怎么样进行定量分析
本文章将教会你如何对实验结果进行定量分析,其需要一定的论文基础,文末有论文撰写小技巧,不要看基础原理的人可以直接调到文章末尾。
一、什么是定量分析
定量分析是一种基于数据和数学模型的分析方法,它在众多领域中发挥着至关重要的作用,尤其在科学研究、市场研究以及社会科学研究等方面。定量分析的核心在于通过具体的数据来对研究对象的特征、行为以及相关关系进行量化描述和深入探究。其首要步骤是明确研究问题,并确定能够量化该问题的关键变量。例如,在市场研究中,研究者可能关注产品的销售量与广告投入之间的关系,这里的销售量和广告投入就是关键的量化变量。接下来,研究者通过各种手段进行数据的收集,这可能包括问卷调查、实验观测、数据库查询等。为了保证分析结果的可靠性,所收集的数据必须准确、完整且具有代表性。
在数据收集完成后,研究者通常会运用统计学方法和数学模型来进行数据分析。描述性统计分析能够对数据的基本特征进行总结,例如计算平均值、中位数、标准差等,以展示数据的集中趋势和离散程度。而相关性分析则用于探究不同变量之间的关联程度,如判断消费者的收入水平与购买能力之间是否存在正相关关系。更为复杂的回归分析可以进一步揭示变量之间的因果关系,帮助研究者建立预测模型,例如预测房价如何受到地理位置、房屋面积、周边配套设施等因素的综合影响。以下是一个完整的定量分析的Python代码示例,涵盖了数据的读取、预处理、统计分析、可视化和结果解释等步骤。我们将使用常见的库如pandas、numpy、scipy和matplotlib来完成这些任务。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats# 读取数据
data = pd.read_csv('your_data.csv') # 请替换为你的数据文件路径# 数据预处理
# 假设数据中包含以下列:'population', 'gdp', 'unemployment_rate', 'consumption_index'
# 请根据你的数据调整列名# 检查数据的基本信息
print(data.info())# 检查数据的描述性统计
print(data.describe())# 数据清洗
# 处理缺失值
data = data.dropna() # 或者使用 data.fillna(...) 方法填充缺失值# 数据转换(如标准化)
data_standardized = (data - data.mean()) / data.std()# 统计分析
# 计算相关矩阵
correlation_matrix = data.corr()
print("相关矩阵:")
print(correlation_matrix)# 假设检验(例如,检验两个变量之间的相关性是否显著)
variable1 = data['population']
variable2 = data['gdp']# 计算皮尔逊相关系数及p值
pearson_r, p_value = stats.pearsonr(variable1, variable2)
print(f"\n皮尔逊相关系数: {pearson_r}, p值: {p_value}")# 如果p值小于显著性水平(如0.05),则拒绝原假设,认为相关性显著# 可视化分析
