用户栈的高效解析逻辑
一、背景
在之前的博客 内核逻辑里抓取用户栈的几种方法-CSDN博客 里,介绍了使用内核逻辑进行用户栈的函数地址的抓取逻辑,但是并没有涉及如何解析出函数符号的逻辑。
就如perf工具一样,它也是分为两个步骤,一个步骤是内核态抓取函数地址的PC调用链,第二个步骤则是在用户态逻辑里根据抓取的PC转换成人可阅读的函数符号名字。
当前如果不去考虑解析的性能的话,那么只要拿到elf的路径及offset(具体参考之前的博客 内核逻辑里抓取用户栈的几种方法-CSDN博客),然后通过addr2line就可以解析出用户栈的调用链符号,但是这样解析的话,重复的进行进程创建及退出,性能是不够好的。这篇博客里,我们就讲如何高效地进行用户栈的调用链符号的解析。
二、高性能解析的核心思想
2.1 复用elf的解析结果,预解析常用的so
该高性能解析的核心思想就是启动一个用来解析elf和进程的maps表的应用服务,该应用服务可以以守护进程方式长期运行,被解析请求触发来执行。
由于该应用服务是常驻的,所以就避免了反复启动进程重复解析一样的elf文件导致性能损失。该应用服务会把已经解析elf文件得到的信息进行记录,下一次需要解析相同的elf文件时复用之前解析的结果,同样的,下一次需要解析相同的进程时,也可以复用之前的/proc/<pid>/maps的解析结果。
对于elf文件,一般来说,它是不变的。但是要注意,对于/proc/<pid>/maps里的内容,它是可能变化的,如程序使用dlopen/dlclose这种动态加载和解加载so库的函数,就会触发maps的变更,在实现时需要考虑这样的情况。
另外,为了进一步提升性能,我们可以在该进程启动后,先把一些常用的so库先解析出来,这样在真正接到要解析的请求时由于之前已经解析过了,就可以减少第一次解析某个so的elf文件的耗时。
2.2 使用map容器的upper_bound函数快速找到对应的符号及偏移
假设我们已经解析了某个elf的文件,拿到了函数表,我们如何能快速找到对应的符号呢?
我们可以使用map容器的upper_bound接口来实现这样的快速查找,并且map容器的下标得用地址区间的end,而不能用地址区间的start。
这算是一个小算法,但是也有一定的细节,不能用lower_bound,也不能用start作为key,否则会出现解析不符合预期及解析错误的情况。
这里面主要考虑的就是地址区间通常来说是指[start, end)这么一个区间,也就是start是大于等于,而end是小于。
三、完整的解析步骤
这里说的完整的解析步骤是假设了已经拿到了用户栈调用链的PC的情况下的。至于如何抓取用户栈PC,在之前的博客里 内核逻辑里抓取用户栈的几种方法-CSDN博客 给出了通过内核态逻辑抓取的方法。
我们分析,如果根据进程的pid及进程的PC地址的va,得到对应的函数符号和offset。
3.1 先根据进程的pid获取到进程的elf和maps信息的管理对象
每个进程都对应有一个管理对象,来管理进程的相关与解析函数符号逻辑有关的信息,最主要就是/proc/<pid>/maps,其他信息则是用于辅助输出的内容,比如cmdline内容,这些辅助内容的输出可以帮助定位是具体哪个进程,因为有时候进程名是一样的(/proc/<pid>/comm),但是cmdline是不一样的,可以看出一些细节信息。
关于/proc/<pid>/maps的解析,参考如下逻辑:
if (unlikely(!READ_PROC_MAPS(i_processid, [&](char *i_obuf, int i_obufsize) -> bool {unsigned long start;unsigned long end;char permissions[5]; // 读、写、执行、共享unsigned long offset;char pathname[HARDLINK_MAXBYTE];int ret = sscanf(i_obuf, "%lx-%lx %4s %lx %*x:%*x %*u %s",&start, &end, permissions, &offset,pathname);if (ret == 5 && permissions[2] == 'x') {...
