【web自动化】-8-EXCEL数据驱动
一、openpyxl的基本使用
安装库 、加载Excel文件、获取当前工作表、操作工作表
import openpyxl# 加载 Excel 文件
workbook = openpyxl.load_workbook(r"D:\Project234_web\data\666.xlsx")# 获取当前激活的工作表(默认第一张)
sheet = workbook.active # active 默认获取当前激活的工作表内容(第一张工作簿)# # 也可通过表名获取工作表(按需取消注释)sheet2 = workbook["Sheet2"]# 遍历工作表的行数据(仅获取值,不包含单元格对象)
for row in sheet.iter_rows(values_only=True):print(row)# 获取并打印 B5 单元格的数据
B5 = sheet["B5"]
print(B5)
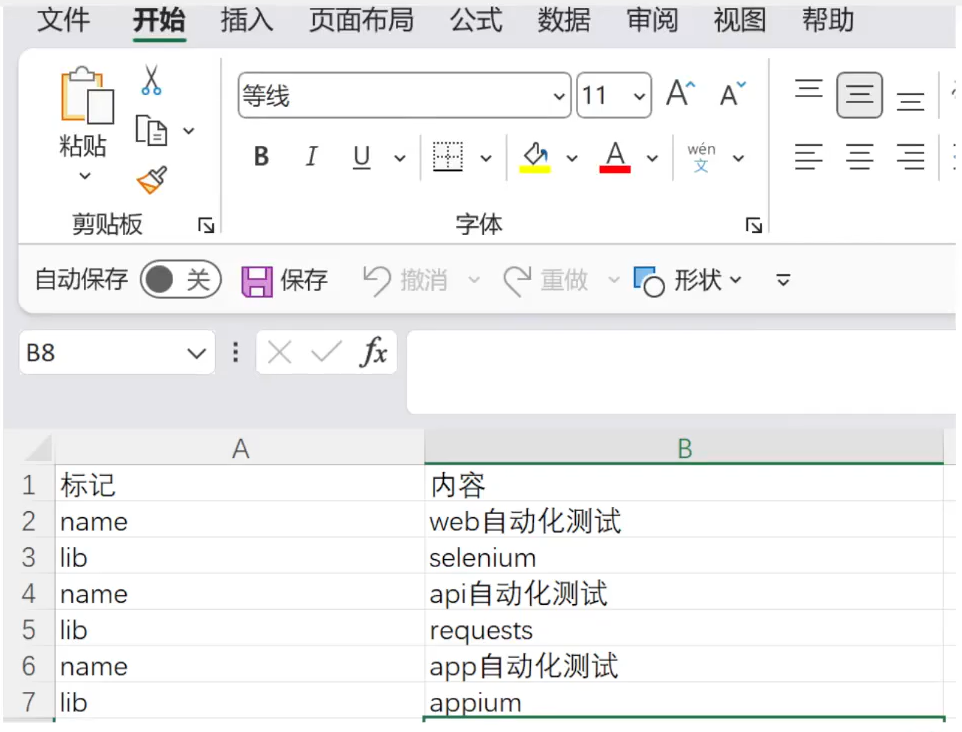
获取表格中的实际值的两种方式:.value
# 获取表格中单个数据通过表格的具体坐标或者坐标值获取实际值
B5 = sheet["B5"].value
print(B5)a = sheet.cell(4, 2).value
print(a)二、 将 Excel 表格转化为用例执行
2.1 安装依赖库
- pip install pytest-xlsx
- 可以识别 Excel 表中的关键字执行对应的用例步骤
- 原理:通过反射的机制调用关键字方法执行
2.2 表格文件命名规则
所有需要被当做用例去执行的 Excel 表格命名必须符合默认规则:
- Excel 文件名一定要以 test 开头
- Excel 文件后缀一定要是 xlsx 结尾
- 例子:test_tianqiu.xlsx
新建一张 Excel 表格符合用例命名规则
如果通过 pytest test_tq.xlsx -vs 执行时找不到对应的表格
- 那么需要切换路径 cd 文件夹
- 直接将表格放置项目下面即可
三、定义 hook 钩子进行调度
hook 是 pytest 非常核心的概念和机制,也是测试开发必须掌握的一个技能
hook 称为钩子函数,会自动被系统识别,在被需要的时候进行自动化的调用
- 创建一个 hook 钩子函数
- 在使用 hook 之前先配置基本的日志输出格式
ini
[pytest]
addopts = -vs --alluredir report
log_file = log/pytest.log
log_file_level = info
log_file_format = %(levelname)-8s %(asctime)s [%(name)s:%(lineno)s] : %(message)s
log_file_date_format = %Y-%m-%d %H:%M:%S
- 通过钩子函数来记录被调用的信息
- 在 conftest.py 模块中定义钩子函数
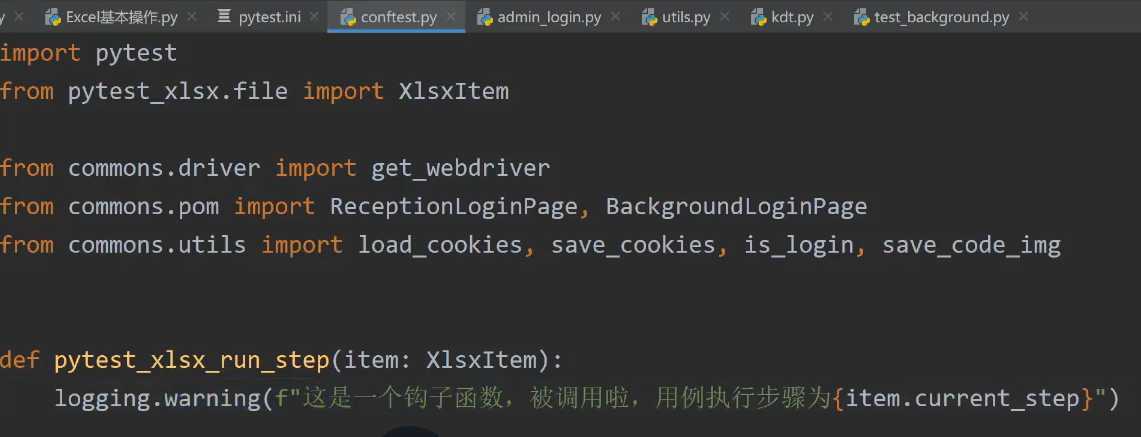
四、 自定义钩子函数执行用例
定义一个钩子函数来执行对应的关键字方法调用
实现步骤:
- 实例化关键字对象
- wd = KeyWord ()
- 获取用例的执行步骤
- 通过 item.current_step 属性获取
- 结果如下:
WARNING 2023-10-27 20:49:13 [root:12] : 这是一个钩子函数, 被调用啦, 用例执行步骤为: {'标记': 'lib', '内容': 'appium'} - 解析关键字和参数信息
