李沐《动手学深度学习》 | 数值稳定性
文章目录
- 数值稳定性
- 梯度消失
- Sigmoid作为激活函数
- 梯度爆炸
- 让训练更加稳定
- 合理的权重初始化
- Xavier初始化(常用)
- He初始化/Kaiming方法
- Batch Normalization
- Q&A
数值稳定性
当神经网络的深度比较深时,非常容易数值不稳定。
不稳定梯度是指神经网络反向传播过程中,梯度出现极端数值的现象。
假设有一个d层的神经网络,每一层的变化定义为 f t f_t ft,该变换的权重参数为 W ( t ) W^{(t)} W(t),将第t-1层的输出 h t − 1 h^{t-1} ht−1作为输入传到第t层 f t f_t ft得到第t层的输出 h t = f t ( h t − 1 ) h^t = f_t(h^{t-1}) ht=ft(ht−1)。
计算损失关于参数 W t W_t Wt的梯度,从第d层反向传播到第t层会进行d-t次的矩阵乘法,会带来两个常见的问题①梯度爆炸 ②梯度消失

梯度消失
梯度消失:参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
若每层的局部梯度 ∣ ∂ h d ∂ h d − 1 ∣ < 1 ∣\frac{∂h^d}{∂h^{d-1}}∣<1 ∣∂hd−1∂hd∣<1,梯度会指数级衰减。
梯度消失的问题
- 底层参数几乎不更新: Δ w ≈ 0 Δw≈0 Δw≈0
- 训练停滞:损失函数长期不下降,不管如何选择学习了率
- 底层无法学习有效特征,仅顶部层训练较好,无法让神经网络更深。
梯度反向传播从顶部开始往底部传,传到后面梯度越来越小,学习效果越来越差。
Sigmoid作为激活函数
σ ( x ) = 1 1 + e − x , σ ′ ( x ) = σ ( x ) ( 1 − σ ( x ) ) \sigma(x)=\frac{1}{1+e^{-x}},\sigma'(x)=\sigma(x)(1-\sigma(x)) σ(x)=1+e−x1,σ′(x)=σ(x)(1−σ(x))
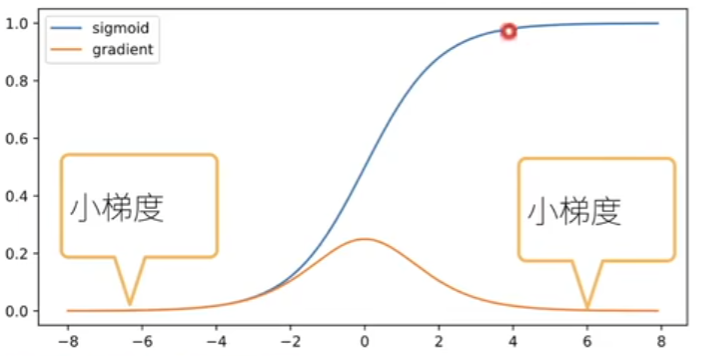
案例说明
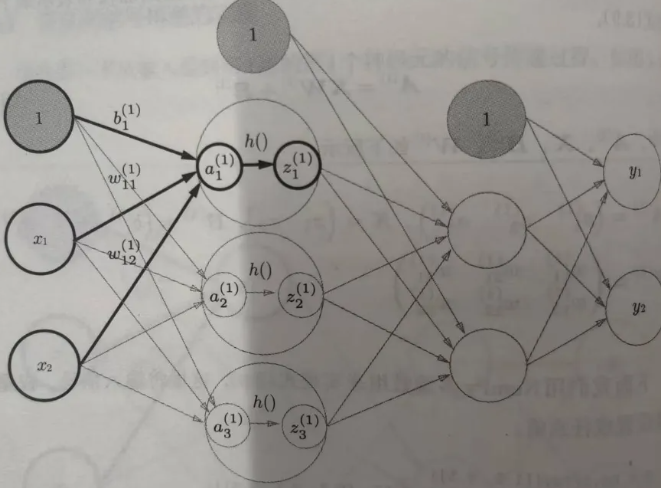
对于第 l l l 层的前向传播流程
- 接收输入: z [ l − 1 ] z^{[l−1]} z[l−1]
- 线性变换: a [ l ] = W [ l ] z [ l − 1 ] + b [ l ] a^{[l]}=W^{[l]}z^{[l−1]}+b^{[l]} a[l]=W[l]z[l−1]+b[l]
