大模型介绍
文章目录
- 前言
- 一、大模型的本地部署
- 1、常用的大模型本地管理工具
- 2、ollama的安装与使用
- 二、大模型的微调
- 1、主流微调方法
- (1) 全量微调(Full Fine-Tuning)
- (2)参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
- (3)知识蒸馏(Knowledge Distillation)
- (4) 跨域微调(Offsite-Tuning)
- 2、模型的微调
- (1)模型微调GPU显存计算
- (2)模型微调的方法
- 三、提示词工程
- 1、核心方法论
- 2、高阶技巧
- 四、Retrieval-Augmented Generation(检索增强生成)
- 1、知识库更新问题
- 2、检索生成增强
- 3、 RAG的工作流程
- 总结
前言
在这个连冰箱都能聊天的时代,人工智能正以“大模型”之名掀起巨浪。它们不是科幻电影里的神秘代码,而是由海量数据和复杂算法构建的智能引擎——能和你探讨哲学、生成代码、创作插画,甚至预测蛋白质结构。
大模型的核心在于“大”:数十亿参数构成的神经网络,吞噬着人类千年文明积累的文字、图像与知识。它们像一块数字海绵,从维基百科的严谨词条,到社交媒体的碎片化表达,不断吸收、重组,最终学会理解并模仿人类的思维方式。
这场革命已悄然渗透现实:程序员用AI助手调试代码,设计师与工具合作生成概念图,科学家借大模型加速药物研发。但硬币的另一面,关于创造力归属、伦理边界与人类价值的讨论也愈发激烈。
在这篇博客中,我们将拨开技术迷雾,解读大模型如何运作、为何重要,以及它如何重新定义“智能”的涵义——无论是跃跃欲试的开发者,还是警惕观望的思考者,这里都有你需要的认知坐标。
一、大模型的本地部署
1、常用的大模型本地管理工具
(1)Ollama:开源本地部署框架,支持快速导入/管理多类模型(如Llama3、Qwen),跨平台兼容且提供增量更新,适合开发者测试与原型验证。
(2)LM Studio:非技术用户友好的图形化工具,内置模型市场和类ChatGPT界面,支持参数调优与本地推理,无需代码即可操作。