{'标记': 'click', '内容': '//*[@id="kw"]', '_blankField': [None]} {'标记': 'input', '内容': '//*[@id="su"]', '_blankField': ['美女']} - 解析格式
- 标记对应的就是关键字: click,input
- 关键字方法调用需要使用的实参是内容
- 需要被定位元素值: //*[@id="su"]
- 元素需要使用的实参 (输入的内容)
- 关键字是标记,实参是内容
动态调用关键字对应的方法(核心是 “反射机制”):
- “通过反射机制完成调用”:在 Python 中,
getattr函数可以通过字符串形式的方法名,从对象中获取对应的方法(这就是 “反射”)。 - “通过关键字对象及对应的关键字进行使用”:假设
wd是一个封装了各种关键字方法的对象(比如包含click、input等方法的类的实例)。 func = getattr(wd, key):getattr(wd, key)会从wd对象中,获取名为key(即前面提取的关键字,如"click"或"input")的方法,并赋值给func。func(*args):调用获取到的方法func,并把前面提取的参数args以可变参数的形式传入,从而执行对应的操作(比如点击元素、向元素输入内容)。
举个更具体的例子
假设我们有一个 WebDriverWrapper 类,封装了 click 和 input 方法:
class WebDriverWrapper:def click(self, element_xpath):# 模拟点击元素的逻辑,这里简化为打印print(f"点击元素:{element_xpath}")def input(self, element_xpath, text):# 模拟输入内容的逻辑,这里简化为打印print(f"向元素 {element_xpath} 输入:{text}")
然后,按照前面的流程解析数据并调用:
# 假设解析出的第一个操作(点击)
key1 = "click"
args1 = ["//*[@id='kw']"]# 假设解析出的第二个操作(输入)
key2 = "input"
args2 = ["//*[@id='su']", "美女"]# 实例化封装类
wd = WebDriverWrapper()# 调用点击方法
func1 = getattr(wd, key1)
func1(*args1) # 输出:点击元素://*[@id='kw']# 调用输入方法
func2 = getattr(wd, key2)
func2(*args2) # 输出:向元素 //*[@id='su'] 输入:美女
这样,通过 “解析测试数据→提取关键字和参数→反射调用方法” 的流程,就可以灵活地执行不同的页面操作,这也是关键字驱动测试框架的核心逻辑之一。
五、实战演练
基于 Excel 关键字驱动的自动化测试框架,核心是通过 Excel 配置测试步骤,结合 pytest 的 Fixture 和反射机制,实现 “无代码化” 编写 Web 自动化测试用例。
⭐ 核心概念回顾
- 关键字驱动:用 “关键字”(如
click、input、get)表示页面操作,将操作逻辑与测试数据分离。 - Fixture:
pytest的固件机制,用于管理测试前后的环境(如启动 / 关闭浏览器)。 - 反射:通过
getattr动态根据字符串(关键字)调用对象方法,实现 “关键字→操作” 的映射。