# 绘制散点图
plt.figure(figsize=(10, 6))
plt.scatter(variable1, variable2, alpha=0.5)
plt.title('Population vs GDP')
plt.xlabel('Population')
plt.ylabel('GDP')
plt.grid(True)
plt.show()# 绘制箱线图
plt.figure(figsize=(10, 6))
data.boxplot(column=['unemployment_rate', 'consumption_index'])
plt.title('Boxplot of Unemployment Rate and Consumption Index')
plt.ylabel('Value')
plt.grid(True, axis='y')
plt.show()# 绘制直方图
plt.figure(figsize=(10, 6))
plt.hist(data['consumption_index'], bins=10, edgecolor='black')
plt.title('Histogram of Consumption Index')
plt.xlabel('Consumption Index')
plt.ylabel('Frequency')
plt.grid(True, axis='y')
plt.show()# 结果解释
# 根据相关矩阵和假设检验的结果,解释变量之间的关系
# 例如,如果人口和GDP之间的皮尔逊相关系数较高且p值显著,可以认为两者存在显著的正相关关系
# 同时,根据散点图、箱线图和直方图,可以进一步理解数据的分布和特征# 如果需要更多分析,可以继续添加其他统计方法和可视化图表定量分析的优势在于它能够以客观、精确的方式呈现研究结果,并且便于不同研究之间进行比较和验证。与定性分析相比,它更侧重于数据和数量关系,避免了过多主观因素的干扰。然而,定量分析也有其局限性,它往往依赖于数据的质量和所选模型的合理性。如果数据存在偏差或者模型假设不准确,分析结果可能会产生误导。因此,在进行定量分析时,研究者需要谨慎地设计研究方案,选择合适的分析方法,并对结果进行充分的解释和讨论,以确保分析结论的科学性和实用性。
二、在论文怎么写这部分内容
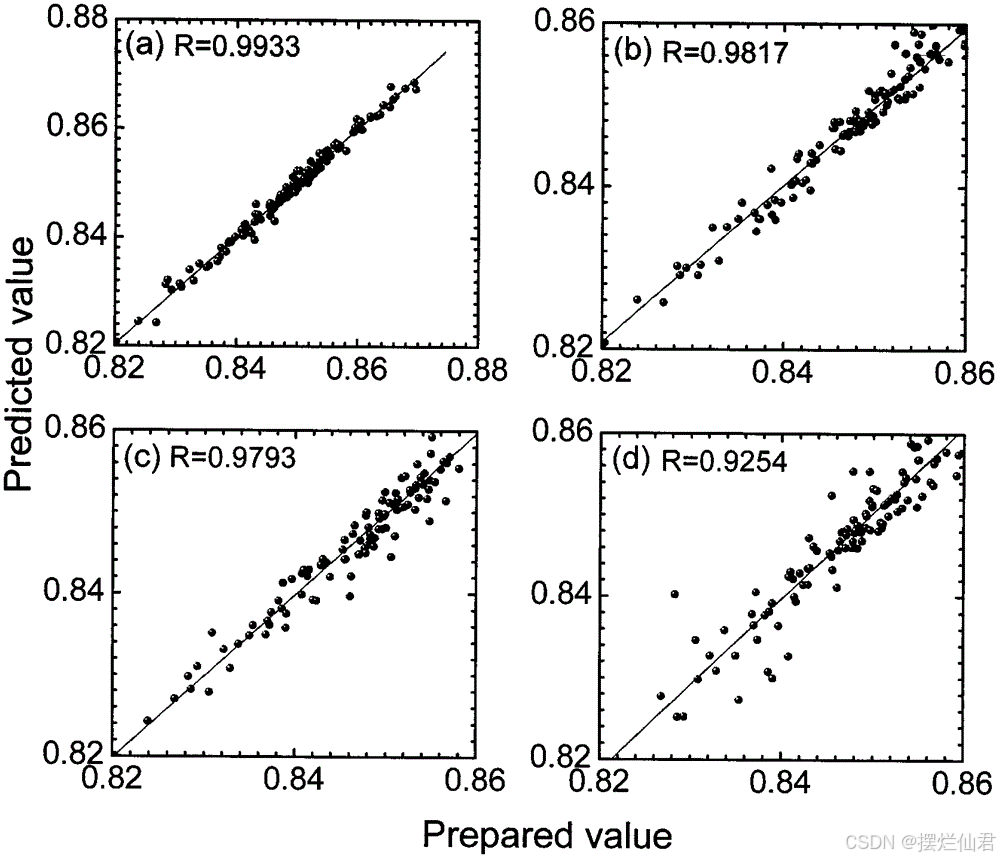
论文中的定量分析部分通常起始于研究问题的明确界定。研究问题决定了分析的目标和方向,因此需要在这一部分清晰地阐述研究的核心问题以及通过定量分析期望揭示的内容。然后,需要确定与研究问题紧密相关的变量,这些变量是定量分析的基石。例如,在研究消费者行为与市场营销策略之间的关系时,消费者购买频率、消费金额、年龄、性别等都可能是关键变量。先放一个真正的学术论文,看看其是怎么撰写这部分内容的:
在数据预处理方面,论文应阐述如何对收集到的原始数据进行整理和清洗。这可能包括处理缺失值、异常值、数据标准化等步骤。例如,若存在大量缺失值,需要说明采用何种方法进行填补,如均值填补、回归填补等;对于异常值,是选择剔除还是进行修正,并解释这样做的理由。数据预处理的目的是确保数据的质量,提高分析的准确性。
