技术专栏|LLaMA家族——模型架构
LLaMA的模型架构与GPT相同,采用了Transformer中的因果解码器结构,并在此基础上进行了多项关键改进,以提升训练稳定性和模型性能。LLaMA的核心架构如图 3.14 所示,融合了后续提出的多种优化方法,这些方法也在其他模型(如 PaLM)中得到了应用。
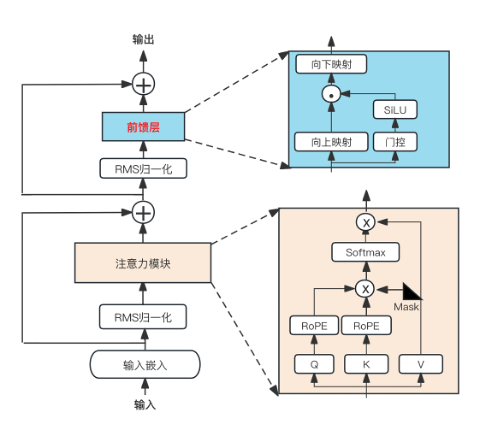
图3.14 LLaMA的模型架构示意图
模型有以下主要特点:
1.前置的归一化层(Pre-Normalization):为增强训练稳定性,LLaMA 采用前置归一化策略,即在每个 Transformer 子层的输入之前进行归一化,而非传统的后置归一化。
2.SwiGLU激活函数和降维:在前馈层(FFN)中采用用SwiGLU激活函数,替代传统的ReLU,提升了非线性表达能力和训练稳定性。前馈层维度减少为²⁄₃ 4d,其表达式down(up(x))×SwiGLU(gate(x)),其中down、up、gate都是线性层。
3.旋转式位置编码(RoPE):在查询(Q)和键(K)上应用旋转式位置编码,以增强模型对相对位置信息的感知能力。
前置归一化层详解
归一化操作可以协调在特征空间上的分布,更好地进行梯度下降。在神经网络中,特征经过线性组合后,还要经过激活函数,如果某个特征数量级过大,在经过激活函数时,就会提前进入它的饱和区间(例如sigmoid激活函数),即不管如何增大这个数值,它的激活函数值都在1附近,不会有太大变化,这样激活函数就对这个特征不敏感。在神经网络用SGD等算法进行优化时,不同量纲的数据会使网络失衡,变得不稳定。
归一化的方式主要包括以下几种方法:批归一化(BatchNorm)、层归一化(LayerNorm)、实例归一化(InstanceNorm)、组归一化(GroupNorm)。归一化的不同方法对比如图3.15所示,图中N表示批次,C表示通道,H,W表示空间特征。
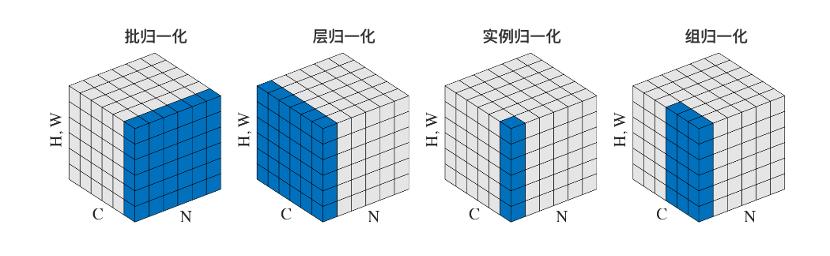
图3.15 归一化的不同方法对比
1.BatchNorm:在批次方向做归一化,计算N×H×W的均值,BatchNorm的主要缺点是对批次的大小比较敏感,对小的批次大小效果不好;由于每次计算均值和方差是在一个批次上,所以如果批次太小,则计算的均值、方差不足以代表整个数据分布;同时,对于RNN来说,文本序列的长度是不一致的,即RNN的深度不是固定的,不同的时间步需要保存不同的统计特征,可能存在一个特殊序列比其他序列长很多的情况,这样在训练时计算很麻烦。
2.LayerNorm:在通道方向做归一化,计算C×H×W的均值,LayerNorm中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差,所以,LayerNorm不依赖于批次的大小和输入序列的深度,因此对于RNN的输入序列进行归一化操作很方便,而且作用明显。
3.InstanceNorm:一个通道内做归一化,计算H×W的均值,主要用在图像的风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个批次归一化不适合图像风格化中,因而对H×W做归一化,可以加速模型收敛,并且保持每个图像实例之间的独立。
4.GroupNorm:将通道方向分组,然后每个组内做归一化,计算(C//G)HW的均值,G表示分组的数量;这样与批次大小无关,不受其约束。当批次大小小于16时,可以使用这种归一化。
5.SwitchableNorm:将BatchNorm、LayerNorm、InstanceNorm结合,赋予权重,让网络自己学习归一化层应该使用什么方法。其使用可微分学习,为一个深度网络中的每一个归一化层确定合适的归一化操作。
旋转位置编码详解
旋转位置编码(RotaryPositionEmbedding,RoPE)是一种将相对位置信息融入自注意力机制的位置编码方法,能够提升Transformer架构的表达能力和外推性能。受GPTNeo的启发,LLaMA放弃了传统的绝对位置编码,而采用旋转位置编码,这种方式已成为当前主流大模型中最常用的相对位置编码方案之一。
ROPE的核心优势在于提升模型外推能力——即在训练与推理时输入长度不一致的情况下仍具备良好的泛化性能。例如,若模型训练时仅见过512个token的文本,传统绝对位置编码方法在推理超过该长度时可能性能骤降,而RoPE能自然延展到更长的输入序列,适应长文本和多轮对话等任务。
旋转位置编码总结如下:
1.保持相对位置信息一致性:RoPE可以有效地保持位置信息的相对关系,即相邻位置的编码之间有一定的相似性,而远离位置的编码之间有一定的差异性。这样可以增强模型对位置信息的感知和利用,而这正是其他绝对位置编码方式(如正弦位置编码、学习的位置编码等)所不具备的。
2.具备强外推性:RoPE可以通过旋转矩阵来生成超过预训练长度的位置编码,显著提高模型的泛化能力和鲁棒性。这是固定位置编码方式(如正弦位置编码、固定相对位置编码等)难以实现的,因为它们只能表示预训练长度内的位置,而不能表示超过预训练长度的位置。
3.计算高效,兼容线性注意力:RoPE可以与线性注意力机制兼容,即不需要额外的计算或参数来实现相对位置编码。RoPE 相较于Transformer-XL、XLNet等混合编码方式,具有更低的计算与内存开销。
RoPE 的实现流程简述如下:对每个 token,先计算其查询和键向量,再根据其位置信息生成对应的旋转位置编码。随后将查询和键的向量按照两两一组进行旋转变换,最后通过内积计算自注意力分数。此外,RoPE 可从二维推广至任意维度,进一步拓展其在复杂任务中的应用潜力。

全文引自《开启智能对话新纪元:大规模语言模型的探索与实践》