典型 RAG实现:NFRA智能问答系统实战的总结与反思
前言
本文是基于近段时间做 NFRA 智能问答系统实战的总结与反思,同时,回顾当初做这个项目的执行方式——“项目实战为主,书籍为辅”,以及当时的项目目标。
按当时的项目目标来看,以“项目实战为主,书籍为辅”的执行方式,是挺不错的,项目目标均已实现。RAG 智能问答系统的召回率,从初始版本的 79.52%,经过迭代优化,提升到 96%,提升幅度是:20.7%。
RAG 系统 QA流程图
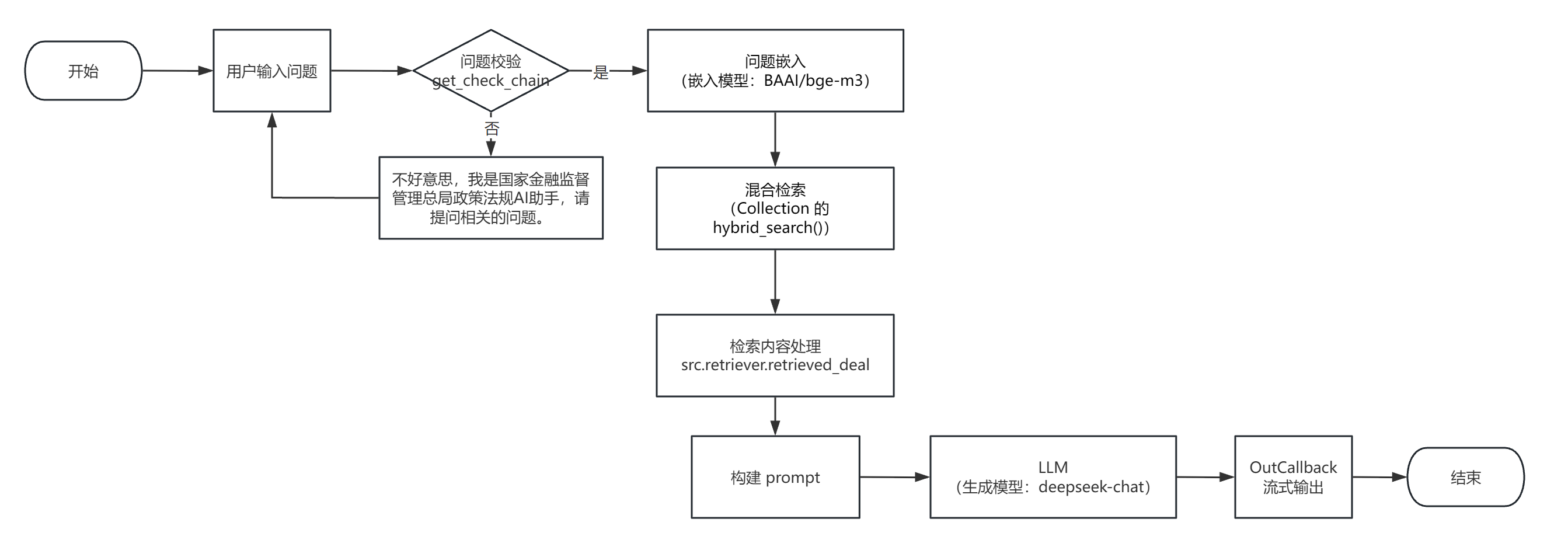
实现过程总结与反思
典型 RAG 的实现过程,主要包括三个主要步骤:数据索引、检索和生成。
(一)如何构建数据索引
数据索引一般是一个离线的过程,主要是将私域数据向量化后,构建索引并存入向量数据库的过程。主要包括:数据提取、文本分割、嵌入(embedding)及创建索引等环节。即从原始数据到便于检索数据的过程。
1.1 数据提取
(1)数据获取:包括多格式数据,例如:PDF、word、markdown以及数据库和API等,加载不同数据源获取等,根据数据自身情况,将数据处理为同一个范式;
- Doc类文档:直接解析其实就能得到文本到底是什么元素,比如标题、表格、段落等等。这部分直接将文本段及其对应的属性存储下来,用于后续切分的依据;
- PDF类文档:
- 难点:如何完整恢复图片、表格、标题、段落等内容,形成一个文字版的文档。
- 解决方法:使用 LangChain 提供的 UnstructuredLoader ,它既可以读取图片、PPT等中的文字,也可以对 PDF 进行结构化解析,使用它的“hi_res”高精度模式,能较为准确地铺抓到文件中的表格、页面布局、元素坐标等内容。
- 其他 PDF解析器:
| PDF 解析器 | 功能特点 | 性能表现 | 适用场景 |
| PyPDF | python 库中的一款轻量型工具 | 较快的处理速度 | 简单的文档文本解析 |
| PDFPlumber | 擅长处理表格数据,较强的布局分析能力 | 性能具有显著优势,但在文本提取上,比PyPDF表现稍差 | PDF 文件中有表格数据,推荐使用它 |
| PyMuPDF | 全面的功能,支持 PDF 渲染、编辑,复杂文档的精细化处理 | 性能表现出色,准确度同样如此 | 处理排版复杂的 PDF 文件,推荐使用它 |
| Unstructured | 是 LangChain中DirectoryLoader的默认加载器,是一个开源库,不过要全部使用其特性,需要依赖额外的服务支持 | 在使用其 API版本时,处理速度会受到网络状况影响 | 处理排版复杂的 PDF 文件,推荐使用它 |
【项目中应用】
在实战项目中,选择的是 PyMuPDF 对政策法规条文进行文本提取,而没选择处理速度更快的 PyPDF,是因为:要处理的政策法规文件数不算多;需要确保文件内容提取的准确度;还有,不涉及表格、图片等复杂内容的处理。
- PPT类文档:
- 难点:如何对PPT中大量的流程图,架构图进行提取,因为这些图多以形状元素在PPT中呈现,如果光提取文字,大量潜藏的信息就完全丢失了。
解决方法:将PPT转换成PDF形式,然后用上述处理PDF的方式来进行解析。
- 难点:如何对PPT中大量的流程图,架构图进行提取,因为这些图多以形状元素在PPT中呈现,如果光提取文字,大量潜藏的信息就完全丢失了。
