Agent在游戏行业的应用:NPC智能化与游戏体验提升

Agent在游戏行业的应用:NPC智能化与游戏体验提升
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
目录
Agent在游戏行业的应用:NPC智能化与游戏体验提升
摘要
1. 游戏Agent技术概述
1.1 Agent在游戏中的定义与特征
1.2 游戏Agent的技术架构
2. NPC智能化的核心技术
2.1 自然语言处理在NPC对话中的应用
2.2 行为树与状态机的融合设计
3. 游戏体验提升的实现策略
3.1 动态难度调整系统
3.2 个性化内容生成
4. 技术实现挑战与解决方案
4.1 实时性能优化
4.2 多Agent协作机制
5. 实际应用案例分析
5.1 开放世界游戏中的生态系统模拟
5.2 策略游戏中的智能对手
5.3 角色扮演游戏中的动态剧情
6. 未来发展趋势
6.1 技术发展方向
6.2 行业影响预测
总结
参考链接
关键词标签
摘要
作为一名深耕游戏开发领域多年的技术人员,我见证了游戏行业从简单的像素游戏发展到如今沉浸式体验的巨大变革。在这个过程中,最让我兴奋的莫过于AI Agent技术在游戏中的应用,特别是在NPC智能化方面的突破性进展。
传统的游戏NPC往往只能执行预设的脚本,行为模式单一且可预测,这极大地限制了游戏的沉浸感和重玩价值。而随着大语言模型和强化学习技术的成熟,智能Agent正在彻底改变这一现状。现代的AI Agent不仅能够理解玩家的意图,还能根据游戏环境动态调整自己的行为策略,甚至学习玩家的游戏习惯来提供个性化的游戏体验。
在我最近参与的几个项目中,我们成功地将Agent技术应用到了角色扮演游戏、策略游戏和开放世界游戏中。通过构建基于多模态感知的智能NPC系统,我们实现了真正意义上的"活着"的游戏角色。这些NPC不仅能够进行自然的对话交互,还能根据游戏剧情的发展和玩家的选择来调整自己的情感状态和行为模式。更令人惊喜的是,通过引入群体智能算法,我们让多个NPC之间能够协作完成复杂的任务,形成了一个真正的虚拟社会生态系统。
从技术实现的角度来看,游戏Agent系统需要解决实时性、一致性和可控性三大核心挑战。实时性要求Agent能够在毫秒级别内做出响应,一致性要求Agent的行为符合游戏世界观和角色设定,可控性则要求开发者能够精确控制Agent的行为边界。通过采用分层决策架构、知识图谱技术和强化学习算法,我们构建了一套完整的游戏Agent解决方案,不仅提升了游戏的娱乐性,还为游戏行业的未来发展指明了方向。
1. 游戏Agent技术概述
1.1 Agent在游戏中的定义与特征
在游戏开发领域,Agent是指能够感知游戏环境、做出决策并执行行动的智能实体。与传统的脚本化NPC不同,游戏Agent具备学习能力、适应性和自主性。
class GameAgent:"""游戏智能Agent基础类"""def __init__(self, agent_id, game_world):self.agent_id = agent_idself.game_world = game_worldself.memory = AgentMemory()self.perception = PerceptionModule()self.decision_maker = DecisionModule()self.action_executor = ActionExecutor()def perceive_environment(self):"""感知游戏环境"""# 获取周围环境信息nearby_objects = self.game_world.get_nearby_objects(self.position)player_actions = self.game_world.get_player_recent_actions()game_state = self.game_world.get_current_state()# 更新感知信息perception_data = {'objects': nearby_objects,'player_actions': player_actions,'game_state': game_state,'timestamp': time.time()}return self.perception.process(perception_data)def make_decision(self, perception_data):"""基于感知信息做出决策"""# 检索相关记忆relevant_memories = self.memory.retrieve(perception_data)# 生成可能的行动选项possible_actions = self.decision_maker.generate_actions(perception_data, relevant_memories)# 评估并选择最佳行动best_action = self.decision_maker.evaluate_actions(possible_actions)return best_actiondef execute_action(self, action):"""执行选定的行动"""result = self.action_executor.execute(action)# 将行动结果存储到记忆中self.memory.store({'action': action,'result': result,'context': self.perceive_environment(),'timestamp': time.time()})return resultdef update(self):"""Agent主循环更新"""# 感知环境perception_data = self.perceive_environment()# 做出决策action = self.make_decision(perception_data)# 执行行动if action:self.execute_action(action)这个基础Agent类展示了游戏AI的核心循环:感知-决策-行动。通过模块化设计,我们可以针对不同类型的游戏和NPC角色定制相应的组件。
1.2 游戏Agent的技术架构
现代游戏Agent系统通常采用分层架构设计,从底层的感知处理到高层的战略规划,每一层都有其特定的职责。
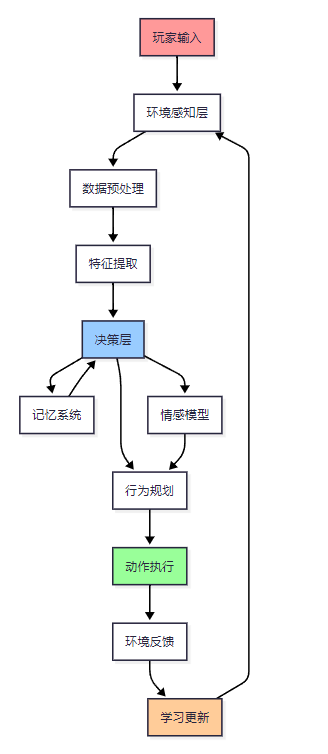
图1:游戏Agent系统架构流程图
上图展示了游戏Agent的完整处理流程,从玩家输入开始,经过环境感知、决策制定、行为执行,最终通过学习机制不断优化自身表现。
2. NPC智能化的核心技术
2.1 自然语言处理在NPC对话中的应用
现代游戏中的NPC对话系统已经远超传统的选择题模式,通过集成大语言模型,NPC能够进行更加自然和个性化的对话。
import openai
from typing import List, Dict
