【菜狗学聚类】时序数据聚类算法和相关论文
目录
时间序列数据的类型与特性
1、具体时间序列数据类型
1.1 单变量时间序列
1.2 多变量时间序列
1.3 张量场时间序列
1.4 多场时间序列
2、 传统时间序列分析方法
2.1 相似性度量方法
2.1.1 原始数据相似性
2.1.2 特征提取方法
2.2 传统聚类算法
2.2.1 分区方法
2.2.2 层次方法
2.2.3 基于模型的方法
2.2.4 基于密度的方法
方法1:DTW动态时间规整
基于K中心点聚类算法(K-Medoids)的数据聚类
K-means和K-medoids区别
K-means更优的情况
K-medoids更优的情况
方法2:层次聚类算法
✅ 一、提取更丰富的统计特征
✅ 二、使用滑动窗口提取局部动态特征
✅ 三、傅里叶变换 / 小波变换(频域特征)
✅ 四、使用深度学习提取表示(自动特征提取)
✅ 五、手工构造的统计-结构混合特征
论文1:(时序数据—向量表示—分类)多元时间序列分类任务中的一种新型RC方法Reservoir computing approaches for representation and classification of multivariate time series
1、文章内容
2、本质讲解
1️⃣ 储层计算(Reservoir Computing)
2️⃣ 储层模型空间(Reservoir Model Space)关键点:
论文2:(注意力机制+LSTM模型 识别动作模式)通过行动模式识别驾驶异质性的新框架
过程1:动作阶段提取
单变量分割算法:
①数据准备
②设置阈值、初步分类
③合并稳定段落
多变量分割算法
①找转折点
②直接切断
③提取动作阶段
④输出行为阶段库
过程2:动作模式校准
1) 数据准备
2) 聚类实验
3) 行动模式识别 & 可变重要性分析
过程3:基于注意力的双向LSTM模型——动作模式分类
模型结构包含四层:
时间序列数据的类型与特性
时间序列数据具有高维性、顺序性、动态性等特点,根据其观测方式可进一步分为以下几类:
-
单变量 vs 多变量时间序列(Univariate vs Multivariate)
-
规则 vs 不规则采样(Regular vs Irregular Sampling)
-
完整 vs 缺失观测(Complete vs Partially-Observed)
-
定长 vs 可变长序列(Fixed-Length vs Variable-Length)
对于这些类型,不同的建模和聚类策略需做出相应适配。例如,多变量时间序列常需考虑变量间协同变化关系;而不规则采样与缺失观测则通常引入时序插值、自编码器或PIP(Partially-Observed Inference Process)机制。
1、具体时间序列数据类型
1.1 单变量时间序列
-
每个时间点仅包含一个数据值
-
示例:城市温度随时间变化
1.2 多变量时间序列
-
具有相同时间戳的多个时间序列集合
-
示例:三轴加速度计测量的3D加速度
1.3 张量场时间序列
-
排列在规则网格上的数据数组
-
子类型:
-
图和网络的时间序列
-
移动物体空间位置的时间序列(轨迹数据)
-
空间配置和分布的时间序列
-
1.4 多场时间序列
-
多种模态传感器数据的组合
-
示例:陀螺仪、磁力计和加速度计的组合
2、 传统时间序列分析方法
2.1 相似性度量方法
2.1.1 原始数据相似性
-
欧几里得距离(ED):
-
计算简单,但对噪声和失真敏感
-
要求时间序列长度相同
-
-
动态时间扭曲(DTW):
-
可处理不同长度的时间序列
-
通过对齐(扭曲)序列计算距离
-
时间复杂度高(O(n²))
-
-
相关性:
-
检测随机噪声中的已知波形
-
线性复杂度频率空间实现
-
-
互相关:
-
频域中更有效
-
检测随机噪声中波形的最佳方法之一
-
2.1.2 特征提取方法
-
主成分分析(PCA):
-
线性降维技术
-
消除不显著信息,保留显著信息
-
-
多维缩放(MDS):
-
非线性降维技术
-
在低维空间表示高维数据
-
-
K-gram:
-
保持元素序列的顺序特性
-
-
