、实时路线管理、周边导航管理、系统管理。
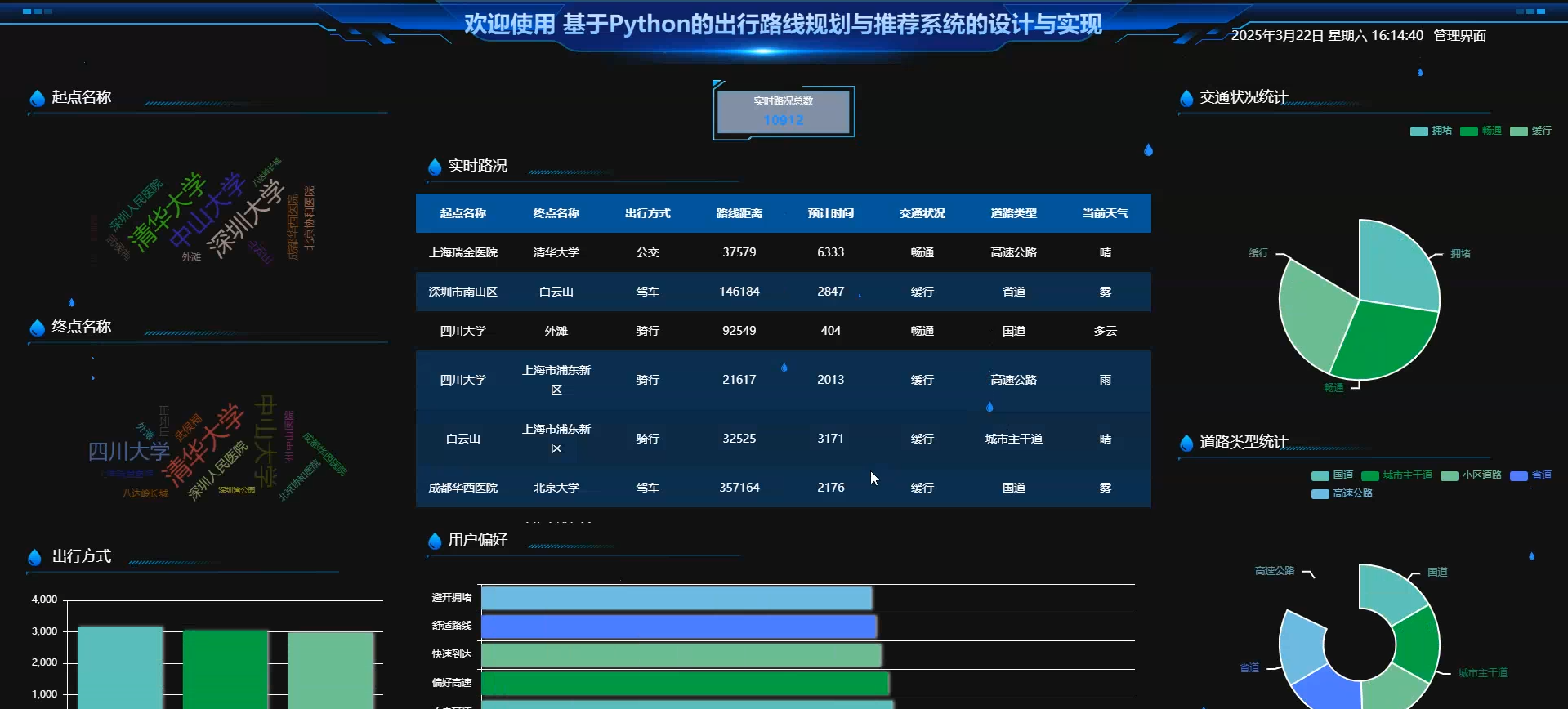
3、大屏可视化分析:起点名称、终点名称、出行方式、实时路况、用户偏好、交通状况统计、道路类型统计、。
4、算法:协同过滤算法。
5、出行路线规划与推荐系统数据可视化分析-论文参考
6、出行路线规划与推荐系统数据可视化分析-成果展示
6.1演示视频
2026届大数据毕业设计选题推荐-基于Python的出行路线规划与推荐系统 爬虫数据可视化分析
6.2演示图片
☀️可视化大屏☀️
☀️登录注册☀️
☀️查看出行路线☀️
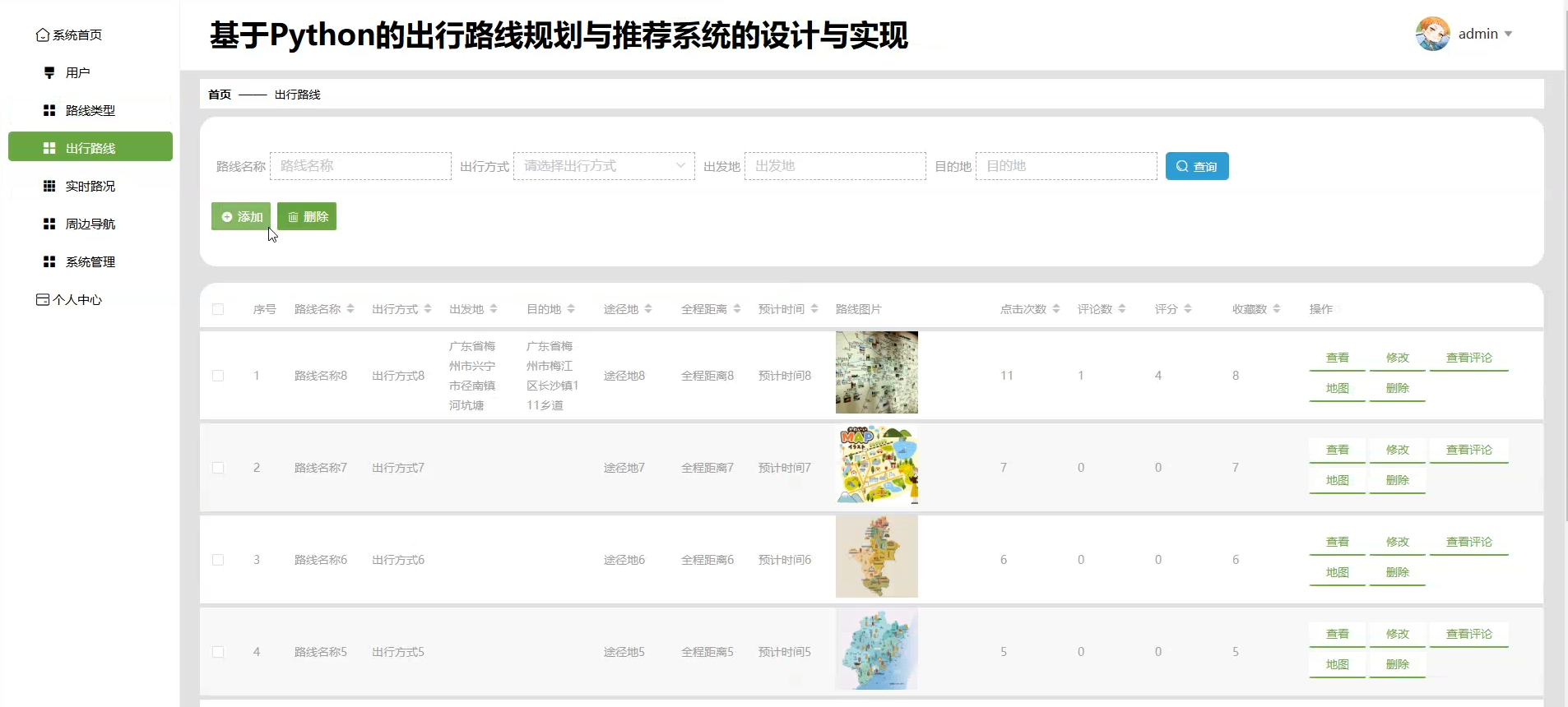
☀️出行路线管理☀️
☀️用户管理☀️
7、代码展示
1.数据清洗【代码如下(示例):】
class RouteDataCleaner:"""出行路线数据清洗处理类"""def __init__(self):self.setup_logging()self.cleaned_data = Noneself.raw_data = Nonedef setup_logging(self):"""配置日志记录"""logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s',handlers=[logging.FileHandler('data_cleaning.log'),logging.StreamHandler()])self.logger = logging.getLogger(__name__)def load_raw_data(self, file_path):"""加载原始数据"""try:if file_path.endswith('.csv'):self.raw_data = pd.read_csv(file_path, encoding='utf-8')elif file_path.endswith('.json'):with open(file_path, 'r', encoding='utf-8') as f:data = json.load(f)self.raw_data = pd.DataFrame(data)self.logger.info(f"原始数据加载完成,共{len(self.raw_data)}条记录")return self.raw_dataexcept Exception as e:self.logger.error(f"数据加载失败: {str(e)}")return Nonedef remove_duplicates(self, df):"""去除重复数据"""initial_count = len(df)# 基于关键字段去重df_deduplicated = df.drop_duplicates(subset=['start_point', 'end_point', 'user_id', 