SupChains团队:化学品制造商 ChampionX 供应链需求预测案例分享(十七)
文章出自:Forecasting Case Study with a Chemical Company
本篇适合对供应链预测感兴趣的读者,文章的亮点在于通过先进的机器学习模型,ChampionX成功降低了20%的预测误差,尽管面临历史数据有限和缺乏需求驱动因素的挑战。这种方法适用于需要精确预测的行业,如化工和重工业。
手动推荐关联文章
作者Nicolas Vandeput、SupChains技术团队、供应链相关文章还有:
- SupChains技术团队零售产品销量预测建模方案解析(一)
- SupChains技术团队回答:模型准确率提高 10%,业务可以节省多少钱?(二)
- SupChains团队: 衡量Forecast模型结果在供应链团队内的传递质量(三)
- SupChains团队:供应链数据的异常特征管理指南(四)
- SupChains技术团队:需求预测中减少使用分层次预测(五)
- SupChains团队:全局机器学习模型在需求预测中的应用(六)
- VN1 供应链销量预测建模竞赛技巧总结与分享(七)
- SupChains团队:供应链新品预测建模的一些策略(八)
- 供应链团队设置安全库存的五层境界(九)
- 供应链项目中产品的ABC XYZ分类法弊端(十)
- 供应链项目中库存管理与优化指南(十一)
- 端到端供应链优化案例研究:需求预测 + 库存优化(十二)
- SupChains团队:Animalcare公司供应链需求预测模型案例分享(十三)
- 供应链需求预测项目如何设定合理的KPI、准确率指标(十四)
- 供应链项目缺货时如何进行需求预测(十五)
文章目录
- 1. 业务情况
- 2. 预测挑战
- 2.1. 预测层级
- 2.2. 有限的历史数据
- 2.3. 需求驱动因素
- 3. SupChains 解决方案
- 3.1. 预测指标
- 3.2. 数据清洗(产品过渡)
- 3.3. 模型与技术
- 3.4. 结果
- 3.5. 预测期内的结果
- 4. 自上而下与自下而上
通过使用尖端机器学习模型和广泛的预测技术,SupChains 提供了一个预测模型,帮助国际化学品制造商 ChampionX 将其预测误差降低了 20%(与基准相比)。尽管缺乏历史数据且没有需求驱动因素,但仍取得了这些成果。
1. 业务情况
我们的客户 ChampionX 在化学和石油行业占据主导地位,生产和分销各种化学制剂、产品、零件和勘探工具给其他制造商。2021 年,ChampionX 在 60 多个国家开展业务,拥有 7,000 名员工,总收入达 30 亿美元。
他们目前正在审查库存和预测实践,并寻求我们的帮助以提高预测准确性,同时就预测需求的最佳聚合级别提供见解。