# ---------- 关键字类:Keyword ----------
class Keyword:def __init__(self, driver):self.driver = driver # 接收浏览器驱动,用于操作页面# 新增:访问被测页面的关键字(对应浏览器的get方法)def get(self, url, *args):self.driver.get(url) # 打开目标URL# 其他关键字(示例,需根据需求补充,如click、input等)def click(self, locator, *args):self.driver.find_element(By.XPATH, locator).click()def input(self, locator, value, *args):self.driver.find_element(By.XPATH, locator).send_keys(value)# 关闭驱动的关键字(处理无实参场景,用*args接收不定长参数)def quit_driver(self, *args):self.driver.quit()# ---------- 步骤执行函数:pytest_xlsx_run_step ----------
def pytest_xlsx_run_step(item: XlsxItem):# 1. 实例化关键字对象(需先获取driver,图3/图4会讲Fixture集成)# 注:实际需通过Fixture获取driver,此处为逻辑示意driver = get_webdriver() # 假设get_webdriver()是获取浏览器驱动的方法wd = Keyword(driver)# 2. 获取当前要执行的测试步骤(从Excel解析而来)step = item.current_step # item封装了Excel中当前行的步骤数据# 3. 解析关键字和参数key = step["标记"] # 从Excel的“标记”列获取关键字(如get、click)# 从Excel的“内容”“列1”等列获取参数,组成实参列表args = [step["内容"], step["列1"]]# 处理参数中的None(若最后一个参数为None,移除它,避免报错)if args and args[-1] is None:args.pop()# 4. 动态调用关键字方法(反射)func = getattr(wd, key) # 根据关键字获取Keyword类中的方法func(*args) # 传入参数执行方法
2. Fixture 与 Excel 的集成
作用:通过 Excel 配置 pytest 的 Fixture,实现 “用例级” 的环境管理(如共享浏览器驱动)。
-
Excel 配置格式:
标记 内容 列 1 mark usefixtures admin_driver get http://... click //xpath... - 第 3 行(
mark行):表示 “使用名为admin_driver的 Fixture”。 - 后续行:是具体的测试步骤(如打开 URL、点击元素)。
- 第 3 行(
-
代码中集成 Fixture:
# ---------- Fixture 定义(示例) ---------- @pytest.fixture(name="admin_driver") def admin_driver_fixture():driver = webdriver.Chrome() # 启动浏览器yield driver # 提供driver给测试用例driver.quit() # 测试结束后关闭浏览器# ---------- 步骤执行函数中获取 Fixture ---------- def pytest_xlsx_run_step(item: XlsxItem):# 1. 从item中获取Fixture(对应Excel中配置的usefixtures)driver = item.usefixtures["admin_driver"] # 使用admin_driver Fixture的driverwd = Keyword(driver) # 实例化关键字对象# 后续步骤与之前一致(解析Excel步骤、调用关键字方法)...
