linux--------------Ext系列⽂件系统(下)
1.ext2文件系统
引言
ext2(Second Extended File System)是Linux历史上最经典的文件系统之一,其设计思想深刻影响了后续的ext3、ext4等版本。尽管它缺乏日志功能,但其简洁高效的磁盘布局仍值得学习。本文将围绕ext2的Block Group结构、目录与文件名的存储、路径解析逻辑、挂载分区的实现以及路径缓存优化展开详细解析。
1-1 宏观认识
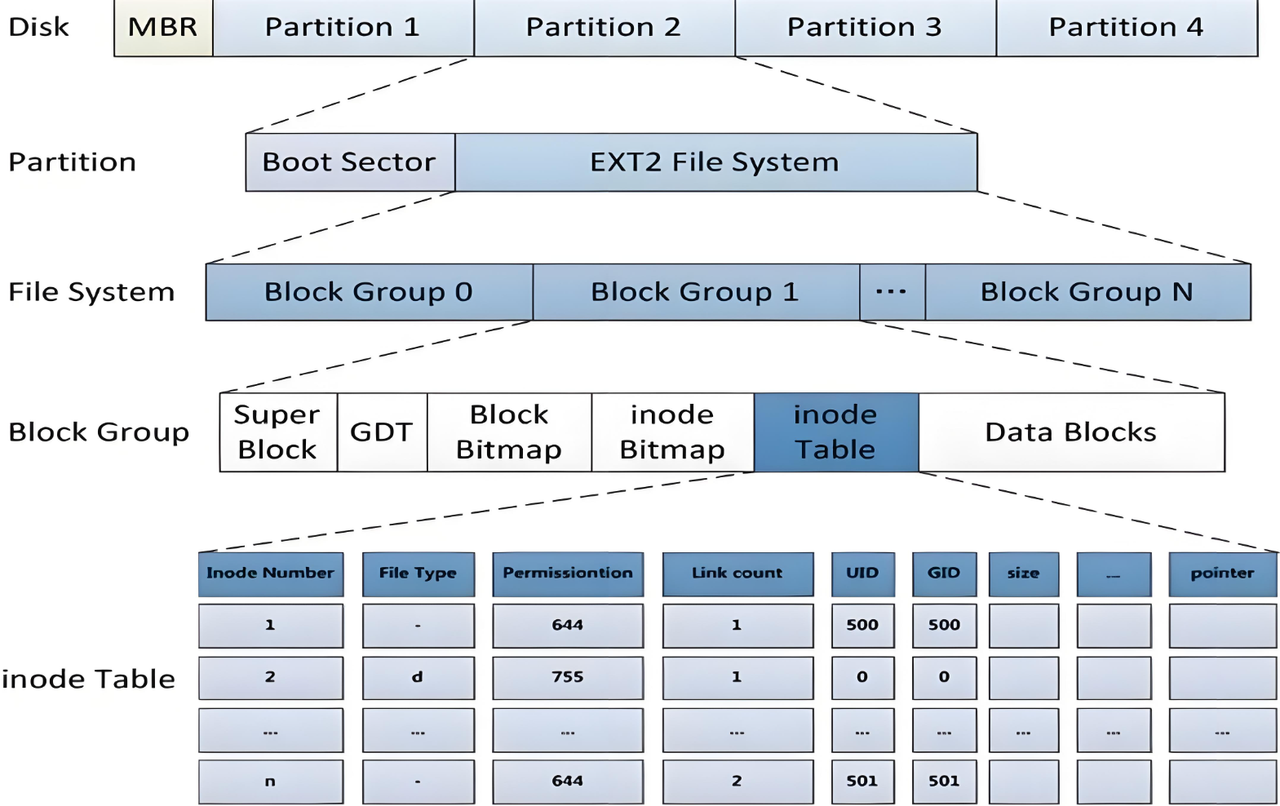
一、Block Group:ext2的物理组织单元
ext2将存储空间划分为多个Block Group,每个组独立管理自己的元数据和数据块,这种设计既提升了性能(减少磁头移动),又增强了容错能力。
-
超级块(Super Block)
位于每个Block Group的头部(仅部分组备份),记录全局信息:-
文件系统大小、块大小(如4KB)
-
Inode总数、空闲块数
-
最后一次挂载时间等
-
-
组描述符(Group Descriptor)
存储组内关键结构的偏移地址:-
块位图(Block Bitmap)和Inode位图(Inode Bitmap)的位置
-
Inode表(Inode Table)的起始块号
-
-
块位图与Inode位图
-
块位图:每个比特表示一个数据块是否空闲(1=占用,0=空闲)。
-
Inode位图:同理管理Inode的分配状态。
-
-
Inode表
-
每个Inode(如128字节)对应一个文件/目录,存储元数据:权限、大小、时间戳,以及15个块指针(12个直接、1个间接、1个双间接、1个三间接)。
-
-
数据块(Data Blocks)
-
存储实际文件内容或目录项列表。
-
二、目录与文件名的存储机制
目录在ext2中是一个特殊文件,其内容由若干目录项(Dirent)组成,每个目录项结构如下:
plaintext
复制
下载
| Inode号(4B) | 目录项长度(2B) | 文件名长度(1B) | 文件类型(1B) | 文件名(变长) |
-
可变长度设计:短文件名(如
a.txt)占用较小空间,长文件名自动扩展,避免浪费。 -
线性查找:目录项以链表形式存储,查找文件需遍历(后续ext4改用哈希树优化)。
三、路径解析:从/home/user/file.txt到数据块
当用户访问路径时,文件系统需逐级解析:
-
根目录起点:根目录的Inode号固定为2,读取其数据块。
-
逐级查找:
-
解析
home:在根目录的目录项中找到home的Inode号。 -
解析
user:进入home目录的数据块,查找user的Inode号。 -
最终定位
file.txt的Inode,获取文件内容。
-
-
权限检查:每一级目录需验证执行权限(
x位)。
四、挂载分区:连接设备与文件系统树
通过mount命令将分区挂载到目录(如/mnt):
-
读取超级块:验证文件系统类型和完整性。
-
初始化VFS结构:将设备关联到挂载点,建立
super_block和inode内存对象。 -
隐藏原内容:挂载后,原目录内容不可见,直到卸载(
umount)。
五、路径缓存(dentry缓存):加速访问的关键
为避免重复解析路径,内核维护目录项缓存(dentry cache):
-
缓存命中:若
/home/user已缓存,下次访问/home/user/file.txt时直接跳过已解析部分。 -
LRU淘汰策略:缓存空间不足时,淘汰最久未使用的条目。
二、硬链接(Hard Link):共享inode的“文件分身”
1. 硬链接的原理
-
直接关联inode:硬链接通过目录项直接指向目标文件的inode号。
-
引用计数:每个inode中有一个
i_links_count字段,记录被硬链接引用的次数。 -
示例命令:
bash
复制
下载