离散傅里叶变换(DFT):
-
将时域信号转换到频域
-
-
离散小波变换(DWT):
-
多分辨率分析
-
-
Shapelets:
-
比较时间序列的子部分而非整个序列
-
2.2 传统聚类算法
2.2.1 分区方法
-
K-means:
-
简单高效,但需预先指定聚类数
-
-
K-medoids(PAM):
-
使用medoids而非means,对异常值更鲁棒
-
-
模糊C-means:
-
允许数据点属于多个聚类
-
2.2.2 层次方法
-
凝聚性聚类(自下而上)
-
分裂性聚类(自上而下)
-
不需要预先指定聚类数
2.2.3 基于模型的方法
-
自组织图(SOM):
-
神经网络方法
-
用于发现时间数据模式
-
2.2.4 基于密度的方法
-
优点:
-
不需要预设聚类数
-
能检测任意形状的聚类
-
能识别异常值
-
-
示例算法:DBSCAN
方法1:DTW动态时间规整
算法笔记-DTW动态时间规整_dtw动态时间规划,r语言-CSDN博客
动态时间规整/规划(Dynamic Time Warping, DTW)是一个比较老的算法,大概在1970年左右被提出来,最早用于处理语音方面识别分类的问题。
简单来说,给定两个离散的序列(实际上不一定要与时间有关),DTW能够衡量这两个序列的相似程度,或者说两个序列的距离。同时DTW能够对两个序列的延展或者压缩能够有一定的适应性。
在时间序列聚类中,相当于用于替代计算欧氏距离这个步骤。
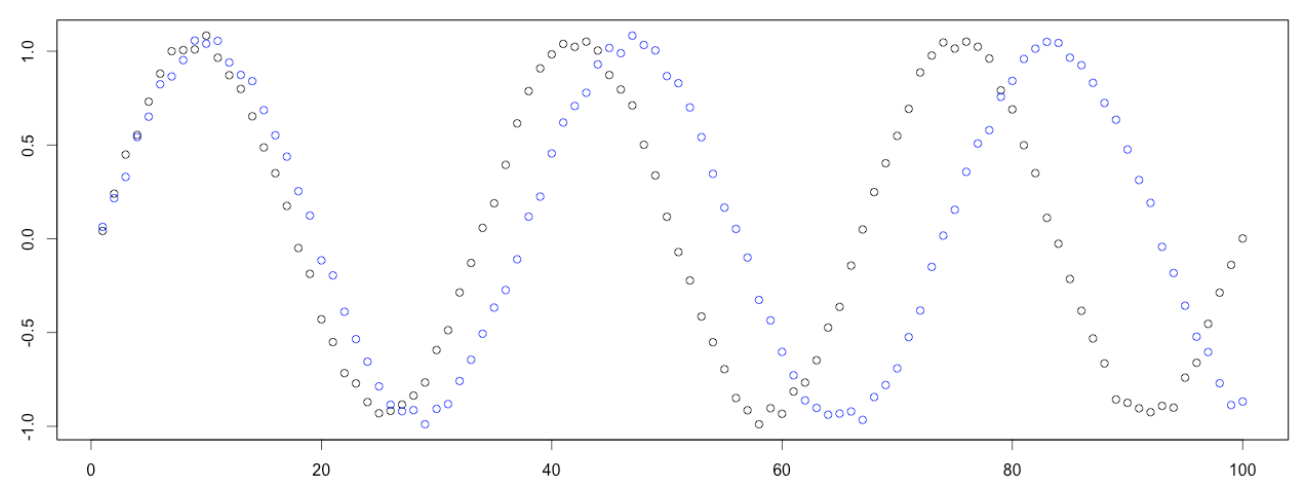
DTW能够计算这两个序列的相似程度,并且给出一个能最大程度降低两个序列距离的点到点的匹配。
给定三个序列:
X:3,5,6,7,7,1Y:3,6,6,7,8,1,1
Z:2,5,7,7,7,7,2X和Y距离函数:
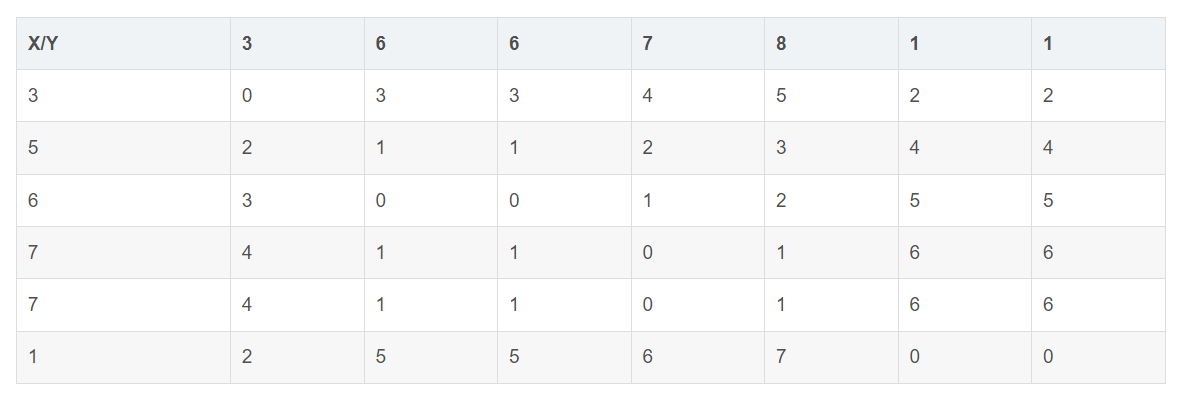
-
初始化边界条件
第一行和第一列的数值直接累加 -
动态规划递推规则
右图每个单元格的值由其左、上、左上三个方向的最小值加上当前单元格的惩罚值。


得到X和Y损失函数:
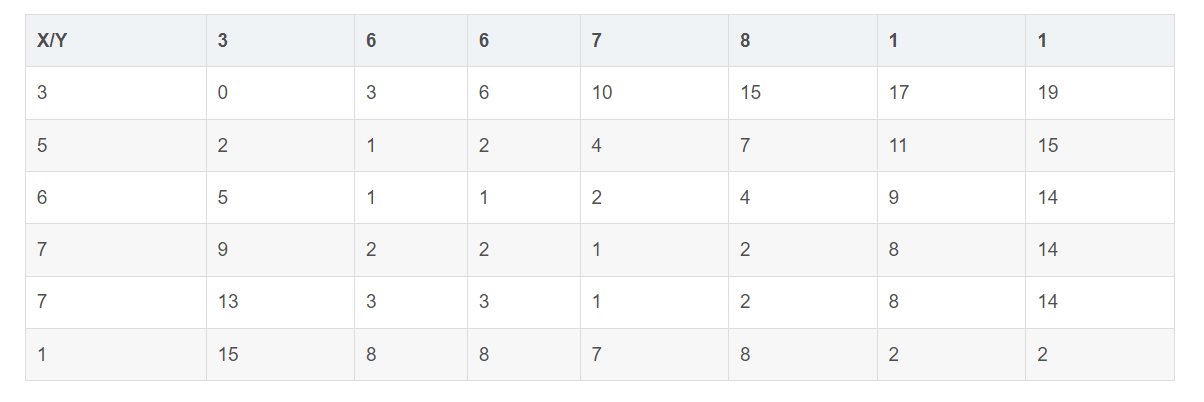
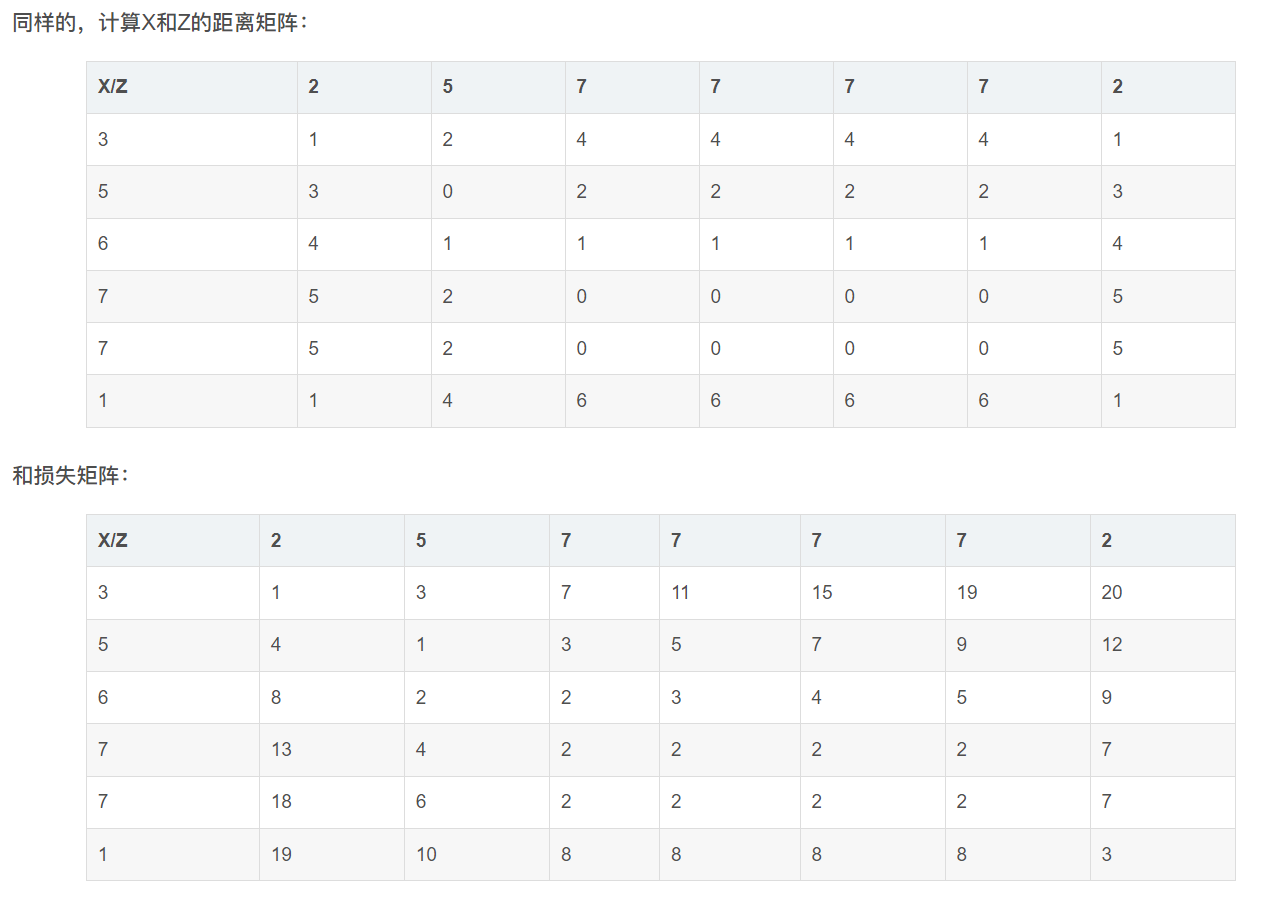
最后,两个序列的距离,由损失矩阵最后一行最后一列给出。所以,X和Y的距离为2,X和Z的距离为3,X和Y更相似。
DTW的缺陷:
首先,它的算法复杂度是O(nm),其中n和m是两个时间序列的长度,这是很高的。其次,它不是距离,因为它不仅不满足分离性质(两个不同时间序列之间的DTW得分可以为零),更重要的是不满足三角不等式,这意味着k维树和球树结构不能使用。这两个限制使得DTW的最近邻分类成为计算密集型算法。第三,DTW允许非常大的时间扭曲,这可能是不希望的。第四,DTW是不可微的,这使得它很难与依赖于最小化目标函数的梯度下降或其变体的机器学习算法一起使用。
基于K中心点聚类算法(K-Medoids)的数据聚类
聚类篇——(三)K-Medoids聚类-CSDN博客
核心思想是通过选择数据集中实际存在的对象作为聚类中心(medoids),而非像K-Means使用均值点。其目标是最小化所有数据点到其所属medoid的总距离(即总成本)。
然后开始迭代过程:对于每一次迭代,将随机选择的一个非中心点替代原始中心点中的一个,重新计算聚类结果。若聚类效果有所提高,保留此次替换,否则恢复原中心点。
对于时间序列数据使用该方法的原因:DTW计算出的距离矩阵直接作为K-medoids的输入,避免K-means对虚拟均值的依赖(时间序列均值无实际意义)。因此不可以直接对于时序数据进行kmeans聚类。而k-中心点是真实序列(如DTW距离之和最小的样本),解释性强。
KMedoids 聚类(K中心点方法)是 KMeans 的一种鲁棒变体,其核心思想是:
-
用真实的数据点作为**“中心点(medoid)”**,不是像 KMeans 那样计算平均值作为中心。
-
对于非欧氏距离(比如 DTW、编辑距离等),或者数据不适合求“平均”的情况,KMedoids 就特别有优势。
-
