机器学习3
七、特征工程
特征工程的目的就是为了在训练模型之前处理数据,让数据变得更好一点,让训练出来的模型效果更好
处理数据的方案:
特征的提取:提取数据集中的信息,进行数据信息的转化,如果遇到缺失值、异常值要进行处理
归一化处理:把数据集中数值压缩在一定范围,避免大值数据这种异常值的影响,可以消除掉数据中的单位因素产生是影响
标准化处理:把数据集变成均值为 x,标准差为 y 这样的分布,机器学习提供的 API 满足均值为 0,标准差为 1【默认情况】
降维处理:去掉数据集中一些不需要的特征信息,这些特征信息对于模型的训练几乎没有影响,属于无效的特征信息
7.1、DictVectorizer
DictVectorizer是sklearn.feature_extraction中用于特征提取和编码的重要工具之一,特别适用于处理字典格式的数据。它可以将字典列表转换为模型可直接使用的数值型特征矩阵,其中每一行代表一个样本,每一列表示一个特征DictVectorizer实例化参数:参数 默认值 说明 dtypenumpy.float64输出数组的数据类型 separator"="当类别特征名称与值之间需要拼接时使用(默认不启用) sparseTrue如果为 True,输出是三元组的稀疏矩阵;如果为False,输出是 Numpy 数组sortTrue是否按字母顺序排序特征名
from sklearn.feature_extraction import DictVectorizer
"""DictVectorizer 不会处理数字,数字是多少处理后就是多少如果是字符串,就会处理,不同的字符串就会作为不同的特征每一个特征就是一列数据,这一列数据满足一个位置上数值为1【通常】,其余位置为0【one-hot】
"""
# 定义一个数据集
data = [{"name": "张三", "address": "成都", "age": 18},{"name": "lisi", "address": "重庆", "age": 20},{"name": "王五", "address": "贵州", "age": 30},
]
# 创建字典特征提取的对象
dv = DictVectorizer(sparse=True)
"""fit_transform 方法等价于先执行 fit 方法、然后执行 transform 方法fit 方法的作用:在特征工程阶段:比如 minMaxScaler(最小值最大值归一化),fit 方法就会从数据集中学习到数据集中的最大值、最小值StandardScaler(标准化),fit 方法就会从数据集中学习数据集中的均值和标准差等信息模型阶段:后期使用机器学习里面的模型---创建出来的对象叫做估计器训练模型 --- 投喂transform 方法的作用:【一定在 fit 方法之后执行】使用 fit 方法的结果去处理数据问题:我们训练模型的时候,是需要把所有数据集的信息都执行fit方法吗?分开执行fit方法?只需要部分数据集执行fit方法?不是把所有数据集都去做 fit 处理训练模型的时候,只能够提供训练集里面的信息给fit,去得到训练集的信息,来训练模型而不可以把测试集的信息给到fit,否则会导致测试集中的数据集已经被处理了,模型后期做验证的时候就会存在误差训练数据集 fit 方法之后,还需要对测试集进行 fit?不需要,测试集就直接使用训练集中的信息(最大值、最小值。。。)
"""
result = dv.fit_transform(data)
# dv.fit(data)
# result = dv.transform(data)
print(result)
# 查看特征名字 --- 有警告
# print(dv.get_feature_names())
print(dv.get_feature_names_out())
"""稀疏矩阵转为numpy里面的数组、matrix