'timestamp'],keep='first')removed_count = initial_count - len(df_deduplicated)self.logger.info(f"去除重复数据: {removed_count}条")return df_deduplicateddef clean_coordinate_data(self, df):"""清洗地理坐标数据"""def validate_coordinates(row):try:lat, lng = float(row['latitude']), float(row['longitude'])# 中国境内坐标范围验证if 3.86 <= lat <= 53.55 and 73.66 <= lng <= 135.05:return Truereturn Falseexcept (ValueError, TypeError):return False# 标记无效坐标valid_coords = df.apply(validate_coordinates, axis=1)invalid_count = len(df) - valid_coords.sum()# 移除无效坐标记录df_clean = df[valid_coords].copy()self.logger.info(f"移除无效坐标数据: {invalid_count}条")return df_cleandef standardize_address_format(self, df):"""标准化地址格式"""def clean_address(address):if pd.isna(address):return None# 去除多余空格和特殊字符address = str(address).strip()address = re.sub(r'\s+', ' ', address)address = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s\-()]', '', address)# 统一地名简写replacements = {'北京市': '北京','上海市': '上海', '天津市': '天津','重庆市': '重庆'}
2.大屏可视化【代码如下(示例):】
@csrf_exempt
def dashboard_data(request):"""大屏数据API"""try:# 获取实时路况数据traffic_data = {'畅通': TrafficData.objects.filter(status='smooth').count(),'缓慢': TrafficData.objects.filter(status='slow').count(), '拥堵': TrafficData.objects.filter(status='congested').count(),'严重拥堵': TrafficData.objects.filter(status='blocked').count()}# 