电子书转PDF格式教程,实现epub转PDF步骤
EPUB 格式属于流式文档,在屏幕尺寸各异的设备上都能自动适配显示。然而,要是你使用的是特定的阅读设备,像打印机、不支持 EPUB 格式的电子阅读器(例如某些早期的 Kindle 型号),或者需要在固定尺寸的屏幕上展示内容,那么转换为 PDF 格式会是更好的选择。下面就教你怎么把电子书转换成PDF格式。
一、 使用命令行工具实现批量转换
如果你需要批量转换 EPUB 文件,可以结合命令行工具编写脚本:
bash
#!/bin/bash# EPUB 转 PDF 批量转换脚本
# 需要安装 calibre 工具包(包含 ebook-convert 命令)# 源目录(存放 EPUB 文件)
SRC_DIR="epubs"# 目标目录(保存 PDF 文件)
DEST_DIR="pdfs"# 创建目标目录(如果不存在)
mkdir -p "$DEST_DIR"# 遍历 EPUB 文件并转换
for epub_file in "$SRC_DIR"/*.epub; do
if [ -f "$epub_file" ]; then
# 获取文件名(不含扩展名)
filename=$(basename "$epub_file" .epub)
# 转换为 PDF
echo "正在转换: $filename.epub"
ebook-convert "$epub_file" "$DEST_DIR/$filename.pdf"
if [ $? -eq 0 ]; then
echo "✓ 转换成功: $filename.pdf"
else
echo "✗ 转换失败: $filename.epub"
fi
fi
doneecho "批量转换完成!"
使用此方案前需要安装 Calibre 工具包,它提供了强大的 ebook-convert 命令行工具。
二、使用 Python 实现 EPUB 转 PDF也是个不错的技术选择
你可以使用 Python 的 ebooklib 库读取 EPUB 文件,然后使用 pdfkit 或 reportlab 库生成 PDF。这种方案适合自动化批量转换。
以下是一个使用 Python 实现 EPUB 转 PDF 的示例代码:
import ebooklib
from ebooklib import epub
from bs4 import BeautifulSoup
import pdfkitdef epub_to_pdf(epub_path, pdf_path):
try:
# 读取 EPUB 文件
book = epub.read_epub(epub_path)
# 提取 EPUB 中的文本内容
text_content = ""
for item in book.get_items():