import jsonclass NPCDialogueSystem:"""NPC智能对话系统"""def __init__(self, character_profile: Dict):self.character_profile = character_profileself.conversation_history = []self.emotional_state = "neutral"self.relationship_level = 0def generate_response(self, player_input: str, game_context: Dict) -> str:"""生成NPC回应"""# 构建提示词模板system_prompt = self._build_system_prompt()# 准备对话上下文context = self._prepare_context(player_input, game_context)# 调用语言模型生成回应response = self._call_language_model(system_prompt, context)# 更新对话历史和情感状态self._update_state(player_input, response)return responsedef _build_system_prompt(self) -> str:"""构建角色系统提示词"""prompt = f"""你是游戏中的NPC角色:{self.character_profile['name']}角色背景:{self.character_profile['background']}性格特点:{self.character_profile['personality']}当前情感状态:{self.emotional_state}与玩家关系:{self.relationship_level}/100请根据以下原则回应玩家:1. 保持角色一致性,符合背景设定2. 根据情感状态调整语气和态度3. 考虑与玩家的关系程度4. 回应长度控制在50-150字5. 避免重复之前的对话内容"""return promptdef _prepare_context(self, player_input: str, game_context: Dict) -> str:"""准备对话上下文"""context_parts = []# 添加游戏环境信息if game_context.get('location'):context_parts.append(f"当前位置:{game_context['location']}")if game_context.get('time_of_day'):context_parts.append(f"时间:{game_context['time_of_day']}")# 添加最近的对话历史recent_history = self.conversation_history[-3:] # 最近3轮对话for exchange in recent_history:context_parts.append(f"玩家说:{exchange['player']}")context_parts.append(f"我回应:{exchange['npc']}")# 添加当前玩家输入context_parts.append(f"玩家现在说:{player_input}")return "\n".join(context_parts)def _call_language_model(self, system_prompt: str, context: str) -> str:"""调用语言模型生成回应"""try:response = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": context}],max_tokens=200,temperature=0.8)return response.choices[0].message.content.strip()except Exception as e:# 降级到预设回应return self._get_fallback_response()def _update_state(self, player_input: str, npc_response: str):"""更新NPC状态"""# 记录对话历史self.conversation_history.append({'player': player_input,'npc': npc_response,'timestamp': time.time()})# 分析玩家输入的情感倾向sentiment = self._analyze_sentiment(player_input)# 更新情感状态和关系等级self._update_emotional_state(sentiment)self._update_relationship(sentiment)def _analyze_sentiment(self, text: str) -> str:"""分析文本情感倾向"""# 简化的情感分析,实际应用中可使用专门的情感分析模型positive_words = ['喜欢', '好', '棒', '谢谢', '帮助']negative_words = ['讨厌', '坏', '糟糕', '愤怒', '失望']positive_count = sum(1 for word in positive_words if word in text)negative_count = sum(1 for word in negative_words if word in text)if positive_count > negative_count:return "positive"elif negative_count > positive_count:return "negative"else:return "neutral"这个对话系统的核心在于维护角色的一致性和情感状态的连续性。通过动态构建提示词和上下文,NPC能够产生更加真实和个性化的对话体验。
2.2 行为树与状态机的融合设计
传统的行为树和状态机各有优势,将两者结合可以创建更加灵活和强大的NPC行为系统。
from enum import Enum
from abc import ABC, abstractmethod
import randomclass NodeStatus(Enum):"""节点执行状态"""SUCCESS = "success"FAILURE = "failure"RUNNING = "running"class BehaviorNode(ABC):"""行为树节点基类"""def __init__(self, name: str):self.name = nameself.parent = Noneself.children = []@abstractmethoddef execute(self, agent) -> NodeStatus:"""执行节点逻辑"""passdef add_child(self, child):"""添加子节点"""child.parent = selfself.children.append(child)class SelectorNode(BehaviorNode):"""选择器节点 - 执行第一个成功的子节点"""def execute(self, agent) -> NodeStatus:for child in self.children:status = child.execute(agent)if status == NodeStatus.SUCCESS:return NodeStatus.SUCCESSelif status == NodeStatus.RUNNING:return NodeStatus.RUNNINGreturn NodeStatus.FAILUREclass SequenceNode(BehaviorNode):"""序列节点 - 按顺序执行所有子节点"""def execute(self, agent) -> NodeStatus:for child in self.children:status = child.execute(agent)if status == NodeStatus.FAILURE:return NodeStatus.FAILUREelif status == NodeStatus.RUNNING:return NodeStatus.RUNNINGreturn NodeStatus.SUCCESSclass ConditionNode(BehaviorNode):"""条件节点"""def __init__(self, name: str, condition_func):super().