【YOLOv1】
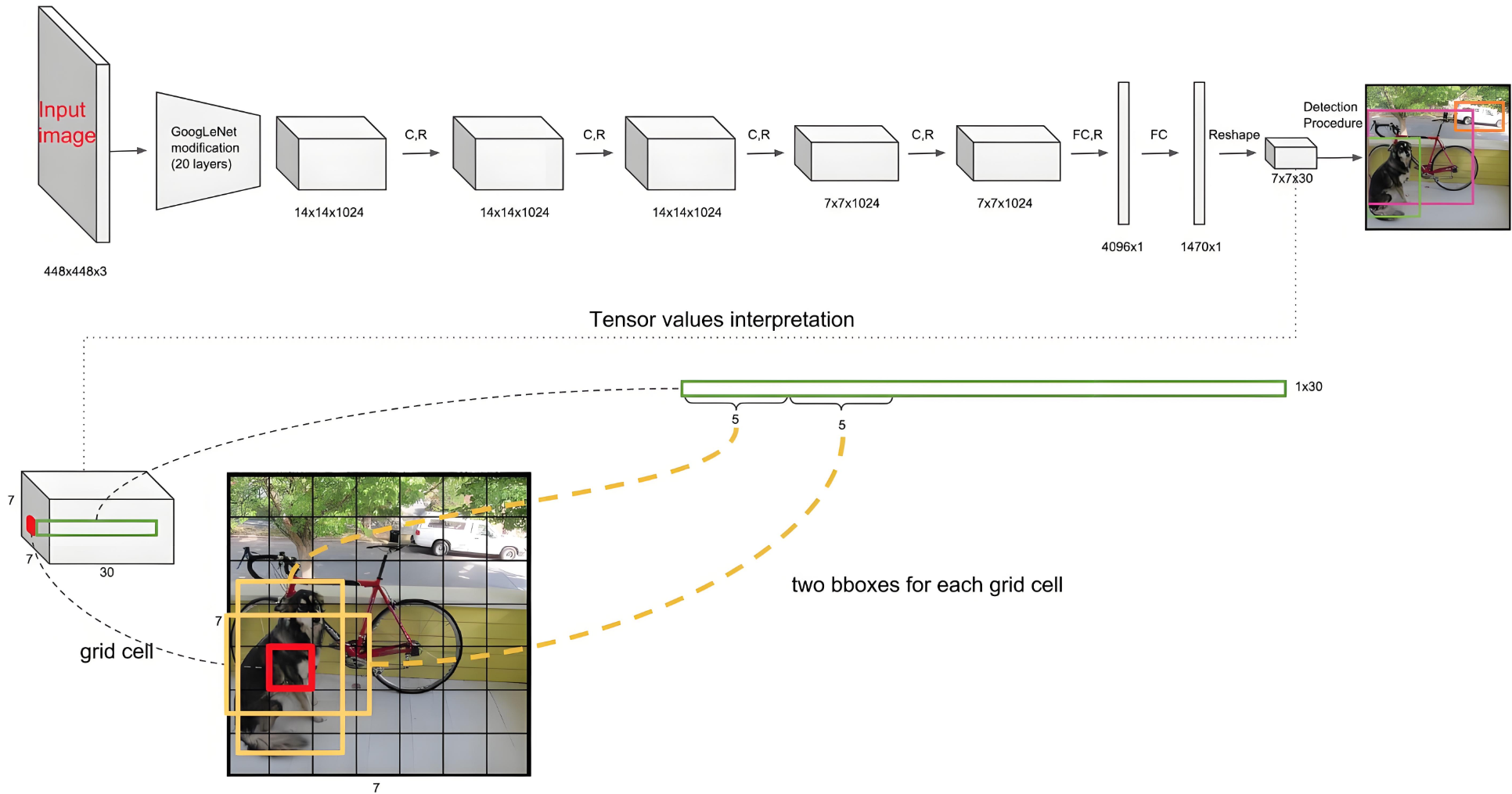
最后输出7*7*30怎么来的
yolov1的作者,把输入的图像,分成7*7个格子
每个小格子需要预测两个边界框2----->一共98个边界框
每一个边界框包含了[【坐标位置xywh+置信度】5个值 2*5 = 10
每个格子中的俩边界框,只能预测同一类别的结果,因为作者选择VOC数据集做实验,所有是20个类别
最终 7*7*30 = 7*7(2*5+20)
每一个格子只会预测某个物体中心点在这个格子上的物体,且同一个格子只会预测同一个类别物体
(上课要说!)
Fast YOLO 是减少部分网络层数 9层
核心思想
YOLOv1 采用的是将一张图片平均分成为 S x S 的网格(论文中的设置是 7 x 7),每个网格分别负责预测中心点落在该网格内的目标
每个网格的大小取决于输入图像的分辨率(如 448×448,则每个网格约为 64×64 像素)
每个网格负责检测中心点落在该网格内的目标【只有当目标的中心点坐标落在某个网格中时,该网格才负责预测该目标】
YOLOv1 算法思想步骤如下:
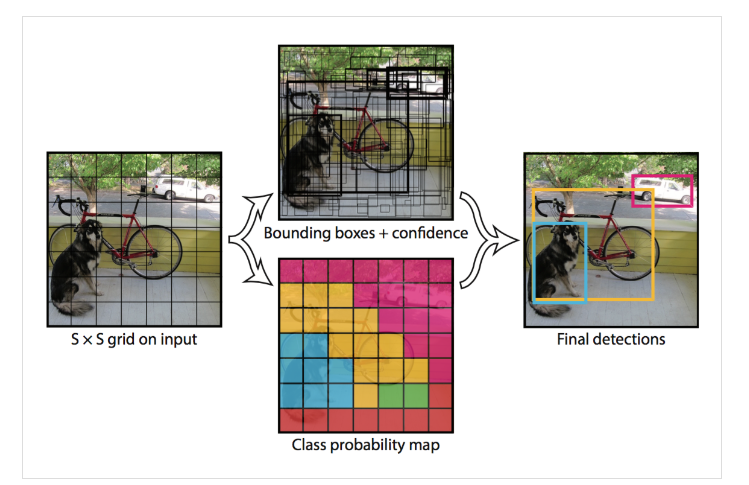
将图像划分为 S x S 的网格(论文中的设置是 7 x 7 的网格)。如果某个物体的中心落在这个网格中,那么这个网格就负责预测这个物体
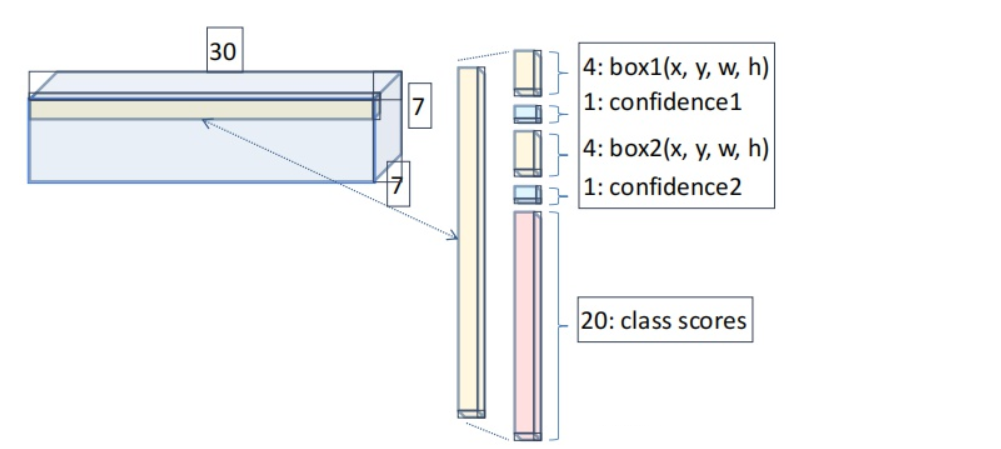
然后每个网格预测 B 个边框(论文中的设置是 2 个边框),即预测出 7 x 7 x 2 个边框,每个边框都要预测(x,y,w,h)+ confidence
项目 含义 x, y 边界框中心点相对于该网格左上角的偏移量(归一化到 [0, 1]) w, h 边界框的宽和高,相对于整张图像的宽高进行归一化 confidence 该边界框的置信度,表示框中存在目标的可能性(confidence = Pr(Object) × IoU) 除了边界框信息,每个网格还会预测 C 个类别概率(C 是类别数量,如 VOC 数据集为 20 类),这些概率是基于网格的,也就是说:不管预测几个边界框,每个网格只预测一套类别概率
最终输出的边界框类别概率 = 网格类别概率 × 边界框置信度
总体而言,S x S 个网格,每个网格要预测 B 个边框,还要预测 C 个类。输出的维度是 S x S x (5 x B + C),对于 VOC 数据集来说,最后输出就是 7 x 7 x (5 x 2 + 20),即 7 x 7 x 30
4、网络结构和预测结合
7 × 7:把图片分成7 × 7,共 49 个网格
30:每个网格有 30 个参数:20 +2 × (1+4) = 30
每个网格单元还预测 C 个条件类别概率 Pr(Classi|Object)。这些概率以包含目标的网格单元为条件。每个网格单元只预测的一组类别概率,而不管边界框的的数量 B 是多少
参数归一化
x、y 是相对于网格单元边界框的中心坐标,归一化到 0 到 1 之间
w、h 是 bb 相对于图片宽高的比例,归一化到 0 到 1 之间
5、损失函数 了解
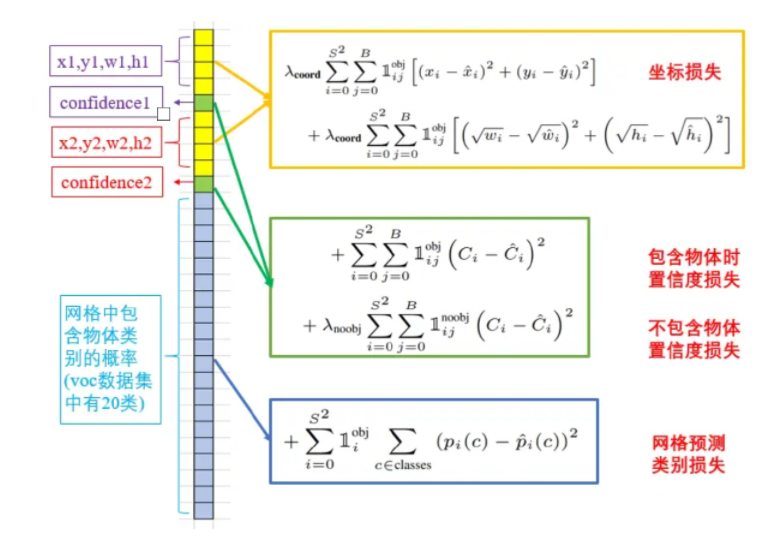
YOLOv1 中的损失函数=定位损失+置信度损失+分类损失

