模型的存储、加载和部署
定义损失函数并以此训练和评估模型
存储模型可以只存储state_dict或模型参数,每当需要部署经过训练的模型时,创建模型的对象并从文件中加载参数,这是 Pytorch 创建者推荐的方法。
目录
模型的存储、加载
模型的部署
模型的存储、加载
承接上文,完成模型的训练后,需要将训练的参数存储在文件中,以供部署和使用。
#定义路径
path2weights="./models/weights.pt"
#将state_dict存储到文件
torch.save(model.state_dict(), path2weights)为了从文件中加载模型参数,定义一个 Net 的对象类并加载state_dict
#定义随机初始权重模型
_model = Net()
#加载文件中的state_dict
weights=torch.load(path2weights)
#赋予权重
_model.load_state_dict(weights)加载成功如下
![]()
模型的部署
将模型加载到内存中后,可以将新数据传递给模型
import matplotlib.pyplot as plt
#抽取一个n=10张量
n=10
x= x_val[n]
y=y_val[n]
print(x.shape)
plt.imshow(x.numpy()[0],cmap="gray")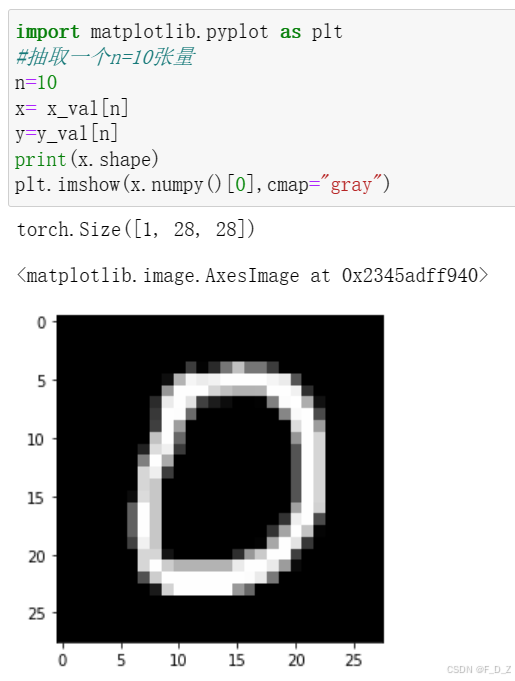
对张量进行预处理
#将维度扩展为 1*C*H*W
x= x.unsqueeze(0)
#转换为torch.float32格式
x=x.type(torch.float)得到模型预测
#获取模型输出
output=_model(x)
#获取预测结果
pred = output.argmax(dim=1, keepdim=True)
print (pred.item(),y.item()) 