它只依赖你提供的距离矩阵(而不要求原始特征必须可以“加法”或“平均”)。
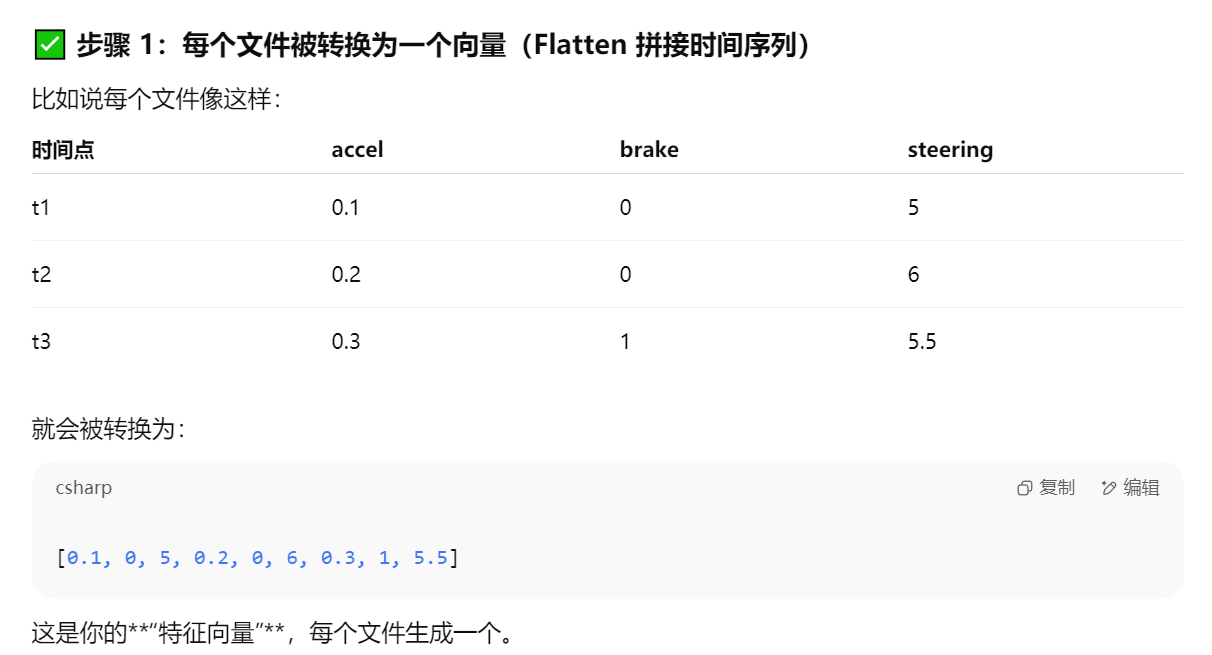


K-means和K-medoids区别
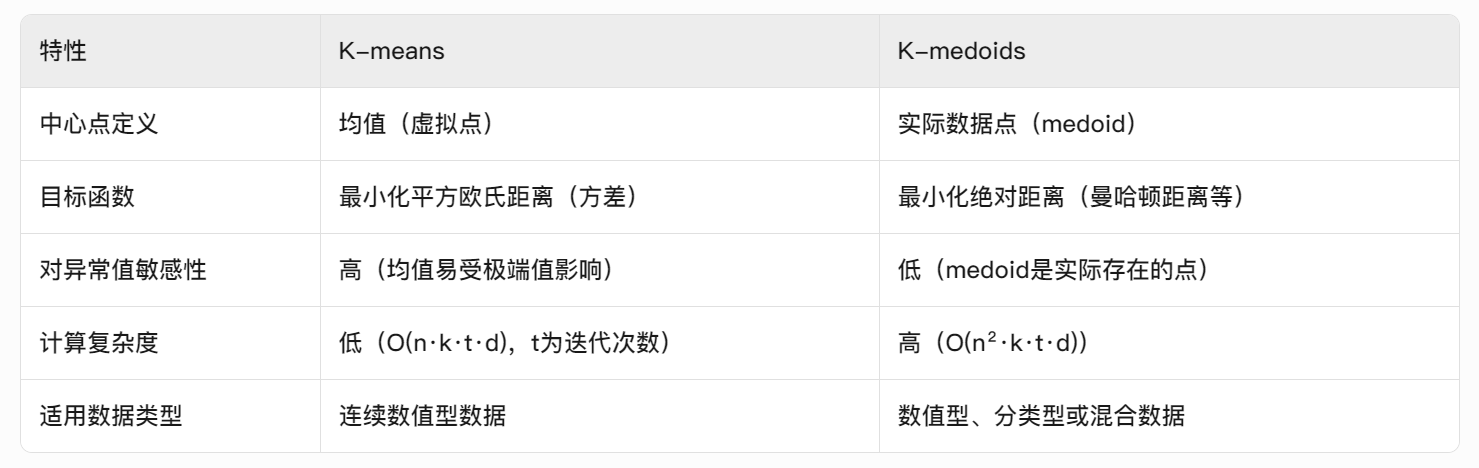
K-means更优的情况
-
数据分布均匀:连续数值型数据且簇呈球形分布(如iris数据集)。
-
大数据集:计算效率高,适合样本量大的场景(如百万级用户画像聚类)。
-
需要快速结果:如实时推荐系统的粗粒度聚类。
K-medoids更优的情况
-
存在异常值或噪声:如医疗数据中可能存在极端检测值。
-
非欧氏空间数据:需用其他距离度量(如曼哈顿距离、余弦相似度)。
-
分类/混合数据:如客户行为数据包含数值(年龄)和分类(性别)。
-
小规模数据:算法复杂度可控(如少于1万样本)。
以下是跑DTW+K-medoids的代码:
import os
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import torch
import torch.nn.functional as F
from sklearn_extra.cluster import KMedoids
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt# 使用指定GPU
device = torch.device("cuda:2" if torch.cuda.is_available() else "cpu")# 1. 读取所有文件并按列选取、归一化
folder_path = '/homexx'
selected_columns = ['utime','brake_sensor','steering_sensor','throttle_sensor','value','accel_dim0','accel_dim2','linear_accel_dim0','orientation_dim0','orientation_dim3','orientation_yaw','pos_dim0','pos_dim1','q_dim0','q_dim1','q_dim2','q_dim3','q_roll','q_pitch','q_yaw','rotation_rate_dim0','rotation_rate_dim2','rotation_rate_ms_imu_dim0','rotation_rate_ms_imu_dim2','vel_dim0']all_series = []
file_names = []for filename in os.listdir(folder_path):if filename.endswith('.csv'):filepath = os.path.join(folder_path, filename)df = pd.read_csv(filepath)[selected_columns]# 标准化每个文件scaler = MinMaxScaler()normalized = scaler.fit_transform(df.values)all_series.append(normalized) # (T, D)file_names.append(filename)# 2. 转换为 Torch tensor 并送入 GPU
normalized_series_torch = [torch.tensor(sample, device=device, dtype=torch.float32) for sample in all_series]# 3. DTW 函数(适配二维序列)