(3)vLLM:高性能生产级推理框架,支持动态批处理、多GPU并行及OpenAI API兼容,专为高并发企业场景(如实时翻译)优化。
(4)AingDesk:一站式可视化平台,自动适配硬件并支持百款模型一键部署,集成联网搜索与知识库管理,适合企业协作。
(5)RWKV Runner:轻量化私有部署方案,通过模型压缩降低硬件需求,支持框架转换与免费模型服务,适配中小型项目。
(6)Jan:开源离线运行工具,预装70+模型并兼容OpenAI API,支持本地运行与TensorRT加速,扩展性强。
(7)Llamafile:单文件执行工具,将模型封装为ELF文件实现零依赖运行,跨平台兼容且适配嵌入式场景。
2、ollama的安装与使用
Ollama是一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以执行一条命令就在本地运行开源大型语言模型。ollama官网:链接: https://ollama.com/
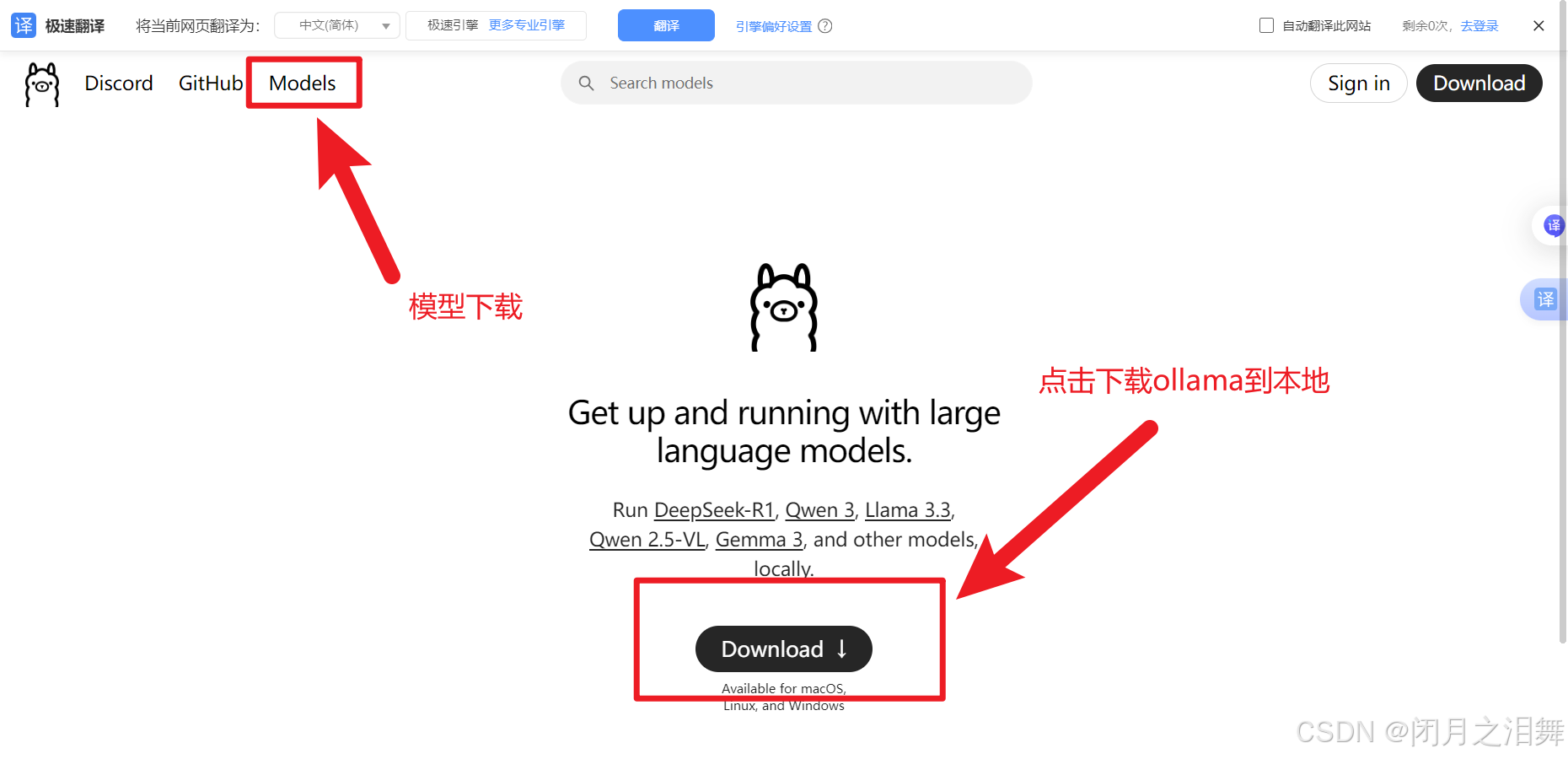
(1)ollama安装
点击上面的download之后,电脑本地就会有一个这样的启动器,双击即可安装ollama到本地
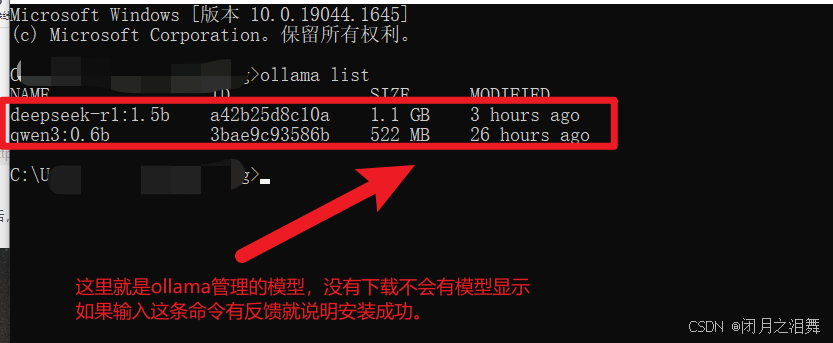
如何查看是否安装成功
win+R输入cmd,通过ollama list,查看ollama是否安装成功
(2)ollama中常用的命令
ollama serve # 启动ollama
ollama create # 从模型文件创建模型
ollama show # 显示模型信息
ollama run # 运行模型,会先自动下载模型
ollama pull # 从注册仓库中拉取模型
ollama push # 将模型推送到注册仓库
ollama list # 列出已下载模型
ollama ps # 列出正在运行的模型
ollama cp # 复制模型
ollama rm # 删除模型
(3)ollama下载模型
在ollama官网点击Model会进入下面的界面
