【大模型原理与技术-毛玉仁】第五章 模型编辑
5 模型编辑
5.1 模型编辑简介
大语言模型有时会产生一些不符合人们期望的结果,如偏见、毒性和知识错误等。
偏见是指模型生成的内容中包含刻板印象和社会偏见等不公正的观点,毒性是指模型生成的内容中包含有害成分,而知识错误则是指模型提供的信息与事实不符。

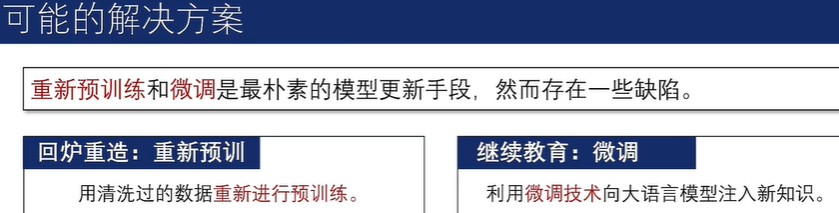
然而,重新预训练存在成本过高等缺陷,微调存在过拟合、灾难性遗忘等缺陷。
为规避重新预训练和微调方法的缺点,模型编辑应运而生。其旨在精准、高效地修正大语言模型中的特定知识点,能够满足大语言模型对特定知识点进行更新的需求。