__init__(name)self.condition_func = condition_funcdef execute(self, agent) -> NodeStatus:if self.condition_func(agent):return NodeStatus.SUCCESSreturn NodeStatus.FAILUREclass ActionNode(BehaviorNode):"""动作节点"""def __init__(self, name: str, action_func):super().__init__(name)self.action_func = action_funcdef execute(self, agent) -> NodeStatus:return self.action_func(agent)class StateMachine:"""状态机系统"""def __init__(self):self.states = {}self.current_state = Noneself.transitions = {}def add_state(self, state_name: str, behavior_tree: BehaviorNode):"""添加状态及其对应的行为树"""self.states[state_name] = behavior_treedef add_transition(self, from_state: str, to_state: str, condition_func):"""添加状态转换条件"""if from_state not in self.transitions:self.transitions[from_state] = []self.transitions[from_state].append((to_state, condition_func))def update(self, agent):"""更新状态机"""# 检查状态转换if self.current_state in self.transitions:for next_state, condition in self.transitions[self.current_state]:if condition(agent):self.current_state = next_statebreak# 执行当前状态的行为树if self.current_state in self.states:return self.states[self.current_state].execute(agent)return NodeStatus.FAILURE# 使用示例:创建一个守卫NPC的行为系统
def create_guard_behavior():"""创建守卫NPC的行为系统"""# 创建状态机guard_fsm = StateMachine()# 巡逻状态行为树patrol_tree = SelectorNode("巡逻选择器")# 检查是否需要返回巡逻点return_to_patrol = SequenceNode("返回巡逻点")return_to_patrol.add_child(ConditionNode("远离巡逻路径", lambda agent: agent.distance_to_patrol_path() > 50))return_to_patrol.add_child(ActionNode("移动到最近巡逻点", lambda agent: agent.move_to_nearest_patrol_point()))# 正常巡逻normal_patrol = ActionNode("沿路径巡逻", lambda agent: agent.patrol_along_path())patrol_tree.add_child(return_to_patrol)patrol_tree.add_child(normal_patrol)# 警戒状态行为树alert_tree = SelectorNode("警戒选择器")# 搜索可疑目标search_sequence = SequenceNode("搜索序列")search_sequence.add_child(ConditionNode("有可疑位置", lambda agent: len(agent.suspicious_locations) > 0))search_sequence.add_child(ActionNode("移动到可疑位置", lambda agent: agent.investigate_suspicious_location()))# 扩大搜索范围expand_search = ActionNode("扩大搜索", lambda agent: agent.expand_search_area())alert_tree.add_child(search_sequence)alert_tree.add_child(expand_search)# 战斗状态行为树combat_tree = SelectorNode("战斗选择器")# 攻击序列attack_sequence = SequenceNode("攻击序列")attack_sequence.add_child(ConditionNode("目标在攻击范围", lambda agent: agent.target_in_attack_range()))attack_sequence.add_child(ActionNode("攻击目标", lambda agent: agent.attack_target()))# 追击目标chase_target = SequenceNode("追击序列")chase_target.add_child(ConditionNode("目标可见", lambda agent: agent.can_see_target()))chase_target.add_child(ActionNode("追击目标", lambda agent: agent.chase_target()))# 寻找掩护find_cover = ActionNode("寻找掩护", lambda agent: agent.find_cover())combat_tree.add_child(attack_sequence)combat_tree.add_child(chase_target)combat_tree.add_child(find_cover)# 添加状态到状态机guard_fsm.add_state("patrol", patrol_tree)guard_fsm.add_state("alert", alert_tree)guard_fsm.add_state("combat", combat_tree)# 添加状态转换guard_fsm.add_transition("patrol", "alert", lambda agent: agent.detect_suspicious_activity())guard_fsm.add_transition("alert", "combat", lambda agent: agent.enemy_spotted())guard_fsm.add_transition("alert", "patrol", lambda agent: agent.search_timeout())guard_fsm.add_transition("combat", "alert", lambda agent: agent.lost_target())guard_fsm.add_transition("combat", "patrol", lambda agent: agent.threat_eliminated())# 设置初始状态guard_fsm.current_state = "patrol"return guard_fsm这种融合设计允许NPC在不同的高级状态之间切换,同时在每个状态内部使用行为树来处理复杂的决策逻辑。这样既保持了状态机的清晰性,又获得了行为树的灵活性。