"""
print(type(result)) # <class 'scipy.sparse._csr.csr_matrix'>
result1 = result.toarray() # numpy ndarray
print(result1)
print(type(result1)) # <class 'numpy.ndarray'>
result2 = result.todense() # numpy matrix
print(result2)
print(type(result2)) # <class 'numpy.matrix'>
7.2、countVectorizer
CountVectorizer
是一个在自然语言处理(NLP)任务中常用的工具,用于将文本数据转换为向量形式。它属于sklearn.feature_extraction.text模块的一部分,是Scikit-learn库提供的功能之一。CountVectorizer`主要通过以下方式工作:词汇表构建:首先根据训练集中的文档创建一个固定的词汇表(即所有唯一词的集合)。每个词在词汇表中都有一个对应的索引位置
词频统计:对于每个文档,
CountVectorizer会计算出词汇表中每个词出现的次数,并忽略那些未出现在文档中的词输出格式:最终的输出是一个稀疏矩阵(sparse matrix),每一行对应一个文档,每一列对应词汇表中的一个词。矩阵中的每个元素表示某个词在某个文档中出现的次数
CountVectorizer默认会忽略一些英文中的停用词(如“is”、“the”等),并且会对单词进行小写化处理。这些行为可以通过传递参数来调整,例如设置stop_words='english'可以显式地过滤英语停用词,而lowercase=False则可以禁用自动小写化处理CountVectorizer实例化参数:
| 参数名 | 类型 | 默认值 | 描述说明 |
|---|---|---|---|
stop_words | string 或 list | None | 指定要忽略的停用词集合: - 若设为 'english',则会使用内建的英语停用词列表(如 "is", "the" 等) - 也可以传入一个自定义的停用词列表 - 单个字母(如 "i"、"a")通常会被自动忽略 |
lowercase | bool | True | 是否在分词前将文本统一转换为小写: - 设为 True:自动转换为小写(推荐用于英文文本) - 设为 False:保留原始大小写格式 |
作用:统计词语在各自的文本(文档)出现的次数
问题:这些词语是怎么来的?这些词就是把所有的文档的内容统计在一起,然后去重【这些词还可以通过设置过滤的手段,去掉一些词语】要统计文本中词语的信息,是不是需要知道如何算一个词
# 英文的分词就比较简单,因为每个单词之间有一个空格
life is short, I learning python
# 中文分词我们需要使用第三方库,jieba
人生苦短,我学pythoncountVectorizer 创建出来对象,可以实现统计词语的次数,分词操作也可以完成英文分词
"""统计词语在各自的文档中出现的次数
"""
# 导入类
from sklearn.feature_extraction.text import CountVectorizer
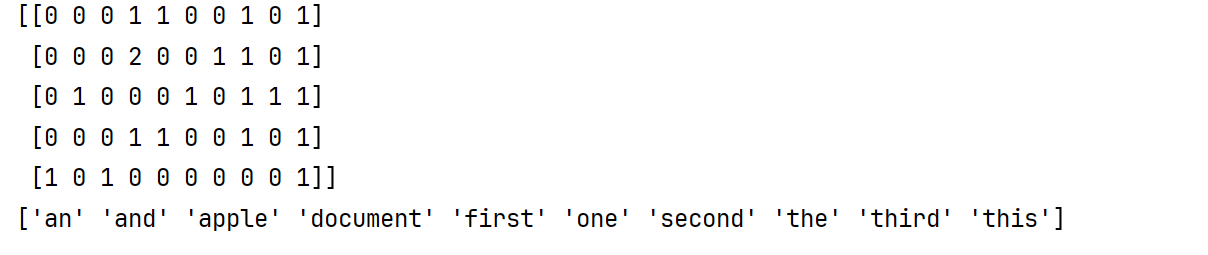
def english_cv():# 准备数据data = ['This is the first document.','This document is the second document.','And this is the third one.','Is this the first document?','this is an apple.']