三、完整流程示例(结合登录场景)
假设要测试 “打开登录页→点击登录按钮” 的流程,Excel 配置如下:
| 标记 | 内容(操作 / URL) | 列 1(参数) | |
|---|---|---|---|
| mark | usefixtures | admin_driver | |
| get | http://xxx/login | ||
| click | //button[@id="login"] | ||
| mark | usefixtures | admin_driver | (若需关闭驱动,可加 quit 步骤) |
| quit_driver |
执行流程:
pytest_xlsx_run_step读取到mark行,触发admin_driverFixture,启动浏览器。- 读取
get行,调用Keyword.get("http://xxx/login"),打开登录页。 - 读取
click行,调用Keyword.click("//button[@id='login']"),点击登录按钮。 - (可选)读取
quit_driver行,调用Keyword.quit_driver(),关闭浏览器。
⭐ 关键细节说明
- Fixture 共享:通过
mark行配置usefixtures,可以让同一条用例的所有步骤共享同一个 Fixture(如admin_driver提供的浏览器),保证操作在同一个浏览器会话中执行。 - 参数处理:
*args用于接收不定长参数,避免因 “无参数步骤”(如quit_driver)传递None导致报错。 - 扩展性:若需新增操作(如
select下拉框、upload文件),只需在Keyword类中添加对应方法,Excel 中用新关键字即可,无需修改核心执行逻辑。
这种模式的优势是非技术人员可通过 Excel 编写测试用例,技术人员只需维护 “关键字类” 和 Fixture,实现了 “测试数据与逻辑的解耦”。
六、钩子函数深层理解
当执行 pytest -表格文件 -vs 命令后,整个流程涉及 pytest 原生执行机制 和 自定义框架的钩子逻辑 结合,最终实现 “表格每行调用一次 pytest_xlsx_run_step”。我们可以拆解为 5 个核心阶段,逐步看代码内部的流动逻辑:
⭐ 阶段 1:pytest 启动与初始化(命令行解析)
触发点:输入 pytest -表格文件 -vs 并回车。
内部流动:
pytest 首先解析命令行参数(-v 详细输出、-s 显示打印、-表格文件 是自定义参数,指定要运行的 Excel 用例文件)。
加载所有已安装的插件(包括我们自定义的 “Excel 关键字驱动插件”),插件会注册自己的 钩子函数(如用例收集、执行相关的钩子)。
初始化测试会话(Session 对象),准备后续的用例收集和执行。
⭐ 阶段 2:测试用例收集(将 Excel 每行转为 “测试项”)
这是最关键的一步:Excel 中的每一行会被转换为 pytest 可识别的 “测试项(Item)”,这决定了 “每行都会触发一次钩子”。
核心逻辑:pytest 原生只能识别 .py 文件中的测试函数 / 类,要让它识别 Excel 文件,需要通过 自定义收集钩子 介入。
内部流动:
pytest 遍历命令行指定的 “表格文件”,触发插件中注册的 pytest_collect_file 钩子(这是 pytest 提供的 “文件收集” 扩展点)。