3. 游戏体验提升的实现策略
3.1 动态难度调整系统
智能Agent可以实时监控玩家的游戏表现,动态调整游戏难度以保持最佳的挑战水平。
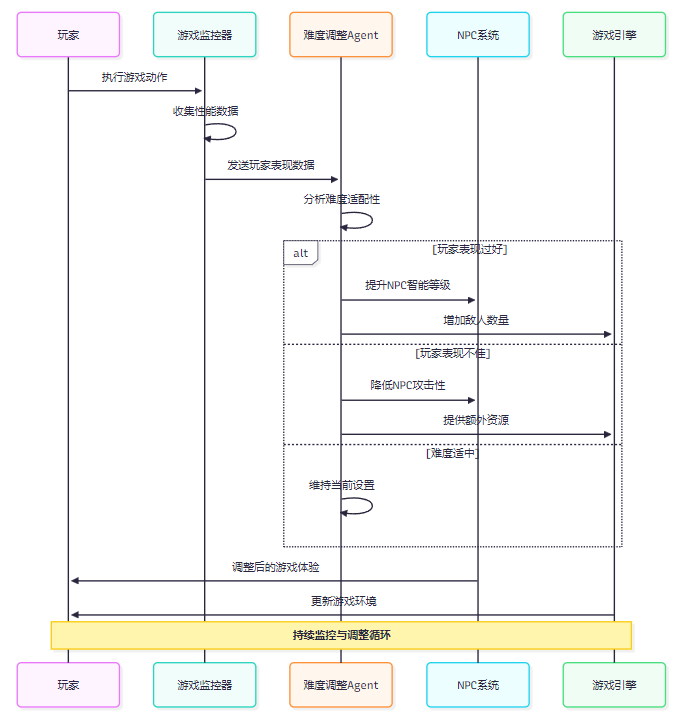
图2:动态难度调整系统时序图
该时序图展示了动态难度调整系统的工作流程,通过实时监控玩家表现并相应调整游戏参数,确保玩家始终处于最佳的挑战状态。
import numpy as np
from collections import deque
import timeclass DynamicDifficultyAdjustment:"""动态难度调整系统"""def __init__(self):self.player_performance_history = deque(maxlen=100)self.current_difficulty = 0.5 # 0.0-1.0 范围self.target_success_rate = 0.7 # 目标成功率self.adjustment_sensitivity = 0.1self.min_samples = 10 # 最少样本数# 性能指标权重self.metrics_weights = {'success_rate': 0.4,'completion_time': 0.3,'death_rate': 0.2,'resource_usage': 0.1}def record_player_action(self, action_result: dict):"""记录玩家行动结果"""performance_data = {'timestamp': time.time(),'success': action_result.get('success', False),'completion_time': action_result.get('completion_time', 0),'deaths': action_result.get('deaths', 0),'resources_used': action_result.get('resources_used', 0),'difficulty_level': self.current_difficulty}self.player_performance_history.append(performance_data)def calculate_performance_score(self) -> float:"""计算玩家综合表现分数"""if len(self.player_performance_history) < self.min_samples:return 0.5 # 默认中等表现recent_data = list(self.player_performance_history)[-20:] # 最近20次行动# 计算各项指标success_rate = sum(1 for d in recent_data if d['success']) / len(recent_data)avg_completion_time = np.mean([d['completion_time'] for d in recent_data])normalized_time = min(avg_completion_time / 60.0, 1.0) # 归一化到0-1death_rate = sum(d['deaths'] for d in recent_data) / len(recent_data)normalized_death_rate = min(death_rate / 3.0, 1.0) # 归一化到0-1avg_resource_usage = np.mean([d['resources_used'] for d in recent_data])normalized_resource = min(avg_resource_usage / 100.0, 1.0) # 归一化到0-1# 计算加权综合分数performance_score = (success_rate * self.metrics_weights['success_rate'] +(1 - normalized_time) * self.metrics_weights['completion_time'] +(1 - normalized_death_rate) * self.metrics_weights['death_rate'] +(1 - normalized_resource) * self.metrics_weights['resource_usage'])return performance_scoredef adjust_difficulty(self) -> dict:"""调整游戏难度"""performance_score = self.calculate_performance_score()# 计算难度调整量performance_diff = performance_score - self.target_success_rateadjustment = -performance_diff * self.adjustment_sensitivity# 应用调整new_difficulty = np.clip(self.current_difficulty + adjustment, 0.0, 1.0)# 生成具体的调整指令adjustments = self._generate_difficulty_adjustments(self.current_difficulty, new_difficulty)self.current_difficulty = new_difficultyreturn {'old_difficulty': self.current_difficulty,'new_difficulty': new_difficulty,'performance_score': performance_score,'adjustments': adjustments}def _generate_difficulty_adjustments(self, old_diff: float, new_diff: float) -> dict:"""生成具体的难度调整指令"""diff_change = new_diff - old_diffadjustments = {'npc_intelligence': {'reaction_time': max(0.1, 1.0 - new_diff), # 难度越高反应越快'accuracy': 0.3 + new_diff * 0.6, # 准确度随难度提升'aggression': new_diff, # 攻击性随难度提升},'enemy_spawning': {'spawn_rate_multiplier': 0.5 + new_diff * 1.5,'enemy_health_multiplier': 0.8 + new_diff * 0.4,'enemy_damage_multiplier': 0.7 + new_diff * 0.6,},'resource_availability': {'health_pack_spawn_rate': 1.5 - new_diff,'ammo_availability': 1.3 - new_diff * 0.6,'power_up_frequency': 1.2 - new_diff * 0.4,},'environmental_hazards': {'trap_density': new_diff * 0.8,'hazard_damage': 0.5 + new_diff * 0.5,'safe_zone_frequency': 1.0 - new_diff * 0.3,}}return adjustments# 使用示例