模型编辑思想


模型编辑定义

模型编辑挑战

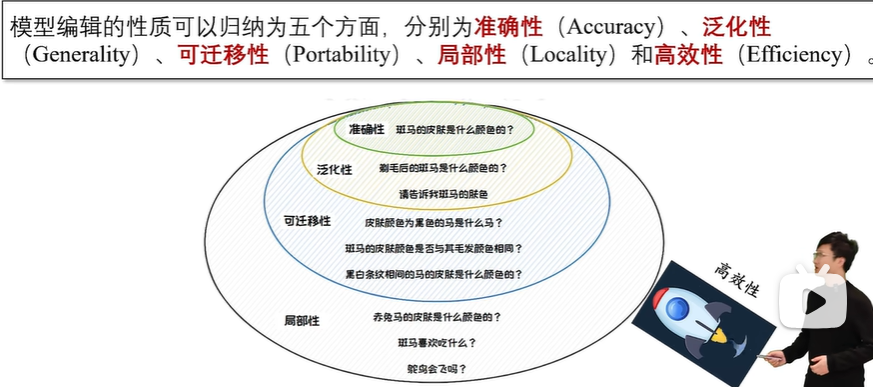
模型编辑性质






常用数据集
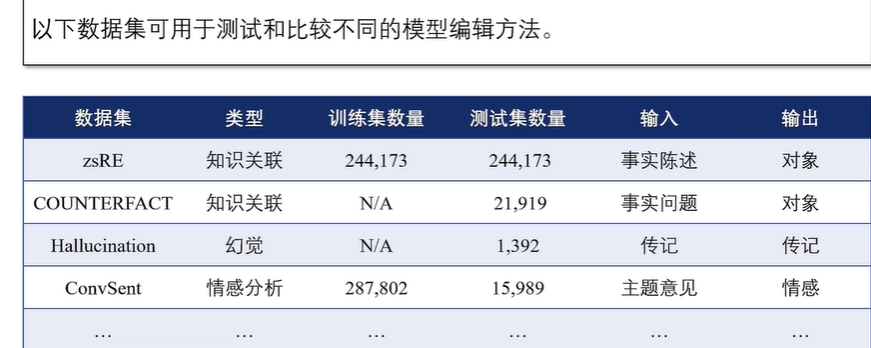
在模型编辑的相关研究中,使用最广泛的是由Omer Levy 等人提出的zsRE数据集。
zsRE是一个问答任务的数据集,通过众包模板问题来评估模型对于特定关系(如实体间的“出生地”或“职业”等联系)的编辑能力。
在模型编辑中,zsRE数据集用于检查模型能否准确识别文本中的关系,以及能否根据新输入更新相关知识,从而评估模型编辑方法的准确性。