(2)数据清洗:对源数据进行去重、过滤、压缩和格式化等处理;
【项目中应用】
在实战项目中,对提取的文本内容进行了多余文本的去除,比如表头与表尾的文件来源说明“国家金融监督管理总局规章”、“中国银行保险监督管理委员会发布”等,以及多余的空行、网址等信息。
(3)信息提取:提取数据中关键信息,包括文件名、时间、章节title、图片等信息。
【项目中应用】
在实战项目中,只提取了文件名作为文档分块的元数据,目的是为了明确引用条文所属的政策法规文件。其他的信息,并不需要,也就未提取。
1.2 文本分割(Chunking)
为何要对文本进行分割?
- 将大型数据集或长文本分割成更小、有意义的信息片段,这样做可以更有效地利用大模型的非参数记忆;
大语言模型的非参数记忆:可理解为一种通过外部知识源动态获取信息,而非依赖模型内部固定参数存储知识的机制。它允许模型在生成回答时,实时检索并整合外部数据,从而增强回答的准确性、时效性和可靠性。
2. 大模型存在上下文窗口的限制,既有生成大模型,又有嵌入模型。
分块的方式有哪些?
- 按固定字符数分块:这是最直接的方法,通过设定一个固定的字符数来将大文档分割成更小的块。这种方法虽然简单快速,但可能导致语义不连贯问题,例如将一个完整的句子或法条分隔开。为了解决这个问题,通常设置分隔符,以避免强行分割句子或段落,并在块之间保留一定的重叠块,确保语义上下文的连续性。LangChain 中的 CharacterTextSplitter 就是如此实现的;
- 递归分块:通过指定一组分隔符,逐步将文本分割成较小的部分,以更好地保持单个句子或段落的完整性。它实现的原理是,逐个应用分隔符进行分块,每一个分隔符分块之后,与设置的大小进行比较,一旦超过了设置的大小,则换下一个分隔符进行;否则使用该分隔符分块并输出文本块;LangChain 同样提供了对应的分割器——RecursiveCharacterTextSplitter
- 基于格式分块:为了识别复杂的文档结构(如段落、章节、标题、脚注、列表或表格等),可以采用基于特定格式的分块工具。比如:RecursiveCharacterTextSplitter 中的 from_language 方法提供了针对不同编程语言优化的文本分割功能;
- 基于版式分块:对于包含版式信息的文档来说(如 PDF 或 PPT),可以使用 LangChain 提供的 Unstructured 工具提供的基于文档布局的分块策略,它还被 LangChain 官方设置为: DirectoryLoader 中默认的分割器;
- 基于语义分块:这是一种高级分块策略,首先将文本按句子切分,然后利用嵌入技术分析句子的语义,并将相似的句子组合在一起形成块。
- 基于命题分块:基于语言模型的命题分块,将长文本分解为多个表达完整思想的命题。每个命题作为一个小的语义单元,便于检索和存储,适用于需要高效搜索和查阅的场景。
【项目中应用】
在实战项目中,使用的是递归分块(RecursiveCharacterTextSplitter),设置了分块大小,重叠大小,使用了正则:r"第\S*条 "。
之所以统一使用正则表达式:r"第\S*条 ",是因为不管是政策还是法规,文件的主要内容都是以“第X条”的形式出现。而不切断政策法规中的每一条条文,也是确保条文检索准确度的关键所在。
1.3 嵌入(embedding)及创建索引
(1)嵌入(embedding)