ln source.txt hardlink.txt # 创建硬链接
2. 目录结构中的表现
-
目录项结构:硬链接的目录项与普通文件无异,仅存储文件名和inode号。
plaintext
复制
下载
| Inode号(与源相同) | 目录项长度 | 文件名长度 | 文件类型 | 文件名(如hardlink.txt) |
-
删除操作:删除源文件(如
source.txt)后,硬链接依然有效(inode引用计数减1)。仅当i_links_count=0时,文件数据才会被释放。
3. 硬链接的限制
-
无法跨文件系统:inode号仅在同一个文件系统内有效。
-
无法链接目录:避免目录环问题(仅超级用户可通过
ln -d绕过,但风险极高)。
三、软链接(Symbolic Link):存储路径的“快捷方式”
1. 软链接的原理
-
独立inode与数据块:软链接是一个独立的文件,其数据块中存储目标文件的路径字符串。
-
示例命令:
bash
复制
下载
ln -s source.txt symlink.txt # 创建软链接
2. 目录结构中的表现
-
目录项结构:软链接拥有自己的inode,文件类型标记为
符号链接。plaintext
复制
下载
| Inode号(新) | 目录项长度 | 文件名长度 | 文件类型(符号链接) | 文件名(如symlink.txt) |
-
数据块内容:存储目标路径(如
source.txt,长度不超过文件系统块大小)。
3. 软链接的特性
-
跨文件系统支持:路径解析不依赖inode,可指向其他文件系统的文件。
-
悬空链接风险:删除源文件后,软链接仍存在但指向无效路径。
三、软硬链接对比:核心差异与使用场景
| 对比项 | 硬链接 | 软链接 |
|---|---|---|
| 本质 | 共享inode的多个目录项 | 存储目标路径的独立文件 |
| inode占用 | 不创建新inode,共享源文件inode | 创建新inode和数据块 |
| 跨文件系统 | ❌ 不支持 | ✅ 支持 |
| 链接目录 | ❌ 默认禁止(防止环路) | ✅ 支持 |
| 删除源文件 | 文件仍可通过硬链接访问 | 链接失效(悬空链接) |
| 存储内容 | 直接指向inode号 | 存储目标文件的路径字符串 |
| 性能 | 路径解析快(无需递归) | 解析慢(需递归查找目标路径) |
四、目录结构中的链接示例
假设目录结构如下:
复制
下载
/ ├── source.txt # 源文件(inode=1001) ├── hardlink.txt # 硬链接(inode=1001) └── symlink.txt -> source.txt # 软链接(inode=1002,数据块存储路径"source.txt")
-
硬链接的目录项
-
文件名:
hardlink.txt,inode号:1001,文件类型:普通文件。 -
删除
source.txt后,hardlink.txt仍可访问原数据。
-
-
软链接的目录项
-
文件名:
symlink.txt,inode号:1002,文件类型:符号链接。 -
删除
source.txt后,访问symlink.txt会报错:No such file or directory。
-
五、应用场景与最佳实践
-
硬链接适用场景
-
需要多入口访问同一文件(如日志文件的多个硬链接)。
-
节省inode资源(无额外inode开销)。
-
-
软链接适用场景
-
跨文件系统引用文件或目录。
-
动态路径切换(如版本管理中指向
latest版本目录)。 -
避免循环依赖(如
/bin/sh软链接到/bin/bash)。
-
六、ext2文件系统对链接的限制
-
硬链接的最大数量
-
由inode的
i_links_count字段位数决定(通常为65535次)。
-
-
软链接路径长度
-
受限于文件系统块大小(如4KB块最大存储4096字节路径)。
-