5.2 模型编辑经典方法
如果将大语言模型比作冒险游戏中的勇者,那么模型编辑可被看作一种满足“升级”需求的方法,可以分别从内外两个角度来考虑。
外部拓展法:通过设计特定的训练程序,使模型在保持原有知识的同时学习新信息。
内部修改法:通过调整模型内部特定层或神经元,来实现对模型输出的精确控制。
外部拓展法
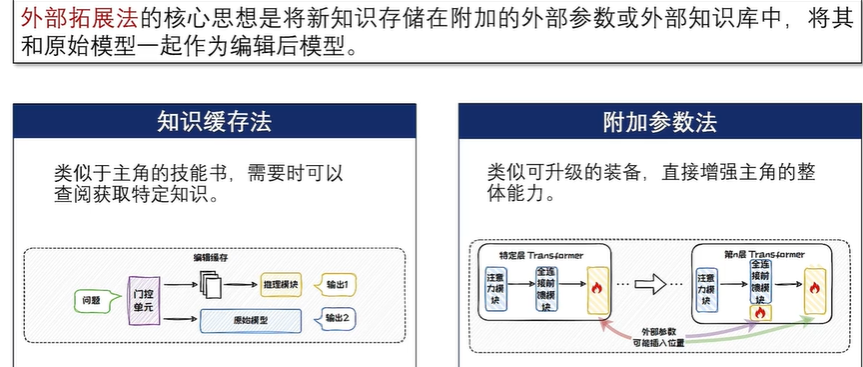
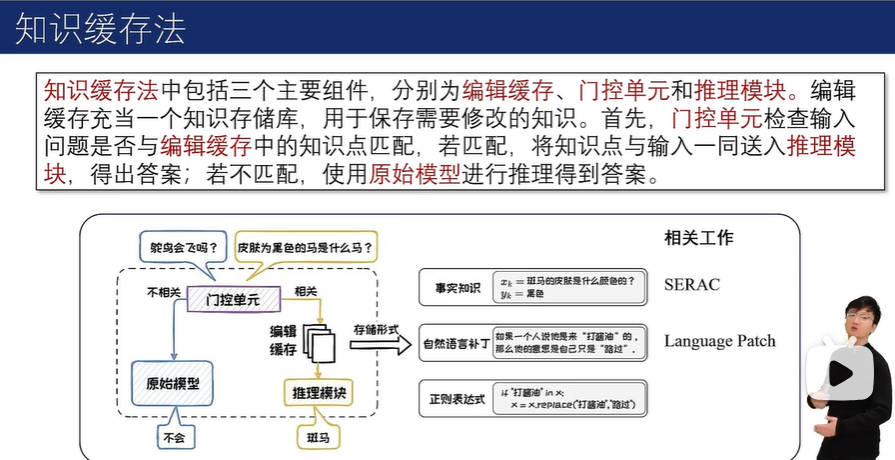
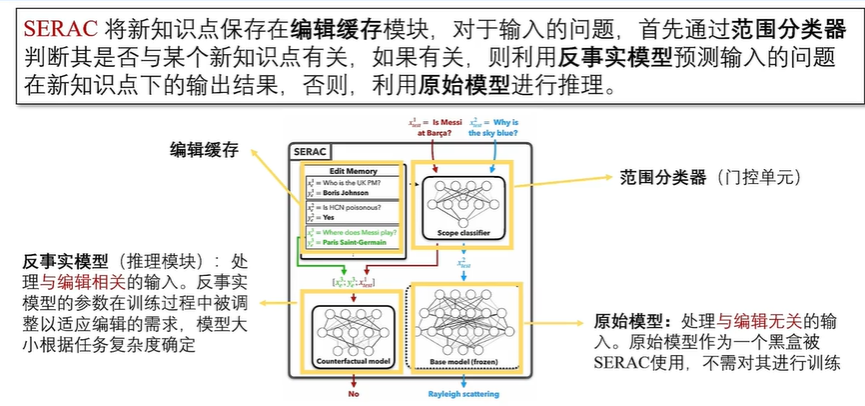