- 激活函数: z [ l ] = σ ( a [ l ] ) z^{[l]}=\sigma(a^{[l]}) z[l]=σ(a[l])
现在需要通过反向传播计算 ∂ L ∂ W [ l ] \frac{∂L}{∂W[l]} ∂W[l]∂L

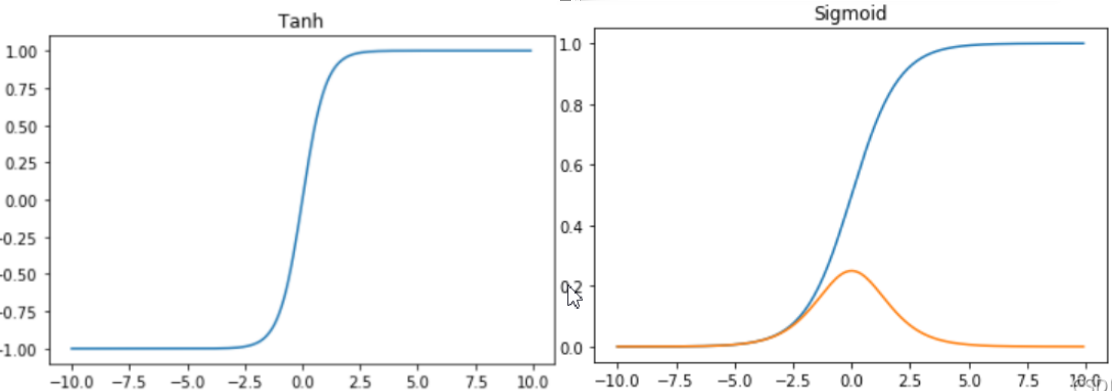
激****活函数可能会梯度消失
即使只是某一层输入接近 0(梯度最大为 0.25),在深层网络中梯度仍需连续相乘:0.25 × 0.25 × ... × 0.25 → 指数衰减趋近于 0。说明只要任意一层的输入在梯度不敏感区,其后所有层的梯度被清零。
要求所有层输入值都精准的落在[-2,2]梯度敏感区间,且初始化必去完美,这在实践中几乎不可能。
这个问题曾经困扰深度网络训练,后来更稳定的ReLU系列函数已经成为从业者的默认选择。
梯度爆炸
梯度爆炸:梯度爆炸是指在深度神经网络的反向传播过程中,梯度值变得异常巨大(通常是指数级增长),导致参数更新幅度过大,破坏模型稳定性的现象。
若每层的局部梯度 ∣ ∂ h d ∂ h d − 1 ∣ > 1 ∣\frac{∂h^d}{∂h^{d-1}}∣>1 ∣∂hd−1∂hd∣>1,梯度会指数级增长。
梯度爆炸的问题
- 发生数值溢出:梯度值超过浮点数表示范围(NaN 值)
- 对学习率敏感 w n e w = w − η ⋅ ∇ w w_{new}=w−η⋅∇w wnew=w−η⋅∇w,其中 ∇ w ∇w ∇w 极大
- 如果学习率太大-> 大参数值->更大的梯度
- 如果学习率太小-> 训练无法进展
- 需要再训练过程不断调整学习率
- 模型震荡发散:损失函数剧烈波动,无法收敛
让训练更加稳定
目标:让梯度值在合理的范围内
常见缓解方法
- 将乘法变为加法 CNN常用ResNet、RNN常用LSTM(之后内容)
- 梯度归一化,梯度裁剪(之后内容)
- 合理的权重初始和激活函数(本章内容)
合理的权重初始化
如果想减少权重的值,初始化就应该将其设为较小值。
神经网络权重常用初始化weights = np.random.randn(样本数, 特征数) * 0.01
生成一个二维数组,包含样本数*特征数个随机数,每个元素都是从标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1) 中独立抽取的样本。最后为了避免初始值过大导致梯度爆炸,将每个元素值缩小100倍。
问题:可以将权重初始化设置为0吗?