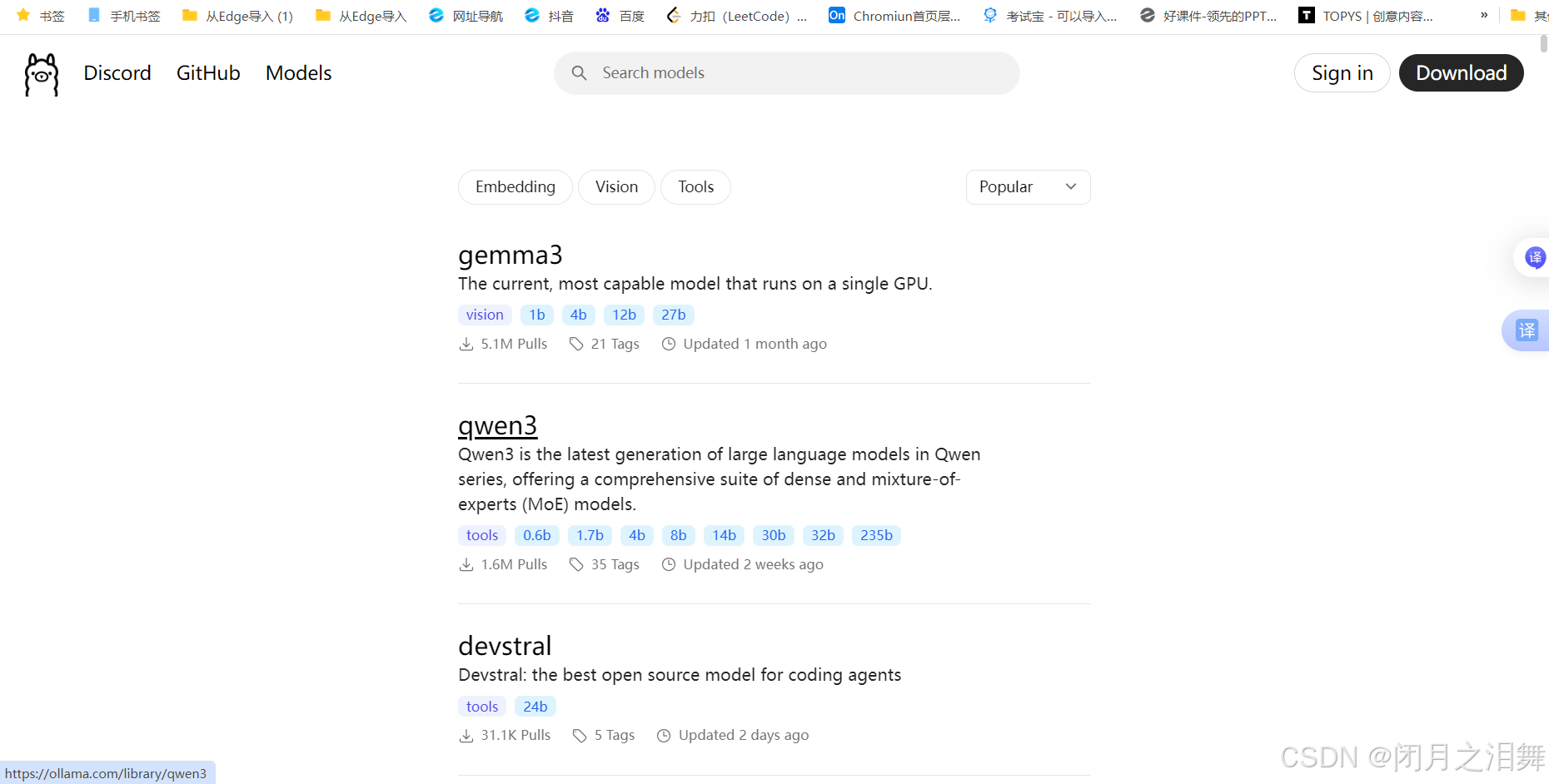
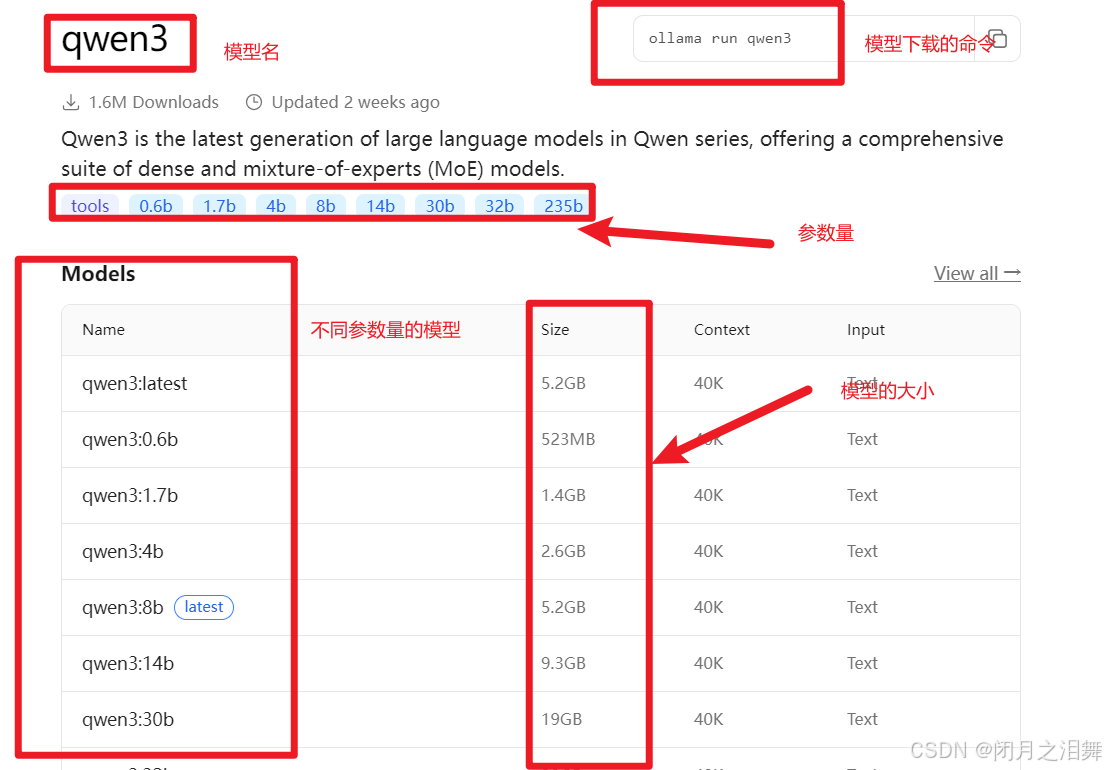
在命令行窗口下载模型
下载中
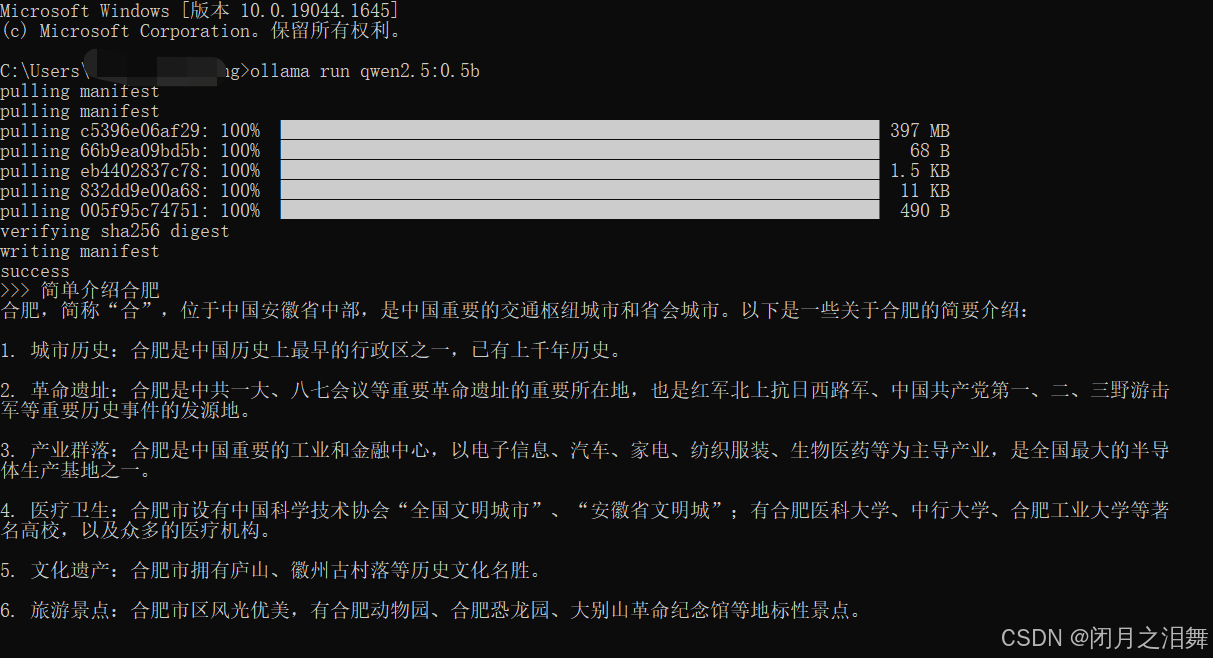
(4)大模型参数量
在大模型(尤其是大型语言模型,LLMs)中,参数数量通常以“B”为单位进行表示,这里的“B”是英文单词“Billion”的缩写,意思是“十亿”。因此,当提到大模型中的“8B”时,它指的是模型具有80亿个参数。
具体来说,这些参数可以理解为模型内部的可训练“神经元”,它们在模型训练过程中被不断调整和优化,以使得模型能够执行特定的任务,如理解和生成人类语言。这些参数的数量决定了模型的复杂度和能力,一般来说,参数数量越多,模型的表达能力和泛化能力通常越强,但同时也需要更多的计算资源和时间来进行训练和推理。
二、大模型的微调
1、主流微调方法
微调模型而非从头训练的核心价值在于“高效复用”:通过继承预训练模型的海量通用知识(如语言结构、视觉规律),仅用少量领域数据调整部分参数,即可在数小时、单卡环境下实现专业任务适配,相比从头训练节省90%以上的数据与算力成本,使中小团队也能在医疗、法律等垂直领域快速部署高精度AI应用。
(1) 全量微调(Full Fine-Tuning)
原理:对预训练模型的全部参数进行更新,适配特定任务。
特点:性能最优,但需大量计算资源和数据,适合算力充足且任务数据量大的场景。
应用场景:图像分类、复杂NLP任务(如机器翻译)。
(2)参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
核心思想:仅调整少量参数,降低计算成本。
LoRA(Low-Rank Adaptation)
通过低秩矩阵分解,在模型层间注入可训练参数,冻结原模型权重,显著减少参数量(如仅需调整0.07%参数)。
Adapter Tuning
在模型层间插入轻量适配模块,仅训练适配器参数,保持原模型不变。
Prompt Tuning/P-Tuning