def dtw_torch(x, y):T_x, T_y = x.shape[0], y.shape[0]cost_matrix = torch.cdist(x, y) # shape: (T_x, T_y)dp = torch.full((T_x + 1, T_y + 1), float('inf'), device=x.device)dp[0, 0] = 0.0for i in range(1, T_x + 1):for j in range(1, T_y + 1):dp[i, j] = cost_matrix[i-1, j-1] + torch.min(torch.stack([dp[i-1, j], dp[i, j-1], dp[i-1, j-1]]))return dp[T_x, T_y]# 4. 构建距离矩阵
n = len(normalized_series_torch)
distance_matrix = torch.zeros((n, n), device=device)for i in range(n):for j in range(i, n):dist = dtw_torch(normalized_series_torch[i], normalized_series_torch[j])distance_matrix[i, j] = distdistance_matrix[j, i] = dist # 对称# 5. 聚类并评估
sil_scores = []
range_n_clusters = range(2, 10)best_score = -1
best_k = None
best_labels = None# 转为 CPU numpy (sklearn 不能直接用 GPU tensor)
distance_matrix_cpu = distance_matrix.cpu().numpy()for n_clusters in range_n_clusters:model = KMedoids(n_clusters=n_clusters, metric='precomputed', random_state=42)labels = model.fit_predict(distance_matrix_cpu)score = silhouette_score(distance_matrix_cpu, labels, metric='precomputed')sil_scores.append(score)print(f'n_clusters = {n_clusters}, silhouette score = {score:.4f}')if score > best_score:best_score = scorebest_k = n_clustersbest_labels = labels# 6. 可视化轮廓系数
plt.figure(figsize=(8, 4))
plt.plot(list(range_n_clusters), sil_scores, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Silhouette Score')
plt.title('Selecting the Optimal Number of Clusters')
plt.grid(True)
plt.show()print(f'✅ 最佳聚类数为: {best_k}, Silhouette Score: {best_score:.4f}')结果:等待三四个小时也没跑完,数据量太大了。后面可能要看看怎么更快一点,或者多占几张卡试一下。
如果直接跑k-medoids算法,使用欧氏距离,效果很差:
import os
import numpy as np
import pandas as pd
from sklearn_extra.cluster import KMedoids
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt# 路径设置
folder_path = "xx" # 替换为你的数据路径
file_names = [f for f in os.listdir(folder_path) if f.endswith('.csv')]# 1. 读取并处理每个文件为向量
data_vectors = []