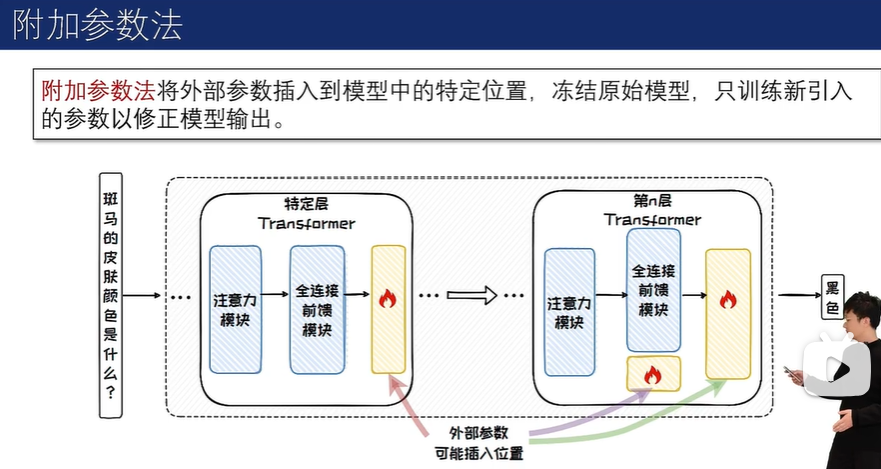
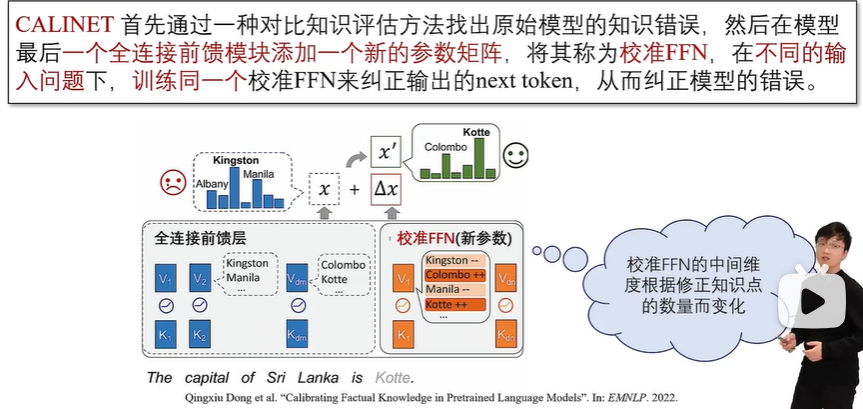
外部拓展法包括知识缓存法和附加参数法。
内部修改法
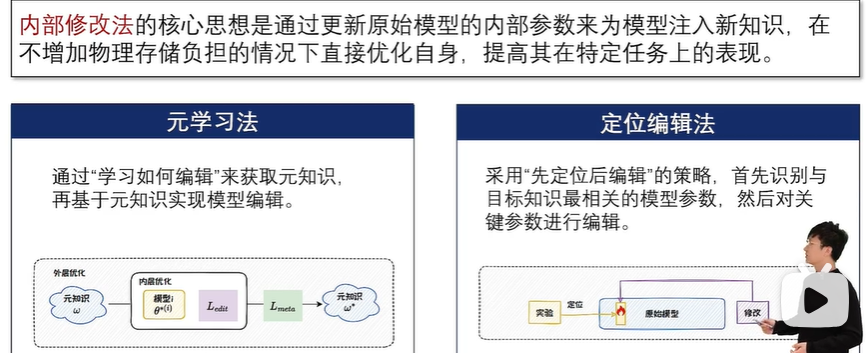
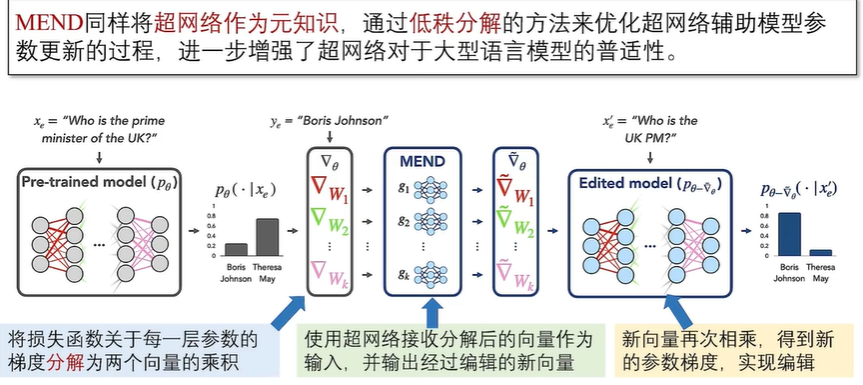
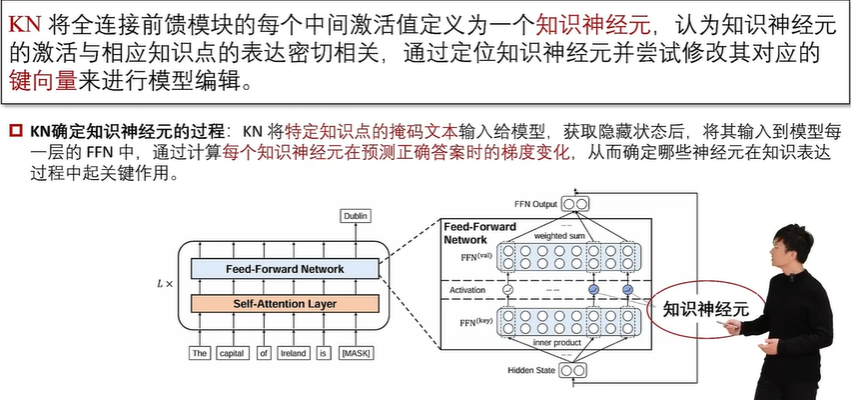
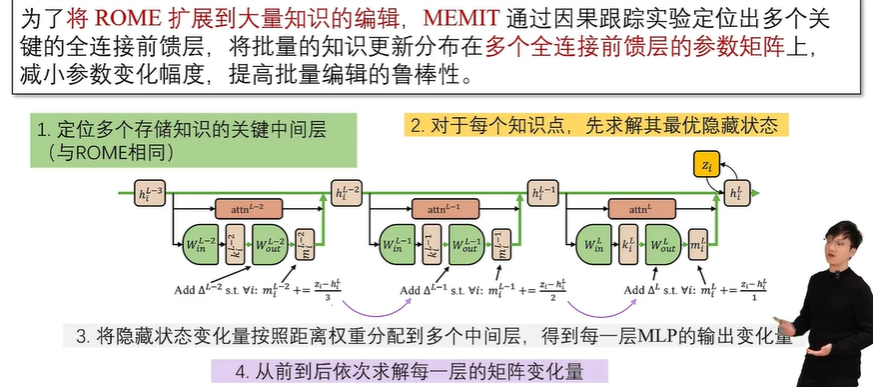
内部修改法包括元学习法和定位编辑法。