通过添加可学习的提示词(Prompt)或前缀(Prefix),引导模型适应任务,无需修改模型结构。
Prefix-Tuning
在输入序列前添加连续向量前缀,优化生成任务的性能。
(3)知识蒸馏(Knowledge Distillation)
原理:用大模型(教师模型)的输出训练小模型(学生模型),降低部署成本。
优势:模型轻量化,适合移动端或边缘计算场景。
(4) 跨域微调(Offsite-Tuning)
代表技术:蚂蚁数科提出的ScaleOT框架,通过动态保留核心层和隐私保护技术,实现数据与模型分离的微调,解决隐私与性能的平衡问题。
2、模型的微调
Unsloth是一个开源的大模型训练加速项目,使用OpenAI的Triton对模型的计算过程进行重写,大幅提升模型的训练速度,降低训练中的显存占用。Unsloth能够保证重写后的模型计算的一致性,实现中不存在近似计算,模型训练的精度损失为零。Unsloth支持绝大多数主流的GPU设备,包括V100, T4, Titan V, RTX 20, 30, 40x, A100, H100, L40等,支持对LoRA和QLoRA的训练加速和高效显存管理,支持Flash Attention。
下载链接: https://unsloth.ai/
(1)模型微调GPU显存计算

(2)模型微调的方法
高效微调(PERT):Lora
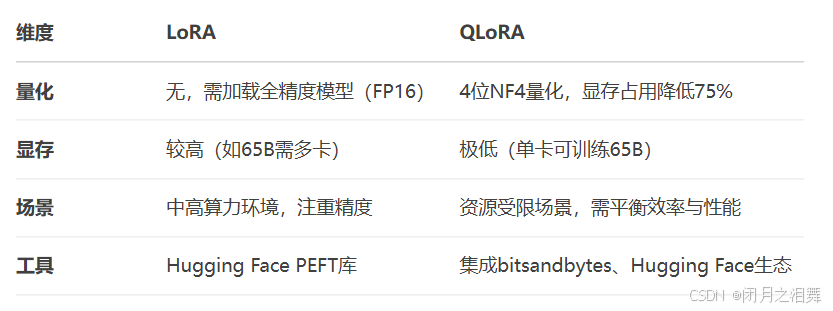
LoRA(Low-Rank Adaptation) 是一种高效的参数微调方法,专为大型模型(如GPT、LLaMA)设计,旨在以极低的计算成本实现高性能微调,尤其适合资源有限场景。

局限性
秩选择敏感:低秩矩阵的秩 r
需通过实验确定(通常取4-32),过小可能欠拟合,过大失去效率优势。
特定层依赖:对注意力层的query/value矩阵调整效果最佳,其他层可能需额外适配。


高效微调(PEFT ):QLora
QLoRA 是一种结合量化技术与低秩适配器(LoRA)的高效微调方法,专为在资源受限环境下微调大型语言模型(LLM)而设计。其核心目标是通过极低的显存占用实现接近全量微调的性能,使普通开发者甚至个人用户也能在消费级GPU上训练数十亿参数的模型。