2. 预测挑战
2.1. 预测层级
为了支持其供应链决策,ChampionX 需要在两个不同的聚合级别(或层级)上享有准确的预测:
- [聚合级别] 区域 x 化学制剂(约 5,000 种组合)以支持生产计划。
- [详细级别] 子区域 x 产品(约 10,000 种组合)以优化库存。
使用特定的粒度级别生成预测会影响其他各个级别的准确性。最终目标是创建按区域 x 化学制剂和按子区域 x 产品的准确预测。因此,SupChains 面临的挑战是找到最有趣的粒度级别。
2.2. 有限的历史数据
客户的 ERP 系统只允许保存长达 3 年的历史销售数据。这种 36 个月的限制在供应链中 过于常见,并且是实现最佳准确性的一个重大缺点。
我们强烈鼓励所有供应链从业者尽可能多地保留历史数据,并以清晰、一致的方式存储。,应用数据管理最佳实践将在预测准确性方面带来投资回报。
我们的客户市场是重工业,ChampionX 是复杂全球供应链中的第一环,处理大宗商品,并且对牛鞭效应高度敏感。这种行为导致了不稳定的需求模式,这对于预测模型来说尤其难以解释。
2.3. 需求驱动因素
由于化学和石油行业的性质,我们无法利用通常的需求驱动因素,如定价、营销或促销,为我们的模型提供额外的洞察。此外,已识别的影响市场的需求驱动因素是宏观经济的,且无法预测:我们无法使用它们来预测未来需求。
此外,由于 BOM 的复杂性,我们无法访问可能提供有关短缺的额外洞察的历史库存水平。
总而言之,这个数据集和预测设置由于以下三个主要原因而特别具有挑战性:
- 多个层级
- (非常)有限的历史数据
- 没有需求驱动因素(促销、价格、短缺)
3. SupChains 解决方案
这个预测挑战是我们面临过的最困难的挑战之一。
为了给自己最大的成功机会,我们尝试了基于统计和基于机器学习的模型。我们尽最大努力优化每个模型,并比较它们的准确性和偏差,以选择最佳解决方案。
3.1. 预测指标
由于数据集不稳定,我们选择了中位数绝对误差(MAE,或图表中的“预测误差”)和偏差的简单组合来评估我们预测的质量。这种组合的优点是易于解释,同时兼顾准确性和偏差。
3.2. 数据清洗(产品过渡)
在我们的密集数据清洗工作中,我们识别了产品过渡。如下图所示,当新产品取代旧产品时,我们的模型可以查看旧产品的历史销售数据,以利于预测新产品。
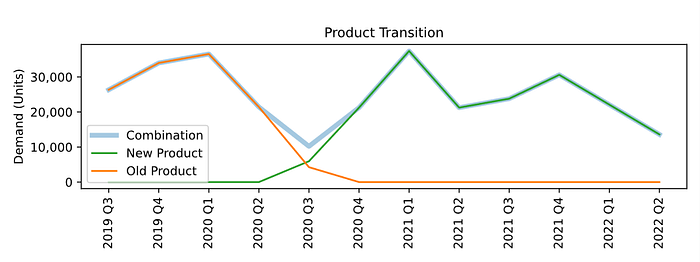
旧版本和新版本相似产品的组合。组合后的数据将用于预测未来的销售。
3.3. 模型与技术
我们开发了两个模型来应对这些挑战并提供准确的预测。
机器学习
第一个是基于树的机器学习模型。该模型利用最新的技术,如 CPU 多线程和 GPU 计算能力,在任何现代笔记本电脑上都能在 5 分钟内生成预测。