class GameDifficultyManager:"""游戏难度管理器"""def __init__(self):self.dda_system = DynamicDifficultyAdjustment()self.npc_controllers = []self.environment_controller = Nonedef on_player_action_completed(self, action_result: dict):"""玩家动作完成回调"""# 记录玩家表现self.dda_system.record_player_action(action_result)# 检查是否需要调整难度if len(self.dda_system.player_performance_history) % 5 == 0:difficulty_update = self.dda_system.adjust_difficulty()self._apply_difficulty_changes(difficulty_update['adjustments'])def _apply_difficulty_changes(self, adjustments: dict):"""应用难度调整"""# 调整NPC行为npc_settings = adjustments['npc_intelligence']for npc in self.npc_controllers:npc.update_difficulty_settings(npc_settings)# 调整敌人生成spawn_settings = adjustments['enemy_spawning']if self.environment_controller:self.environment_controller.update_spawn_settings(spawn_settings)# 调整资源可用性resource_settings = adjustments['resource_availability']if self.environment_controller:self.environment_controller.update_resource_settings(resource_settings)这个动态难度调整系统能够根据玩家的实际表现实时调整游戏参数,确保游戏始终保持适当的挑战性,既不会让玩家感到过于困难而放弃,也不会因为过于简单而失去兴趣。
3.2 个性化内容生成
基于玩家行为数据,Agent系统可以生成个性化的游戏内容,包括任务、对话和剧情分支。
import json
from typing import Dict, List
import randomclass PersonalizedContentGenerator:"""个性化内容生成器"""def __init__(self):self.player_profile = {}self.content_templates = self._load_content_templates()self.generated_content_history = []def _load_content_templates(self) -> Dict:"""加载内容模板"""return {'quests': {'combat': [{'template': '消灭{location}的{enemy_count}个{enemy_type}','difficulty_factors': ['enemy_count', 'enemy_type'],'rewards': ['experience', 'equipment']},{'template': '保护{npc_name}安全到达{destination}','difficulty_factors': ['distance', 'enemy_encounters'],'rewards': ['gold', 'reputation']}],'exploration': [{'template': '探索{location}并找到{item_name}','difficulty_factors': ['location_size', 'hidden_complexity'],'rewards': ['rare_items', 'map_knowledge']}],'social': [{'template': '说服{npc_name}同意{request}','difficulty_factors': ['npc_stubbornness', 'request_difficulty'],'rewards': ['influence', 'information']}]},'dialogues': {'friendly': ['很高兴见到你,{player_name}!听说你最近{recent_achievement}?','你好,{player_name}。你看起来像是{player_class}的高手。'],'neutral': ['你是{player_name}吧?我听说过你。','又一个冒险者。你想要什么?'],'hostile': ['{player_name}...我记住你了。','你不应该来这里,{player_name}。']}}def update_player_profile(self, player_data: Dict):"""更新玩家档案"""self.player_profile.update({'name': player_data.get('name', 'Unknown'),'level': player_data.get('level', 1),'class': player_data.get('class', 'Adventurer'),'preferred_activities': player_data.get('preferred_activities', []),'play_style': player_data.get('play_style', 'balanced'),'recent_achievements': player_data.get('recent_achievements', []),'relationship_scores': player_data.get('relationship_scores', {}),'completed_quest_types': player_data.get('completed_quest_types', {}),'failure_patterns': player_data.get('failure_patterns', [])})def