Python高效操作MySQL数据库
python操作MySQL数据库
- 安装python MySQL连接库
- 安装mysql-connector-python
- 安装PyMySQL(作为替代)
- 从外部导入一个数据库
- python连接MySQL数据库
- (1)导入数据库
- (2)创建数据库连接
- (3)创建游标对象
- (4)执行SQL语句
- (5)获取查询结果
- (6)关闭连接
- (7)执行结果
- 常见的MySQL操作
- (1)插入数据(INSERT)
- (2)更新数据(UPDATE)
- (3)删除数据(DELETE)
- (4)查询数据(SELECT)
- (5)执行多条SQL语句
- (6)使用LIKE进行模糊查询
- (7)使用JOIN进行联合查询
- 使用连接池
- 连接池简介
- 创建连接池
- 获取连接
- 连接池的优势
- 事务管理
- 1.开始事务
- 2.提交事务
- 3.回滚事务
- 4.事务的隔离级别
- (1)READ UNCOMMITTED(未提交读)
- (2)READ COMMITTED(提交读)
- (3)REPEATABLE READ(可重复读)
- (4)SERIALIZABLE(串行化)
- 5:事务隔离级别总结
- 6.案例
安装python MySQL连接库
mysql-connector-python是一个官方推荐的库,用于与MySQL数据库进行交互
安装mysql-connector-python
pip3 install mysql-connector-python
安装PyMySQL(作为替代)
pip3 install pymysql
从外部导入一个数据库

python连接MySQL数据库
(1)导入数据库
首先,我们需要导入pymysql模块,使用它来连接MySQL数据库并执行sql语句

(2)创建数据库连接
我们使用pymysql.connect()方法来建立数据库连接。连接时需要提供MySQL服务器的地址,用户名,密码和要访问的数据库名
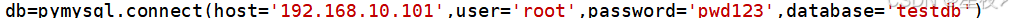
host这里如果写的不是localhost本机需要给root授权
#创建用户root除了localhost以外的可以登录
create user 'root'@'%' IDENTIFIED BY 'pwd123';
#给root用户授权所有权限
grant all ON *.* TO 'root'@'%';
#给root用户密码进行加密
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'pwd123';
(3)创建游标对象
建立连接后,我们需要创建一个游标对象,通过它来执行SQL语句
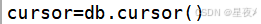
(4)执行SQL语句
通过浮标对象的execute()方法,我们可以执行SQL语句。在执行SQL时,可以使用%s占位符来避免SQL注入攻击

(5)获取查询结果
对于查询操作,fetchall()方法用于获取所有结果,fetchone()方法用于获取单条记录
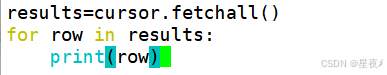
(6)关闭连接
操作完成后,记得关闭游标和数据库连接
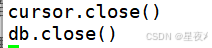
(7)执行结果

常见的MySQL操作
(1)插入数据(INSERT)
插入数据时,我们使用INSERT INTO 语句,通过execute()方法执行插入操作。为了防止SQL注入攻击,插入语句中的值应使用%s占位符
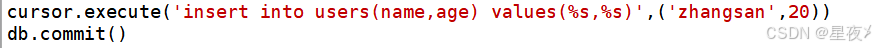

(2)更新数据(UPDATE)
更新数据时,我们使用UPDATE语句,我们通过execute()方法。通常我们会添加WHERE条件,以确保只更新需要更新的记录
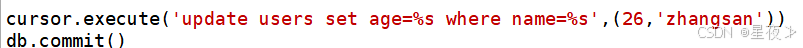

(3)删除数据(DELETE)
删除数据时,我们使用DELTETE语句,并通过where条件确保删除特定记录
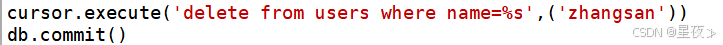

(4)查询数据(SELECT)
查询数据时,使用SELECT语句,可以使用fetchall()获取所有记录,或使用detchone()来获取一条记录

(5)执行多条SQL语句
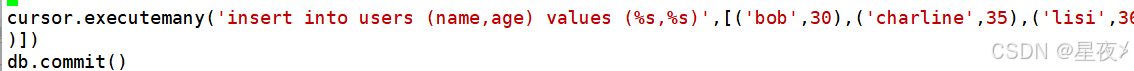

(6)使用LIKE进行模糊查询
LIKE关键字允许你进行模糊查询。你可以使用%通配符来匹配任意字符

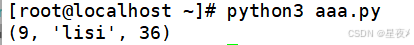
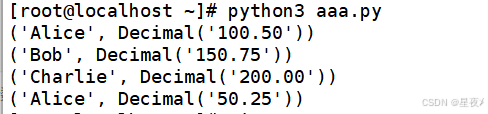
(7)使用JOIN进行联合查询
在多个表之间建立关系时,JOIN关键字用于合并多个表的数据