统计模型
我们的统计模型依赖于三个尖端概念:
- 多时间聚合
- 高级季节性检测
- 模型集成(多模型聚合)
并且可以在不到一分钟内提供 10,000 个预测。
3.4. 结果
如下图所示,我们的机器学习模型与基准(6 个月移动平均)相比,带来了惊人的 20% 预测附加值[1]。这比我们最先进的统计预测引擎的附加值高出一倍多。
[1] 我们将附加值计算为评分指标(结合 MAE 和偏差)的百分比降低。
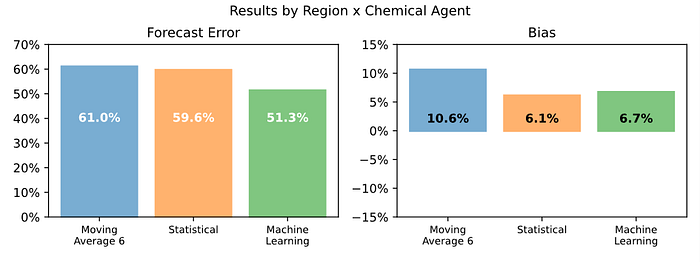
在聚合级别,机器学习提供了 19% 的 FVA(与基准相比),而统计模型为 8%。
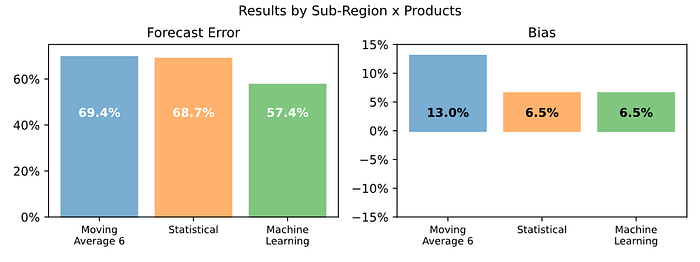
在详细级别,机器学习提供了 22% 的 FVA(与基准相比),而统计模型为 9%。
3.5. 预测期内的结果
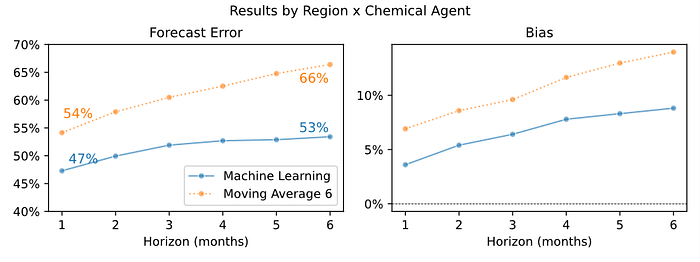
如下图所示,我们的机器学习模型在 6 个月的预测期内提供了准确的预测。模型与基准之间的差距甚至随着时间的推移而扩大!我们的模型每月仅损失约 1% 的准确性,而基准则损失约 2%。
4. 自上而下与自下而上
我们的两个机器学习模型在两种粒度上都带来了巨大的附加值。尽管如此,我们仍希望为两种粒度使用统一的预测(“单一数字预测”)。换句话说,聚合预测(区域和化学制剂)应与详细预测(子区域和产品)保持一致。
为了选择最佳模型(在聚合模型和详细模型之间),我们使用自上而下和自下而上的技术对两个聚合级别进行了第二批测试,如下图所示。此外,我们通过对最初两个模型的预测进行平均,添加了第三个“组合”预测。
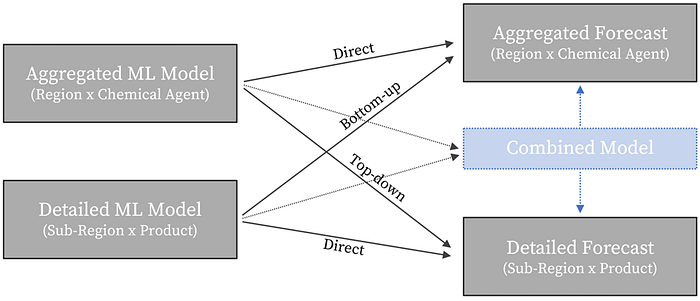
自上而下和自下而上的聚合,用于在不同聚合级别生成预测。
我们使用了 6 个月的滚动预测期,仅从 24 个月的历史数据开始生成第二批测试。对于我们的机器学习模型,如此少量的历史数据就像是“绑着一只手”战斗。尽管如此,它仍然成功地带来了与基准相比 20% 的附加值。
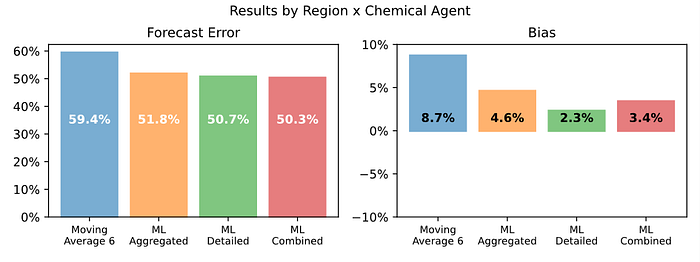
在聚合级别,组合预测的 FVA 为 19.4%(比自下而上预测低 1.6%)。
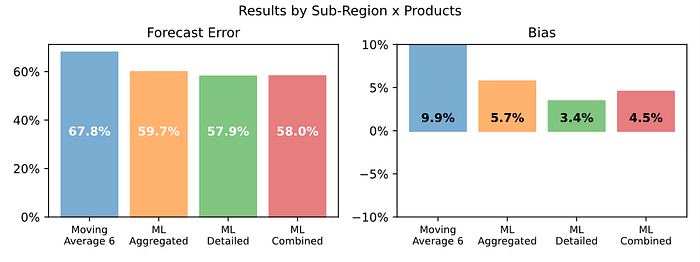
在详细级别,组合预测的 FVA 为 21.0%(比自下而上预测低 1.1%)。
如上图所示,自上而下预测(在详细级别进行)比自下而上和组合预测提供了稍微更准确的预测。
尽管如此,我们决定使用组合模型作为最终模型。事实上,我们有充分的理由相信,这种组合将随着时间的推移提供比单一的自上而下或自下而上模型更好、更具洞察力的结果。