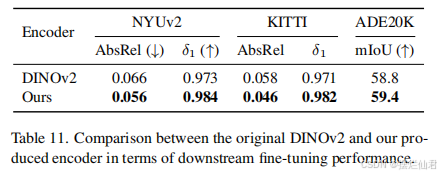
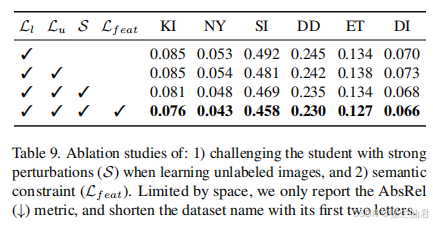
定量分析方法的选择和应用是这一部分的核心内容。应详细说明所采用的统计分析方法或数学模型,如回归分析、聚类分析、因子分析、时间序列分析等,并解释选择这些方法的原因。例如,若采用多元线性回归模型来分析多个自变量对因变量的影响,需要阐述模型的假设条件、变量的选择依据以及模型的拟合过程。同时,应对模型的结果进行详细的解释和讨论,包括系数的显著性、模型的拟合优度等指标。通过这些结果,展示变量之间的关系以及模型对研究问题的解释能力。

模型的验证和检验也是必不可少的环节。在论文中,应描述如何对模型进行验证,如采用交叉验证、留出法等方法来评估模型的泛化能力。此外,还需要进行假设检验,验证模型中的各个参数是否显著,以及整体模型是否具有统计学意义。例如,通过t检验来判断回归系数是否显著不为零,通过F检验来检验模型的整体显著性。这些检验结果能够增强论文结论的可信度。
三、好用的定量分析技巧
你如果要做定量分析,那么最好要有一个表格数据,通过数据来展示自己的定量分析。但是要做一个表格比较麻烦,这边建议你先直接用latex排版,用来写表格的latex代码如下:
\documentclass{article}
\usepackage{booktabs}
\usepackage{siunitx}
\begin{document}\begin{table}[htbp]\centering\caption{定量分析结果}\label{tab:quantitative_analysis}\begin{tabular}{@{}lSSSS@{}}\toprule\textbf{变量} & \textbf{平均值} & \textbf{标准差} & \textbf{最小值} & \textbf{最大值} \\\midrule变量 1 & 12.34 & 5.67 & 8.90 & 15.78 \\变量 2 & 56.78 & 9.12 & 45.67 & 78.90 \\变量 3 & 45.67 & 8.34 & 32.56 & 67.89 \\变量 4 & 23.45 & 6.78 & 12.34 & 34.56 \\变量 5 & 67.89 & 10.23 & 56.78 & 89.01 \\\bottomrule\end{tabular}\begin{tablenotes}\small\item \textbf{注}:表格中列出了各变量的主要统计量,包括平均值、标准差、最小值和最大值。\end{tablenotes}
\end{table}\end{document}这个代码创建了一个包含变量名称、平均值、标准差、最小值和最大值的定量分析表格,使用了 booktabs 和 siunitx 两个宏包来美化表格和对齐数值。你可以根据自己的需求修改表格中的变量名称和数据,也可以调整表格的列数和格式,跑出来的格式基本比较完美。
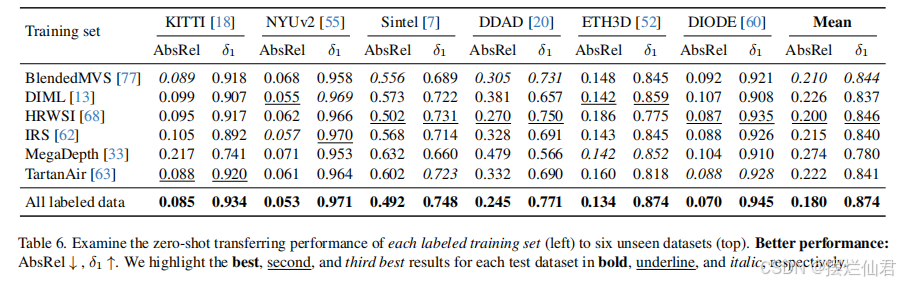
其中值得注意的是你定量分析对比的前沿论文需要进行文献引用,别忘了哦。(还不会用latex编程的,给你个超链接自己学)