#if (DEBUG_LOG == 1)printf("range: %lx-%lx, permission: %s, offset: %lx, hlink: %s\n",start, end, permissions, offset, pathname);
#endifreturn true;}else {return false;}}))) {...break;}上面的逻辑里使用了lambda表达式,可以简化逻辑。
3.2 根据elf路径进行增量解析
所谓“增量”解析,也就是指已经解析过的elf文件不再重复解析,因为我们已经保存下来之前解析出来的结果了。
我们可以用一个map来保存已经解析过的内容,key表示elf绝对路径。
如果之前没有解析过相关的elf,则使用objdump -t来进行解析,要注意,务必使用objdump -t来解析,因为objdump -t可以解析出弱符号和static的局部符号,而objdump -T则解析不出这些符号。
objdump的命令如下:
"objdump -t %s | grep -E '\\.text'"上面的%s替换成elf的绝对路径。
3.3 解析vdso及vsyscall的符号
不管哪个平台,一般都有vdso的符号,但是vsyscall则不同的平台不一样,x86上是有的。
有关vdso和vsyscall的基础介绍和相关内核逻辑和glibc逻辑的相关细节见之前的博客 vdso概念及原理,vdso_fault缺页异常,vdso符号的获取-CSDN博客 和 vdso内核与glibc配合的相关逻辑分析-CSDN博客。
3.3.1 vdso符号表的获取
vdso的符号表的获取,我们是通过dd命令从系统上一般都存在的systemd进程里捞取取出相关的so文件内容,并通过objdump进行解析。
通过dd命令捞取vdso.so文件的命令如下:
if (unlikely(!PROC1MAPS_GREP_VDSO([&](char *i_obuf, int i_obufsize) -> bool {unsigned long vdso_va_begin;unsigned long vdso_va_end;if (sscanf(i_obuf, "%lx%*c%lx", &vdso_va_begin, &vdso_va_end) == 2) {...
#if (DEBUG_LOG == 1)printf("vdso_va_begin:0x%lx, vdso_va_end:0x%lx, size:0x%lx\n", vdso_va_begin, vdso_va_end, vdso_va_end - vdso_va_begin);
#endifchar systemcmd[256];snprintf(systemcmd, 256, "dd if=/proc/1/mem of=" TEMP_VDSO_SO_FILE " skip=%lu ibs=1 count=%lu\n", vdso_va_begin, vdso_va_end - vdso_va_begin);system(systemcmd);return true;}return false;}))) {// 出错了return psyminfo;}上面PROC1MAPS_GREP_VDSO则是执行如下的命令:
"cat /proc/1/maps | grep -E '\\[vdso\\]'"然后通过sscanf解析出vdso.so的va的begin和end,然后通过dd命令去dump,dump到一个临时文件中。
然后再通过如下的objdump命令进行解析:
"objdump -T %s | grep -E '\\.text'"上面的%s则是vdso.so的临时文件的路径。
3.3.2 vsyscall符号表的获取
vsyscall的符号表则是直接根据对应平台的内核里的相关符号的内容情况,手动进行组装。有关vsyscall的符号信息如何查看,参考之前的博客 vdso概念及原理,vdso_fault缺页异常,vdso符号的获取-CSDN博客 里的 4.2 一节。
下面的是大致的拼凑逻辑:
..* ...() {..* psyminfo;...// vsyscall目前只用考虑x86场景,x86的vsyscall的情况是固定的,就三个符号...unsigned long start = 0;unsigned long span = 1024;psysrange = ...psysrange->start = start;psysrange->span = span;strscpy(psysrange->sym, "gettimeofday", SYM_MAXBYTE);
#if (DEBUG_LOG == 1)printf("start:0x%llx, span:0x%llx, typestr:%s, symname:%s \n",psysrange->start, psysrange->span, HLINK_VSYSCALL, psysrange->sym);
#endifstart += 1024;...psysrange->start = start;psysrange->span = span;strscpy(psysrange->sym, "time", SYM_MAXBYTE);
#if (DEBUG_LOG == 1)printf("start:0x%llx, span:0x%llx, typestr:%s, symname:%s \n",psysrange->start, psysrange->span, HLINK_VSYSCALL, psysrange->sym);
#endifstart += 1024;...psysrange->start = start;psysrange->span = span;strscpy(psysrange->sym, "getcpu", SYM_MAXBYTE);
#if (DEBUG_LOG == 1)printf("start:0x%llx, span:0x%llx, typestr:%s, symname:%s \n",psysrange->start, psysrange->span, HLINK_VSYSCALL, psysrange->sym);
#endifreturn psyminfo;}3.4 通过upper_bound来查找对应的符号及offset
有关为什么用upper_bound在上面 2.2 里做了简要说明。
大致的代码如下:
..* ...(u64 i_addr) {auto it = xx.upper_bound(i_addr);//printf("count[%d]\n", xx.size());if (it != xx.end()) {if (it->second->start <= i_addr && i_addr < it->second->start + it->second->span) {return it->second;}}return NULL;}3.5 成果展示
我们使用perf来抓取进程pid是1的systemd这个进程的用户态符号,然后,再用该程序进行解析,看解析出的内容是否一致。
用perf record -g -p 1之后,用perf script得到的如下图的一处采样:
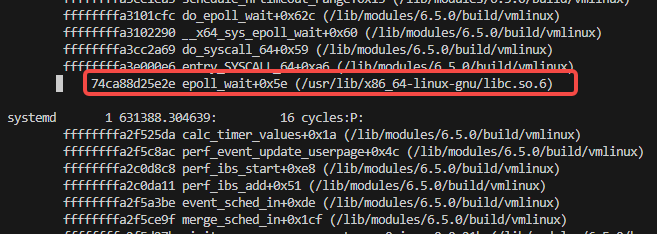
我们使用解析程序,输入pid和va,进行解析,可以看到解析出一样的函数符号名和offset。