for fname in file_names:file_path = os.path.join(folder_path, fname)df = pd.read_csv(file_path)df = df.drop(columns=['utime'])# 如果每列是一个时间序列变量,例如加速度等:标准化再拼接为向量scaler = StandardScaler()df_scaled = scaler.fit_transform(df) # shape: [time_len, num_variables]# 展平成向量(多个变量拼接)vector = df_scaled.flatten() # 变成1D向量data_vectors.append(vector)# 2. 对齐所有样本长度(截断或补零)
min_len = min(len(v) for v in data_vectors)
data_vectors = [v[:min_len] for v in data_vectors] # 截断到最短长度# 3. 构建样本矩阵(每行一个样本)
X = np.vstack(data_vectors)# 4. 计算样本之间的欧氏距离矩阵
from sklearn.metrics import pairwise_distances
distance_matrix = pairwise_distances(X, metric='euclidean')# 5. 遍历不同的聚类数量并计算轮廓系数
sil_scores = []
k_range = range(2, 15)
best_k = None
best_score = -1
best_labels = Nonefor k in k_range:model = KMedoids(n_clusters=k, metric='precomputed', random_state=42)labels = model.fit_predict(distance_matrix)score = silhouette_score(distance_matrix, labels, metric='precomputed')sil_scores.append(score)if score > best_score:best_score = scorebest_k = kbest_labels = labelsprint(f"最佳聚类数:{best_k},对应的轮廓系数:{best_score:.4f}")# 6. 可视化轮廓系数随k的变化
plt.figure()
plt.plot(k_range, sil_scores, marker='o')
plt.xlabel("聚类数 k")
plt.ylabel("轮廓系数")
plt.title("选择最优聚类数")
plt.grid()
plt.show()# 7. 输出每个文件对应的聚类标签
for fname, label in zip(file_names, best_labels):print(f"{fname} --> 类别 {label}")
scipy是科学计算的库:
-
skew偏度、kurtosis峰度
-
pdist支持多种距离计算,包括欧氏距离、曼哈顿距离等,squareform则用于矩阵的压缩与还原。
-
linkage根据输入的距离矩阵或原始数据,计算聚类间的距离关系,生成层次聚类的链接矩阵(linkage matrix)。 -
dendrogram(绘制树状图)根据linkage生成的链接矩阵,可视化层次聚类的树状图(Dendrogram)。 -
fcluster(扁平化聚类结果)根据链接矩阵和阈值(或聚类数量),将层次聚类结果转换为扁平化的簇标签。
轮廓系数最好的才不到0.1:
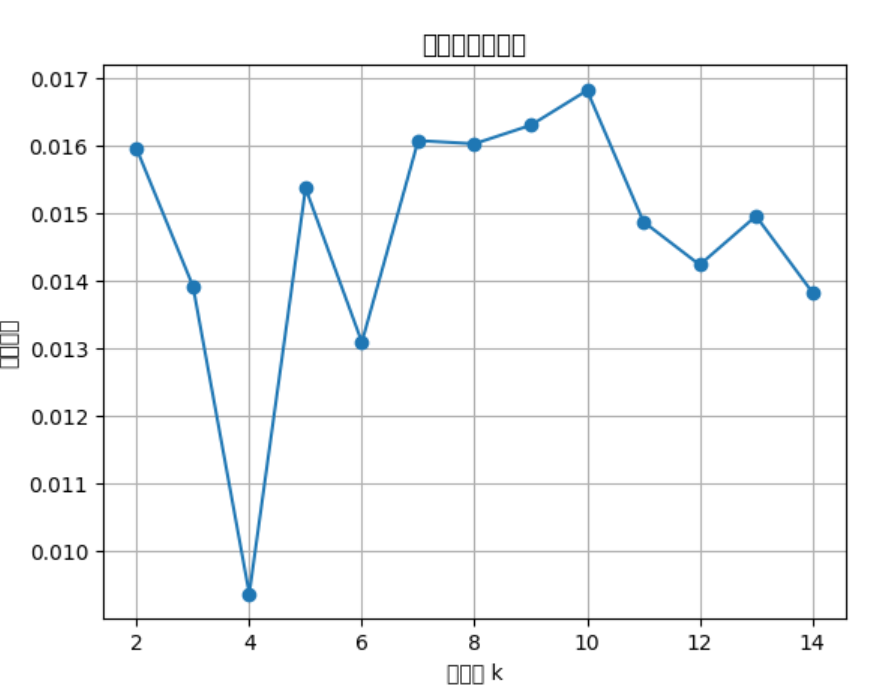
方法2:层次聚类算法
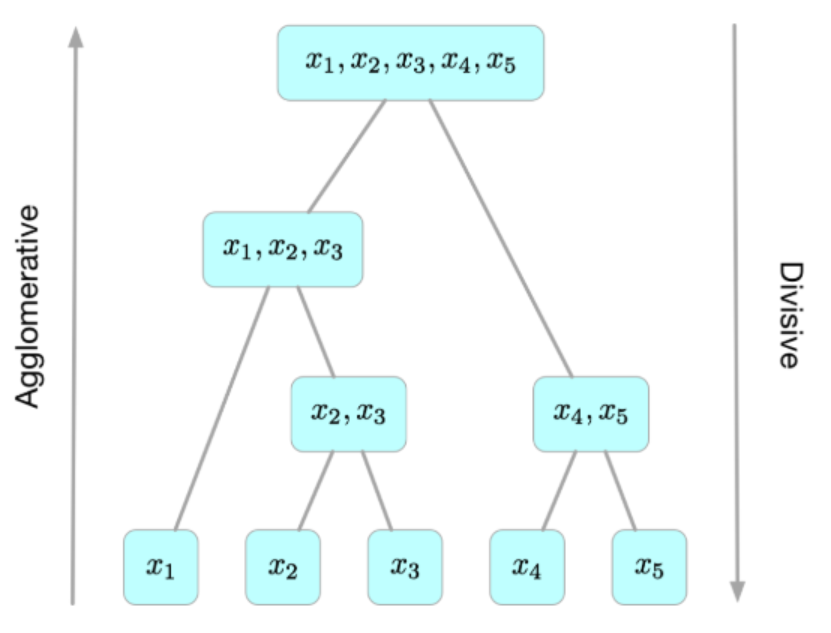
层次聚类算法(Hierarchical Clustering)将数据集划分为一层一层的clusters,后面一层生成的clusters基于前面一层的结果。层次聚类算法一般分为两类:
- Divisive 层次聚类:又称自顶向下(top-down)的层次聚类,最开始所有的对象均属于一个cluster,每次按一定的准则将某个cluster 划分为多个cluster,如此往复,直至每个对象均是一个cluster。
- Agglomerative 层次聚类:又称自底向上(bottom-up)的层次聚类,每一个对象最开始都是一个cluster,每次按一定的准则将最相近的两个cluster合并生成一个新的cluster,如此往复,直至最终所有的对象都属于一个cluster。
层次聚类算法是一种贪心算法(greedy algorithm),因其每一次合并或划分都是基于某种局部最优的选择。
无论什么传统方法,都是提取每个文件的特征,再对特征向量做这个聚类方法的聚类。因此关键应该是如何 提取富含时间信息 和 提取其他特征信息更全面的特征向量。
如果你不想仅仅提取每列的两个统计量(均值+标准差),而是希望保留更多时间序列的信息,可以考虑如下几种策略,它们各有特点,适合不同场景:
✅ 一、提取更丰富的统计特征
| 方法 | 描述 |
|---|---|
| 最小值 / 最大值 | 捕捉极端行为 |
| 中位数 / 四分位数 | 抵抗异常值影响 |
| 偏度(Skewness) / 峰度(Kurtosis) | 分布形态信息 |
| 自相关系数 | 捕捉周期性与重复性行为 |
| 上升时间 / 峰值间距等 | 捕捉时间结构特征 |
✅ 推荐使用
tsfresh或tsfel库,可以自动从时间序列提取成百上千的统计特征。
✅ 二、使用滑动窗口提取局部动态特征
例如设定窗口大小 w=50,步长 s=25:
-
将时间序列划分为若干个小片段
-
对每个窗口片段分别提取统计特征(均值、标准差等)
-
将多个窗口的特征拼接或取平均,形成全局向量
✅ 这样可以捕捉局部动态变化,避免全局均值掩盖重要波动。
✅ 三、傅里叶变换 / 小波变换(频域特征)
将时间序列从时域映射到频域,获取其频率分布信息:
-
傅里叶变换 FFT:分析周期性、主频能量等
-
小波变换:适合非平稳时间序列,能同时保留时域与频域信息
输出方式:
-
取前
k个频率成分的幅值作为特征 -
或根据能量分布划分频带统计能量占比
💡 对于传感器数据(如加速度、转角等),频域特征往往能显著提升聚类/识别效果。
✅ 四、使用深度学习提取表示(自动特征提取)
| 方法 | 描述 |
|---|---|
| 1D-CNN | 使用一维卷积提取局部时序模式 |
| LSTM / GRU | 用递归神经网络建模时间依赖 |
| Transformer | 对长序列建模能力更强 |
| 自编码器 | 压缩时序信息为定长向量表示(如 DCAE) |
✅ 输出的是固定长度的高维特征向量,可用于聚类、分类、检索等。
✅ 五、手工构造的统计-结构混合特征
例如:
-
时间序列最大值出现时间
-
第一次达到阈值的时间点
-
上升或下降趋势段的数量和平均持续时间
适用于有明显结构的行为型数据(如驾驶行为)。
| 序号 | 文章 | 分区 | 链接 |
|---|---|---|---|
| 1 | 深度时间序列聚类:综述 | 4 | 深度时间序列聚类:综述 |
| 2 | 时间序列分类:算法和实现回顾 | 3 | 时间序列分类:算法和实现综述 - Inria - French National Institute for Research in Digital Science and Technology |
论文1:(时序数据—向量表示—分类)多元时间序列分类任务中的一种新型RC方法Reservoir computing approaches for representation and classification of multivariate time series
FilippoMB/Time-series-classification-and-clustering-with-Reservoir-Computing: Implement Reservoir Computing models for time series classification, clustering, forecasting, and much more!