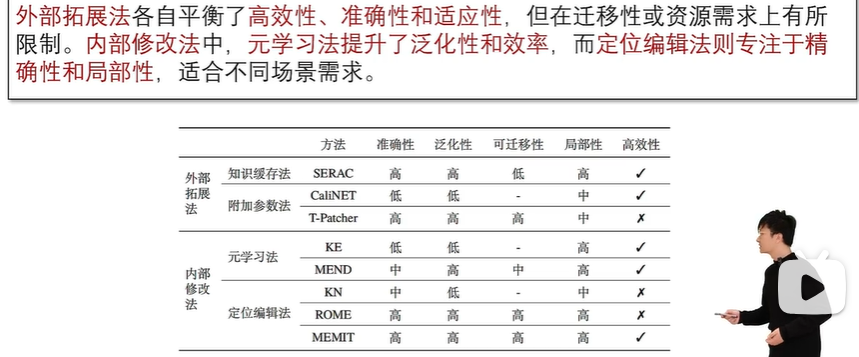
方法比较
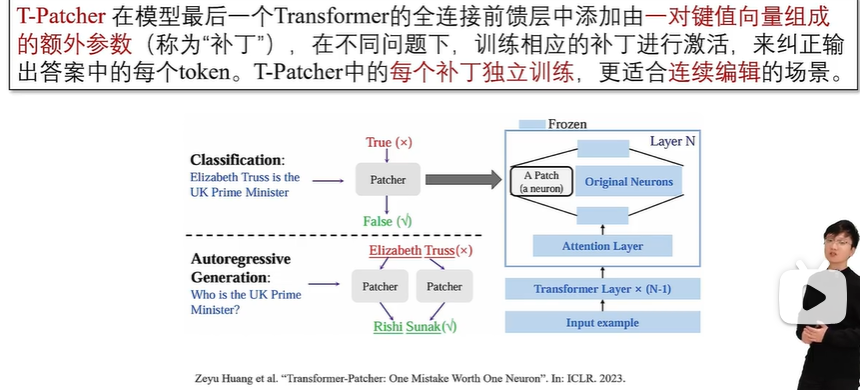
5.3 附加参数法:T-Patcher
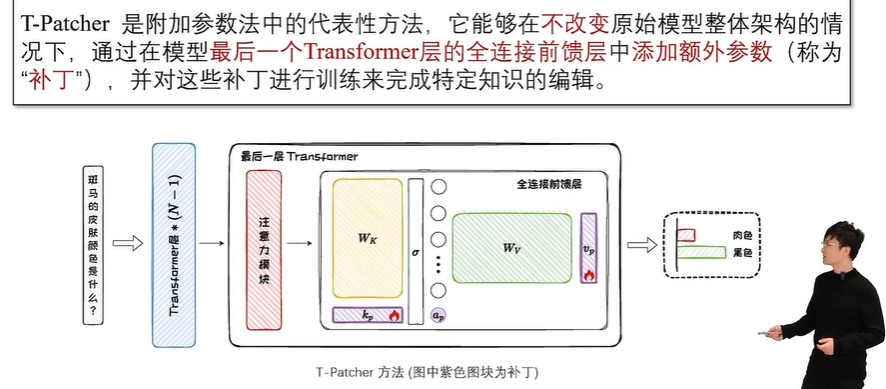
补丁的位置
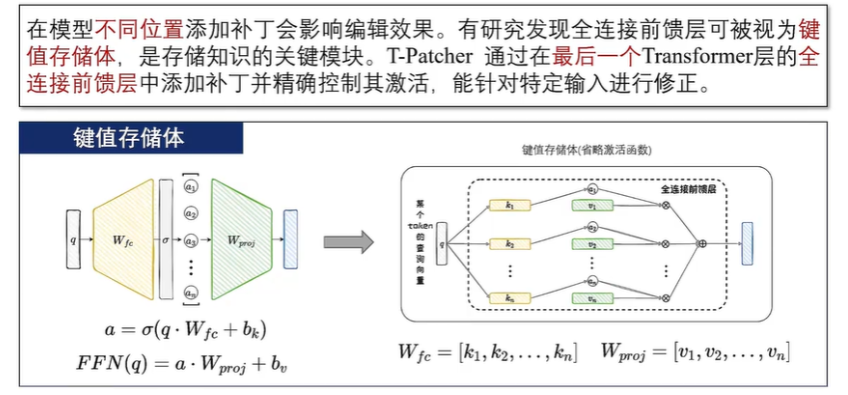
补丁的形式
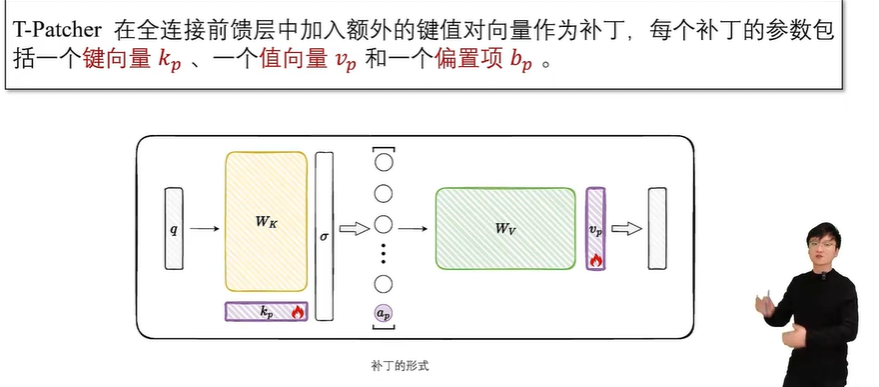

补丁的实现
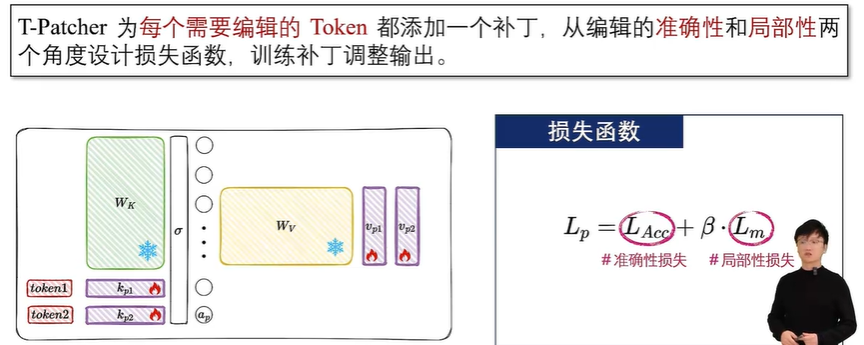