自定义插件的 pytest_collect_file 函数判断:“如果是 Excel 文件,则进行解析”。
解析 Excel 文件:
读取表头(确认 “标记”“内容”“参数” 等列)。
从第 2 行开始,每一行数据封装为一个自定义的测试项对象(如 XlsxItem),每个 XlsxItem 包含当前行的所有信息(关键字、参数、用例 ID 等)。
将所有 XlsxItem 收集到测试会话中,此时 pytest 会认为 “这些 XlsxItem 都是要执行的测试用例”。
举例:若 Excel 有 3 行步骤,此时会生成 3 个 XlsxItem(item1、item2、item3),分别对应 3 行数据。
⭐ 阶段 3:测试用例执行前准备(Fixture 初始化)
核心逻辑:为每个 XlsxItem 准备执行环境(如启动浏览器、连接数据库等),依赖 pytest 的 Fixture 机制。
内部流动:
pytest 对每个 XlsxItem 执行 “前置操作”,检查该用例是否需要依赖 Fixture(如 Excel 中可能通过 mark usefixtures=browser 指定依赖 browser Fixture)。
触发 Fixture 的初始化(如 browser Fixture 启动 Chrome 浏览器,生成 driver 对象),并将 Fixture 结果(如 driver)关联到 XlsxItem 中,供后续步骤使用。
⭐ 阶段 4:执行测试步骤(每行调用一次钩子函数)
这一步直接回答 “为什么每行都调用 pytest_xlsx_run_step”:每个 XlsxItem 执行时,都会触发一次自定义钩子。
核心逻辑:pytest 执行测试用例的本质是 “逐个执行收集到的 Item”,而自定义框架通过钩子将 Item 与步骤执行逻辑绑定。
内部流动:
pytest 开始执行第一个 XlsxItem(对应 Excel 第 1 行),触发插件中注册的 pytest_xlsx_run_step 钩子(这是框架自定义的 “步骤执行” 钩子,专门用于处理 XlsxItem)。
pytest_xlsx_run_step 函数接收当前 XlsxItem 作为参数,解析该行数据:
从 item.current_step 中获取 “关键字”(如 click)、“参数 1”(如元素 XPath)、“参数 2”(如输入值)。
从 item 中获取之前准备好的 Fixture 资源(如 driver 对象)。
通过反射调用关键字对应的方法(如 Keyword.click(driver, xpath)),执行实际的页面操作。
第一个 XlsxItem 执行完毕,pytest 接着执行第二个 XlsxItem(对应 Excel 第 2 行),再次触发 pytest_xlsx_run_step 钩子,重复步骤 2。
以此类推,直到所有 XlsxItem(所有行)执行完毕。
⭐ 阶段 5:执行后清理与报告生成
内部流动:
所有 XlsxItem 执行完毕后,触发 Fixture 的 “后置操作”(如 browser Fixture 关闭浏览器)。
pytest 收集所有步骤的执行结果(成功 / 失败),结合 -v 参数生成详细报告,输出到命令行。
⭐ 关键结论:为什么每行调用一次钩子?