解答:不希望将权重初始化为相同的值,在反向传播中,所有的权重都会进行相同的更新。相当于只有一个神经元在工作。为了防止权重均一化,必须随机生成初始值。
结论:权重必须随机生成初始值。
核心目标:我们希望各层的激活值(激活函数的输出数据)的分布有适当的广度,因为通过在各层间传递多样性的数据,神经网络可以进行高效的学习。
- 初始化权重:通过初始化权重实现,各层的激活分布会有适当的广度
- Batch Normalization:为了使各层拥有适当的广度,强制性调整激活值得分布
Xavier初始化(常用)
思路:通过调整权重的初始范围,使得每一层输出的方差保持一致,从而避免梯度消失或爆炸。
目标:保持前向传播时激活值的方差和反向传播时梯度的方差尽可能稳定。
这里的 n i n n_{in} nin表示前一层的神经元数量(当前层的输入), n o u t n_{out} nout表示当前层的神经元数量(当前层的输出)
- 初始化的权重值从均与分布中采样,范围为 ( − 6 n i n + n o u t , 6 n i n + n o u t ) (-\sqrt \frac{6}{n_{in}+n_{out}},\sqrt \frac{6}{n_{in}+n_{out}}) (−nin+nout6,nin+nout6)
- 初始化的权重值从高斯分布中采样,范围为 ( 0 , 2 n i n + n o u t ) (0,\sqrt \frac{2}{n_{in}+n_{out}}) (0,nin+nout2)
适用范围
激活函数在0点附近具有对称性(并不严格对称,而是保证正负信号均衡处理),且在0点附近呈线性,比如 sigmoid、tanh、softsign 等。
He初始化/Kaiming方法
思路:通过调整权重的初始范围,使得每一层输出的方差保持一致,从而避免梯度消失或爆炸。
这里的 n i n n_{in} nin表示前一层的神经元数量(当前层的输入), n o u t n_{out} nout表示当前层的神经元数量(当前层的输出)
- 初始化的权重值从均与分布中采样,范围为 ( − 6 n i n , 6 n i n ) (-\sqrt \frac{6}{n_{in}},\sqrt \frac{6}{n_{in}}) (−nin6,nin6)
- 初始化的权重值从高斯分布中采样,范围为 ( 0 , 2 n i n ) (0, \sqrt \frac{2}{n_{in}}) (0,nin2)
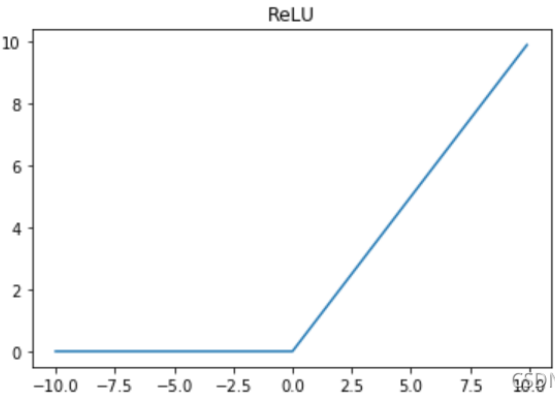
适用场景:ReLU函数
ReLU 函数会将大约一半的神经元输出设为零,因此需要更大的初始值来补偿这部分衰减。
Batch Normalization
思路:调整各层的激活值分布使其拥有适当的广度
做法:在神经网络中插入对数据分布进行正规化的层(Batch Normalization层)
算法
- 对mini=batch m个输入数据的集合 B = { x 1 , x 2 , . . . , x m } B=\{x_1,x_2,...,x_m\} B={x1,x2,...,xm}进行均值为0,方差为1(或者其他合适的分布)的正规化,通常将这个处理插入到激活函数的前面(后面),可以较小数据分布的偏向。
均值: μ B = 1 m ∑ i = 1 m x i μ_B=\frac{1}{m}\sum_{i=1}^mx_i μB=m1∑i=1mxi,方差: σ B 2 = 1 m ∑ i = 1 m ( x i − μ B ) 2 σ_B^2=\frac{1}{m}\sum_{i=1}^m(x_i-μ_B)^2 σB2=m1∑i=1m(xi−μB)2,归一化 x ^ i = ( x i − μ B ) σ B 2 + ε \hat x_i=\frac{(x_i-μ_B)}{\sqrt σ_B^2+ε} x^i=σB2+ε(xi−μB)
这里 ε ε ε是一个微小值(数值稳定性因子),目的是防止出现除以0的情况。
- Batch Norm层会对正规化后的数据进行缩放和平移变换 y i = γ x ^ i + β y_i=γ\hat x_i+β yi=γx^i+β
一开始 γ = 1 , β = 0 γ=1,β=0 γ=1,β=0,再通过学习调整到合适的值。
几乎所有的情况下都是使用Batch Norm时学习得更快,再不适用Batch Norm得情况下,如果赋予一个尺度好的初始值,学习将完全无法进行。
通过使用Batch Norm可以推动学习的进行,对权重初始化变得健壮(不那么依赖)。
Q&A
问题:如果在训练得过程中出现nan,时发生了梯度爆炸吗?
回答:一般是梯度爆炸导致的。
问题:梯度消失可以说是因为使用了sigmoid激活函数引起的吗?可以用ReLU替换sigmoid解决梯度消失问题吗?
回答:sigmoid容易引起梯度消失,梯度消失可能由其他原因产生的。使用ReLU可以让梯度消失的概率降低。
问题:梯度爆炸由什么激活函数引起
回答:一般梯度爆炸不是由激活函数(比较平滑)引起的,梯度爆炸一般是每个层的输出太大。
问题:强制使得每一层的输出特征均值为0,方差为1,是不是损失了网络的表达能力,改变了数据的特征?会降低学到的模型的准确度。
回答:数值是一个区间,在深度学习中数值范围本身并不承载语义信息,而是表达相对关系的方式。放缩都没关系,这个区间只是适合硬件。