if item.get_type() == ebooklib.ITEM_DOCUMENT:
content = item.get_content().decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
text_content += soup.get_text() + "\n\n"
# 配置 pdfkit(需要安装 wkhtmltopdf)
config = pdfkit.configuration(wkhtmltopdf=r'C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe') # 根据实际安装路径修改
# 将文本转换为 PDF
pdfkit.from_string(text_content, pdf_path, configuration=config)
print(f"转换成功!PDF 文件已保存至: {pdf_path}")
return True
except Exception as e:
print(f"转换失败: {e}")
return False# 使用示例
if __name__ == "__main__":
epub_file = "example.epub" # 替换为你的 EPUB 文件路径
pdf_file = "output.pdf" # 替换为你想要保存的 PDF 文件路径
epub_to_pdf(epub_file, pdf_file)
使用此方案前需要安装以下依赖:
pip install ebooklib beautifulsoup4 pdfkit
另外,还需要安装 wkhtmltopdf 工具并配置其路径。
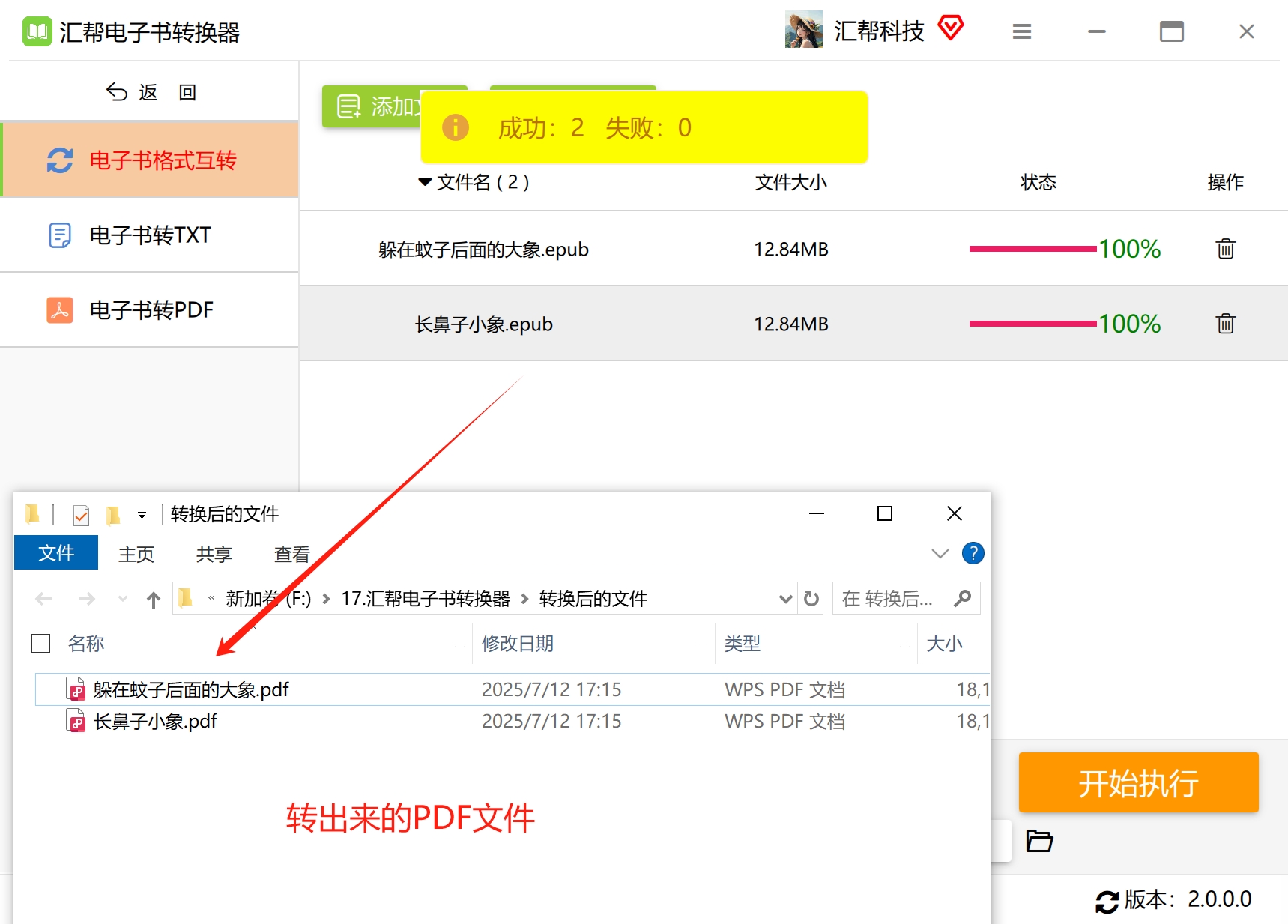
三、如果我们对技术的视线方式一窍不通,市面上也有很多帮我们实现好的界面话的工具,比如“汇帮电子书转换器”就可以转换。这个方法更适合小白操作。
实现注意事项:
1、格式保真:EPUB 和 PDF 是两种不同类型的格式,转换过程中可能会丢失一些格式信息,如交2、互式元素、动态内容等。
3、依赖安装:Python 和 Node.js 方案都需要安装额外的依赖库和工具,如 wkhtmltopdf 或 Calibre。
4、性能考虑:对于大量或大型 EPUB 文件,转换可能需要较长时间,可以考虑使用多线程或分布式处理。
5、样式处理:如果需要更好地保留 EPUB 中的样式,可以提取 EPUB 中的 CSS 并应用到生成的 PDF 中。
选择哪种方案取决于你的具体需求和技术栈,Python 方案适合快速开发,Node.js 方案适合集成到 Web 服务中,而命令行工具则适合简单批量转换。