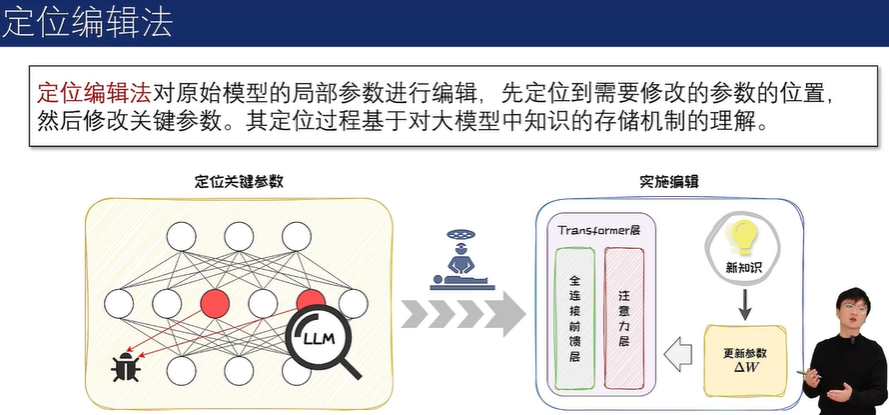
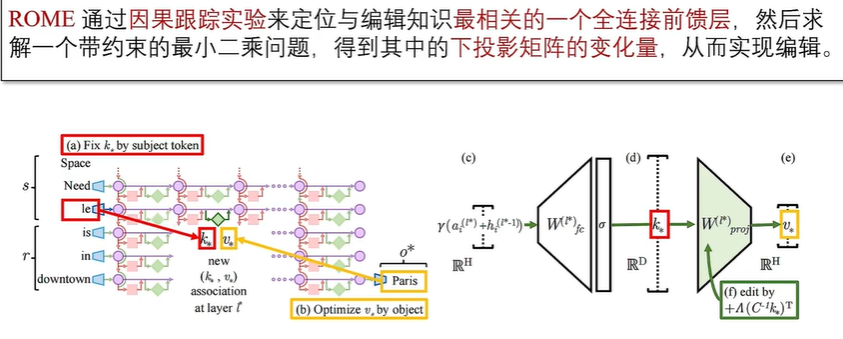
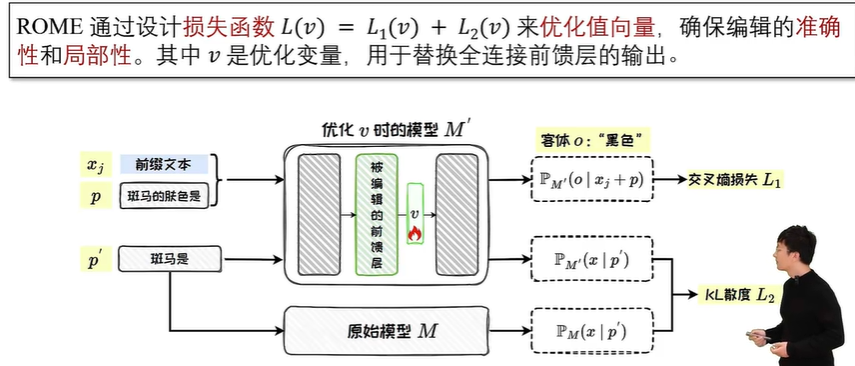
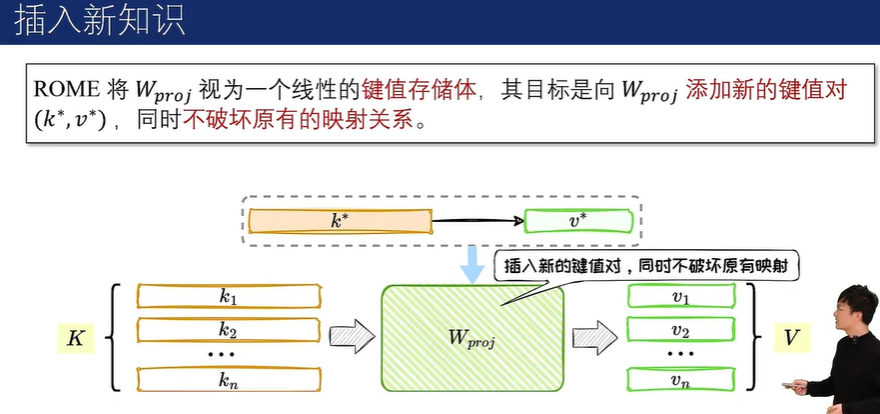
5.4 定位编辑法:ROME


知识存储位置
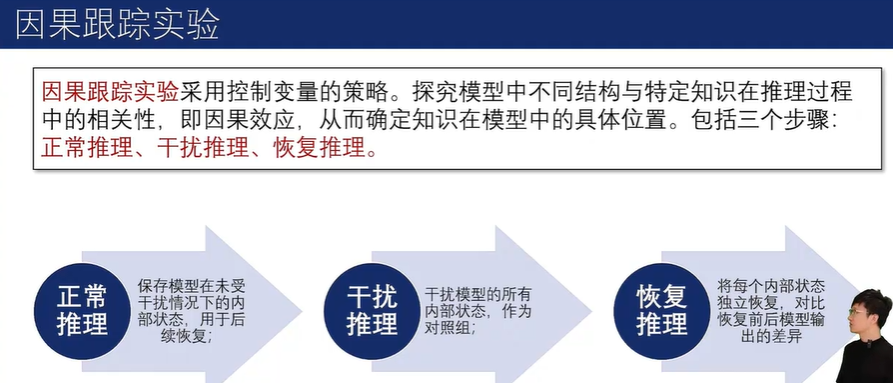
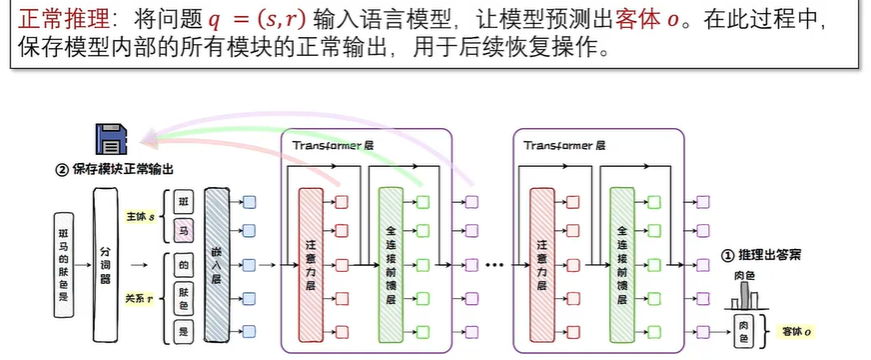