获取出行方式统计transport_data = {'驾车': Route.objects.filter(transport_type='car').count(),'公交': Route.objects.filter(transport_type='bus').count(),'步行': Route.objects.filter(transport_type='walk').count(), '骑行': Route.objects.filter(transport_type='bike').count()}# 获取热门路线popular_routes = Route.objects.values('route_name').annotate(count=models.Count('id')).order_by('-count')[:10]routes_list = [item['route_name'] for item in popular_routes]# 道路类型统计road_types = {'高速公路': Route.objects.filter(road_type='highway').count(),'城市快速路': Route.objects.filter(road_type='express').count(),'主干道': Route.objects.filter(road_type='main').count(),'次干道': Route.objects.filter(road_type='secondary').count()}# 统计数据stats_data = {'totalUsers': User.objects.count(),'todayRoutes': Route.objects.filter(created_at__date=timezone.now().date()).count(),'avgTime': Route.objects.aggregate(avg_time=models.Avg('duration'))['avg_time'] or 0}response_data = {'traffic': traffic_data,'transport': transport_data, 'routes': routes_list,'roadTypes': road_types,'stats': stats_data,'timestamp': timezone.now().isoformat()}return JsonResponse(response_data)except Exception as e:return JsonResponse({'error': str(e)}, status=500)
8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。