机器学习 day02
文章目录
- 前言
- 一、TF-IDF特征词重要度特征提取
- 二、无量纲化处理
- 1.最大最小值归一化
- 2.normalize归一化
- 3.StanderScaler标准化
前言
- 通过今天的学习,我掌握了TF-IDF特征词重要度特征提取以及无量纲化处理的相关知识和用法
一、TF-IDF特征词重要度特征提取
- 机器学习算法在处理文本时有广泛应用,在分析文本时,我们常常使用词频(TF),逆文档频率(IDF)反映文本中的关键词
- 词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性
- 逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度
- TF-IDF可以反映词语在某文本中的重要程度
以下给出相应的计算公式:

- 需要注意的是,在sklearn库中对TF和IDF的公式进行了优化,sklearn中直接使用一个词在某文档中出现的次数作为TF,而IDF的计算公式如下:
I D F ( t ) = log ( 总文档数 + 1 包含词 t 的文档数 + 1 ) + 1 IDF(t)=\log(\dfrac{总文档数+1}{包含词t的文档数+1})+1 IDF(t)=log(包含词t的文档数+1总文档数+1)+1
API:sklearn.feature_extraction.text.TfidfVectorizer()
该API的用法和结果与CountVectorizer相似,只是此API返回的是TF-IDF组成的系数矩阵
def my_cut(text):return " ".join(jieba.cut(text))
data=["教育学会会长期间,坚定支持民办教育事业!", "扶持民办,学校发展事业","事业做出重大贡献!"]
data=[my_cut(i) for i in data]
# print(data)
# print("词频",CountVectorizer().fit_transform(data).toarray())
transfer=TfidfVectorizer()
res=transfer.fit_transform(data)
print(pd.DataFrame(res.toarray(),columns=transfer.get_feature_names_out()))
二、无量纲化处理
无量纲化顾名思义就是消除单位对数据的影响
1.最大最小值归一化
- 归一化公式如下:
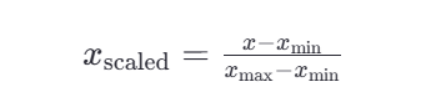
API:sklearn.preprocessing.MinMaxScaler(feature_range)
该API可以将所有的数据归一化到指定的范围内
from sklearn.preprocessing import MinMaxScaler
data = [[12,22,4],[22,23,1],[11,23,9]]
transfer = MinMaxScaler((0,1)) #默认是0-1
data = transfer.fit_transform(data)
2.normalize归一化
- normalize归一化可以对数据的行或列分别进行归一化,主要有以下三种方法:
1.L1归一化,使用数据的绝对值相加作为分母,特征值作为分子
2.L2归一化,使用平方作为分母,特征值作为分子
3.max归一化,只用最大值作为分母,特征值作为分子
from sklearn.preprocessing import normalize
# Normalizer归一化
data = [[12,22,4],[22,23,1],[11,23,9]]
data_scaler = normalize(data,"l2",axis=0)
print(data_scaler)
3.StanderScaler标准化
前两种归一化方法会受到数据中的异常点的影响,导致鲁棒性较差,使用标准化可以解决这个问题
- 标准化公式:
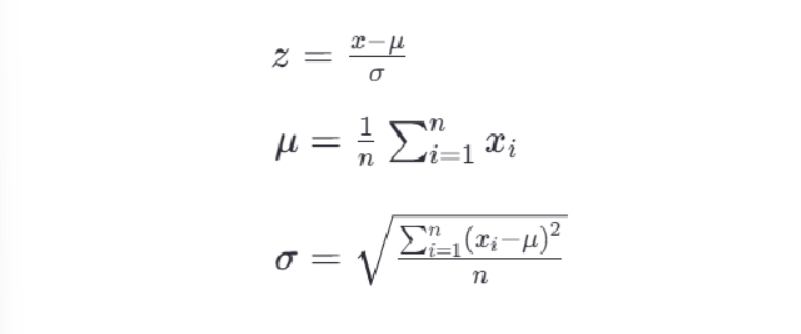
API:sklearn.preprocessing.StanderScaler()
from sklearn.preprocessing import StandardScaler
# 标准化归一化
data = [[12,22,4],[22,23,1],[11,23,9]]
scaler = StandardScaler()
# scaler.fit(data) # 统计数据的均值和方差并保存下来
# scaler.transform(data) #进行标准化转换
data_scaler = scaler.fit_transform(data)
print(data_scaler)
- 注意到创建转换器类对象后fit和transform可以分开进行,fit用于统计并保存当前数据的均值和方差,transform使用保存的均值和方差进行对应转换,如果有两组数据,只对第一组数据fit,那么第二组数据使用transform时会使用第一组数据的均值和方差
from sklearn.preprocessing import StandardScaler
# 标准化归一化
data = [[12,22,4],[22,23,1],[11,23,9]]
scaler = StandardScaler()
scaler.fit(data) # 统计数据的均值和方差并保存下来
scaler.transform(data) #进行标准化转换data2 = [[13,21,5]]
data2 = scaler.transform(data2) #此时使用的是data的均值与方差
print(data2)
THE END