# 创建对象"""英文:stop_words:哪些词被忽略掉,不参与最终的词表统计,列表lowercase:默认情况下会把所有的词转为小写在分词"""cv = CountVectorizer(stop_words=["is"])# fit_transformresult = cv.fit_transform(data)print(result.toarray())print(cv.get_feature_names_out())
# 中文分词,使用 jieba 工具
"""jieba 工具的使用:1、安装 jieba 库2、jieba 分词介绍:他是一个用来做中文分词的库,基于规则进行分词的,这个规则它自己设置了的,也可以引入自己的规则这个规则的官方名字叫做词典3、jieba 分词有三种分词方案:1.默认模式【精确模式】:一般选择这种方式,按照词典对文本进行分词2.全模式:更加细粒度的分词,分词的结果会更多一点3.搜索引擎模型:就在精确模式的基础之上,把长一点词汇进一步分词4、分词的 api:lcut、lcut_for_search
"""
# 导入jieba分词
"""完成一个分词工具方法,能够把列表文本中的分词结果统计出来(词不可以重复),然后让countVectorizer统计次数
"""
import jieba
def chinese_cv():# data = [# '好好学习,天天向上,今天天气很不错哟,今天只有半天课',# '好好学习,天天向上,今天天气很不错哟,今天只有半天课'# ]data = "在北京天安门看升国旗好开心呀"# 默认模式result1 = jieba.lcut(data)print(result1)# 统计次数cv = CountVectorizer(stop_words=['呀'])result = cv.fit_transform(result1)print(result.toarray())print(cv.get_feature_names_out())# 全模式 cut_all 参数设置为 True# result2 = jieba.lcut(data, cut_all=True)# print(result2)# 搜索引擎模式# result3 = jieba.lcut_for_search(data)# print(result3)
# 引入自己的词典---有的时候这个词典的内容可能不会再jieba分词中生效,为什么?
"""设置的词语的词频可能没有默认词典中的词语的词频高,那么就把词频放大
"""
"""如果说要引入自己的分词规则,就需要自己的定义词典,然后引入到项目中定义词典的步骤:1、创建一个txt文件2、在文件中,每一行就是一个词,一共有三个数据词 词频[option] 词性[option]3、加载自定义的词典,使用方法load_userdict实现,参数就是词典的访问路径
"""
def self_cv():# 加载用户自定义的词典jieba.load_userdict("./my_dict.txt")data = """我冒了严寒,回到相隔二千余里,别了二十余年的故乡去。时候既然是深冬;渐近故乡时,天气又阴晦了,冷风吹进船舱中,呜呜的响,从篷隙向外望,苍黄的天底下,远近横着几个萧索的荒村,没有一些活气。我的心禁不住悲凉起来了。"""result = jieba.lcut(data)print("/".join(result))
# 获取词典中分词过后的词语的内容和词性
"""需要使用到jieba库中的词性方法
"""
import jieba.posseg as pos
def posseg_cv():# 准备文本data = "教育学会会长期间坚定支持民办教育事业!"# 进行分词result = pos.lcut(data)"""item:词a:词性"""for item, a in result:print(item, a)
if __name__ == '__main__':posseg_cv()
7.3、TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)是一种常用的文本特征表示方法,用于评估一个词对一个文档或语料库中的重要程度,比如如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类
词频(Frequency):一个词在语料库中出现的次数,词频越高,说明该词在该文档中越重要
词频概率(Word Probability): 通常指的是归一化后的词频,即一个词在文档中出现的次数除以文档总词数,用来衡量这个词在整个文档中的相对重要性
逆文档频率:词语在整个文档集合中的重要程度
TfidfVectorizer 是 scikit-learn 提供的一个工具,用于将文本数据转换为 TF-IDF 特征矩阵,函数介绍如下:
| 参数名 | 类型 | 默认值 | 描述说明 |
|---|---|---|---|
stop_words | string 或 list | None | 指定要忽略的停用词集合: - 若设为 'english',则会使用内建的英语停用词(如 "is", "the" 等) - 也可以传入一个自定义的停用词列表 - 单个字母(如 "i"、"a")通常会被自动忽略 |
use_idf | bool | True | 是否启用 IDF(逆文档频率)加权: - 设为 True:使用 TF-IDF 权重计算 - 设为 False:仅使用 TF(词频)并归一化 |
smooth_idf | bool | True | 是否对 IDF 进行平滑处理: - 加1平滑,防止除以0的情况,使计算更稳定 |
norm | string | 'l2' | 归一化方式: - 'l1':L1 范数归一化(所有特征绝对值之和为1) - 'l2':L2 范数归一化(默认,欧氏距离归一化) |
"""TF-IDF 用于评估某一个词在文档中的重要程度要计算TF-IDF,就需要分别先计算出TF和IDF,然后相乘TF = countVectorizer 统计的结果IDF(t)=log(文档总数+1/包含该词语的文件的数目数+1)+1
"""
# 导入类
from sklearn.feature_extraction.text import TfidfVectorizer
# 准备数据集
data = ['This is the first document.','This document is the second document.','And this is the third one.','Is this the first document?','this is an apple.'