用例收集阶段:Excel 每行被转换为一个独立的 XlsxItem(测试项),pytest 会将每个 XlsxItem 视为一个 “最小测试单位”。
执行阶段:pytest 会逐个执行所有 XlsxItem,而 pytest_xlsx_run_step 是框架为 XlsxItem 注册的 “执行钩子”,因此 每个 XlsxItem 执行时会触发一次钩子,即每行调用一次。
简单说:“一行对应一个测试项,一个测试项触发一次钩子”,这是 pytest 插件机制与框架设计共同作用的结果。
在基于 Excel 的关键字驱动测试框架中,识别表格里的 “测试用例名称行” 和 “usefixtures 行”,需要结合 Excel 结构约定 + 钩子函数内的逻辑判断来实现。
⭐ Excel 结构的约定(核心前提)
框架会对 Excel 的 “特殊行” 做格式约定,让钩子函数能通过行内容区分 “普通步骤行” 和 “特殊配置行”。常见约定如下(以示例表格为例):
| 行号 | 标记列 | 内容列 | 列 1 | 作用 |
|---|---|---|---|---|
| 1 | name | login_Excel_test | 标记 “测试用例名称” | |
| 2 | mark | usefixtures | admin_driver | 标记 “要使用的 Fixture 名称” |
| 3 | get | http://xxx.com | 普通步骤:打开页面 | |
| 4 | click | //button[@id="login"] | 普通步骤:点击登录按钮 |
⭐ 钩子函数内的识别逻辑
当 pytest_xlsx_run_step(或类似的步骤执行钩子)处理每一行时,会先判断当前行是否是 “特殊行”,再决定是 “执行配置逻辑” 还是 “执行页面操作”。
1. 识别 “测试用例名称行”(name 行)
- 约定:若某行的 “标记列” 值为
name,则 “内容列” 是测试用例名称。 - 钩子内逻辑:
def pytest_xlsx_run_step(item: XlsxItem):step = item.current_step # 获取当前行数据mark = step["标记"]content = step["内容"]if mark == "name":# 记录测试用例名称,用于日志、报告等test_case_name = contentlogging.info(f"开始执行测试用例:{test_case_name}")return # 这一行是配置行,不执行页面操作# 后续处理普通步骤...
2. 识别 “usefixtures 行”(mark 行)
- 约定:若某行的 “标记列” 值为
mark,且 “内容列” 值为usefixtures,则 “列 1” 是要使用的 Fixture 名称。 - 钩子内逻辑:
def pytest_xlsx_run_step(item: XlsxItem):step = item.current_stepmark = step["标记"]content = step["内容"]param = step["列1"]if mark == "mark" and content == "usefixtures":# 触发 Fixture 逻辑(比如获取名为 param 的 Fixture)fixture_name = param # 示例中是 "admin_driver"driver = item.usefixtures[fixture_name] # 从 Fixture 管理处获取 driver# 初始化关键字对象,为后续步骤准备环境wd = Keyword(driver)return # 这一行是配置行,不执行页面操作# 后续处理普通步骤...
⭐ 代码流动:从 “识别特殊行” 到 “执行步骤”
当执行 pytest -表格文件 -vs 后,整体流程如下:
- Excel 解析阶段:框架读取 Excel 所有行,每行封装为
XlsxItem,包含 “标记”“内容”“列 1” 等数据。 - 钩子触发阶段:pytest 为每个
XlsxItem触发pytest_xlsx_run_step钩子。 - 特殊行判断:
- 若当前
XlsxItem是 “name 行”:记录用例名称,不执行操作。 - 若当前
XlsxItem是 “usefixtures 行”:获取 Fixture(如admin_driver对应的浏览器),初始化关键字对象(如wd = Keyword(driver))。 - 若当前
XlsxItem是 “普通步骤行”(如get、click行):从item中获取之前初始化的wd,解析 “标记” 和 “参数”,执行页面操作(如wd.get(url)、wd.click(locator))。
- 若当前
⭐ 总结
钩子函数能识别 “测试用例名称行” 和 “usefixtures 行”,是因为:
- Excel 有明确的格式约定:用 “标记列” 的值(如
name、mark)区分特殊行。 - 钩子函数内有判断逻辑:在执行每一行时,先检查 “标记列”,若匹配特殊行的约定,就执行对应的配置逻辑(记录名称、加载 Fixture),而非页面操作。
这种 “约定 + 逻辑判断” 的方式,让 Excel 既能配置测试元信息(名称、Fixture),又能编写具体步骤,实现了 “无代码化” 的测试用例管理。
示例代码中确实没有直接写 if name 或 if mark 的判断逻辑,这是因为 这些 “特殊行” 的处理逻辑被 “隐藏” 在了框架的其他部分(比如用例收集阶段、XlsxItem 类的内部处理,或其他钩子函数中),而示例代码只展示了 “普通步骤执行” 的核心流程。
⭐ 核心原因:代码的 “分层设计”
一个完整的关键字驱动框架会按 “职责” 拆分逻辑,不同阶段处理不同任务:
- 用例收集阶段:负责识别 “特殊行”(
name、mark行),并提前处理配置(如记录用例名称、加载 Fixture)。 - 步骤执行阶段(即
pytest_xlsx_run_step):只负责执行 “普通步骤”(get、click行),因为特殊行的逻辑已经在前期处理完了。
示例代码省略了 “用例收集阶段的特殊行处理”,只展示了 “执行阶段的步骤调用”,所以看不到 if name 或 if mark 的判断。
⭐ 这些逻辑具体藏在哪里?
