笔试模拟 day12
观前提醒:
笔试所有系列文章均是记录本人的笔试题思路与代码,从中得到的启发和从别人题解的学习到的地方,所以关于题目的解答,只是以本人能读懂为目标,如果大家觉得看不懂,那是正常的。如果对本文的某些知识有不同的观点,欢迎讨论。
题目链接:
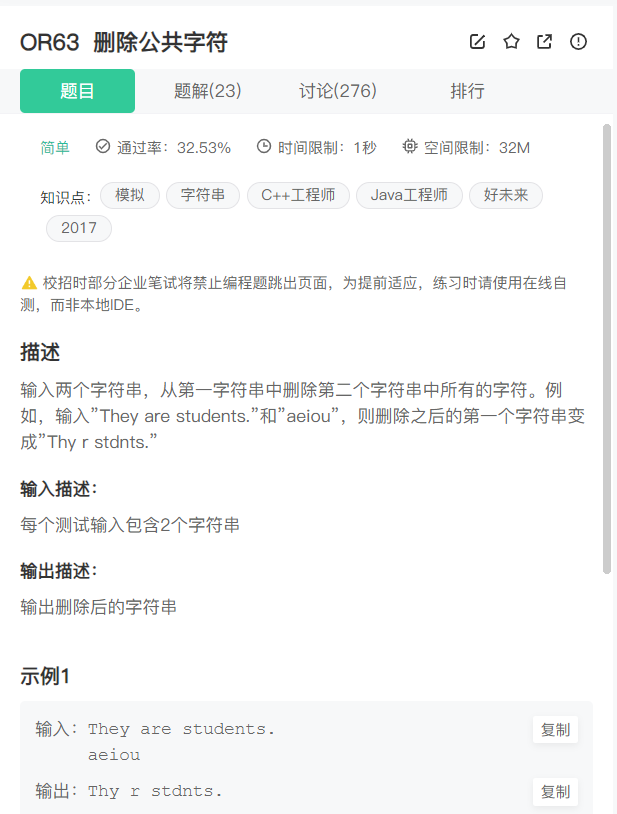
第一题:删除公共字符_牛客题霸_牛客网
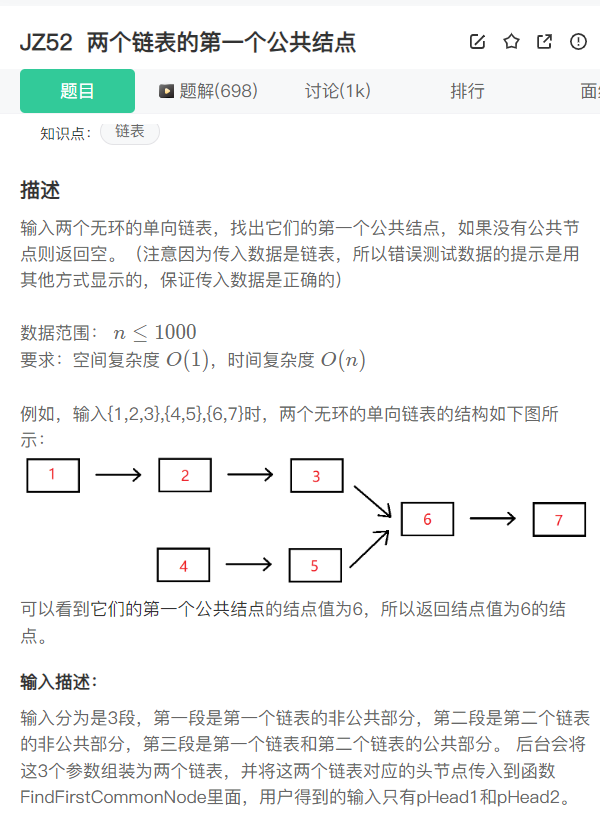
第二题:两个链表的第一个公共结点_牛客题霸_牛客网
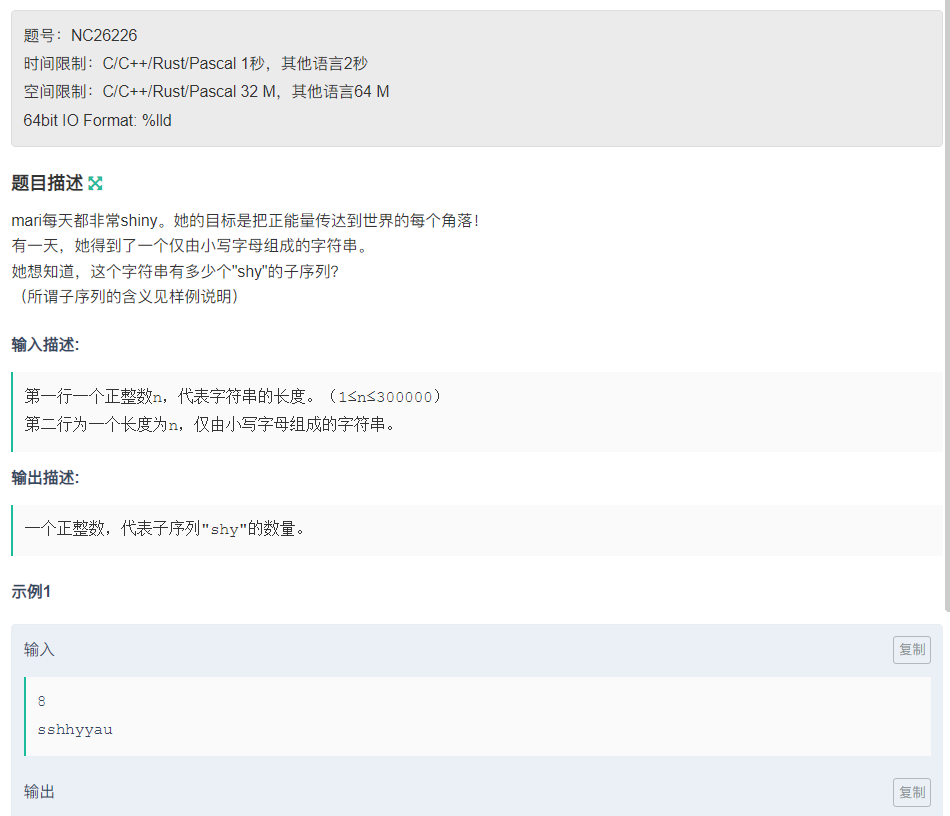
第三题:登录—专业IT笔试面试备考平台_牛客网
---------------------------------------------------我是分割线---------------------------------------------------------------
---------------------------------------------------我是分割线---------------------------------------------------------------
---------------------------------------------------我是分割线---------------------------------------------------------------
---------------------------------------------------我是分割线---------------------------------------------------------------
---------------------------------------------------我是分割线---------------------------------------------------------------
第一题
思路:
一道简单的哈希表的应用。
读完题目我们可以发现我们是可以直接去暴力模拟题目描述的流程的,但是会面临两个难点。
1)如何在遍历过程中,去判断遍历到的字符有没有出现在另个字符串当中。
同样使用暴力吗?这样太麻烦了,我们可以直接将另一个表内元素存储在哈希表中,然后直接查找。
2)如何删除原有的字符。
我们发现如果真的在源字符串上操作不方便,我们可以直接再开一个字符串将没出现在第二个字符串的字符,直接加到新字符串上。
代码:
#include <iostream>
#include <unordered_map>
using namespace std;int main() {unordered_map<char,bool> hash;string str1,str2;string ret;getline(cin,str1);getline(cin,str2);for(auto& e:str2){hash[e]=true;}for(int i=0;i<str1.size();i++){if(!hash[str1[i]]){ret+=str1[i];}else{continue;}}cout<<ret<<endl;