]
# 创建对象
"""norm:就是把结果在使用正则化技术进行正则化之后在输出,默认使用的是l2范数,可以设置为None、l1范数、l2范数
"""
"""手写代码实现TF-IDF,不要去调用API
"""
tv = TfidfVectorizer(norm="l2")
result = tv.fit_transform(data)
print(result.toarray())
print(tv.get_feature_names_out())
# import math
# print(1.40546511 ** 2 + 1.69314718 ** 2 + 1 + 1 + 1.18232156 ** 2)
# print(1/math.sqrt(1.40546511 ** 2 + 1.69314718 ** 2 + 1 + 1 + 1.18232156 ** 2))
手动实现TF-IDF
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
data = ['This is the first document','This is the second document','And the third one','Is this the first document',
]
# 使用 countVectorizer 进行统计 --- 每个文本中对应的词出现的频率
cv = CountVectorizer()
result = cv.fit_transform(data)
tf = result.toarray()
fenzi = len(data) + 1
fenmu = np.sum(tf!=0, axis=0) + 1
idf = np.log(fenzi/fenmu) + 1
tf_idf = tf * idf
print(tf_idf)
# l2 范数
fenmu2 = np.sqrt(np.sum(tf_idf ** 2, axis=1))
# 需要进行numpy中广播,进行除法运算
re = tf_idf / fenmu2.reshape(-1, 1)
print(re)7.4、MinMaxScaler 归一化(最大最小归一化)
他就是通过缩放的方式,把值缩放在一定范围之内,从而减少了因为不同特征之间的单位的影响,即这个操作属于无量纲化的方法之一【作用:去掉数据中单位不同的影响,这种操作一般需要使用在有数据范围边界的情况下】
按照每一个特征进行计算的
MinMaxScaler
:是一种用于归一化数据的技术,通常用于机器学习和数据分析中。它将每个特征的值缩放到一个指定的范围内,通常是 [0, 1]。MinMaxScaler是sklearn.preprocessing模块中的一个类,可以方便地应用于数据集,MinMaxScaler()`用来实例化对象,参数如下:
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
feature_range | tuple (min, max) | (0, 1) | 指定缩放的目标范围,默认是 [0, 1]。也可以设置为其他范围,例如 (−1, 1) |
copy | boolean | True | 是否复制原始数据(避免修改原始数据)。如果为 False,则尝试进行原地操作(in-place) |
"""数学公式:result = (X-Xmin)/(Xmax-Xmin)默认范围[0,1]API:from sklearn.preprocessing import MinMaxScaler参数:feature_range=(0, 1) --- 缩放过后的值的范围问题:如果数据集中存在异常值,比如数据 1 1 2 3 4 突然来一个数字 1000,那么就会导致其他的数据被压缩在接近于 0 的位置每一个特征之间,进行单独的计算,即以每一列进行最大值和最小值统计计算
"""
from sklearn.preprocessing import MinMaxScaler
from sklearn.feature_extraction import DictVectorizer
# 数据准备 --- 5 个数据(每一行一条数据),2 个特征(每一列一个特征)
data = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
# 创建对象
mms = MinMaxScaler()
result = mms.fit_transform(data)
print(result)
print("=====================")
# 数据集准备 --- 字典数据
data1 = [{"name": "张三", "address": "成都", "age": 18},{"name": "lisi", "address": "重庆", "age": 20},{"name": "王五", "address": "贵州", "age": 30},
]
dv = DictVectorizer(sparse=False)
re1 = dv.fit_transform(data1)
print(dv.get_feature_names_out())
print(re1)
re2 = mms.fit_transform(re1)
print(re2) # 就是把非 one-hot 编码值进行计算,类似于name=张三这样的特征信息,就没有进行归一化,因为不进行归一化也是一样的结果