1、文章内容
多元时间序列(MTS)的分类已被广泛研究。Reservoir Computing(储层计算,RC)**作为一种高效方法,能够将MTS转换为固定长度的向量表示,并可被标准分类器进一步处理。
尽管RC在训练速度方面具有无可匹敌的优势,但基于传统RC架构的MTS分类器在精度上仍不及全可训练的神经网络。
本文提出了一种名为“Reservoir Model Space(储层模型空间)”的新型方法,这是一种基于RC的无监督技术,旨在学习MTS的向量表示。该方法通过训练线性模型来预测储层动态的低维嵌入,并将每个MTS编码为这些线性模型的参数向量。得益于中间降维步骤,储层模型空间可生成更具判别力的表示,同时保持较高的计算效率。
2、本质讲解
目标:如何让训练超快的RC方法,在多元时间序列分类中也能达到深度学习模型的精度?
作者提出了一个新思路:
不要直接用RC输出的特征,而是训练一个小模型来预测RC的“行为”→ 把这个模型的“参数”当作特征!
思想很像“模型即特征(Model as Feature)”:
-
与其直接提取数据本身,不如看:“一个线性模型怎么学习它的变化模式”
-
把“预测器”变成表示器
1️⃣ 储层计算(Reservoir Computing)
-
RC是一种轻量神经网络架构:
-
固定一个随机RNN(不训练)
-
只训练输出层(通常是线性回归)
-
-
所以速度快,因为不用反向传播训练隐藏层
2️⃣ 储层模型空间(Reservoir Model Space)关键点:
-
将一个多元时间序列 X输入到RC中,得到RC的状态序列 ht
-
接下来不是直接拿 ht 去做分类
-
而是:
学一个线性模型 yt=Wht,拟合某个“降维表示” zt
然后把这个模型的参数 W,当作这个MTS的表示向量!
也就是说,每一条时间序列 → 会被编码成一个线性模型的权重向量。
这样可以捕捉该序列在RC动态空间中的“行为规律”。
效果好的原因:
-
原始RC:直接拿状态序列,信息冗余多
-
本文方法:先降维 → 再拟合 → 参数就是精华
-
类似“逼着模型去压缩、去泛化”,比原始特征更干净
论文2:(注意力机制+LSTM模型 识别动作模式)通过行动模式识别驾驶异质性的新框架
1、使用kmeans/模糊Cmeans聚类(无监督学习技术)
将驾驶员行为聚类为不同的组,从聚类的统计分析中推断驾驶风格。
缺点:缺乏可解释性,未必对应于现实驾驶行为。
2、监督学习训练模型
学习“输入特征、输出标签”之间的关系,模型能够在未标记的数据中分类、预测驾驶行为。
标记数据:从专家知识、其他技术组合获得。
3、无监督学习+统计分析
例如使用主成分分析+kmeans聚类将用户分为谨慎、温和、激进等驾驶风格。
标记方法:分析轨迹数据的均值、分布,为驾驶员分配固定的驾驶概况。
过程1:动作阶段提取
每个单变量有单一的动作趋势。
合并多个变量,识别涉及到的变量。
单变量分割算法:
这个算法的目的是把一条连续变化的曲线(比如速度、加速度等)划分成多个段落,
①数据准备
假设有一条时间序列,比如一个驾驶过程中加速度的变化曲线(加速度 vs 时间):
-
找到“转折点”(Turning Points)
就是曲线中趋势发生明显改变的地方,比如从上升转为下降的点,或从下降转为稳定的点。 -
计算每一段的“变化”
-
Δy 表示某段内变量值(如加速度)的增减幅度;
-
Δx 表示该段所占的时间长度。
-
②设置阈值、初步分类
要定义标准来判断“变得多还是少”:
-
θ₁:如果 Δy 比它大,说明“明显上升”。
-
θ₂:如果 Δy 比它小,说明“明显下降”。
-
γ:判断时间长度是否“太短”——用于后面的段合并处理。
-
如果 Δy > θ₁,就把它标记为“上升”(I)
-
如果 Δy < θ₂,就标记为“下降”(D)
-
如果 Δy 在中间范围,就标记为“稳定”(S)
-
③合并稳定段落
有些“稳定段”可能时间太短,可能只是个小波动:
-
如果某段的 Δx < γ,而且它两边的段时间都比较长(Δx > γ),那说明它可能只是噪声或小波动;
-
就把这个“稳定段”合并到它相邻的一段中,减少碎片化。
④稳定段落细分为高稳定、地稳定
把“稳定段”再按数值大小分成 高 H / 低 L
⑤得到了“每个变量在不同时间段的变化趋势”:
-
比如:
-
速度:I → I → S(H) → D → S(L)
-
加速度:S(L) → I → S(H) → D → S(L)
-
多变量分割算法
①找转折点
在所有变量中寻找“转折点”(Turning Points),也就是数据趋势发生明显变化的点。
②直接切断
利用这些转折点,把多变量的驾驶轨迹(例如速度+加速度+方向盘角度)切成一个个段落。