- 思路:将文本、图像、音频和视频等转化为向量矩阵的过程,也就是变成计算机可以理解或处理的格式。
- 常见的 embedding 模型:
- BGE 系列
- Qwen 系列
【项目中应用】
- 初版使用:BAAI/bge-base-zh-v1.5;
- 迭代优化过程中:
- 尝试使用:BAAI/bge-large-zh-v1.5,发现召回率提升低;
- 最终使用:BAAI/bge-m3(实现混合索引,milvus_model.hybrid 包中 BGEM3EmbeddingFunction,源码中默认使用的嵌入模型)
之所以它成为了最终使用的嵌入模型,是因为检索评估结果来看:召回率稳定在 93%-96%。
可以通过 Hugging Face 网站搜索更多开源的嵌入模型。
(2)创建索引:
- 思路:数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程。
- 常用的工具:FAISS、ChromaDB、Milvus 等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。
【项目中应用】
实战项目中,选择了 Milvus 作为存储嵌入的向量数据库。之所以选择它,是因为想了解学习,而且经过了解后,它完全适合项目诉求,不过有点大材小用了,用于学习,这点无关紧要。
选择了 Milvus 作为数据库,那么在选择给嵌入加索引的时候,就要选择所使用的 Milvus 版本支持的索引类型。
Milvus 支持多种索引类型,这些类型按其处理的向量嵌入类型分为:浮点嵌入(也称浮点向量或密集向量)、二进制嵌入(也称二进制向量)和稀疏嵌入(也称稀疏向量)。
在项目中的混合检索:
- 给浮点嵌入选择的索引类型是:IVF_FLAT,它适合的场景:高速查询、要求尽可能高的召回率。
- 给稀疏嵌入选择的索引类型是:SPARSE_INVERTED_INDEX。
更多索引类型相关的内容,可查看官方文档:In-memory Index Milvus v2.5.x documentation
(二)如何对数据进行检索
检索环节是获取有效信息的关键环节。
怎么实现获取有效信息呢?
- 元数据过滤:当我们把索引分成许多chunks的时候,检索效率会成为问题。这时候,如果可以通过元数据先进行过滤,就会大大提升效率和相关度。
- 检索技术:检索的主要方式有以下这几种:
- 向量化(embedding)相似度检索:相似度计算方式包括内积(IP)、欧氏距离、曼哈顿距离、余弦等;
- 关键词检索:传统的检索方式,元数据过滤也是一种,还有一种就是先把 chunk做摘要,再通过关键词检索找到可能相关的chunk,增加检索效率;
- 全文检索
- SQL检索:更加传统的检索算法。
【项目中应用】
混合检索:密集向量检索,稀疏向量检索,它们的相似度计算均是内积(IP)。
- 对密集向量检索来说,选择内积作为相似度计算,是因为内积适合用于文本嵌入的语义比较,使用内积时需要向量的归一化,而使用的嵌入模型 BAAI/bge-m3,官方也是推荐使用归一化的;
- 对稀疏向量检索来说,之所以使用内积,则是因为 Milvus 数据库中,稀疏嵌入式索引仅支持IP 和BM25 (用于全文检索)度量。再加之,项目使用的是稀疏向量检索,而非全文检索,因此选择内积(IP)。
3. 检索前处理:
为何要对查询进行检索前处理呢?