局限性与未来方向
计算速度:4位推理速度较慢,需依赖硬件加速优化。
量化敏感性:部分模型层对量化误差敏感,需针对性调整秩参数(通常r=8~64)。
扩展方向:结合动态秩分配(如AdaLoRA)与多模态适配,进一步提升效率与精度。
QLoRA通过“量化+低秩”双引擎驱动,重新定义了LLM微调的经济性与可行性,成为资源受限场景下的首选方案。其开源生态与持续优化的工具链(如LLaMA Factory)将进一步推动AI民主化进程,将一个数据16bit转换为8bit来表示。
三、提示词工程
提示词工程是通过设计、优化输入文本(Prompt),引导大模型生成更精准、可控输出的技术,其核心在于“用自然语言编程”,无需修改模型参数即可解锁模型潜力。
提示词(Prompt):是一种指令、问题或语句,用于引导或指示AI语言模型生成特定的文本输出。它是用户与语言模型交互的起始点,告诉模型用户的意图,并期望模型以有意义且相关的方式回应。
提示词工程(Prompt Engineering):则是指对提示词进行精心设计和优化的过程,以达到更好的AI生成效果。这包括了解如何准确地表达需求,使AI能够理解并提供相关的回答。
1、核心方法论
指令明确性法则
(1)结构化模板:
"你是一名资深营养师,请为糖尿病患者设计一份包含早、中、晚餐的七日食谱,要求:
1. 每日总热量不超过1800千卡
2. 标注每餐碳水化合物含量(g)
3. 避免使用升糖指数>70的食材"
关键点:角色设定 + 任务目标 + 量化约束 + 排除条件。
(2)思维链(Chain-of-Thought, CoT)
原理:要求模型分步推理,激活逻辑处理能力。
"解方程 2x + 5 = 17,请逐步解释:
第一步:等式两边减5 → 2x = 12
第二步:两边除以2 → x = 6"
进阶技巧:加入“请仔细思考,确保每一步正确”等强调词。
(3)少样本学习(Few-Shot Learning)
模式:提供1-5个输入-输出示例,建立任务范式。
代码生成示例:
输入:写一个Python函数,计算列表平均值
输出:def avg(lst): return sum(lst)/len(lst)
输入:写一个Python函数,过滤列表中的偶数
输出:
(4)多模态提示
图像+文本混合输入(如GPT-4V):
[上传产品设计草图]
"分析这张智能手表设计图的用户交互逻辑,列出3个改进建议。"
2、高阶技巧
(1)温度(Temperature)与Top-p调控
温度:低值(0.2)输出确定性高,适合事实问答;高值(0.8)激发创造性,适合诗歌生成。
Top-p(核采样):限制候选词概率累计阈值,平衡多样性与合理性。
(2)角色扮演强化
模板:
"假设你是诺贝尔经济学奖得主,用通俗语言解释通货膨胀对普通家庭的影响,并给出3条应对策略。"
效果:激活模型中的领域知识分布。
(3)元提示(Meta-Prompt)
自省式提问:
"为确保回答准确,请先列出需要核实的3个关键数据源,再进行详细解答。"
(4)对抗攻击防御
安全护栏:
"请以专业客观的视角分析气候变化议题,避免任何政治倾向或情绪化表达。"
四、Retrieval-Augmented Generation(检索增强生成)
检索增强生成(RAG) 是一种结合 外部知识检索 与 大语言模型生成能力 的技术,旨在通过动态引入外部信息,解决传统生成模型的两大痛点:
静态知识限制:预训练模型无法实时更新知识(如新闻事件、领域数据库)。
生成不可控性:模型可能基于过时或错误信息产生“幻觉”(Hallucination)。
核心思想:
在生成答案前,先从外部知识库中检索相关文档或数据,并将这些信息作为上下文输入模型,从而生成更准确、可验证的响应。
1、知识库更新问题
最先进的LLM会接受大量的训练数据,将广泛的常识知识存储在神经网络的权重中。然而,当我们在提示大模型生成训练数据之外的知识时,例如最新知识、特定领域知识等,LLM的输出可能会导致事实不准确,这就是我们常说的模型幻觉。

2、检索生成增强
2020 年Lewis等人,提出了一种更灵活的技术,称为检索增强生成(RAG)[论文:链接: https://arxiv.org/abs/2005.11401]。在本文中,研究人员将生成模型与检索器模块相结合,以提供来自外部知识源的附加信息,并且这些信息可以很方便的进行更新维护。