7.5、normalize 归一化
通过选择不同的范数,实现数据的归一化
l1 l2 max
按照行进行数据处理的
sklearn.preprocessing.normalize(X, norm='l2', axis=1, copy=True, return_norm=False)| 参数名 | 类型 | 默认值 | 含义 |
|---|---|---|---|
X | array-like of shape (n_samples, n_features) | - | 输入数据(二维数组或稀疏矩阵) |
norm | {'l1', 'l2', 'max'}, default='l2' | 'l2' | 使用哪种范数来归一化 |
axis | int, default=1 | 1 | 归一化的方向: 1:按行(每个样本) 0:按列(每个特征) |
copy | boolean, default=True | True | 是否复制原数据(避免修改原始输入) |
return_norm | boolean, default=False | False | 是否返回每个样本的范数值 |
返回值:
| 参数设置 | 返回值类型 | 返回值说明 |
|---|---|---|
return_norm=False(默认) | ndarray 或 sparse matrix | 归一化后的数据(每个样本单位化) |
return_norm=True | (X_normalized, norms) | 一个元组: 1. 归一化后的数据 2. 每个样本对应的范数值 |
L1 范数适合稀疏数据、L2 范数适合强调方向一致性、Max 范数适合强调最大特征影响。根据你的任务目标选择最合适的归一化方式,才能提升模型性能
"""利用范数来实现数据的无量纲化 ---- normalize 把数据单位化,即所有特征的值的和(....)为 1范数:l1:数学公式:re = ||X||/(||X1|| + ... + ||Xn||) 每一条数据的值的和为 1l2:【掌握】数学公式:re = ||X||/sqrt(||X1||^2 + ... + ||Xn||^2) 每一条数据集的值的平方和等于1l∞:数学公式:re = max(X,1) 每一条数据中的值最大的一个为 1API:from sklearn.preprocessing import normalizenormalize(X, norm="l2", *, axis=1, copy=True, return_norm=False)参数:X:输入数据norm:选择的范数,l1 l2 maxaxis:按照每一行进行数据处理
"""
from sklearn.preprocessing import normalize
data = [[1, 2], [3, 4], [5, 6]]
l1 = normalize(data, norm="l1", axis=1)
print(l1)
l2 = normalize(data, norm="l2", axis=1)
print(l2)
max = normalize(data, norm="max", axis=1)
print(max)7.6、标准化
把所有的值的按照均值为0,标准差为1分布
什么是去中心化?就是每一个值减去均值
公式转化
StandardScaler:是sklearn.preprocessing模块中的一个类,用于执行标准化操作,即将数据转换为具有零均值和单位方差的形式,StandardScaler()用来实例化对象,与MinMaxScaler一样,原始数据类型可以是 list、DataFrame 和 ndarray
| 特性/属性/方法 | 说明 |
|---|---|
| 所属模块 | sklearn.preprocessing |
| 主要功能 | 对数据进行标准化(零均值、单位方差) |
| 标准化公式 | z=\frac{x−μ}{σ} 其中 μμ 是均值,σσ 是标准差 |
| 常用方法 | |
.fit(X) | 计算每个特征的均值和标准差 |
.transform(X) | 使用计算出的均值和标准差对数据进行标准化 |
.fit_transform(X) | 先调用 fit,再调用 transform |
.inverse_transform(X) | 将标准化后的数据还原为原始分布 |
| 参数设置 | |
with_mean=True | 是否中心化(减去均值),默认 True |
with_std=True | 是否缩放(除以标准差),默认 True |
| 输入数据类型支持 | list, numpy.ndarray, pandas.DataFrame |
| 输出数据类型 | numpy.ndarray |
| 与 MinMaxScaler 区别 | |
| 标准化 vs 归一化 | StandardScaler:基于均值和标准差 MinMaxScaler:将数据缩放到 [0,1] 区间 |
| 对异常值敏感度 | StandardScaler 对异常值较敏感 |
| 适用场景 | 当数据近似服从正态分布时效果较好 |
"""标准化的操作结果:让数据按照均值为0,标准差为1进行分布对异常值也是敏感的API:from sklearn.preprocessing import StandardScaler属性:mean_:均值scale_:标准差按照特征进行处理,即按照列的维度进行数据处理,每一个均值就是某一个特征的均值,标准差同理....