直接用用户的问题进行文档检索,很多时候,用户的问题是十分口语化的,描述的也比较模糊,这样会影响文档相关片段被检索到的概率,致使无法获取有效的信息。
检索前处理,常见方法:
- 查询重写,这是最直接的方法,通过自定义的提示模板引导大模型来重写用户的查询,使查询问题更加清晰明了,比较适合处理冗长的查询。LangChain 提供了开箱即用的工具:RePhraseQueryRetriever
- 查询分解,它是将查询拆分成多个子问题,以从不同视角探索查询的不同方面,使得检索出来的内容更加丰富。LangChain 同样提供了开箱即用的工具类: MultiQueryRetriever。它对每个生成的查询,都通过检索器获取相应的文档片段,然后会对所有检索到的文档片段去重后合并为一个结果集。
- 查询扩展,可以通过 HyDE(假设文档嵌入)来实现。该方法的核心在于针对给定的查询,创建一个假设的回答文档,随后对该文档进行嵌入处理,并利用此嵌入去检索相关的文档片段,并作为最终的检索结果。这种方法比较适合处理描述比较模糊或者比较简短的查询。
【项目中应用】
这些三个检索前处理的方法,在项目迭代优化的过程中都探究过,具体的内容可参考文章末尾引用内容的第 2-4 篇。
项目最终未采用它们是因为它们对检索召回率的提升不如混合检索。
4. 检索后处理(有检索前处理,那自然就会有检索后处理)
- 重排序(Rerank):相关度、匹配度等因素做一些重新调整,得到更符合业务场景的排序。
【项目中应用】
实战项目中使用的混合检索,采用的是 pymilvus 中 Collection 的 hybrid_search() 方法,它的里面就有一个重排的参数,支持自定义重排器。
通过实战检索评估对比,最终采用的重排技术是:RRF(Reciprocal Rank Fusion,倒数排名融合),平滑参数 k=60。
- 压缩:通过压缩检索到的文档分块,可以避免生成大模型在处理过长上下文时易出现的“中途遗忘”问题, 从而是生成的答案更加准确。
(三)对检索到的文本如何生成有效回复
文本生成就是将原始 query 和检索得到的文本组合起来,输入大语言模型得到结果的过程,本质上是一个 prompt engineering 过程。
3.1 通过改进提示词来提高大模型输出质量
改进提示词的方法:
1、要求基于检索生成和引入事实核查机制
- 通过在提示词中明确限制大模型基于检索到的内容进行生成,可以有效避免引入错误信息。
- 还可以引入事实核查机制,通过比对生成内容与检索文档的一致性,同样可以避免引入错误信息。
2、通过模板和示例引导生成结果(对应提示技术分别是:方向性刺激提示、少样本提示)
- 通过模板,可以引导大模型,生成具有结构化的内容;
- 通过少样本,可以引导大模型,生成更符合需求风格的内容。
3、增强生成的多样性和全面性
- 可以让大模型生成多个候选答案,随后与检索结果进行比较,选择最优的一个;
- 也可以在提示词中引导和鼓励大模型考虑不同的观点或可能性,以生成更全面的答案。
3.2 通过选择合适的大模型来提高输出质量
除了改进提示词来提高大模型输出质量之外,还可以通过选择合适的大模型来提高输出质量。
选择大模型需要考虑:
- 任务匹配性:不同的模型可能在特定任务上表现更佳,比如有些模型强化了代码、数学能力,那么在处理代码和数学任务时,就可以考虑选择它们;
- 模型开源与否与调用方式:选择闭源的模型,是通过 API 调用;选择开源模型,一般是开源模型平台部署和本地化部署;
- 模型规模与性能:一般来说,参数越大的模型具有更强的生成能力和理解复杂语境的能力。不过,在追求性能的同时,要考虑到资源消耗。
【项目中应用】
在实战项目中,选择的模型是:deepseek-chat。之所以选择它,是因为首先它是一款国产的大模型,中文语义理解准确率高达 92.7%,位于前列水平;其次,它是 chat 类型的大模型,符合智能问答的场景。
至此。
文章关联:
RAG项目实战:LangChain 0.3集成 Milvus 2.5向量数据库,构建大模型智能应用-CSDN博客
检索召回率优化探究二:基于 LangChain 0.3集成 Milvus 2.5向量数据库构建的智能问答系统-CSDN博客
检索召回率优化探究三:基于LangChain0.3集成Milvu2.5向量数据库构建的智能问答系统-CSDN博客
检索召回率优化探究四:基于LangChain0.3集成Milvu2.5向量数据库构建的智能问答系统_langchain 与 fastgpt 召回率-CSDN博客
项目代码地址:https://gitee.com/qiuyf180712/rag_nfra