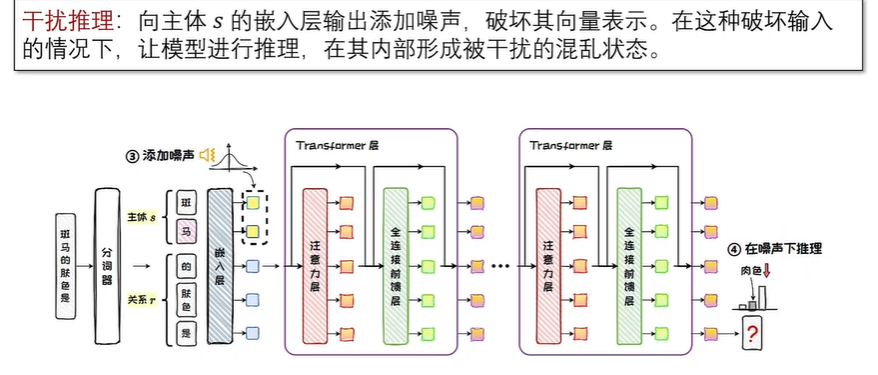
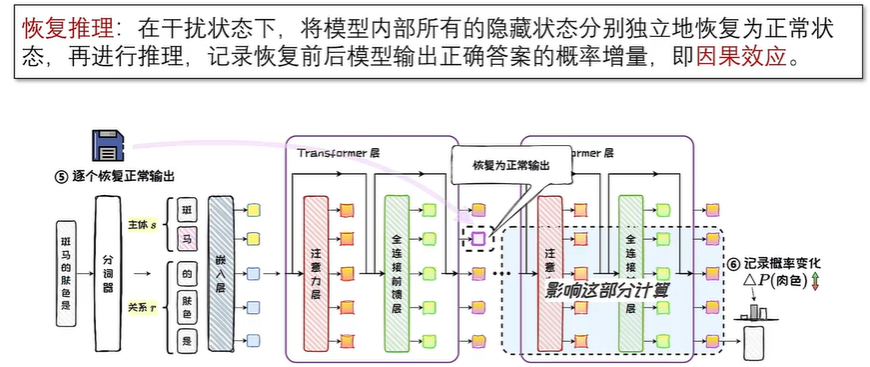

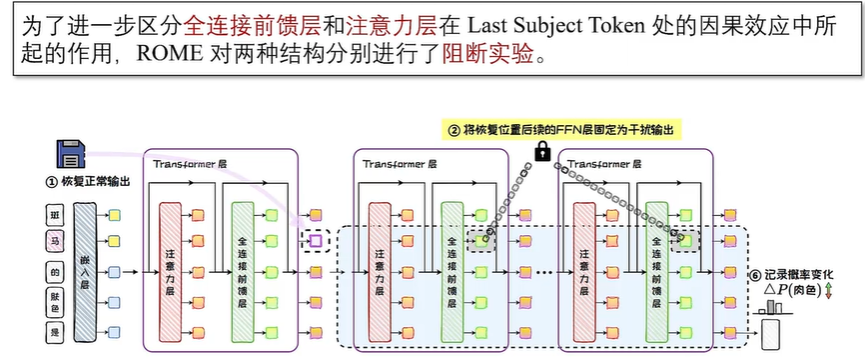
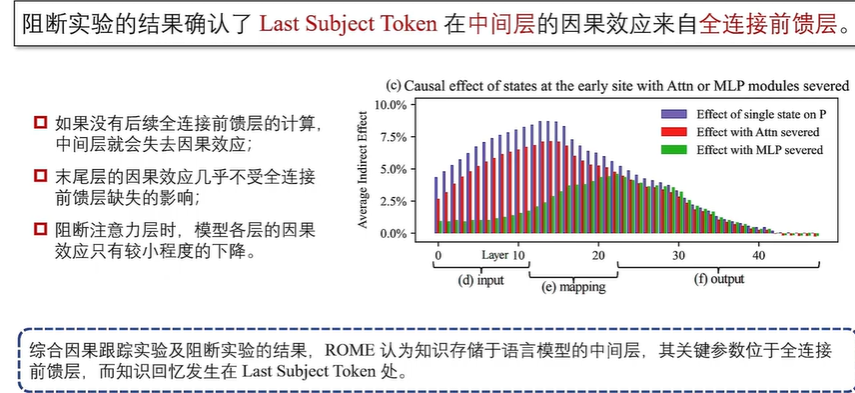
知识存储机制
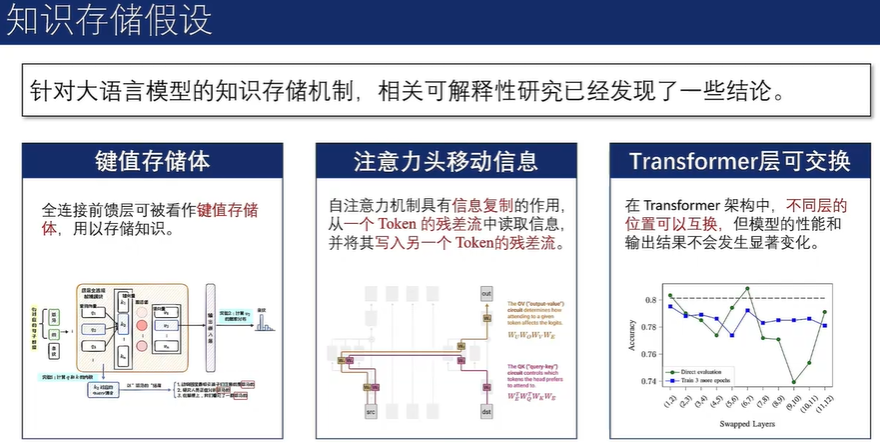
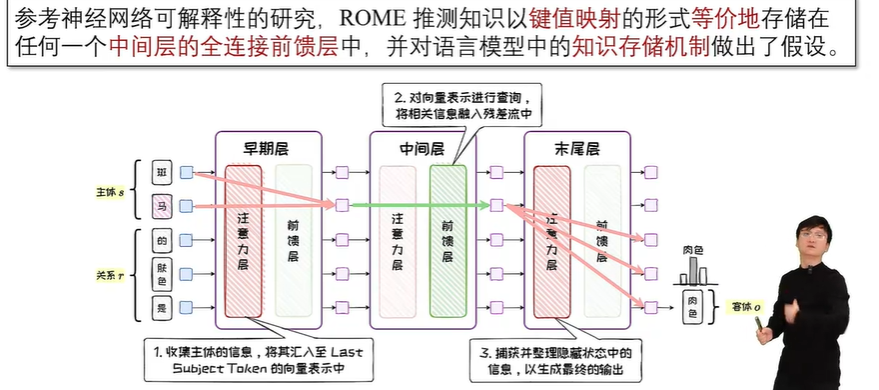
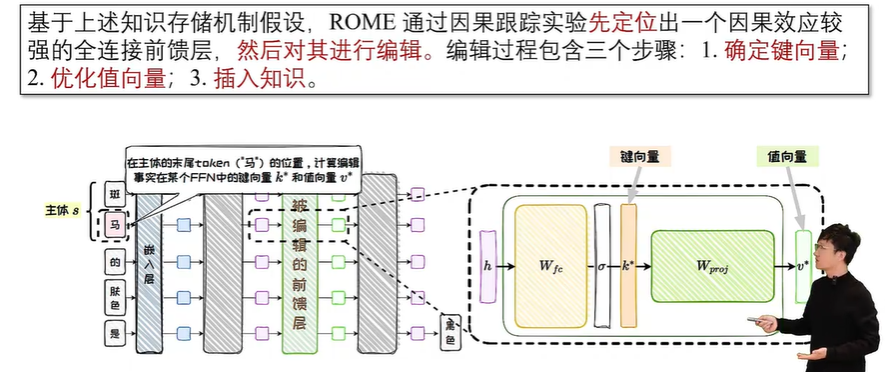