以 “mark usefixtures 行”(加载 Fixture)和 “name 行”(记录用例名称)为例,它们的处理逻辑通常在以下位置:
1. 用例收集阶段(XlsxItem 初始化时)
当框架解析 Excel 生成 XlsxItem(每行一个)时,会先判断当前行是否是 “特殊行”,并提前处理:
# 假设这是框架内部解析Excel的代码(示例)
class XlsxItem:def __init__(self, row_data):self.row_data = row_data # 当前行的原始数据(标记、内容、列1等)self.is_special = False # 是否是特殊行self.test_case_name = None # 用例名称self.fixtures = {} # 要加载的Fixture# 识别“name行”并记录用例名称if row_data["标记"] == "name":self.test_case_name = row_data["内容"]self.is_special = True # 标记为特殊行,不执行步骤# 识别“mark usefixtures行”并记录要加载的Fixtureelif row_data["标记"] == "mark" and row_data["内容"] == "usefixtures":fixture_name = row_data["列1"]self.fixtures[fixture_name] = self._load_fixture(fixture_name) # 提前加载Fixtureself.is_special = True # 标记为特殊行,不执行步骤else:self.current_step = row_data # 普通行,保存步骤数据def _load_fixture(self, fixture_name):# 内部逻辑:调用pytest的Fixture机制获取资源(如浏览器driver)return pytest fixture系统返回的资源(如driver)
2. 执行前的过滤(钩子函数分工)
pytest 允许注册多个钩子函数,不同钩子处理不同阶段的逻辑。例如:
pytest_runtest_setup钩子:负责执行 “前置操作”(如处理name行的日志打印、mark行的 Fixture 加载)。pytest_xlsx_run_step钩子:只处理 “普通步骤”,因为特殊行已经被pytest_runtest_setup过滤掉了。
# 框架内部的其他钩子(处理特殊行)
def pytest_runtest_setup(item: XlsxItem):if item.is_special: # 如果是特殊行if item.test_case_name: # 是name行print(f"===== 开始执行用例:{item.test_case_name} =====")else: # 是mark usefixtures行print(f"===== 加载Fixture:{item.fixtures.keys()} =====")# 你看到的示例钩子(只处理普通步骤)
def pytest_xlsx_run_step(item: XlsxItem):if item.is_special: # 过滤特殊行,不执行步骤return# 以下是你看到的核心逻辑(解析参数、调用关键字方法)driver = item.fixtures.get("admin_driver") # 直接用提前加载的Fixturewd = Keyword(driver)# ... 解析步骤并执行 ...
⭐ 为什么示例代码不展示这些判断?
示例代码的目的是 突出 “关键字调用” 的核心流程(解析参数→反射调用方法),因此省略了 “特殊行处理”“Fixture 加载” 等辅助逻辑。就像讲 “汽车如何行驶” 时,会重点讲 “发动机如何驱动车轮”,而省略 “钥匙开门”“系安全带” 等前置步骤(这些步骤虽然必要,但不是核心行驶逻辑)。
⭐ 总结
“name 行”“mark 行” 的判断逻辑并没有消失,而是:
- 被拆分到了框架的 “用例收集阶段”(
XlsxItem初始化时)或 “前置钩子”(如pytest_runtest_setup)中; - 通过
XlsxItem的is_special等属性标记特殊行,确保pytest_xlsx_run_step只处理普通步骤。
这种分层设计让代码职责更清晰:前期处理配置,后期专注执行,避免一个函数堆砌所有逻辑。