1 预测的中心点和实际的中心点的损失 (一般不开方是避免损失
2 开根号:小目标不受大目标的影响
公式解释:
是一个权重系数,用于平衡坐标损失与其他损失项,论文中设置的值为 5
S^2表示有多少个 grid,
B 表示框的个数,在 YOLOv1 中是 2 种,即 B 为 2
obj 表示有物体时的情况
noobj 表示没有物体时的情况
i j 表示第 i 个 的第 j 个框
1_{ij}^{obj}是一个指示函数,当某个边界框负责某个对象时为 1,否则为 0
x_i和y_i表示实际的坐标,
表示预测的坐标
w_i和h_i表示实际的宽高,
表示预测的宽高
C_i表示实际的置信度分数(C_i=Pr(obj)*IoU),\hat{C_i}表示预测的置信度分数
一个较小的权重系数,用来减少无对象区域的置信度损失的影响,论文中设置的值为 0.5
是一个指示函数,当某个边界框负责某个对象时为 0,否则为 1
p_i(c)是第 i 个网格单元格中对象的真实类别分布,\hat{p_i}(c)是预测的类别概率分布
5.1 公式解读
公式部分非常规操作详解:
关于开根号:如果直接对 w 和 h 做 MSE,大框的误差会远大于小框,导致模型更关注大目标,使用平方根可以缓解这种尺度不均衡问题,使得小目标和大目标在损失中权重更均衡
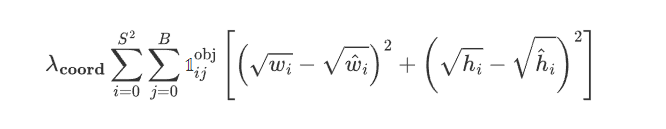
关于 S 的平方以及 i 和 j