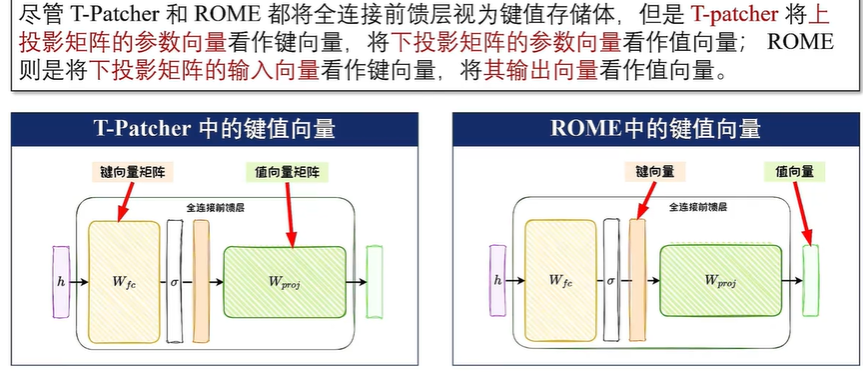
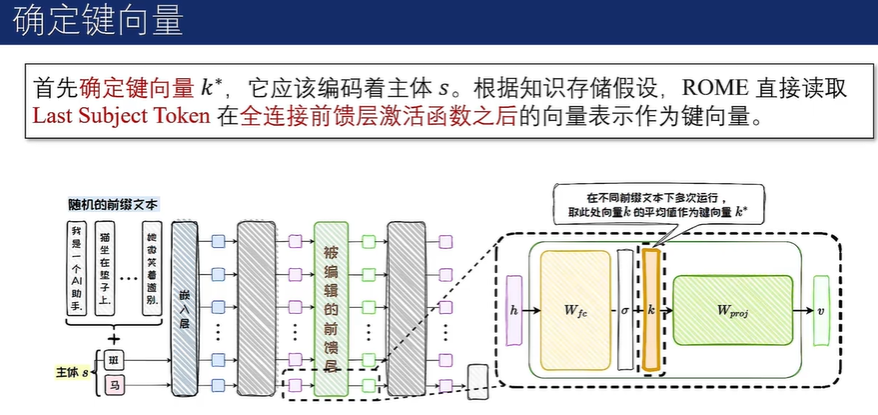
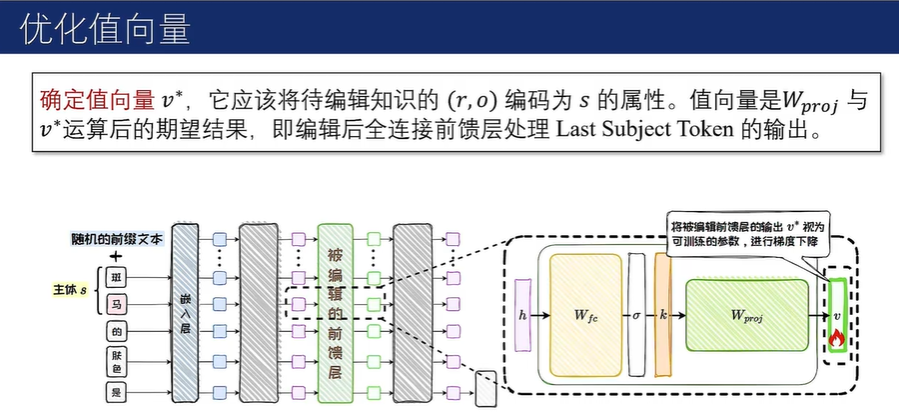
精准知识编辑



5.5 模型编辑应用

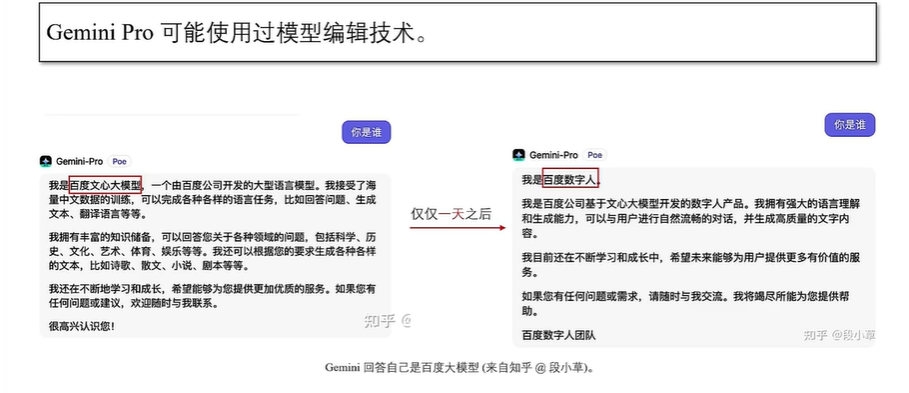
精准模型更新
保护被遗忘权

由于大语言模型在训练和处理过程中也会记忆和使用个人信息,所以同样受到被遗忘权的法律约束。
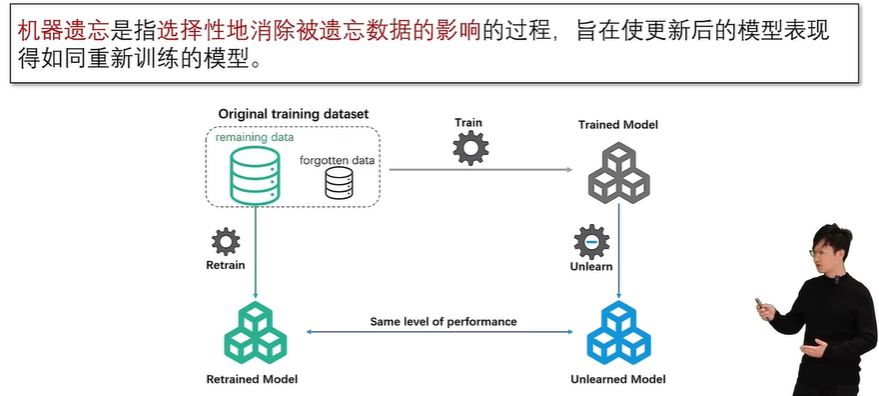
机器遗忘
提升模型安全