"""
from sklearn.preprocessing import StandardScaler
data = [[1,2], [2,3], [3,4]]
# 创建对象
ss = StandardScaler()
result = ss.fit_transform(data)
# 结果
print(result)
# 均值
print(ss.mean_)
# 标准差
print(ss.scale_)总结:归一化、标准化操作,是放在分割数据集之前还是之后?应该是在分割数据集之后,因为训练模型之前,是不能够泄露测试机数据集信息的,否则会导致测试不准确,如果泄露了,类似于知道了答案,去做测试【这个思想也要扩展到后期训练模型的时候,也不能够让测试集的内容放在训练集里面,或者测试集、推理过程中使用训练过的内容来使用】
7.7、特征降维
特征降维的目的:去掉数据集中对于模型进行数据识别等操作影响几乎不大的特征信息,减少维度,比如 300 维度变成 100 维度,从而提高计算效率,减少这些没必要的特征信息的影响
特征降维的方法:
低方差过滤法:就是计算某个特征的方差,如果方差小于设置的阈值,那么就舍弃掉
相关系数法:根据计算的结果,进行一个选择操作
PCA:主成分分析,他的实现过程就是把某一个高纬度的特征信息投影在低维度上
低方差过滤法:
项目 内容说明 所属模块 sklearn.feature_selection类名 VarianceThreshold作用 实现低方差过滤的特征选择方法,用于删除那些在样本中变化很小的特征 适用场景 特征值几乎不变(如所有样本都为1或0)的特征可被移除 原理 计算每个特征的方差,若方差小于设定阈值,则认为该特征对模型无帮助,删除它 参数名 threshold,float 类型,默认值 0.0,设置方差阈值。只有方差大于等于该值的特征才会保留,低于该值的特征将被删除"""实现过程:就是通过设置方差阈值,如果某一个特征计算出来的方法的值,小于该阈值,就舍弃掉这个特征信息,否则保留类似于设置阈值这样的参数,我们把他认为是设置超参数,这样的参数的设置,一次性基本上是没办法设置到最佳的,需要通过大量的测试、经验来设置API:from sklearn.feature_selection import VarianceThreshold """ import pandas from sklearn.feature_selection import VarianceThreshold from sklearn.datasets import load_iris import pandas as pd # 数据集准备 iris = load_iris() data, target = iris.data, iris.target print(data[: 2]) print(iris.feature_names) # 通过 pandas 方法 var 计算方差 df = pandas.DataFrame(data, columns=iris.feature_names) std = df.var() print(std) # 创建低方差过滤对象 --- threshold 阈值设置 vt = VarianceThreshold(threshold=0.6) result = vt.fit_transform(data) print(result[:2]) # 获取保留下来特征的索引值 print(vt.get_support(indices=True))过拟合:就模型在训练过程中,在训练数据集中不仅学了到了很好的特征信息【需要模型识别的内容】,还学习到了背景等噪声信息,这样的模型会影响其鲁棒性,在已知的数据集中【训练数据集】模型可以很好的预测结果,但是对于一个新的数据样本,模型无法做出很好的预测
欠拟合:在模型的训练中,训练出来的模型效果差,效果差体现在两个地方:对于训练集表现差、未知数据样本表现也差。一般情况下,发生这样的问题就是数据集的问题、训练次数不够,模型没有得到最佳值【收敛完成】
协方差:反映了这两个变量在这一点上是否一起“偏高”或“偏低”它们各自的平均水平
皮尔逊相关系数
scipy.stats.pearsonr(x, y)` 是 Scipy 库中用于计算两个变量之间 Pearson 相关系数的函数。Pearson 相关系数是衡量两个变量之间线性关系强度和方向的指标。相关系数的范围是 -1 到 1
| 项目 | 内容说明 |
|---|---|
| 函数名称 | pearsonr |
| 所属模块 | scipy.stats |
| 功能 | 计算两个一维数组之间的 皮尔逊相关系数(Pearson Correlation Coefficient) 和 p 值 |
| 适用场景 | 检查两个变量之间是否存在线性关系,常用于数据分析、特征选择、统计检验等 |
函数介绍
函数参数