关于权重系数

关于 noobj

6、NMS处理

7、算法性能对比
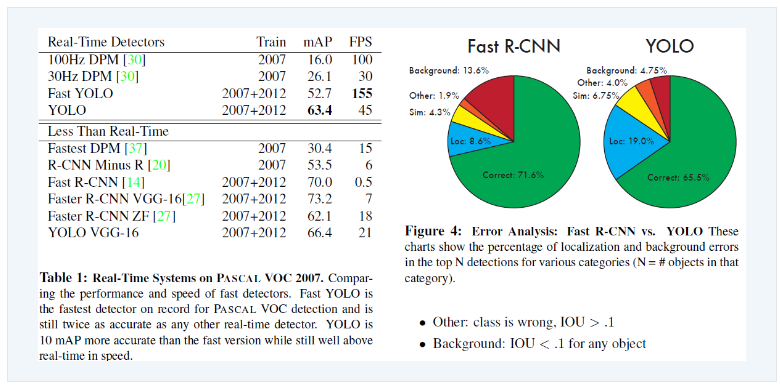
Fast R-CNN:
Correct:71.6%的检测结果是正确的
Loc:8.6%的错误是由于定位不准确
Sim:4.3%的错误是由于相似类别的误分类
Other:1.9%的错误是由于其他原因。
Background:13.6%的错误是将背景误判为对象
YOLO:
Correct:65.5%的检测结果是正确的
Loc:19.0%的错误是由于定位不准确
Sim:6.75%的错误是由于相似类别的误分类
Other:4.0%的错误是由于其他原因
Background:4.75%的错误是将背景误判为对象
8、优缺点
8.1 优点
实时处理:可达到 45 fps,远高于 Faster R-CNN 系列,轻松满足视频目标检测
避免产生背景错误:YOLO 的区域选择阶段是对整张图进行输入,上下文信息利用更充分,不容易出现错误背景信息
8.2 缺点
定位精度不够高:由于输出层为全连接层,在检测时只支持与训练图像相同的输入分辨率
小物体和密集物体检测效果不佳:每个网格单元只能预测两个框,并且只能有一个类,这使得它难以处理成群出现的小对象,例如鸟群
召回率低:会错过一些实际存在的目标