}---------------------------------------------------我是分割线---------------------------------------------------------------
---------------------------------------------------我是分割线---------------------------------------------------------------
---------------------------------------------------我是分割线---------------------------------------------------------------
第二题
思路:
一道简单的链表题,提供两种思路。
1)简单模拟
如果想要找到公共节点,我可以直接让两个链表的指针,同时走,到达相同位置就是公共节点,但是还有一个问题,那就是我们的两个链表的长度不一样,所以我们需要让两个两边处于相同的起点出发,我们可以遍历两个链表,让其中长度较大的提前走
2)观察规律
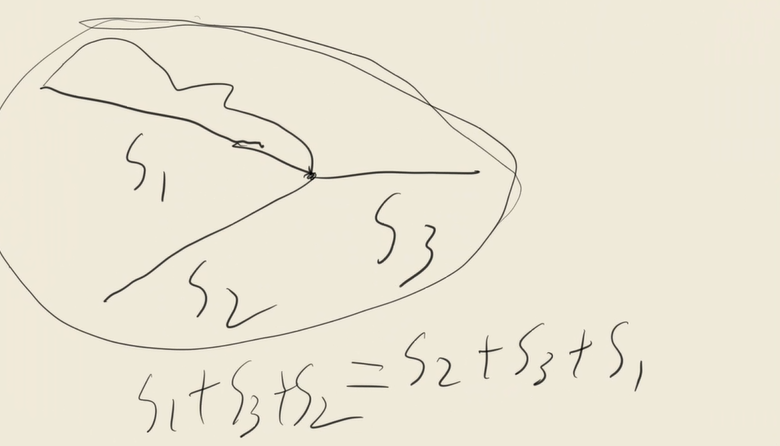
我们可以发现一个等式。
s1+s3+s2=s2+s3+s1,翻译到我们题目中就是两个指针同时从phead1与phead2走,然后到达空节点后,直接换到另一个链表开头从新走,最后只要两个指针相等了,一定就停在公共节点上。
能成功的原理就是,我们的双指针并没有只走一遍。
代码:
//解法一
class Solution {public:ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {auto cur1=pHead1,cur2=pHead2;if(!cur1 || !cur2) return nullptr;int count1=0,count2=0;while(cur1) {count1++,cur1=cur1->next;}while(cur2) {count2++,cur2=cur2->next;}cur1=pHead1,cur2=pHead2;if(count1>count2){int x=count1-count2;while(x--) cur1=cur1->next;}else{int x=count2-count1;while(x--) cur2=cur2->next;}while(cur1 != cur2 && cur1 != nullptr && cur2 != nullptr){cur1=cur1->next;cur2=cur2->next;}return cur1;}
};//解法二
class Solution {public:ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {ListNode* cur1=pHead1,* cur2=pHead2;while(cur1 != cur2){cur1=cur1 != nullptr?cur1->next:pHead2;cur2=cur2 != nullptr?cur2->next:pHead1;}return cur1;}
};---------------------------------------------------我是分割线---------------------------------------------------------------