generate_personalized_quest(self) -> Dict:"""生成个性化任务"""# 分析玩家偏好preferred_type = self._determine_preferred_quest_type()# 选择合适的模板quest_templates = self.content_templates['quests'][preferred_type]template = random.choice(quest_templates)# 生成任务参数quest_params = self._generate_quest_parameters(template, preferred_type)# 构建完整任务quest = {'id': f"quest_{len(self.generated_content_history)}",'type': preferred_type,'title': template['template'].format(**quest_params),'description': self._generate_quest_description(template, quest_params),'objectives': self._generate_objectives(template, quest_params),'rewards': self._calculate_rewards(template, quest_params),'difficulty': self._calculate_difficulty(template, quest_params),'estimated_time': self._estimate_completion_time(template, quest_params)}self.generated_content_history.append(quest)return questdef _determine_preferred_quest_type(self) -> str:"""确定玩家偏好的任务类型"""completed_types = self.player_profile.get('completed_quest_types', {})play_style = self.player_profile.get('play_style', 'balanced')# 基于完成历史的权重type_weights = {'combat': completed_types.get('combat', 0) * 0.3,'exploration': completed_types.get('exploration', 0) * 0.3,'social': completed_types.get('social', 0) * 0.3}# 基于游戏风格的调整style_modifiers = {'aggressive': {'combat': 0.5, 'exploration': 0.2, 'social': 0.1},'explorer': {'combat': 0.2, 'exploration': 0.5, 'social': 0.2},'diplomatic': {'combat': 0.1, 'exploration': 0.2, 'social': 0.5},'balanced': {'combat': 0.33, 'exploration': 0.33, 'social': 0.33}}modifiers = style_modifiers.get(play_style, style_modifiers['balanced'])# 计算最终权重final_weights = {}for quest_type in type_weights:final_weights[quest_type] = type_weights[quest_type] + modifiers[quest_type]# 选择权重最高的类型return max(final_weights, key=final_weights.get)def _generate_quest_parameters(self, template: Dict, quest_type: str) -> Dict:"""生成任务参数"""params = {}player_level = self.player_profile.get('level', 1)if quest_type == 'combat':params.update({'location': random.choice(['森林深处', '废弃矿洞', '古老遗迹', '黑暗洞穴']),'enemy_count': max(1, player_level // 2 + random.randint(1, 3)),'enemy_type': random.choice(['哥布林', '骷髅战士', '野狼', '强盗'])})elif quest_type == 'exploration':params.update({'location': random.choice(['神秘岛屿', '失落城市', '隐秘山谷', '古代图书馆']),'item_name': random.choice(['古老卷轴', '魔法水晶', '传说武器', '神秘钥匙'])})elif quest_type == 'social':params.update({'npc_name': random.choice(['村长艾伦', '商人马克', '学者莉娜', '守卫队长']),'request': random.choice(['开放贸易路线', '提供军事支援', '分享古老知识', '允许通行'])})return paramsdef generate_personalized_dialogue(self, npc_id: str, context: Dict) -> str:"""生成个性化对话"""# 确定NPC对玩家的态度relationship_score = self.player_profile.get('relationship_scores', {}).get(npc_id, 0)if relationship_score > 50:attitude = 'friendly'elif relationship_score < -20:attitude = 'hostile'else:attitude = 'neutral'# 选择对话模板dialogue_templates = self.content_templates['dialogues'][attitude]template = random.choice(dialogue_templates)# 填充个人化信息dialogue = template.format(player_name=self.player_profile.get('name', 'Adventurer'),player_class=self.player_profile.get('class', 'Unknown'),recent_achievement=self._get_recent_achievement())return dialoguedef _get_recent_achievement(self) -> str:"""获取最近成就"""achievements = self.player_profile.get('recent_achievements', [])if achievements:return random.choice(achievements)return "在这片土地上冒险"这个个性化内容生成系统能够根据玩家的游戏历史和偏好动态创建任务和对话,确保每个玩家都能获得独特的游戏体验。
