Kafka生产者原理深度解析
Kafka生产者原理深度解析
在分布式消息系统中,Kafka凭借其高性能、高可靠性和可扩展性,成为了众多企业的首选。而Kafka生产者作为消息发送的核心组件,其内部机制一直是开发者关注的重点。本文将深入解析Kafka生产者的实现原理,包括消息发送流程、拦截器、序列化、分区器、消息累加器以及ACK应答机制,帮助大家更好地理解和使用Kafka。
1. Kafka生产者消息发送流程
Kafka生产者的消息发送流程由 main 线程和 Sender 线程协同完成,涉及多个组件的协同工作,主要包括主线程、Sender线程、拦截器、序列化器、分区器和消息累加器。以下是消息发送的整体流程图:
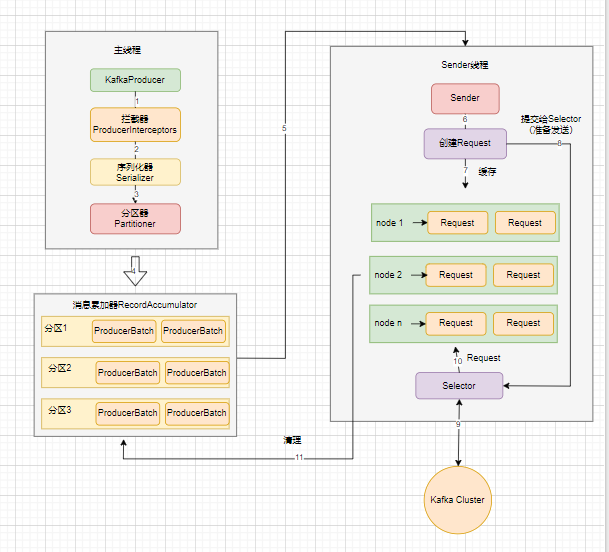
- 主线程:负责创建
KafkaProducer实例,并调用send方法发送消息。 - 拦截器:在消息发送之前,拦截器可以对消息进行定制化处理,例如修改消息内容或进行日志记录。
- 序列化器:将消息的key和value序列化为字节数组,以便在网络中传输。
- 分区器:决定消息发送到哪个分区。根据消息的key或自定义逻辑选择目标分区。
- 消息累加器:将消息暂存到内存中,等待Sender线程批量发送。
- Sender线程:负责将消息批量发送到Kafka Broker。
2. 拦截器:消息的预处理环节
拦截器是Kafka生产者的一个重要扩展点,它允许开发者在消息发送前后插入自定义逻辑。拦截器的作用类似于Spring的Interceptor或MyBatis的插件,可以实现消息的定制化处理。
2.1 拦截器的定义
拦截器需要实现ProducerInterceptor接口,该接口包含以下方法:
onSend:在消息发送之前被调用,可以修改消息内容。onAcknowledgement:在消息发送成功或失败时被调用,可以用于记录日志或进行其他操作。configure:在拦截器初始化时被调用,可以进行一些配置。close:在生产者关闭时被调用,可以进行资源清理。
2.2 拦截器的使用
在生产者配置中,可以通过interceptor.classes参数指定多个拦截器,形成拦截器链。例如:
List<String> interceptors = new ArrayList<>();
interceptors.add("com.example.ChargingInterceptor");
interceptors.add("com.example.LoggingInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
2.3 示例:按量付费拦截器
假设每发送一条消息需要扣除1分钱,可以通过拦截器实现:
public class ChargingInterceptor implements ProducerInterceptor<String, String> {@Overridepublic ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {System.out.println("1分钱1条消息,不管那么多反正先扣钱");return record;}@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {System.out.println("消息被服务端接收啦");}@Overridepublic void close() {System.out.println("生产者关闭了");}@Overridepublic void configure(Map<String, ?> configs) {System.out.println("configure...");}
}
3. 序列化:将消息转换为字节数组
序列化是将消息的key和value转换为字节数组的过程,以便在网络中传输。Kafka自带了多种序列化工具,如StringSerializer、ByteArraySerializer等。此外,还可以使用Avro、JSON、Thrift、Protobuf等高性能序列化工具,或者实现自定义序列化器。
3.1 示例:使用Protobuf序列化
假设我们有一个User类,使用Protobuf进行序列化:
public class User {private int id;private String name;private String phone;private String gender;public byte[] encode() {UserProto.User.Builder builder = UserProto.User.newBuilder();builder.setId(id);builder.setName(name);builder.setPhone(phone);builder.setGender(gender);return builder.build().toByteArray();}