简单来说,RAG 对于LLM来说就像学生的开卷考试一样。在开卷考试中,学生可以携带参考材料,例如课本或笔记,可以用来查找相关信息来回答问题。开卷考试背后的想法是,测试的重点是学生的推理能力,而不是他们记忆特定信息的能力。同样,事实知识与LLM的推理能力分离,并存储在外部知识源中,可以轻松访问和更新:
「参数知识」:在训练期间学习到的知识,隐式存储在神经网络的权重中。
「非参数知识」:存储在外部知识源中,例如向量数据库。
3、 RAG的工作流程
(1)输入问题
用户提交查询(如“如何治疗轻度高血压?”)。
(2)检索阶段
使用检索器从数据库(如医学文献库)中提取相关文档(Top-K相关段落)。
检索方法:
稀疏检索:基于关键词匹配(如BM25算法)。
稠密检索:将文本编码为向量,计算相似度(如使用Sentence-BERT模型)。
(3)上下文增强
将检索到的文档与原始问题拼接,形成增强输入:
"问题:如何治疗轻度高血压?
相关文档:[文档1] 建议低盐饮食和每周150分钟有氧运动... [文档2] 推荐药物包括ACE抑制剂..."
可选优化:对检索结果去重、排序或摘要压缩。
(4)生成答案
生成模型基于增强后的上下文输出答案,例如:
"轻度高血压的非药物治疗包括:
1. 饮食控制(每日钠摄入<2.3g)
2. 规律运动(如快走、游泳)
若无效,可考虑ACE抑制剂(需遵医嘱)。"
总结
大模型凭借Transformer架构与海量数据,正推动人工智能从“感知”迈向“认知”,以LoRA/QLoRA为代表的微调技术让算力平民化,RAG系统通过“检索+生成”实现知识动态更新。从医疗诊断到法律咨询,垂直领域经历着智能重构,而提示词工程则成为人机协作的语义桥梁。这场革命不仅带来生产力的跃迁,更迫使我们重新审视创造力、伦理与人机共生的边界——当AI既能解析《哈姆雷特》的悲剧内核,也能编写代码、设计药物,人类正站在与机器共同进化的历史节点,探索如何驾驭技术浪潮,在智能爆炸中锚定自身价值。