-
如果这段的长度 < τ(阈值):
-
就把它丢弃。原因是太短的段可能是“偶然的小波动”,不具有分析意义。
-
③提取动作阶段
- 从上面切分和清理后的段中,提取“Action Phases”:
-
提取方式可以是基于段落标签、统计特征、时间顺序等进行分类。
-
行为阶段可以是“变道”、“加速”、“减速”等抽象出的操作模式。
-
-
把提取出的行为阶段加入到“行为阶段库”(Action phase Library)中,供后续建模或分析使用。
④输出行为阶段库
-
最终输出所有驾驶员的行为阶段集合——这个行为阶段库可以用于:驾驶行为建模、驾驶风格分类、安全驾驶分析等。
3000个用户—255种不同动作趋势组合—动作阶段库。
过程2:动作模式校准
分层聚类AC的基础上,划分上下文敏感的决策,结合树形图,即AC-DTC算法。
X-means:自动调节哪个簇最好就用哪个数量作为聚类数。
使用SS(1最好)、CHI(越高越好)、DBI(越接近0越好)作为评价指标。

1) 数据准备
-
问题:不同动作阶段持续时间不一致,不适合直接聚类。
-
解决:
-
使用 重采样和下采样方法(RDM) 对动作阶段长度进行标准化:
-
小于中位数长度的阶段:用 FFT + IFFT 进行插值重采样;
-
大于中位数长度的阶段:用 等距采样 下采样。
-
-
-
维度压缩:
-
使用 PCA(主成分分析) 提取主成分;
-
发现PC1 就占了 95% 的信息量,因此只用 PC1 做聚类。
-
2) 聚类实验
-
使用 AC-DTC 和 X-means 两种方法,分别进行多种参数设置的消融实验。
-
AC-DTC:
-
尝试了 4 种链接函数(加权、平均、完整、Ward);
-
其中 Ward 最佳,可以识别出 6 个聚类,内部方差最小。
-
-
X-means:
-
设置的 k 在 4 到 7 之间变化;
-
最终也发现 k = 6 时效果最佳。
-
3) 行动模式识别 & 可变重要性分析
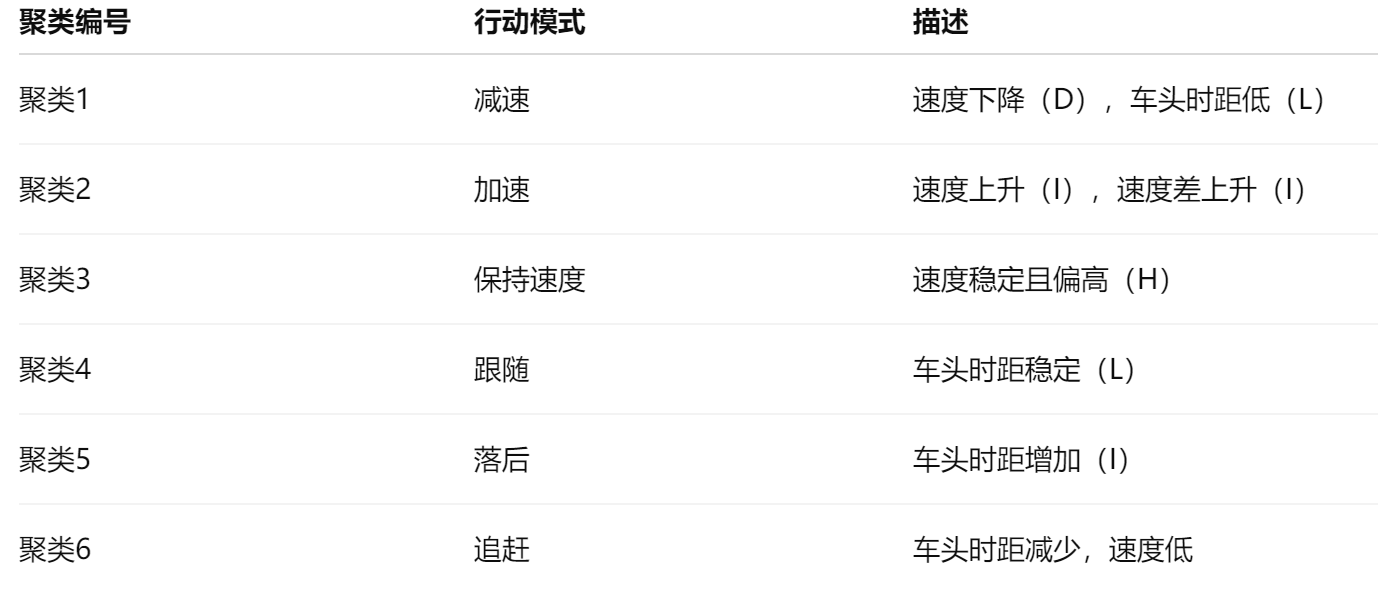
过程3:基于注意力的双向LSTM模型——动作模式分类
该模型用于识别驾驶中的不同动作模式(例如:加速、减速、追赶、保持车距等)。使用标签数据训练这个模型。
模型结构包含四层:
-
嵌入层(Embedding Layer)
-
将每个动作阶段(Action phase)编码成一个向量。
-
方便后续模型理解这些阶段之间的关系。
-
-
双向LSTM层(Bi-LSTM)
-
既从过去(前向)也从未来(后向)理解序列内容。
-
比普通LSTM更能捕捉完整上下文。
-
-
注意力层(Attention Layer)
-
让模型重点关注对分类结果影响最大的步骤。
-
举个例子:若某一阶段突然急刹车,模型会“特别关注”这个动作。
-
-
全连接分类层(Dense Layer + Softmax)
-
将注意后的序列嵌入表示,最终分类为固定的动作模式。
-
未来工作
1. 探索更鲁棒的阈值选取方式
当前的动作阶段提取依赖静态阈值(如速度变化的临界值),但这些阈值具有:
-
敏感性高:稍微调整就会影响分类结果。
-
环境依赖性强:不同道路、交通密度下效果差异大。
👉 你可以探索:
-
自适应阈值策略(如基于KDE、局部均值或聚类中心动态调整)。
-
使用 强化学习 或 贝叶斯优化 自动调整阈值。
-
跨区域泛化分析:在不同城市/国家数据上测试框架。
2. 考虑变量之间的依赖关系
目前的动作阶段是基于单变量趋势进行独立分类的,比如只看速度、或加速度、或车头时距。
👉 下一步你可以:
-
使用 多变量降维方法(如 t-SNE、UMAP、AutoEncoder)来提取联合特征。
-
构建多变量联合趋势规则,捕捉更细腻的驾驶状态(如“高速度+小时距=危险追尾”趋势)。
-
结合 图神经网络(GNN) 建立变量之间的依赖图谱。
3. 引入更多数据源
论文使用的变量是:
-
速度 v
-
加速度 a
-
车头时距 T(前后车的车头间距除以后车速度来计算。当前车刹车时,后车驾驶员所具有的最大反应时间)
-
速度差 Δv(路程/时间)
👉 你可以尝试加入:
-
驾驶员状态(疲劳、注意力等)
-
路况信息(红绿灯、限速、天气)
-
AV-HV 混合交通数据
-
视觉数据(前车图像)做辅助特征提取
4. 扩展到多种驾驶文化和地理区域
👉 你可以:
-
构建或寻找国际驾驶数据集,研究“文化驱动行为差异”
-
比较不同城市、国家之间的动作模式异质性
-
探索 区域标签嵌入 (region embeddings) 与动作模式的关系
——20250818
小狗照亮每一天