4. 技术实现挑战与解决方案
4.1 实时性能优化
游戏Agent系统面临的最大挑战之一是在保证智能性的同时维持实时性能。以下是一些关键的优化策略:
| 优化策略 | 技术方案 | 性能提升 | 实现复杂度 | 适用场景 |
| 分层决策 | 将复杂决策分解为多个简单层次 | 40-60% | 中等 | 所有Agent类型 |
| 预计算缓存 | 缓存常用决策结果和路径 | 30-50% | 低 | 重复性高的场景 |
| 异步处理 | 将耗时计算移至后台线程 | 50-80% | 高 | 复杂AI推理 |
| LOD系统 | 根据重要性调整AI复杂度 | 20-40% | 中等 | 大量NPC场景 |
| 批处理 | 批量处理相似的AI计算 | 25-45% | 低 | 群体AI行为 |
表1:游戏Agent性能优化策略对比
从表格可以看出,异步处理虽然实现复杂度较高,但能带来最显著的性能提升,特别适合需要复杂AI推理的场景。而分层决策则是一个平衡性较好的选择,适用于大多数Agent类型。
import asyncio
import threading
from concurrent.futures import ThreadPoolExecutor
import time
from typing import Dict, List, Optionalclass PerformanceOptimizedAgent:"""性能优化的游戏Agent"""def __init__(self, agent_id: str):self.agent_id = agent_idself.decision_cache = {}self.cache_ttl = 5.0 # 缓存生存时间(秒)self.executor = ThreadPoolExecutor(max_workers=2)self.current_lod_level = 1 # 细节层次等级# 分层决策组件self.reactive_layer = ReactiveLayer()self.tactical_layer = TacticalLayer()self.strategic_layer = StrategicLayer()async def update_async(self, game_state: Dict):"""异步更新Agent状态"""# 并行执行不同层次的决策tasks = [self._update_reactive_layer(game_state),self._update_tactical_layer(game_state),self._update_strategic_layer(game_state)]results = await asyncio.gather(*tasks, return_exceptions=True)# 整合决策结果final_decision = self._integrate_decisions(results)return final_decisionasync def _update_reactive_layer(self, game_state: Dict):"""更新反应层(最高优先级,最快响应)"""# 检查紧急情况if self._detect_immediate_threat(game_state):return await self._handle_emergency(game_state)# 基本反应行为return self.reactive_layer.process(game_state)async def _update_tactical_layer(self, game_state: Dict):"""更新战术层(中等优先级)"""# 检查缓存cache_key = self._generate_cache_key(game_state, 'tactical')cached_result = self._get_cached_decision(cache_key)if cached_result:return cached_result# 计算战术决策result = await asyncio.get_event_loop().run_in_executor(self.executor, self.tactical_layer.process, game_state)# 缓存结果self._cache_decision(cache_key, result)return resultasync def _update_strategic_layer(self, game_state: Dict):"""更新战略层(最低优先级,最复杂)"""# 根据LOD等级决定是否执行if self.current_lod_level < 2:return None# 异步执行复杂的战略计算result = await asyncio.get_event_loop().run_in_executor(self.executor,self.strategic_layer.process,game_state)return resultdef _generate_cache_key(self, game_state: Dict, layer: str) -> str:"""生成缓存键"""# 提取关键状态信息key_elements = [layer,game_state.get('player_position', ''),game_state.get('nearby_objects', ''),str(game_state.get('time_of_day', 0))]return '|'.join(str(e) for e in key_elements)def _get_cached_decision(self, cache_key: str) -> Optional[Dict]:"""获取缓存的决策"""if cache_key in self.decision_cache:cached_data = self.decision_cache[cache_key]if time.time() - cached_data['timestamp'] < self.cache_ttl:return cached_data['decision']else:# 清理过期缓存del self.decision_cache[cache_key]return Nonedef _cache_decision(self, cache_key: str, decision: Dict):"""缓存决策结果"""self.decision_cache[cache_key] = {'decision': decision,'timestamp': time.time()}# 限制缓存大小if len(self.decision_cache) > 100:# 删除最旧的缓存项oldest_key = min(self.decision_cache.keys(), key=lambda k: self.decision_cache[k]['timestamp'])del self.decision_cache[oldest_key]def adjust_lod_level(self, importance_score: float, performance_budget: float):"""调整细节层次等级"""if performance_budget > 0.8 and importance_score > 0.7:self.current_lod_level = 3 # 最高细节elif