使用连接池
连接池简介
连接池技术能够在高并发场景下提升数据库连接的效率。在连接池中,多个数据库连接被提前创建并放入池中,客户端通过池获取连接,而不是每次都建立新的连接。这大大减少了连接创建和销毁的开销。
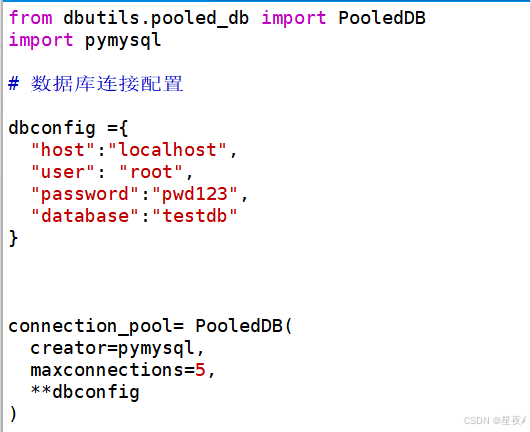
创建连接池
PyMySQL并不直接支持连接池,但我们可以使用 DBUtils 库来创建连接池。首先需要安装 DButils:
pip3 install dbutils
获取连接
从连接池中获取连接时,可以使用connection()方法。每次获取到的连接都可以直接执行数据库操作。

连接池的优势
性能提升:连接池减少了每次数据库操作时创建新连接的开销,提高了数据库操作的效率。
资源管理:连接池能够限制最大连接数,避免因过多的数据库连接导致数据库过载。
更易管理:通过连接池,可以统一管理连接的生命周期,简化代码结构。
事务管理
事务是由多个 5QL语句组成的一个工作单元。事务保证了数据的原子性,即所有操作要么都成功,要么都失败。
1.开始事务
事务可以通过 START TRANSACTION来显式开启,但一般我们通过执行 SQL 语句来启动事务。
cursor.execute("START TRANSACTION")
2.提交事务
如果事务中的所有操作都成功,我们使用commit()方法提交事务,保存对数据库的更改。
db.commit()
3.回滚事务
如果事务中的某些操作失败,我们可以使用ro11back()方法回滚事务,将所有更改撤销。
db.rollback()
4.事务的隔离级别
MySQL支持四种事务隔离级别,它们定义了在并发事务执行时一个事务的操作对于其他事务的影响。
隔离级别的设置越高,事务间的干扰越小,但同时可能导致性能下降。MySQL的默认隔离级别是REPEATABLE READ,具体如下:
(1)READ UNCOMMITTED(未提交读)
描述:事务可以读取其他事务未提交的数据,可能导致“脏读”(Dirty Read)。这种级别下,事务间的隔离性最差。
应用场景:通常不推荐使用,除非对数据一致性要求不高。
使用方法:
cursor.execute("SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED")
(2)READ COMMITTED(提交读)
描述:事务只能读取其他事务已经提交的数据,避免了脏读,但仍然可能遇到“不可重复读”(Non-repeatable Read)的问题。即事务中读取的数据在两次读取时可能发生变化(另一个事务已提交了修改)。
应用场景:适用于大多数常见场景,提供了一定的隔离性,同时保证了较好的性能。
使用方法:
cursor.execute("SET TRANSACTION ISOLATION LEVEL READ COMMITTED")
(3)REPEATABLE READ(可重复读)
描述:事务可以保证在事务内多次读取同一数据时,其值不会发生变化。这避免了“不可重复读”的问题,但依然可能会出现“幻读”(Phantom Read),即一个事务读取的数据集在事务执行过程中发生了变化。
应用场景:对于需要保证事务数据一致性的场景,例如金融系统中的余额操作等,可以考虑使用该隔离级别。
使用方法:
cursor,execute("SET TRANSACTION ISOLATION LEVEL REPEATABLE READ")
(4)SERIALIZABLE(串行化)
描述:这是最严格的事务隔离级别,事务会被执行得像串行一样,完全避免了脏读、不可重复读和幻读。然而,这种隔离级别的性能开销最大,可能导致大量的锁竞争。
应用场景:适用于对数据一致性要求极高的场景,如库存管理系统、银行转账等。
使用方法:
cursor.exeCute("SET TRANSACTION ISOLATION LEVEL SERIALIZABLE" )
5:事务隔离级别总结
READ UNCOMMITTED:允许脏读,最低的隔离级别,性能最好,但容易出现数据不一致的情况。
READ COMMITTED:解决了脏读问题,但可能出现不可重复读。
REPEATABLE READ:解决了脏读和不可重复读问题,但可能出现幻读。
SERIALIZABLE:解决了所有问题,但性能最差,可能导致事务长时间等待。
在选择事务隔离级别时,需要根据应用的具体需求平衡数据一致性和性能。如果事务数据不频繁冲突可以选择较低的隔离级别以提升性能;而对于数据一致性要求极高的场景,则应选择更高的隔离级别,尽管这会带来性能上的损失。
在MySQL中,事务的认隔离级别是 REPEATABLE READ
6.案例