}
在生产者配置中指定序列化器:
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getName());
4. 分区器:选择目标分区
分区器的作用是根据消息的key或自定义逻辑选择目标分区。Kafka提供了多种分区策略,包括默认分区器、自定义分区器等。
分区器具体规则有:指定了分区,则直接使用指定分区;未指定分区但自定义了分区器,使用自定义算法选择分区;未指定分区且无自定义分区器,但有 key,使用默认分区器(将 key 的 hash 值与 topic 的 partition 数进行取余得到分区值);既无分区也无 key,第一次调用随机生成一个整数(后面每次调用在这个整数上自增),将该值与 topic 可用的 partition 总数取余得到分区值(即 round-robin 算法) 。
4.1 默认分区器
默认分区器DefaultPartitioner会根据消息的key进行hash取余,选择目标分区。如果key为空,则使用round-robin算法随机选择分区。
int partition = Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
4.2 自定义分区器
可以通过实现Partitioner接口来自定义分区逻辑。例如,根据消息的key值选择分区:
public class SimplePartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {int numPartitions = cluster.partitionCountForTopic(topic);if (key instanceof Integer) {return ((Integer) key) % numPartitions;}return new Random().nextInt(numPartitions);}
}
在生产者配置中指定自定义分区器:
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, SimplePartitioner.class.getName());
5. 消息累加器:批量发送消息
消息累加器RecordAccumulator的作用是将消息暂存到内存中,等待Sender线程批量发送。这样可以减少网络请求的次数,提高性能。
5.1 消息累加器的工作原理
消息累加器本质上是一个ConcurrentMap,每个分区对应一个Deque<ProducerBatch>。当一个batch满了之后,会唤醒Sender线程,发送消息。
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {this.sender.wakeup();
}
6. ACK应答机制:保证数据可靠性
ACK应答机制是Kafka生产者保证数据可靠性的关键。生产者可以通过acks参数配置不同的可靠性级别,根据业务需求选择合适的配置。
6.1 三种ACK配置
- acks=0:生产者不等待Broker的ACK,延迟最低,但可靠性最低。如果Broker故障,可能会丢失数据。
- acks=1(默认):生产者等待Partition的Leader落盘成功后返回ACK,延迟适中,可靠性较高。但如果Leader故障,可能会丢失数据。
- acks=-1(all):生产者等待Partition的Leader和所有Follower全部落盘成功后返回ACK,延迟最高,但可靠性最高。
6.2 示例:配置acks参数
props.put(ProducerConfig.ACKS_CONFIG, "all");
6.3 数据丢失与重复问题
- 数据丢失:在acks=1的情况下,如果Leader故障,可能会丢失数据。
- 数据重复:在acks=all的情况下,如果Leader故障,可能会导致数据重复。可以通过设置
retries=0避免重复。
7. 总结
Kafka生产者的实现原理涉及多个组件的协同工作,包括拦截器、序列化器、分区器、消息累加器和ACK应答机制。通过合理配置这些组件,可以实现高效、可靠的消息发送。希望本文能帮助大家更好地理解和使用Kafka生产者。
如果你对Kafka的其他高级特性(如事务、幂等性等)感兴趣,可以参考Kafka的官方文档或相关教程。