参数名 类型 必须相同长度 描述 x一维数组(array-like) 是 第一个变量数据(如学习时间、身高等) y一维数组(array-like) 是 第二个变量数据(如考试成绩、体重等),必须与 x长度一致返回值
返回值 类型 描述 correlationfloat 皮尔逊相关系数,取值范围 [-1, 1]: - 1:完全正相关 0:无线性关系 -1:完全负相关 pvaluefloat 假设检验的 p 值,用于判断相关性是否显著: - p < 0.05:相关性显著 - p ≥ 0.05:不显著
"""协方差:反映了这两个变量在这一点上是否一起“偏高”或“偏低”它们各自的平均水平API:np.cov 方法,返回值看对角线,25 就是数据 x y 的协方差,5 125 就是数据 x y 各自的方差[[ 5. 25.][ 25. 125.]]如果协方差为正,表示 x y有相关性
"""
import numpy as np
def my_cov():# 学习时间x = np.array([2, 4, 5, 6, 8])# 考试成绩y = np.array([65, 75, 80, 85, 95])# 计算 x y 的协方差print(np.cov(x, y))
# 皮尔逊相关系数
"""api:scipy.stats.pearsonr(x, y)作用:判断两个变量【一维数组,两个变量对应数据集中的两个特征】呈现什么相关性
"""
from scipy.stats import pearsonr
def p_correlation():x = np.array([2, 4, 5, 6, 8])y = np.array([65, 75, 80, 85, 95])# 计算皮尔逊相关系数 --- 返回值是相关系数、p 值"""相关系数:描述的是x y 之间的相关性p 值:描述的是是否肯定原假设,原假设就是x y之间不相关p<0.05:否定原假设p>=0.05:肯定原假设"""statistic, pvalue = pearsonr(x, y)print(statistic)print(pvalue)
if __name__ == '__main__':p_correlation()
PCA:
主成分分析(Principal Component Analysis,PCA)是一种用于降维的技术,核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差【方差越大,数据越离散,得到的信息量就越大】,同时减少数据的维度
PCA:是sklearn.decomposition中的一个类,用来实现主成分分析,PCA(n_components=None)方法用来实例化对象的参数如下:
n_components 类型 | 含义说明 | 公式/说明 |
|---|---|---|
| 小数(0 < k < 1) | 表示希望保留原始数据信息的百分比(即解释方差比) | 假设我们有特征值 𝜆1,𝜆2,...,𝜆𝑛,则信息保留比可以表示为\frac{\sum_{i=1}^{k}\lambda_i}{\sum_{j=1}^{n}\lambda_j},其中k是选择的主成分的数量,n是原始数据的特征数量 |
| 整数(k) | 表示直接选择前 k 个主成分 | 只保留前 k 个主成分 |
"""PCA:主成分分析,就是利用把高纬度的信息映射到低维度上,用低维度特征去描述高纬度特征,从而实现特征降维API:from sklearn.decomposition import PCA参数:n_components1、小数形式:需要保留多少原特征信息,是一个百分比 --- 这里会根据需要保留的信息去选择多少个维度来描述2、整数形式:需要保留的多少个特征信息,比如原来有4个特征信息,如果设置为3,结果就保留3个特征信息
"""
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
iris = load_iris()
data, target = iris.data, iris.target
# PCA 对象
pca = PCA(n_components=0.95) # 需要保留原来特征信息的95%
result = pca.fit_transform(data)
print(result[: 2])
pca1 = PCA(n_components=3) # 需要保留3个特征信息
result1 = pca1.fit_transform(data)
print(result1[: 2])总结:
sklearn 库中的基本的 API 使用,需要了解各种情况,比如归一化、标准化、数据集加载、数据集分割、特征降维等类型
需要明确各种方案是用来做什么事情的,分别有哪些方法,这些方法又是如何来实现的?数学公式又是怎样的?
fit、transform、fit_transform 方法
特征提取【重点】