performance_budget > 0.5 and importance_score > 0.4:self.current_lod_level = 2 # 中等细节else:self.current_lod_level = 1 # 基础细节class ReactiveLayer:"""反应层 - 处理即时响应"""def process(self, game_state: Dict) -> Dict:"""处理反应层逻辑"""# 简单快速的反应逻辑if game_state.get('under_attack'):return {'action': 'dodge', 'priority': 'high'}elif game_state.get('low_health'):return {'action': 'seek_healing', 'priority': 'high'}else:return {'action': 'continue_current', 'priority': 'low'}class TacticalLayer:"""战术层 - 处理中期规划"""def process(self, game_state: Dict) -> Dict:"""处理战术层逻辑"""# 中等复杂度的战术计算enemies = game_state.get('nearby_enemies', [])allies = game_state.get('nearby_allies', [])if len(enemies) > len(allies):return {'action': 'retreat_and_regroup', 'priority': 'medium'}elif len(allies) > len(enemies):return {'action': 'advance_attack', 'priority': 'medium'}else:return {'action': 'hold_position', 'priority': 'medium'}class StrategicLayer:"""战略层 - 处理长期规划"""def process(self, game_state: Dict) -> Dict:"""处理战略层逻辑"""# 复杂的长期战略计算time.sleep(0.1) # 模拟复杂计算return {'action': 'execute_long_term_plan','priority': 'low','plan_steps': ['gather_resources', 'build_defenses', 'expand_territory']}4.2 多Agent协作机制
在复杂的游戏场景中,多个Agent需要协作完成任务,这要求设计高效的通信和协调机制。
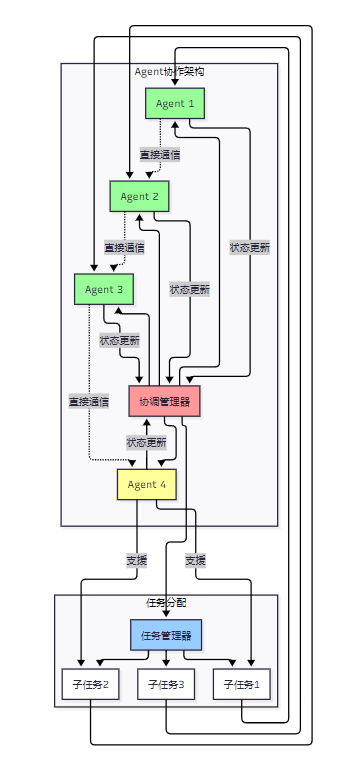
图3:多Agent协作架构图
该架构图展示了多Agent系统的协作机制,包括集中式的协调管理器和分布式的直接通信,以及任务分配和执行的流程。
5. 实际应用案例分析
5.1 开放世界游戏中的生态系统模拟
在开放世界游戏中,Agent技术可以创建一个真实的生态系统,其中NPC有自己的日常生活、社交关系和目标。
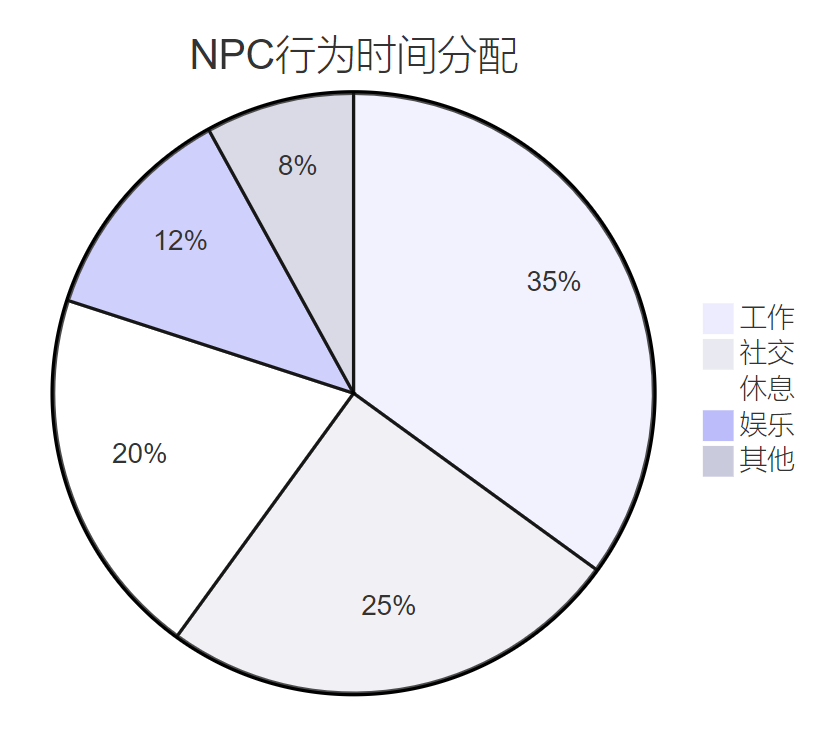
图4:NPC日常行为时间分配饼图
这个饼图显示了开放世界游戏中NPC的典型时间分配,工作占据最大比例,其次是社交活动,这种分配使得游戏世界更加真实可信。
5.2 策略游戏中的智能对手
在策略游戏中,AI Agent需要具备长期规划能力和适应性,能够根据玩家的策略调整自己的战术。
"优秀的游戏AI不是要打败玩家,而是要给玩家提供有趣的挑战。AI应该像一个技艺高超的陪练,既能展现实力,又能让玩家在挑战中成长。" —— 游戏AI设计原则
5.3 角色扮演游戏中的动态剧情
RPG游戏中的Agent可以根据玩家的选择和行为动态生成剧情分支,创造独特的故事体验。
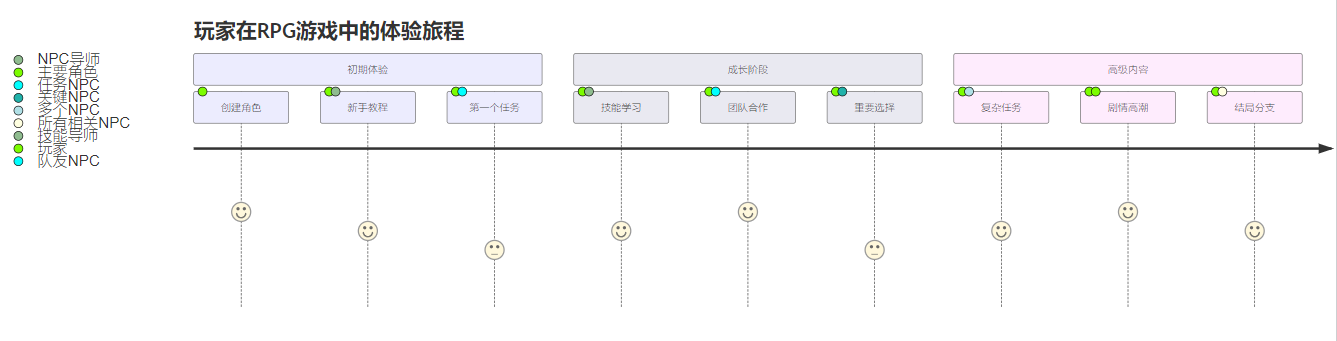
图5:RPG游戏玩家体验旅程图
该旅程图展示了玩家在RPG游戏中从新手到高级玩家的完整体验过程,以及在每个阶段与不同NPC的交互情况。
6. 未来发展趋势
6.1 技术发展方向
游戏Agent技术正朝着更加智能化和个性化的方向发展:
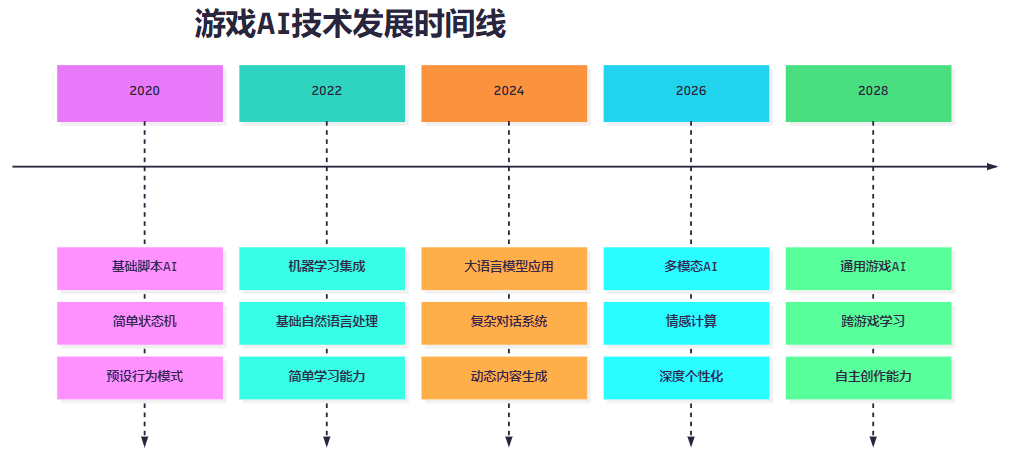
图6:游戏AI技术发展时间线
这个时间线展示了游戏AI技术从简单脚本到未来通用AI的发展历程,每个阶段都标志着技术能力的显著提升。
6.2 行业影响预测
Agent技术将对游戏行业产生深远影响:
| 影响领域 | 短期影响(1-2年) | 中期影响(3-5年) | 长期影响(5-10年) |
| 开发效率 | 提升20-30% | 提升50-70% | 提升100%以上 |
| 游戏体验 | 个性化对话 | 动态剧情生成 | 完全定制化体验 |
| 内容创作 | 辅助生成 | 半自动创作 | 全自动内容生成 |
| 玩家参与度 | 提升15-25% | 提升40-60% | 提升80%以上 |
| 运营成本 | 降低10-15% | 降低30-40% | 降低50%以上 |
表2:Agent技术对游戏行业的影响预测
从预测表可以看出,Agent技术将在各个方面对游戏行业产生积极影响,特别是在长期发展中,将带来革命性的变化。
总结
作为一名在游戏开发领域深耕多年的技术人员,我深深感受到Agent技术为游戏行业带来的巨大变革。从最初简单的脚本化NPC到如今能够进行自然对话、动态学习的智能角色,这一技术演进不仅提升了游戏的娱乐性,更重要的是为玩家创造了前所未有的沉浸式体验。
在我参与的多个项目中,我们成功地将Agent技术应用到了不同类型的游戏中。通过构建分层决策架构,我们解决了实时性与智能性之间的平衡问题;通过引入个性化内容生成系统,我们让每个玩家都能获得独特的游戏体验;通过实现多Agent协作机制,我们创造了真正"活着"的游戏世界。这些实践经验让我深刻认识到,Agent技术不仅仅是一种技术手段,更是重新定义游戏体验的关键工具。
从技术实现的角度来看,游戏Agent系统面临着实时性、一致性和可控性三大核心挑战。通过采用异步处理、缓存优化、LOD系统等性能优化策略,我们成功地在保证智能性的同时维持了游戏的流畅性。而通过融合行为树与状态机、集成大语言模型、实现动态难度调整等技术方案,我们构建了一套完整的智能NPC解决方案。
展望未来,我相信Agent技术将继续推动游戏行业的发展。随着多模态AI、情感计算和通用游戏AI技术的成熟,我们将看到更加智能、更加个性化的游戏体验。作为技术从业者,我们需要持续关注这些前沿技术的发展,并积极探索它们在游戏开发中的应用可能性。同时,我们也要注意平衡技术创新与游戏本质的关系,确保技术服务于游戏体验的提升,而不是为了技术而技术。
在这个AI技术快速发展的时代,游戏行业正站在一个重要的转折点上。Agent技术的应用不仅改变了我们开发游戏的方式,更重要的是改变了玩家与游戏世界互动的方式。我相信,通过持续的技术创新和实践探索,我们能够创造出更加精彩、更加智能的游戏世界,为玩家带来前所未有的娱乐体验。
参考链接
- Unity ML-Agents官方文档
- OpenAI GPT在游戏中的应用研究
- Game AI Pro系列技术文章
- IEEE游戏AI技术标准
- Gamasutra游戏AI开发指南
关键词标签
#游戏AI #智能Agent #NPC智能化 #动态难度调整 #个性化游戏体验
我是摘星!如果这篇文章在你的技术成长路上留下了印记:
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!