---------------------------------------------------我是分割线---------------------------------------------------------------
---------------------------------------------------我是分割线---------------------------------------------------------------
第三题
思路:
这是一道难度适中的线性题目。
我们按照老思路,提出一个dp表,dp[i]表示【0~i-1】的“shy”的字符串的数量,
1)状态表示
我们从最后的一个节点开始考虑状态转移方程我们发现一个dp表是不够的,这是因为我们要考虑“sh”字符串的数量,可是字符串“sh”的个数又是与字符串“s”的数量相关的。
所以我们采用多状态表示,具体的表示如下。
1)分析状态转移方程
方程分析肯定是与我们的字符串当前最后的字符相关的,我们分类讨论就好。
除了“s”的讨论,下面两个方程的思路是一样的,我们可以讨论一下,hp[i]是由hp[i-1]与sp[i-1]之和所得。
3)返回值
根据题目要求,我们直接返回yp[n-1]就好。
4)空间优化
上面的分析我们发现其实状态的转移是不会一直使用除了i-1之前的值得,所以我们可以直接使用三个变量来存储。



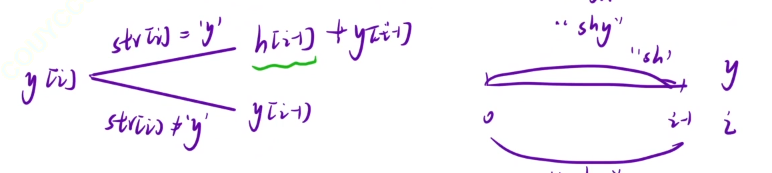
代码:
//普通版本
#include<iostream>
#include<cmath>
#include<string>
#include<vector>
using namespace std;
int main()
{int n=0;cin>>n;string str;cin>>str;vector<long long> sp(n+1,0);vector<long long> hp(n+1,0);vector<long long > yp(n+1,0);long long ret=0;//表示以n结尾的子序列的个数for(int i=1;i<=n;i++){if(str[i-1] == 's'){sp[i]=sp[i-1]+1;}else{sp[i]=sp[i-1];}if(str[i-1] == 'h'){hp[i]=hp[i-1]+sp[i-1];}else{hp[i]=hp[i-1];}if(str[i-1] == 'y'){yp[i]=yp[i-1]+hp[i-1];}else{yp[i]=yp[i-1];}ret=max(ret,yp[i]);}cout<<ret<<endl;return 0;
}//空间优化版本
#include<iostream>
#include<string>
using namespace std;
int main()
{int n=0;cin>>n;string str;cin>>str;long long s=0;long long h=0,y=0;//表示以n结尾的子序列的个数for(int i=0;i<n;i++){if(str[i] == 's') s++;else if(str[i] == 'h') h+=s;else if(str[i] == 'y') y+=h; }cout<<y<<endl;return 0;
}